前提条件
Alibaba Cloudアカウントが作成され、実名認証が完了している。
Alibaba Cloudアカウントを作成し、初めてコンソールにログオンすると、後続の操作を実行する前にAccessKeyペアを作成するように求められます。
OpenSearchアプリケーションを作成して使用するにはAccessKeyペアが必要となるため、Alibaba CloudアカウントのAccessKeyペアを作成する必要があります。
Alibaba CloudアカウントのAccessKeyペアを作成した後、RAMユーザーのAccessKeyペアを作成できます。 これにより、RAMユーザーとしてアプリケーションにアクセスできます。 RAMユーザーに権限を付与する方法の詳細については、RAM認証を参照してください。 注:RAMユーザーは、OpenSearchベクトル検索版インスタンスにアクセスするために、AliyunSearchEngineFullAccessまたはAliyunSearchEngineReadOnlyAccess権限を付与されている必要があります。
3. 仮想プライベートクラウド(VPC)が作成されている。 詳細については、VPCとはを参照してください。
RAMユーザーとしてOpenSearchベクトル検索版インスタンスにアクセスする場合は、Alibaba Cloudアカウントを使用して、RAMユーザーにAliyunSearchEngineFullAccessまたはAliyunSearchEngineReadOnlyAccess権限を付与する必要があります。
インスタンスの購入
OpenSearchコンソールにログオンします。 左上隅で、OpenSearchベクトル検索版に切り替えます。
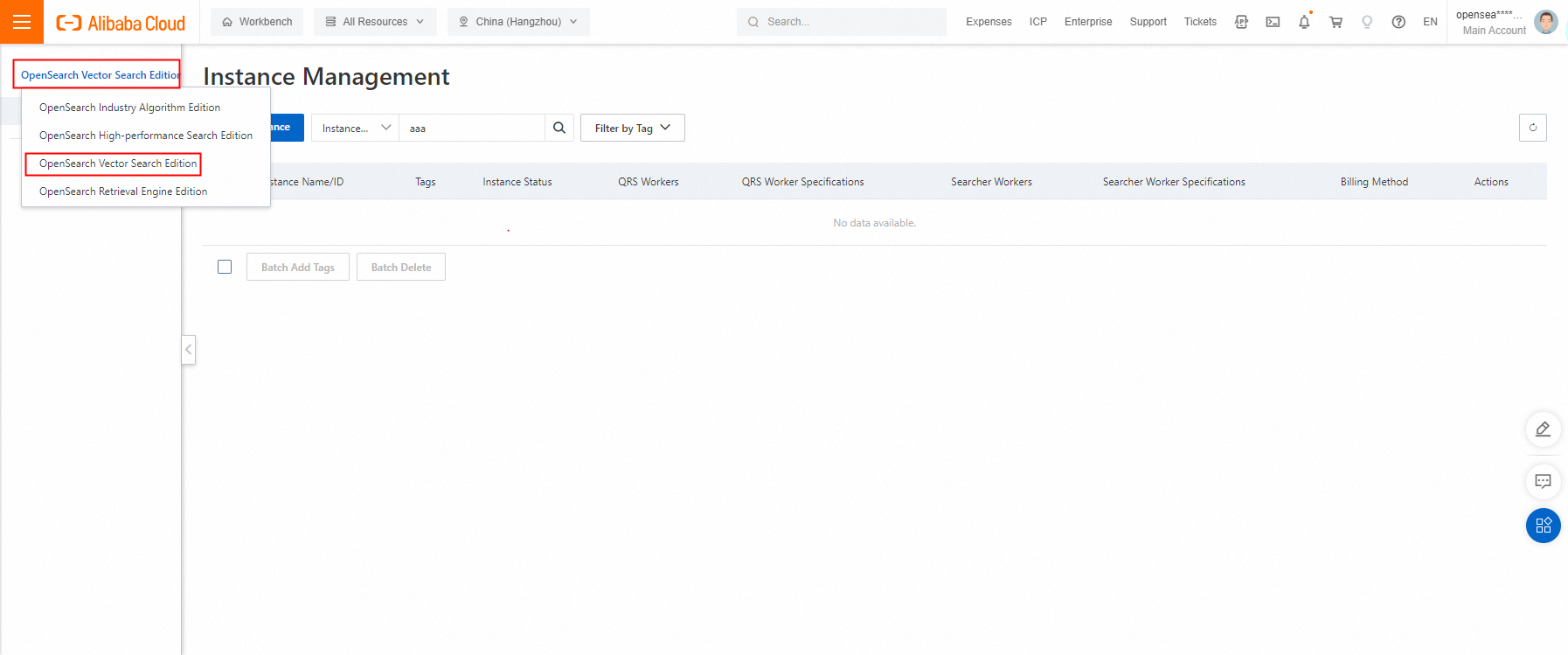
左側のナビゲーションペインで、[インスタンス管理] をクリックします。 [インスタンス管理] ページで、[インスタンスの作成] をクリックします。
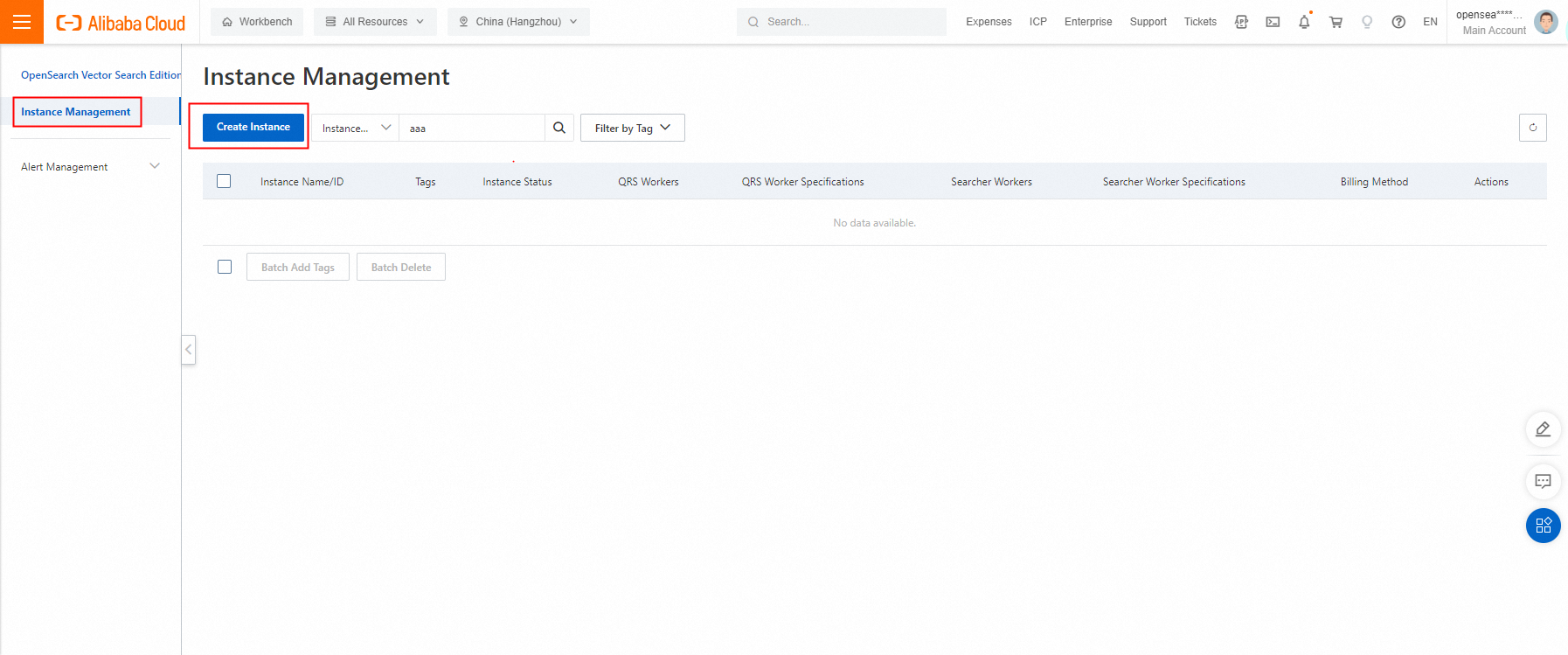
購入ページで、サービスエディションとして[ベクトル検索版] を選択し、インスタンスのリージョンとゾーン、[クエリノード数量]、[クエリノードタイプ]、[データノード数量]、[データノードタイプ]、[単一サーチャーワーカーの合計ストレージ容量]、[VPC]、[vSwitch] パラメーターを設定します。 次に、ユーザー名とパスワードを指定し、[今すぐ購入] をクリックします。 ユーザー名とパスワードは、クエリでの権限検証に使用され、Alibaba Cloudアカウントとパスワードではありません。
ビジネス要件に基づいて、購入するクエリ結果サーチャー(QRS)ワーカーとサーチャーワーカーの数と仕様を指定します。 仕様を指定すると、購入ページに実際の料金が自動的に表示されます。
指定するVPCとvSwitchは、OpenSearchベクトル検索版インスタンスへのアクセスに使用するElastic Compute Service(ECS)インスタンスに設定されているものと一致している必要があります。 そうしないと、OpenSearchベクトル検索版インスタンスにアクセスすると、エラー {'errors':{'code':'403','message':'Forbidden'}} が返されます。
各サーチャーワーカーには、無料のストレージ容量クォータが提供されます。 クォータは50 GB単位で増やすことができます。 合計ストレージ容量が無料クォータを超える場合、超過したストレージ容量に対して課金されます。
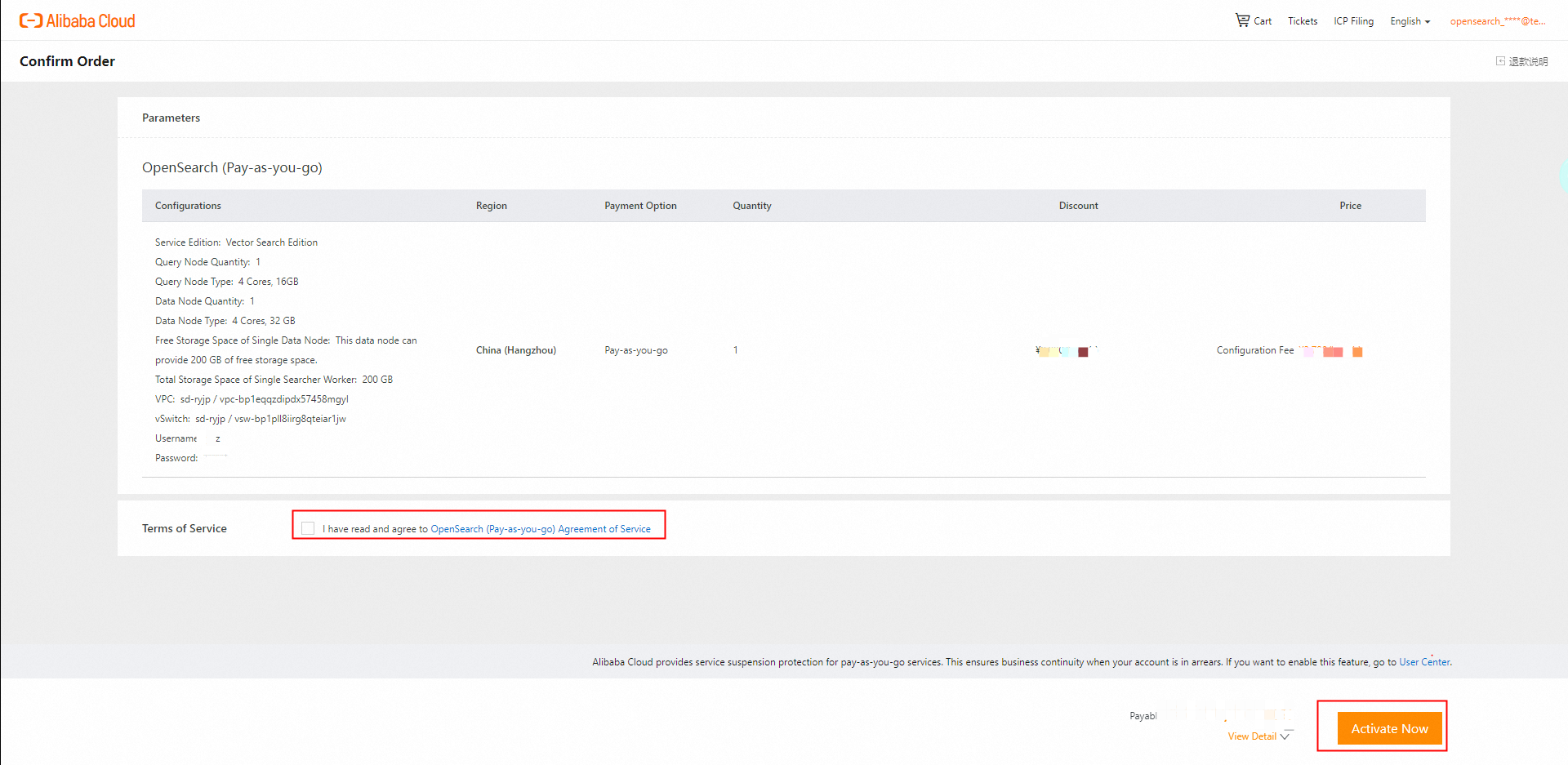
[注文の確認] ページで、設定とサービス契約を確認し、[今すぐアクティブ化] をクリックします。
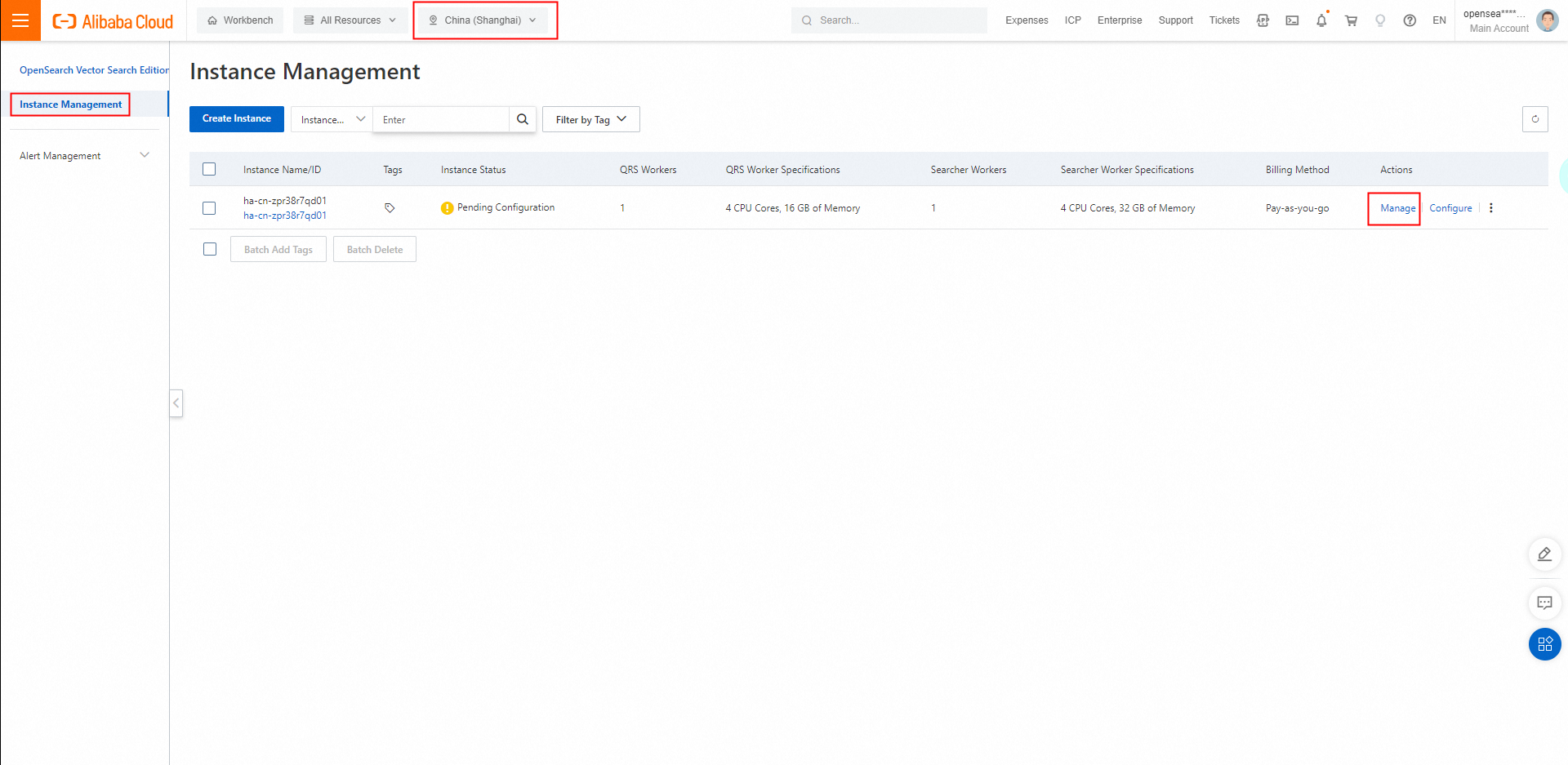
インスタンスを購入した後、[コンソール] をクリックします。 [インスタンス管理] ページで、購入したインスタンスを表示できます。
デフォルトでは、インスタンスの名前は自動的に設定されます。 インスタンスの名前を変更するには、[アクション] 列の[管理] をクリックして、インスタンスの詳細ページに移動します。
[変更] アイコンをクリックし、プロンプトに従ってインスタンス名を変更してから、[確認] をクリックします。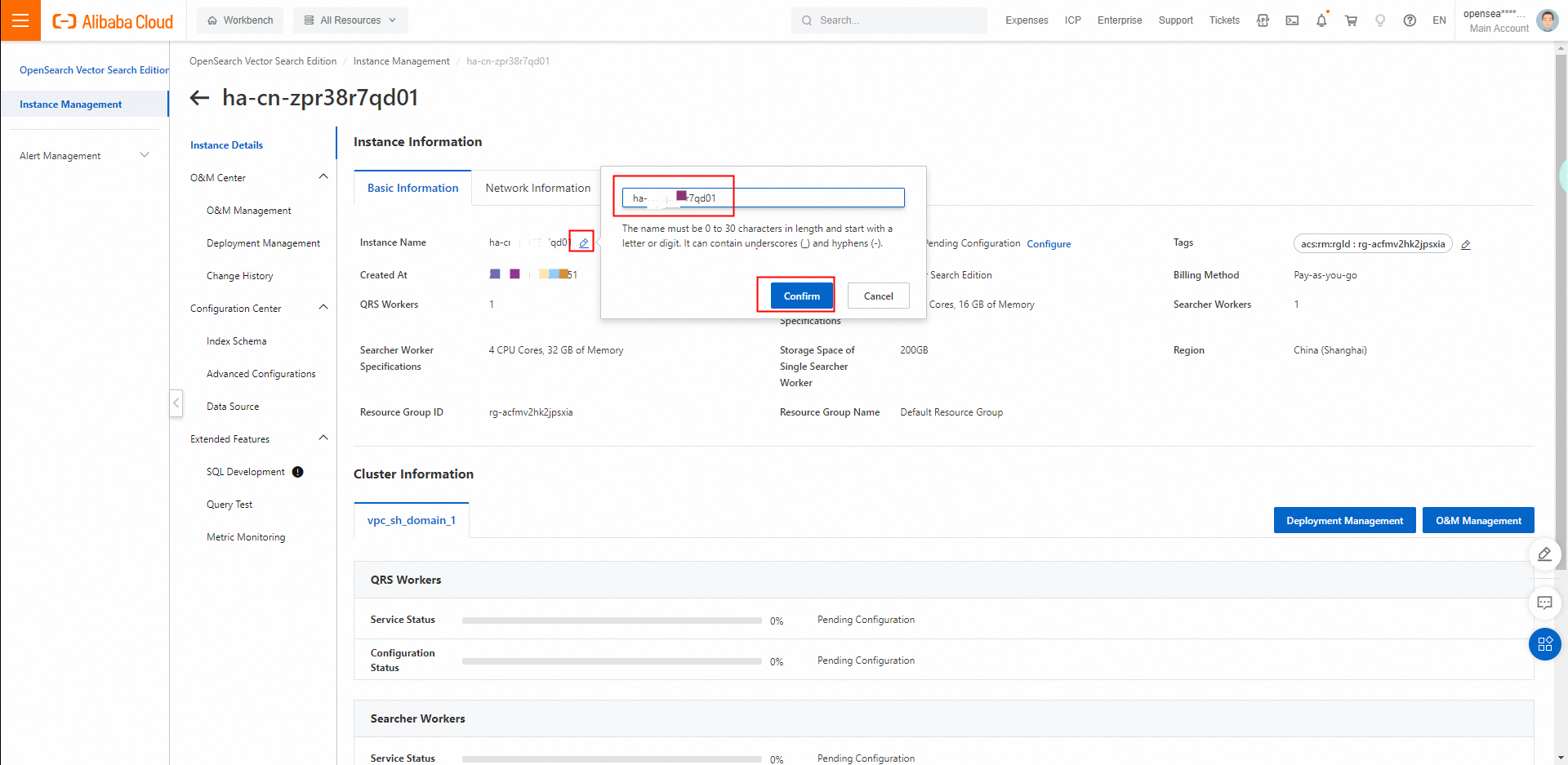
クラスターの設定
購入したインスタンスの詳細ページで、インスタンスが[設定保留中] 状態であり、インスタンスに対して空のクラスターが自動的にデプロイされていることを確認できます。 クラスター内のQRSワーカーとサーチャーワーカーの数と仕様は、インスタンスの購入時に指定したものです。 検索サービスを使用する前に、クラスターのデータソースとインデックススキーマを設定し、インデックスを再構築する必要があります。 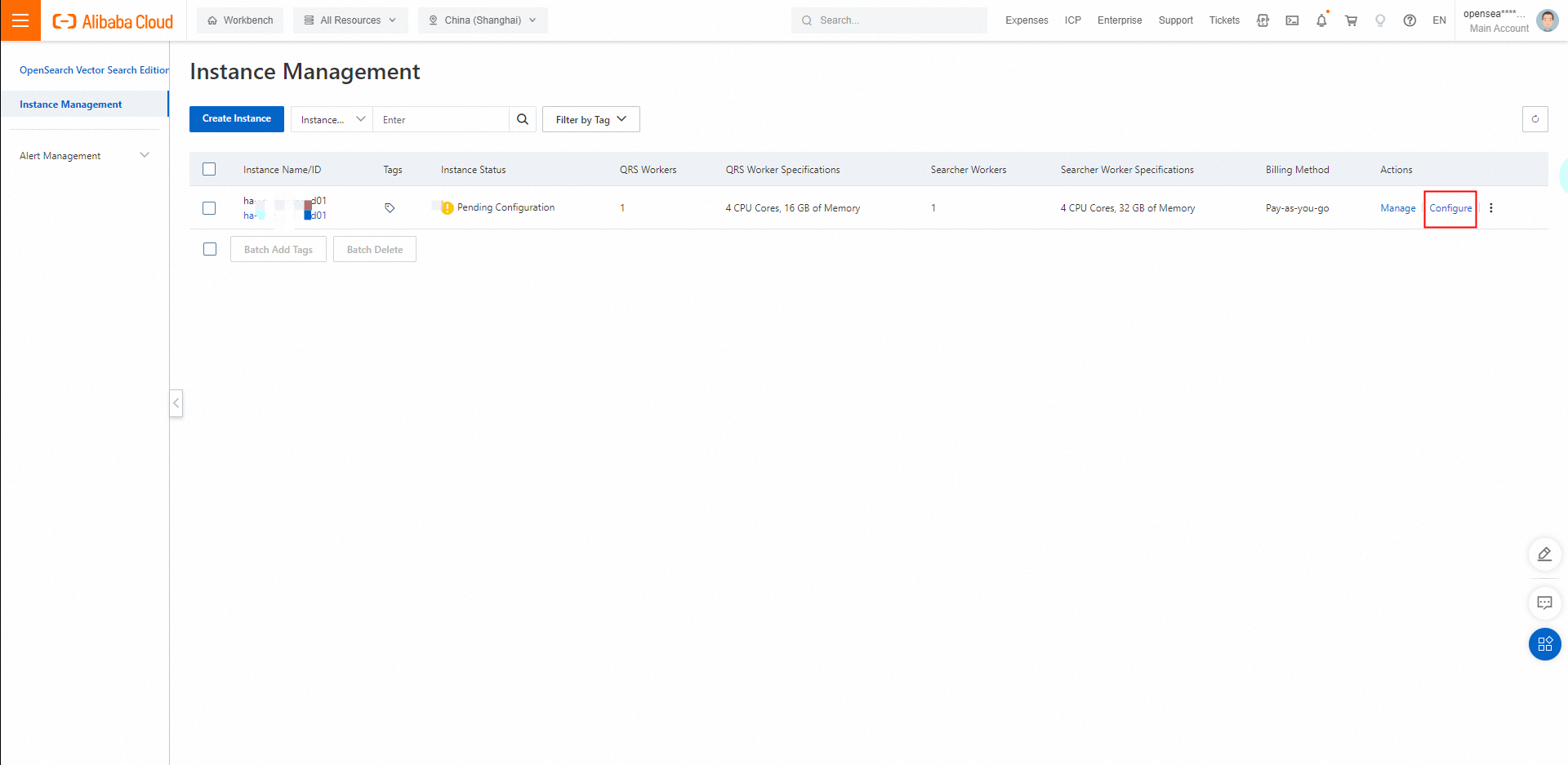
データソースを設定します。 MaxComputeデータソースまたはAPIデータソースからのデータがサポートされています。 この例では、MaxComputeデータソースを使用します。 クラスターのMaxComputeデータソースを設定するには、次の操作を実行します。 [データソースの設定] ステップで、[データソースの追加] をクリックします。 [データソースの追加] パネルで、[データソースの種類] として [MaxCompute] を選択します。 [プロジェクト]、[AccessKey ID]、[AccessKey Secret]、[テーブル]、[パーティションキー] パラメーターを設定します。 ビジネス要件に基づいて、自動再インデックス化で [はい] または [いいえ] を選択します。
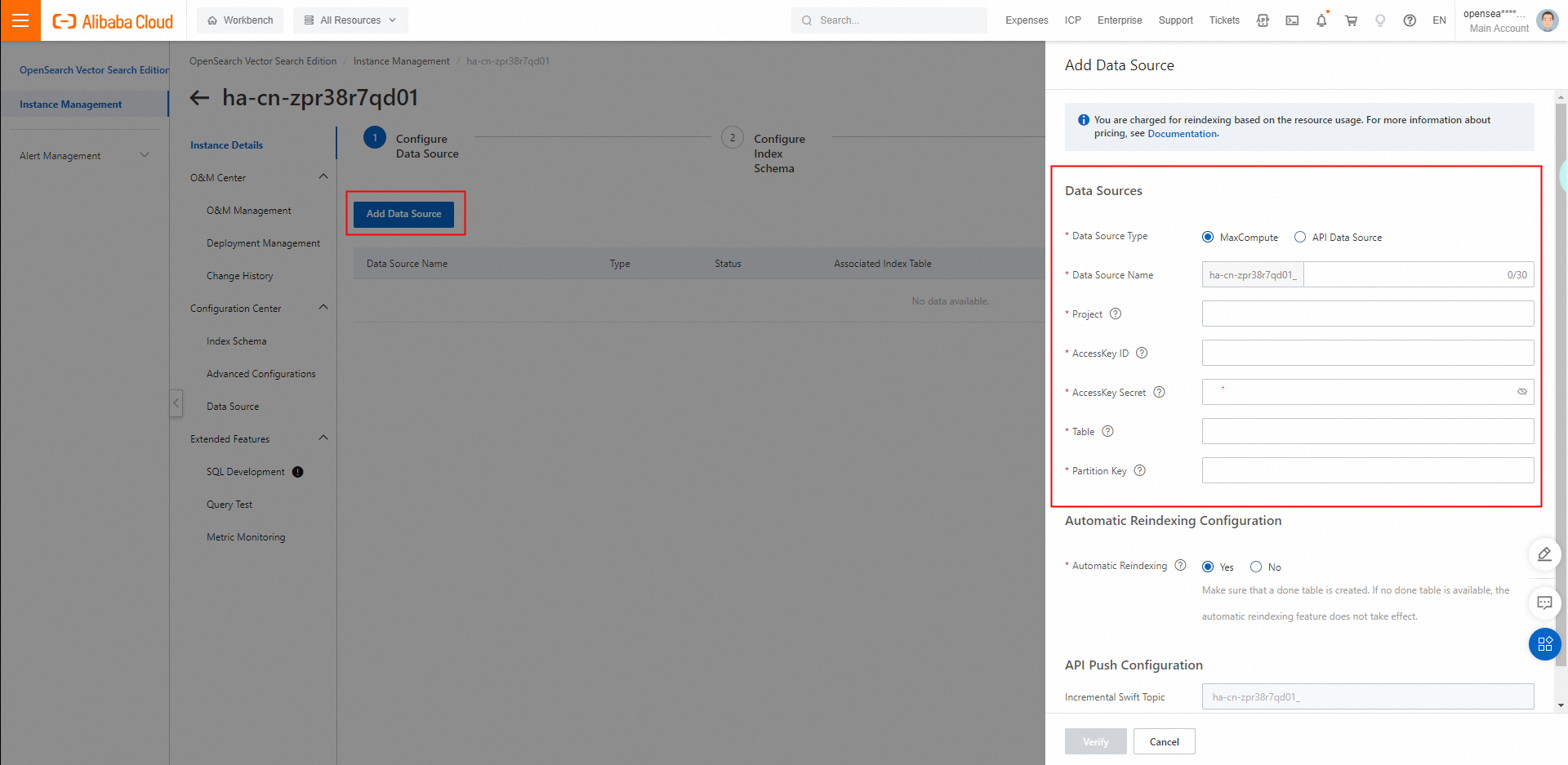
検証に合格したら、[OK] をクリックしてデータソースを追加します。
データソースを設定した後、[次へ] をクリックしてインデックススキーマを設定します。
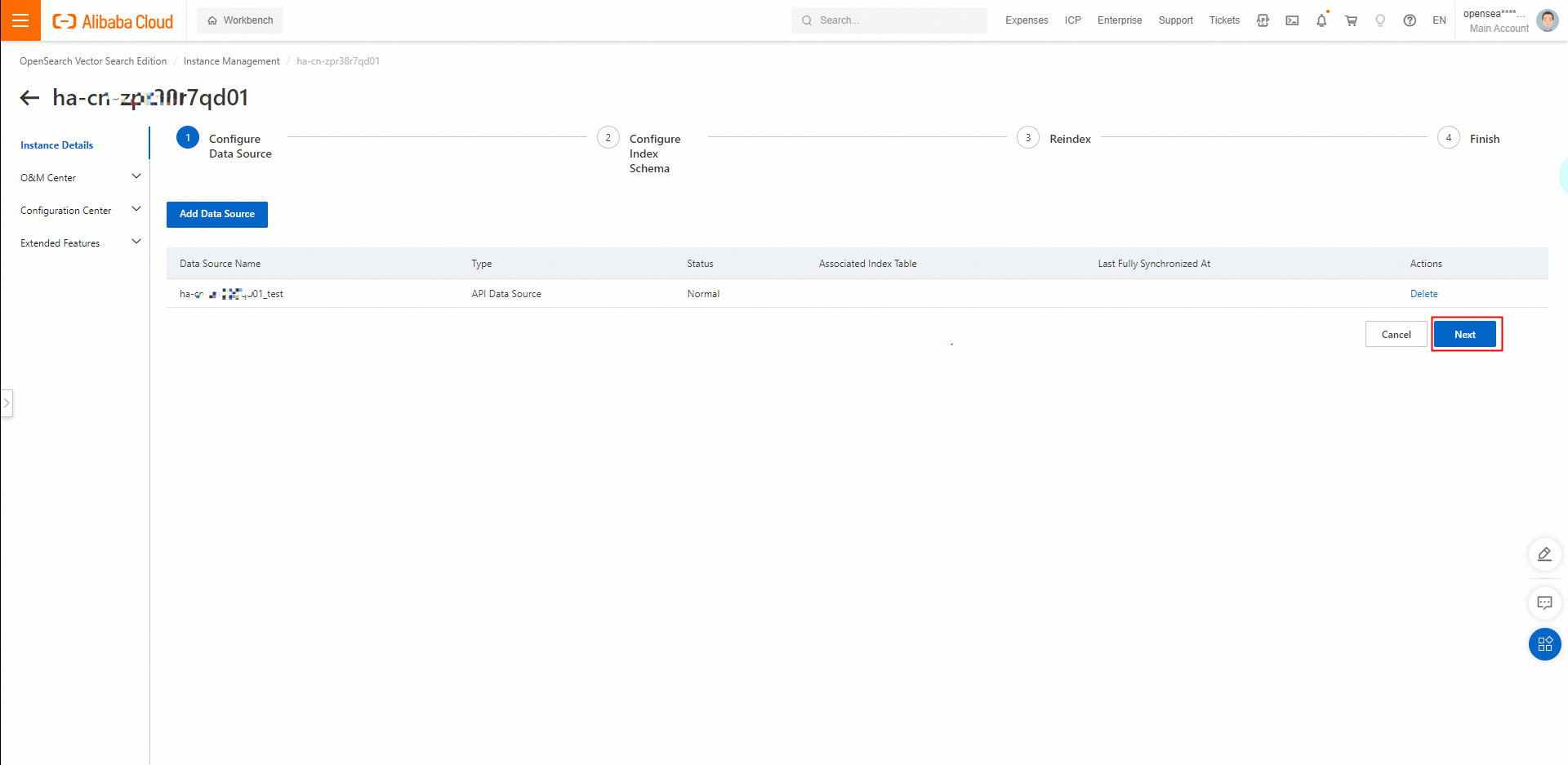
2.1. [インデックステーブルの作成] をクリックします。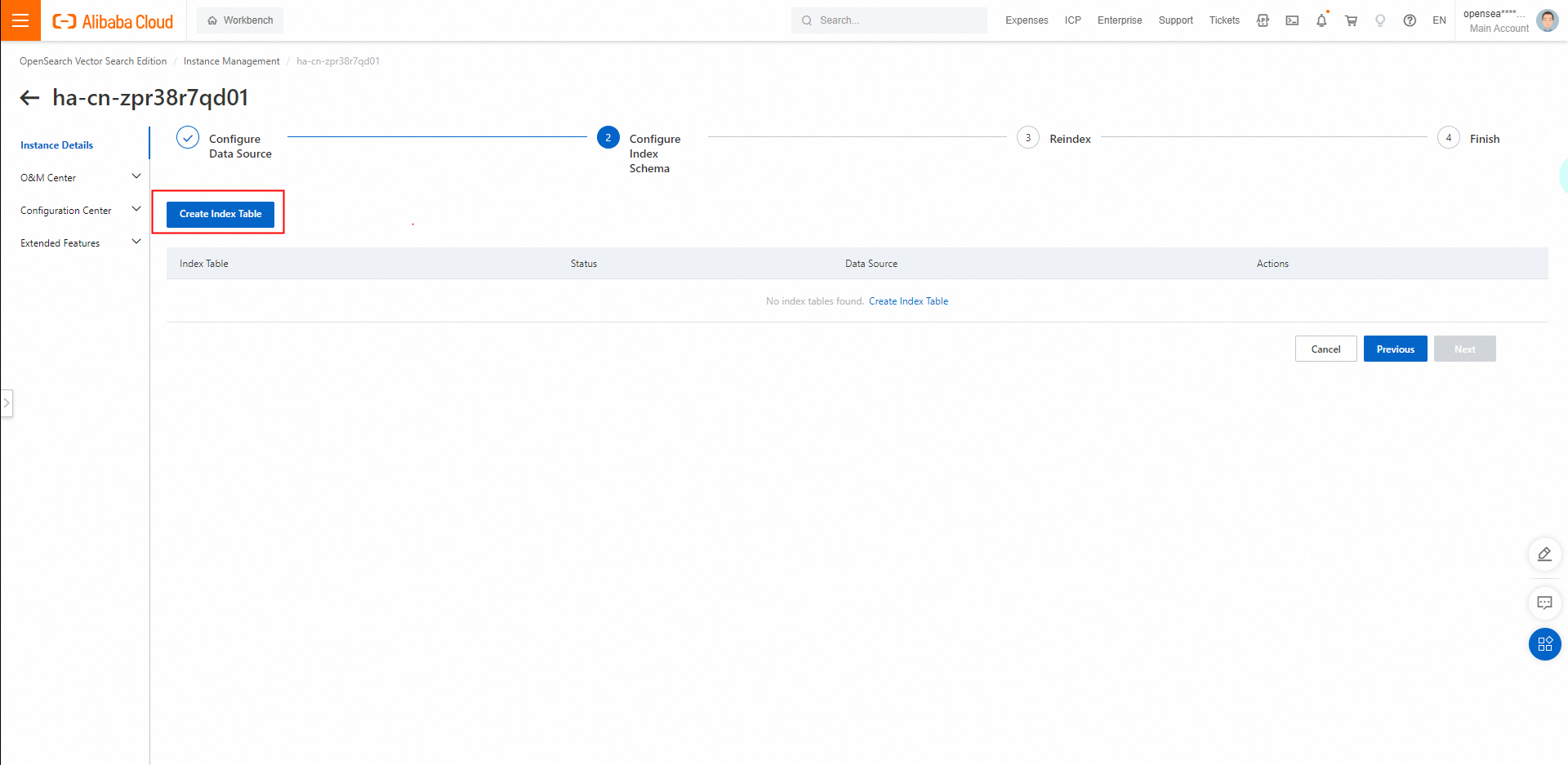
2.2. インデックステーブルを設定します。 [テンプレートの選択] セクションで、[共通テンプレート] を選択します。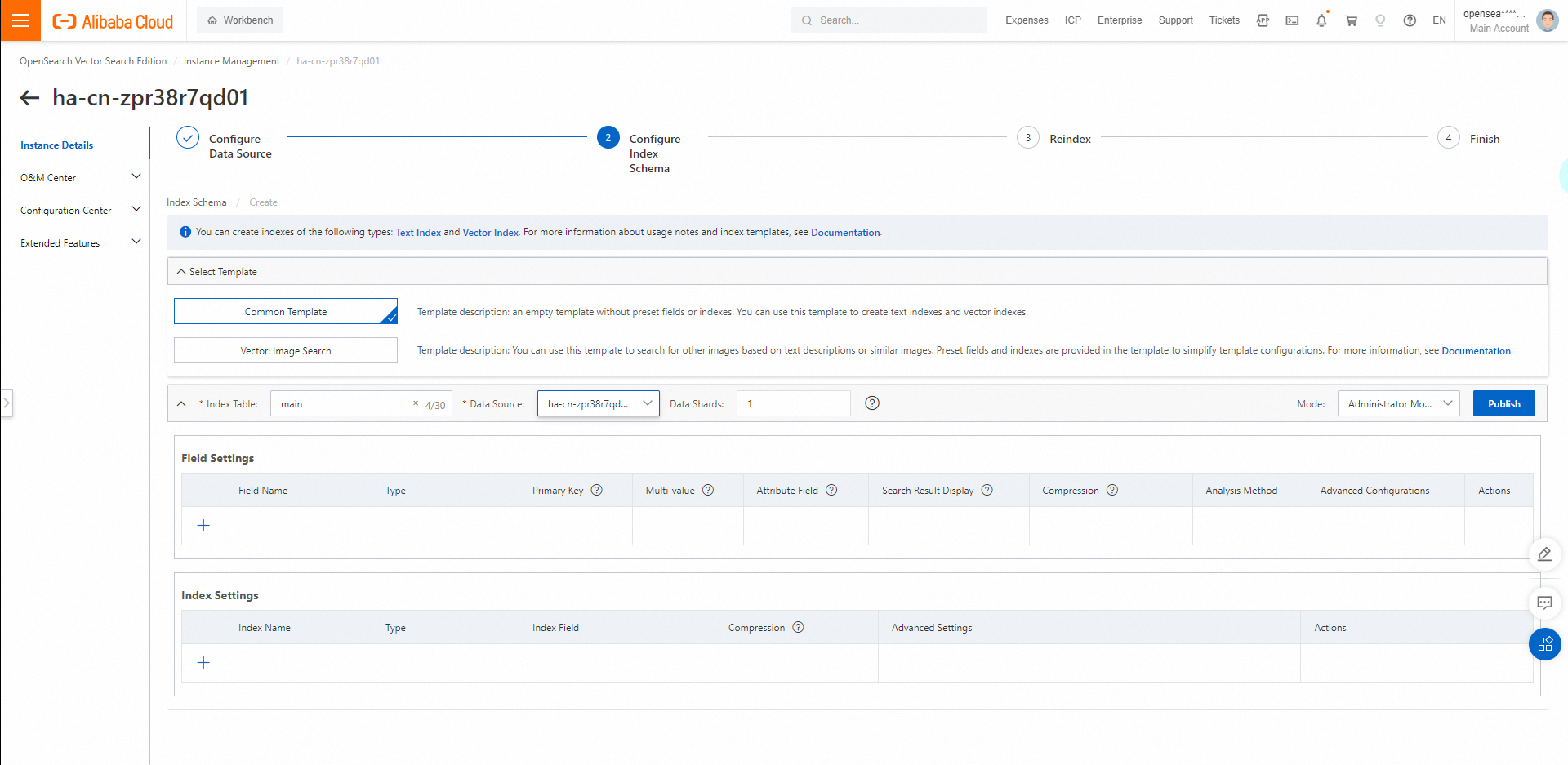
[インデックステーブル]:カスタム名を入力します。
[データソース]:手順1で設定したデータソースを選択します。
[データシャード]:購入したサーチャーワーカーの数に基づいて値を入力します。
2.3. フィールドを設定します。 プライマリキーフィールドとベクトルフィールドの少なくとも2つのフィールドを指定する必要があります。 ベクトルフィールドは、複数値FLOATデータ型である必要があります。
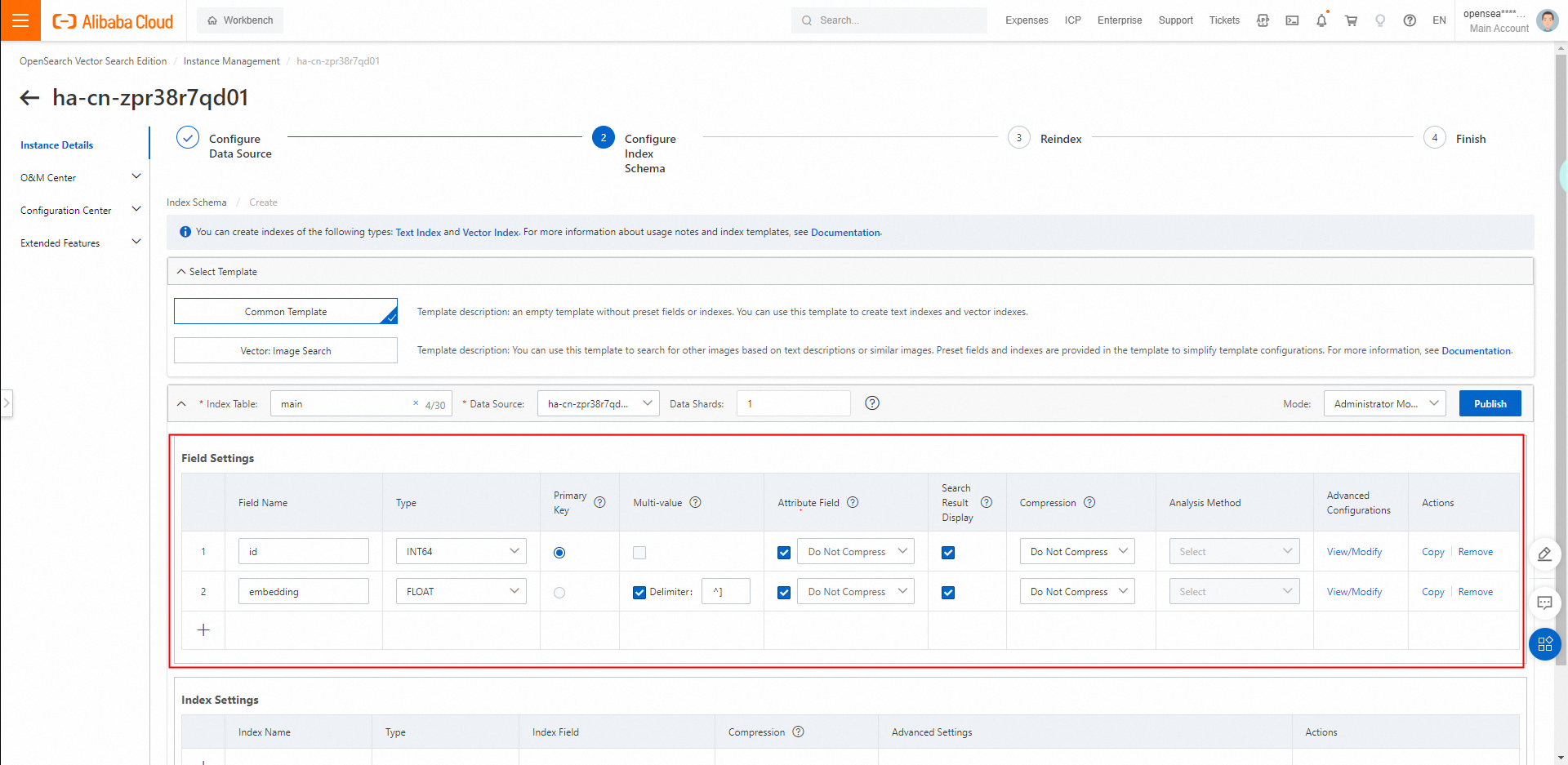
カテゴリを持つベクトルインデックスを設定する場合、プライマリキーフィールドとベクトルフィールドの間にカテゴリフィールドを追加できます。 カテゴリフィールドは、INTEGERデータ型の単一値フィールドまたは複数値フィールドである必要があります。
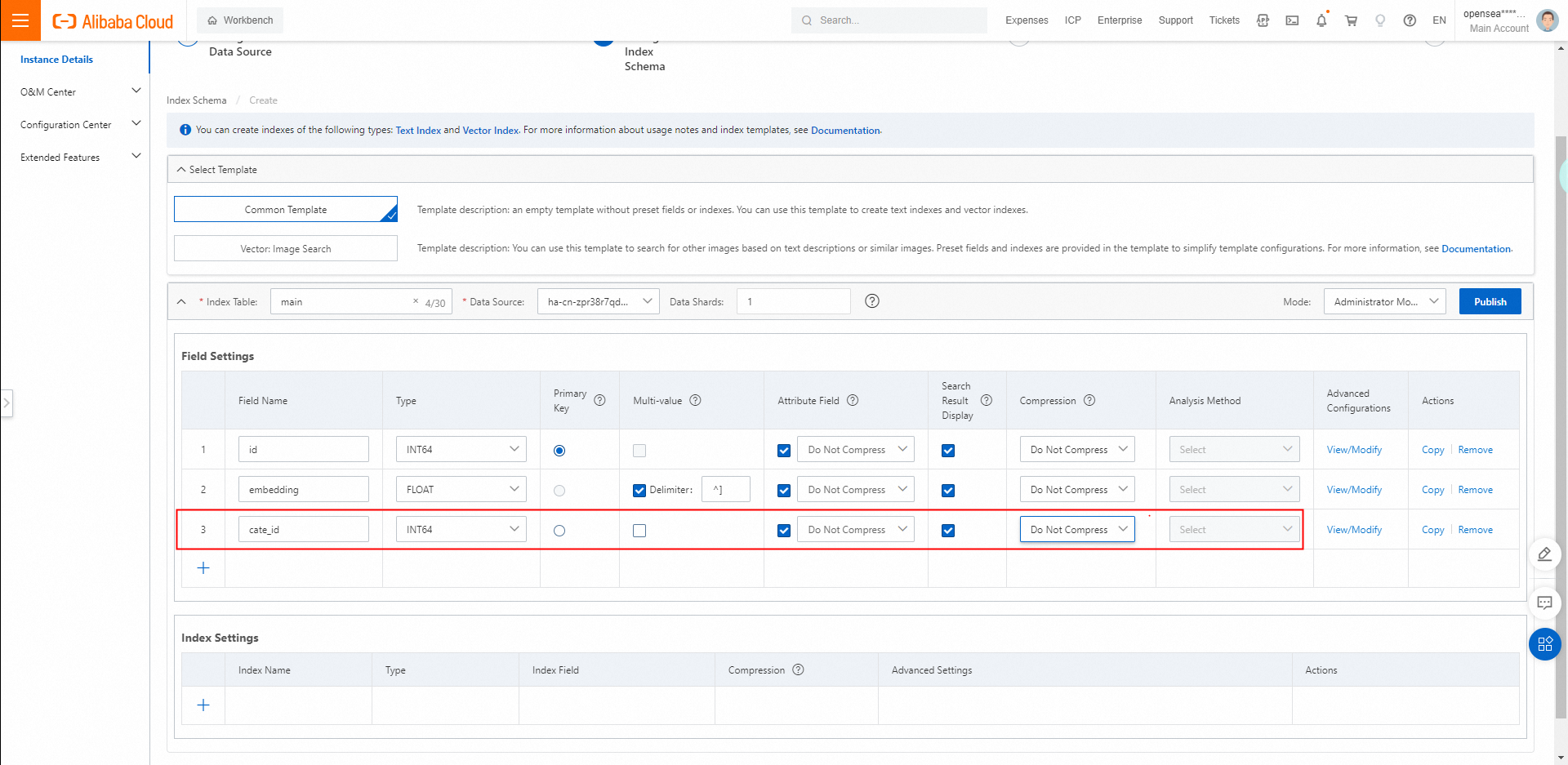
属性フィールドとフィールドデータを圧縮するかどうかを指定します:
属性フィールド: デフォルトでは、属性フィールドは圧縮されません。属性フィールドに file_compressor が選択されている場合、属性フィールドは圧縮されます。
フィールドデータ: デフォルトでは、フィールドデータは圧縮されません。複数値フィールドまたは STRING タイプのフィールドの場合、デフォルトで uniq が選択されます。単一値フィールドの場合、デフォルトで equal が選択されます。
ベクトルインデックスを構成する場合は、主キーフィールド、カテゴリフィールド、ベクトルフィールドの順にフィールドを指定する必要があります。カテゴリフィールドは省略可能です。前の図は例を示しています。
属性フィールドを圧縮する場合は、パフォーマンスへの影響を軽減するために、インデックスのロード方法を変更することをお勧めします。インデックスのロード方法を変更するには、次の操作を実行します。インスタンスの詳細ページで、[デプロイメント管理] をクリックします。表示されるページで、管理する Searcher ワーカーをクリックします。[Searcher ワーカーの構成] パネルで、[オンラインテーブルの構成] タブをクリックします。
インデックスを構成します。プライマリキーインデックスのタイプをPRIMARYKEY64に設定し、ベクトルインデックスのタイプをCUSTOMIZEDに設定する必要があります。
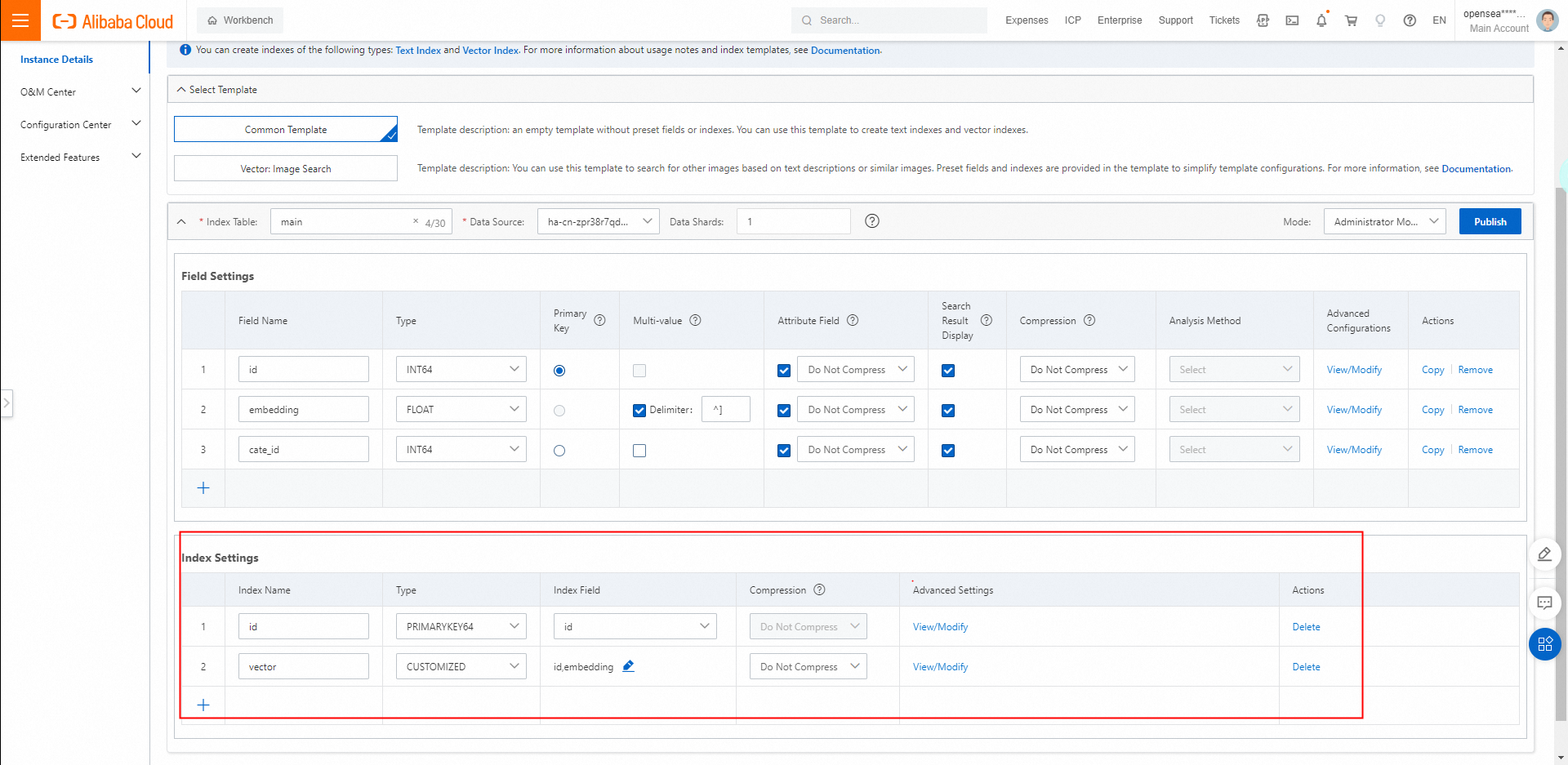
属性フィールドとフィールドデータを圧縮するかどうかを指定します:
デフォルトでは、インデックスフィールドは圧縮されません。インデックスフィールドに file_compressor が選択されている場合、インデックスフィールドは圧縮されます。
プライマリキーインデックスは圧縮できません。
インデックスフィールドを圧縮する場合、パフォーマンスへの影響を軽減するために、インデックスのロード方法を変更することをお勧めします。インデックスのロード方法を変更するには、次の操作を実行します。インスタンスの詳細ページで、[デプロイメント管理] をクリックします。表示されるページで、管理する Searcher ワーカーをクリックします。[Searcher ワーカーの設定] パネルで、[オンラインテーブルの設定] タブをクリックします。
3.1. ベクトルインデックスに含まれるフィールドを指定します。
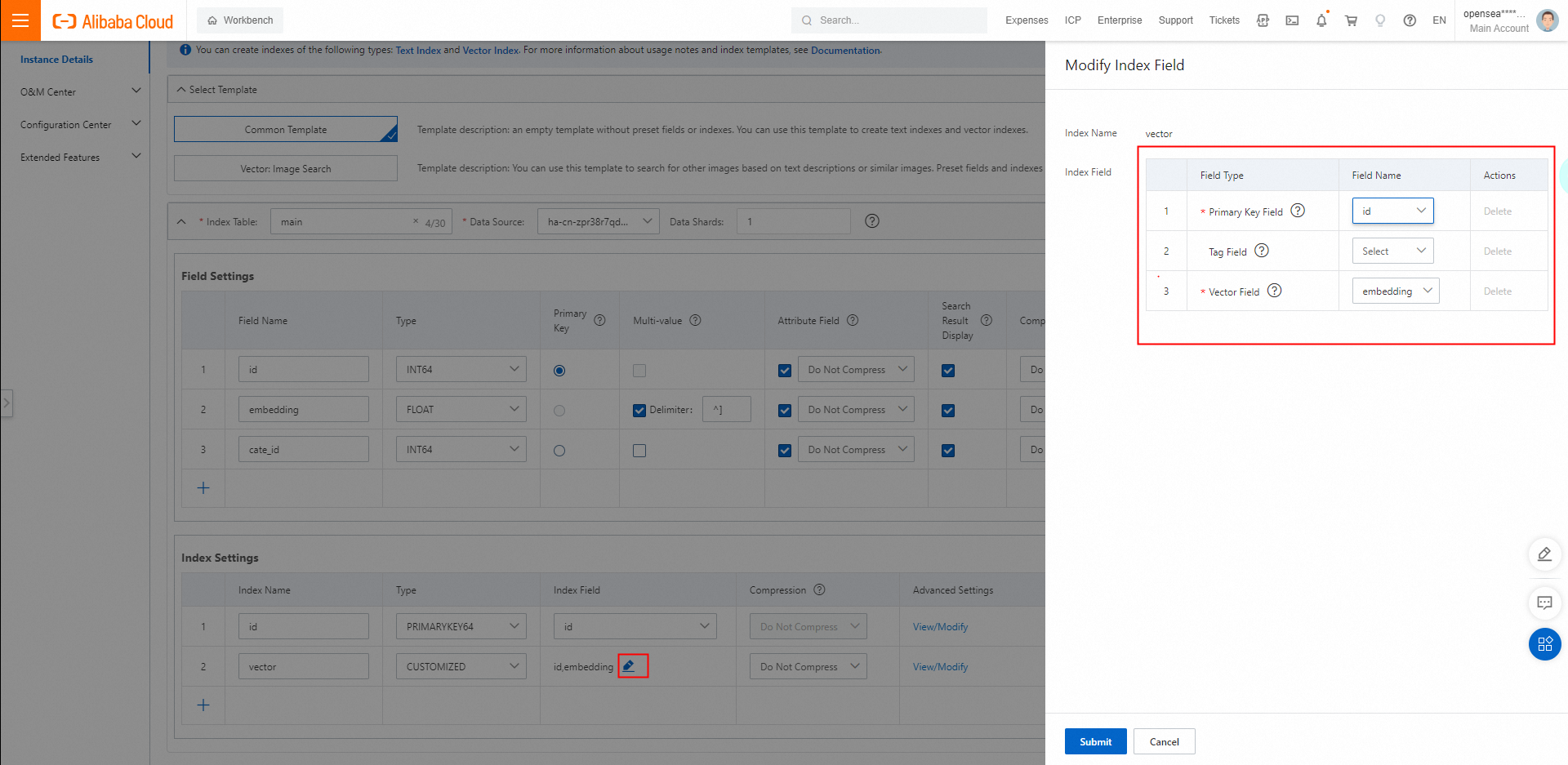
主キーフィールドとベクトルフィールドは必須です。カテゴリフィールドはオプションであり、空のままにすることができます。
3 つの固定フィールドのみを選択でき、新しいフィールドを追加することはできません。
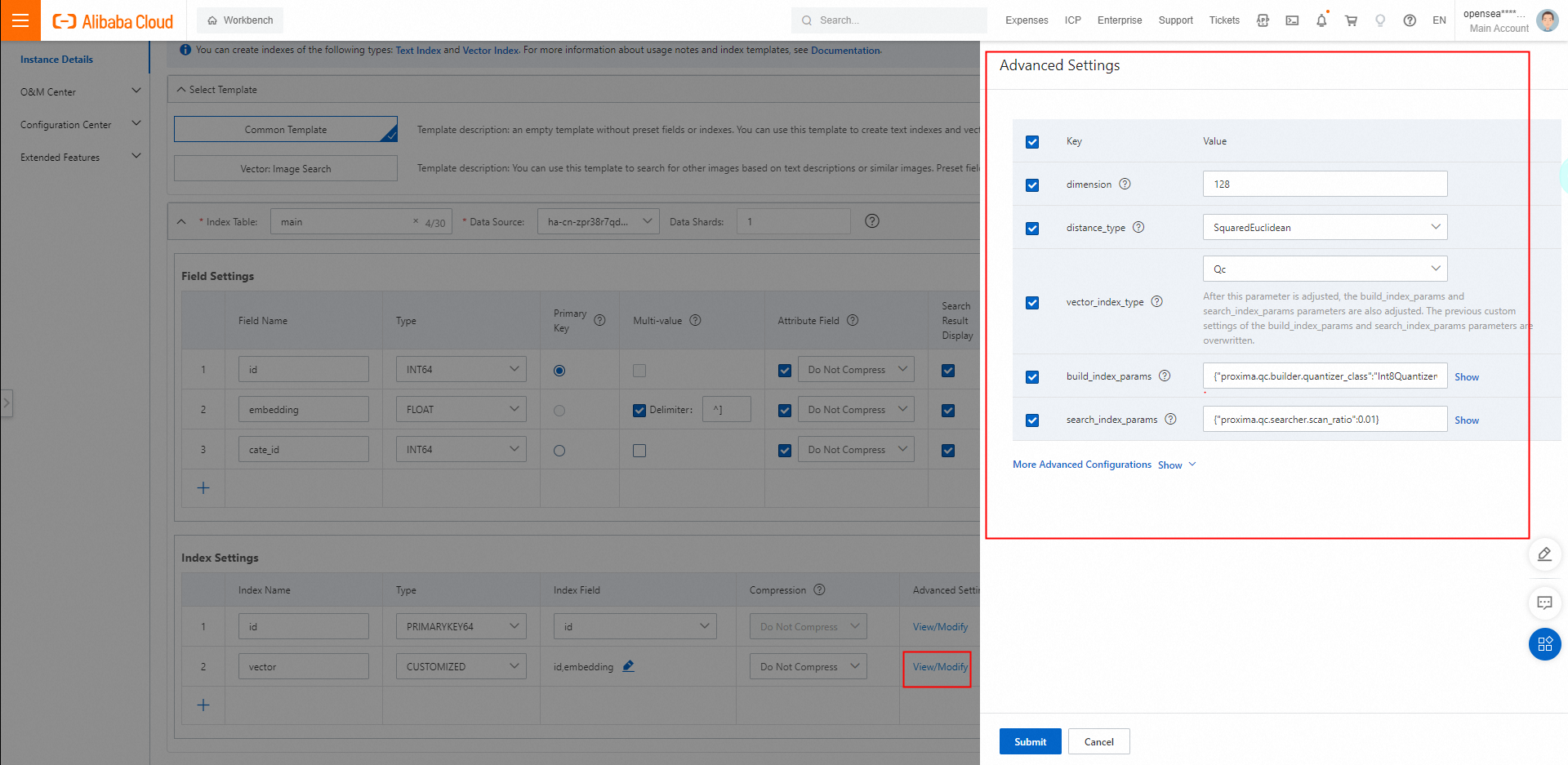
3.2. 詳細設定の構成。ベクトルインデックスのパラメーターを構成する必要があります。次の図は例を示しています。詳細については、ベクトルインデックスを参照してください。
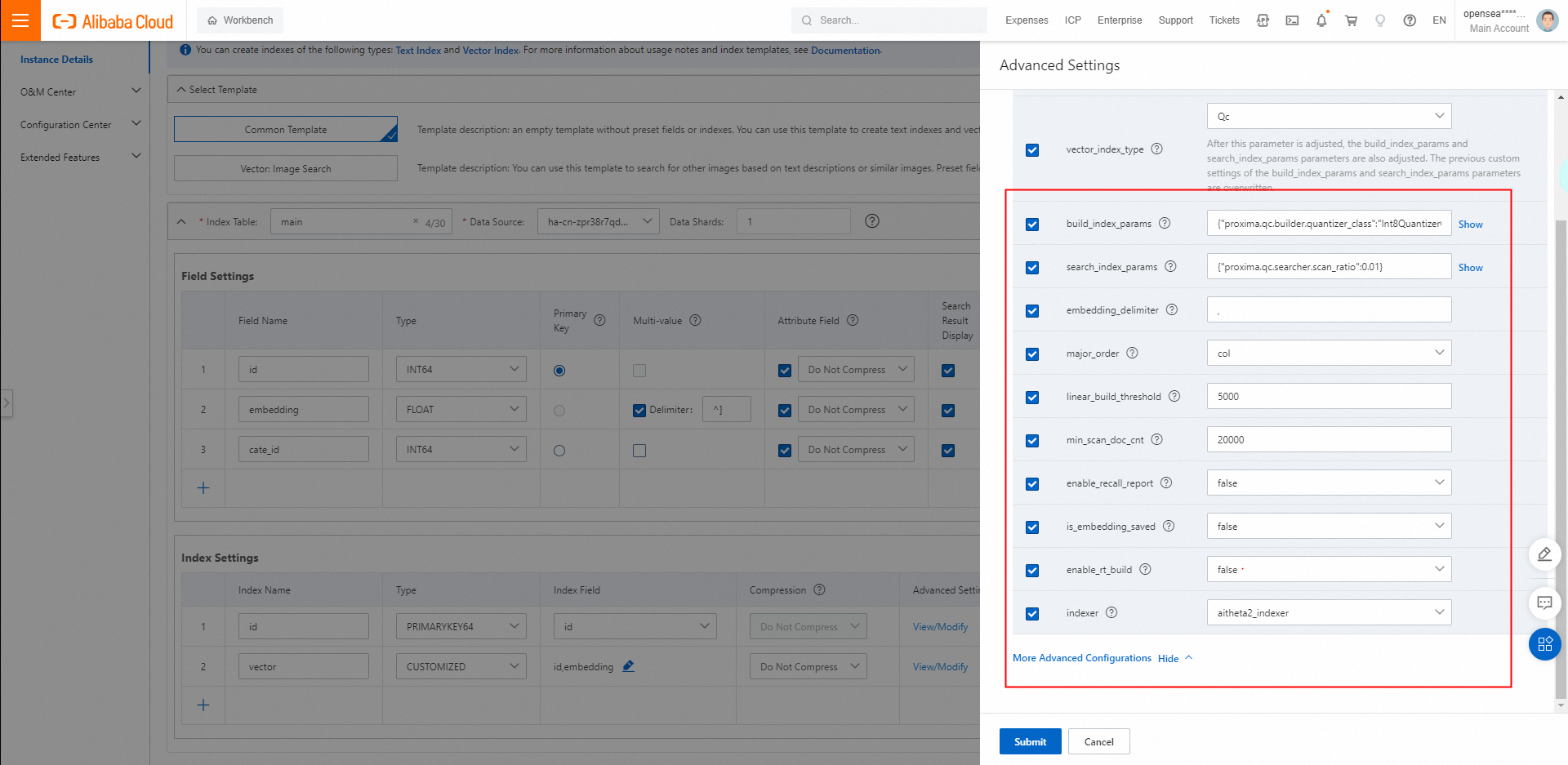
次の図は、さらに多くのパラメーターを示しています。
次のサンプルコードは、build_index_params パラメーターの設定方法の例を示しています。
{
"proxima.qc.builder.quantizer_class": "Int8QuantizerConverter",
"proxima.qc.builder.quantize_by_centroid": true,
"proxima.qc.builder.optimizer_class": "BruteForceBuilder",
"proxima.qc.builder.thread_count": 10,
"proxima.qc.builder.optimizer_params": {
"proxima.linear.builder.column_major_order": true
},
"proxima.qc.builder.store_original_features": false,
"proxima.qc.builder.train_sample_count": 3000000,
"proxima.qc.builder.train_sample_ratio": 0.5
}次のサンプルコードは、search_index_params パラメーターの設定方法の例を示しています。
{
"proxima.qc.searcher.scan_ratio": 0.01
}システムはベクトルインデックスのパラメーターを自動的に構成します。特別な要件がない場合は、[OK] をクリックして構成を完了できます。
構成が完了したら、[バージョンの保存] をクリックします。表示されるダイアログボックスで、説明を入力し、公開 をクリックします。説明は任意です。
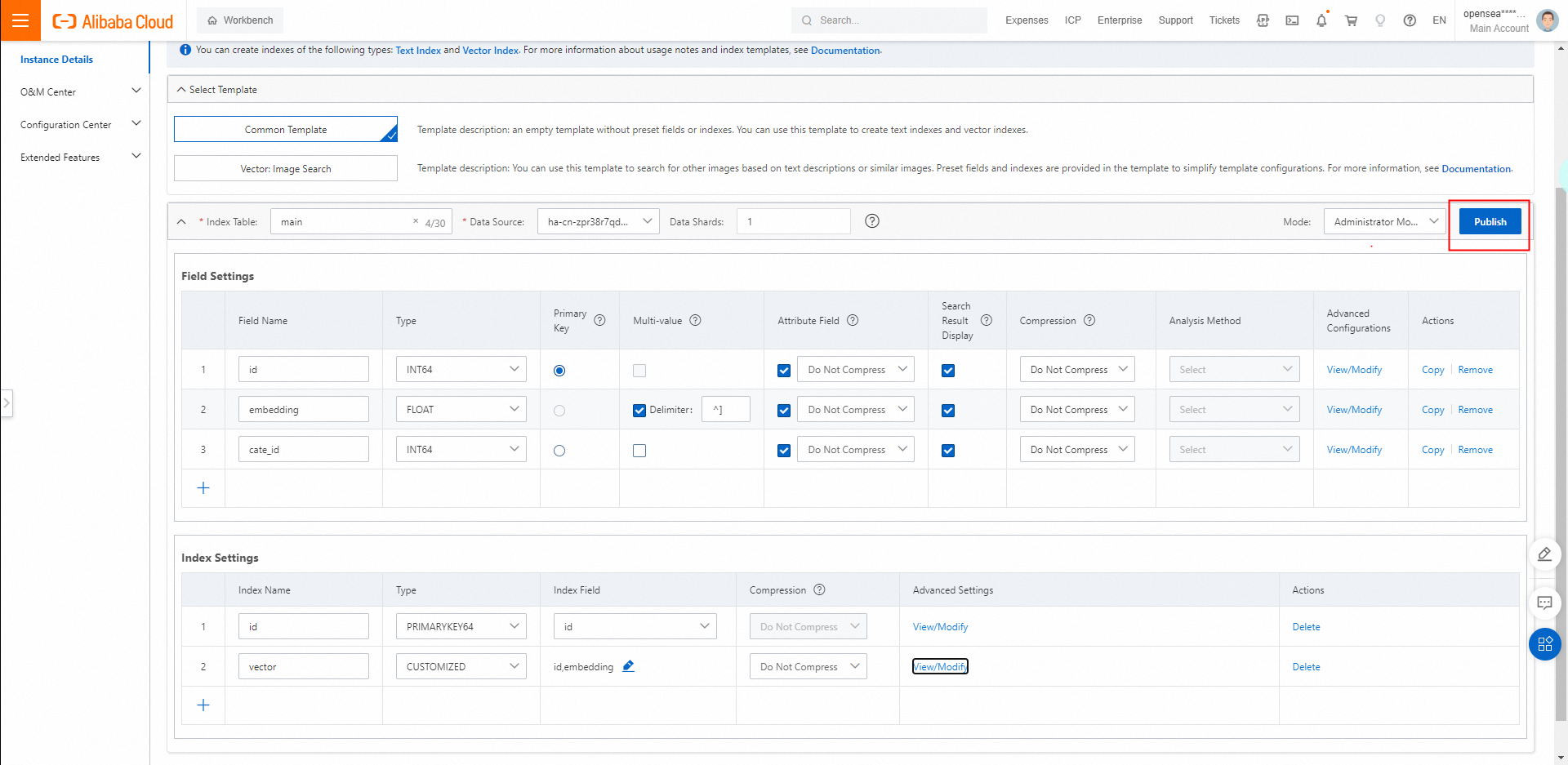
インデックスが公開されたら、[次へ] をクリックしてインデックスを再構築します。
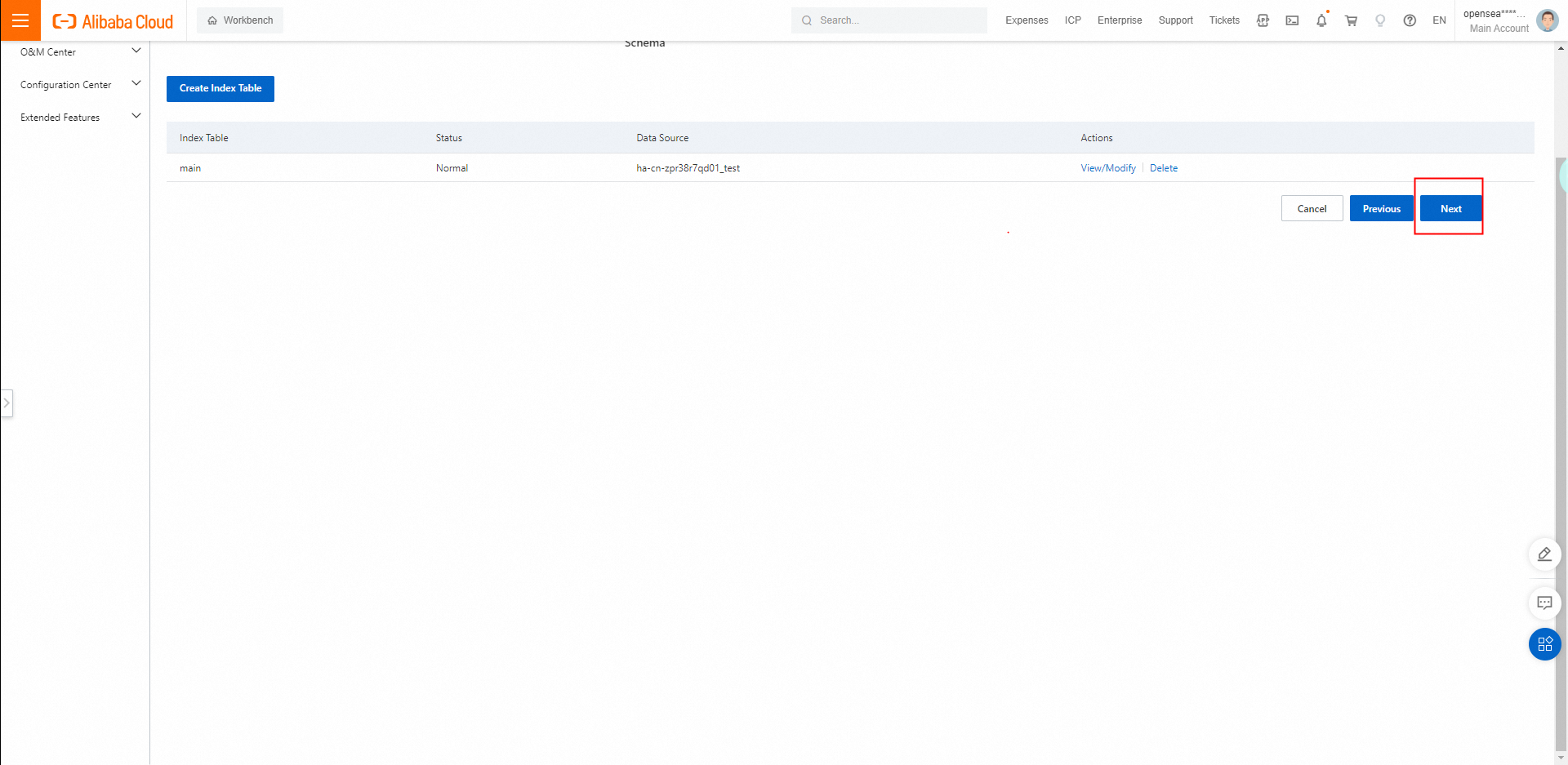
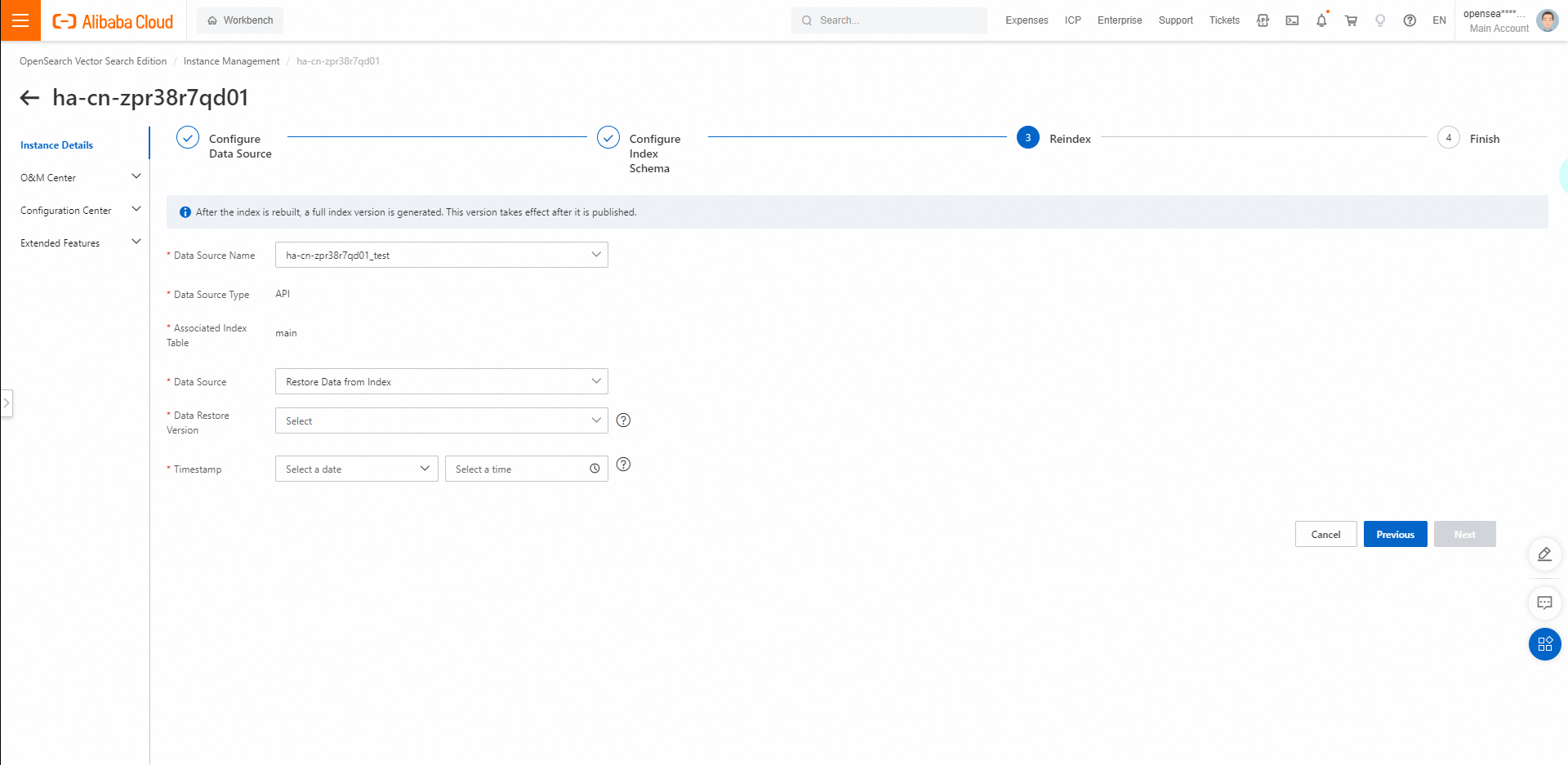
インデックスを再構築します。インデックスの再構築要件に基づいてパラメーターを構成し、[次へ] をクリックします。
APIデータソース
MaxComputeデータソース
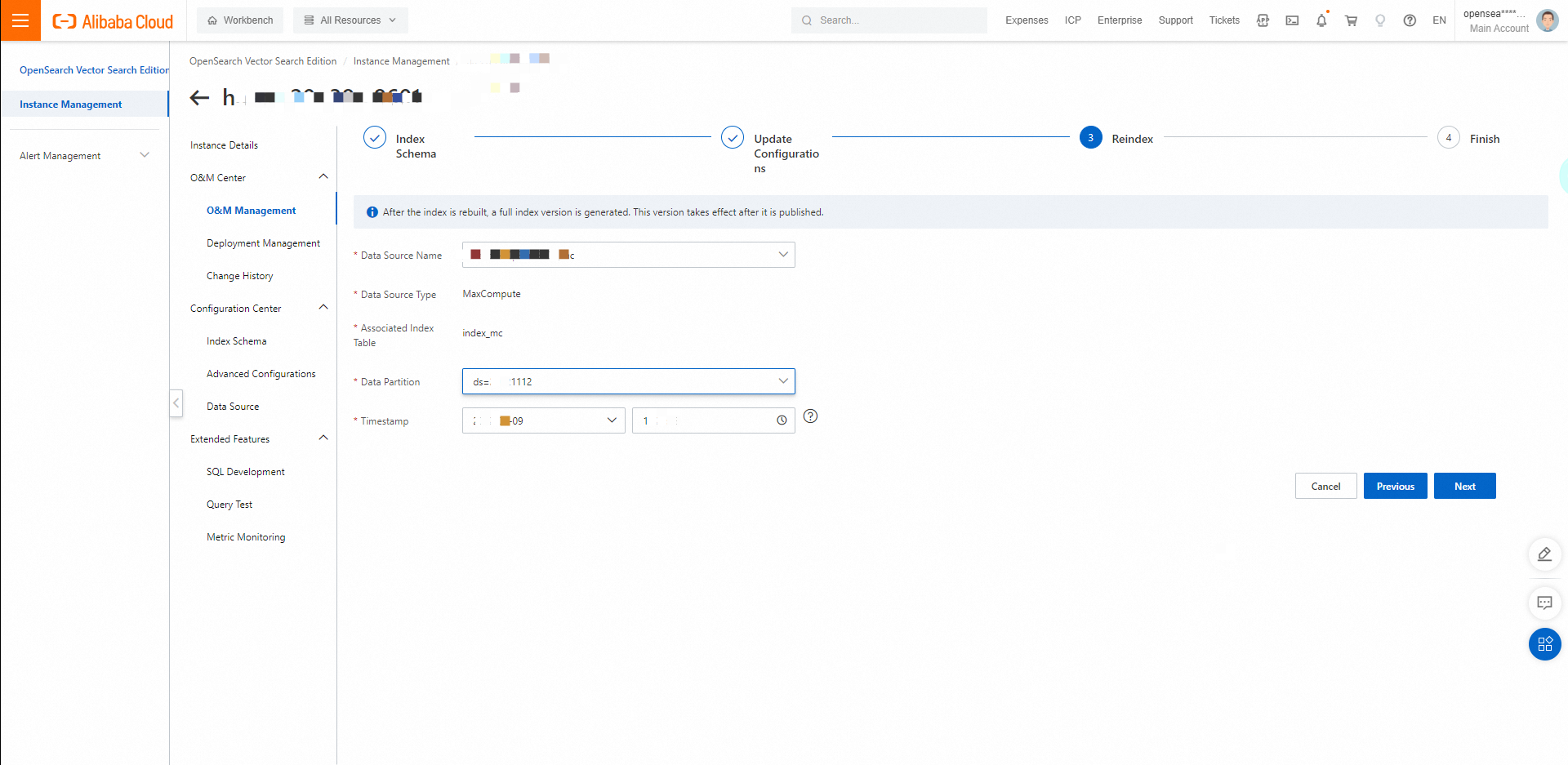
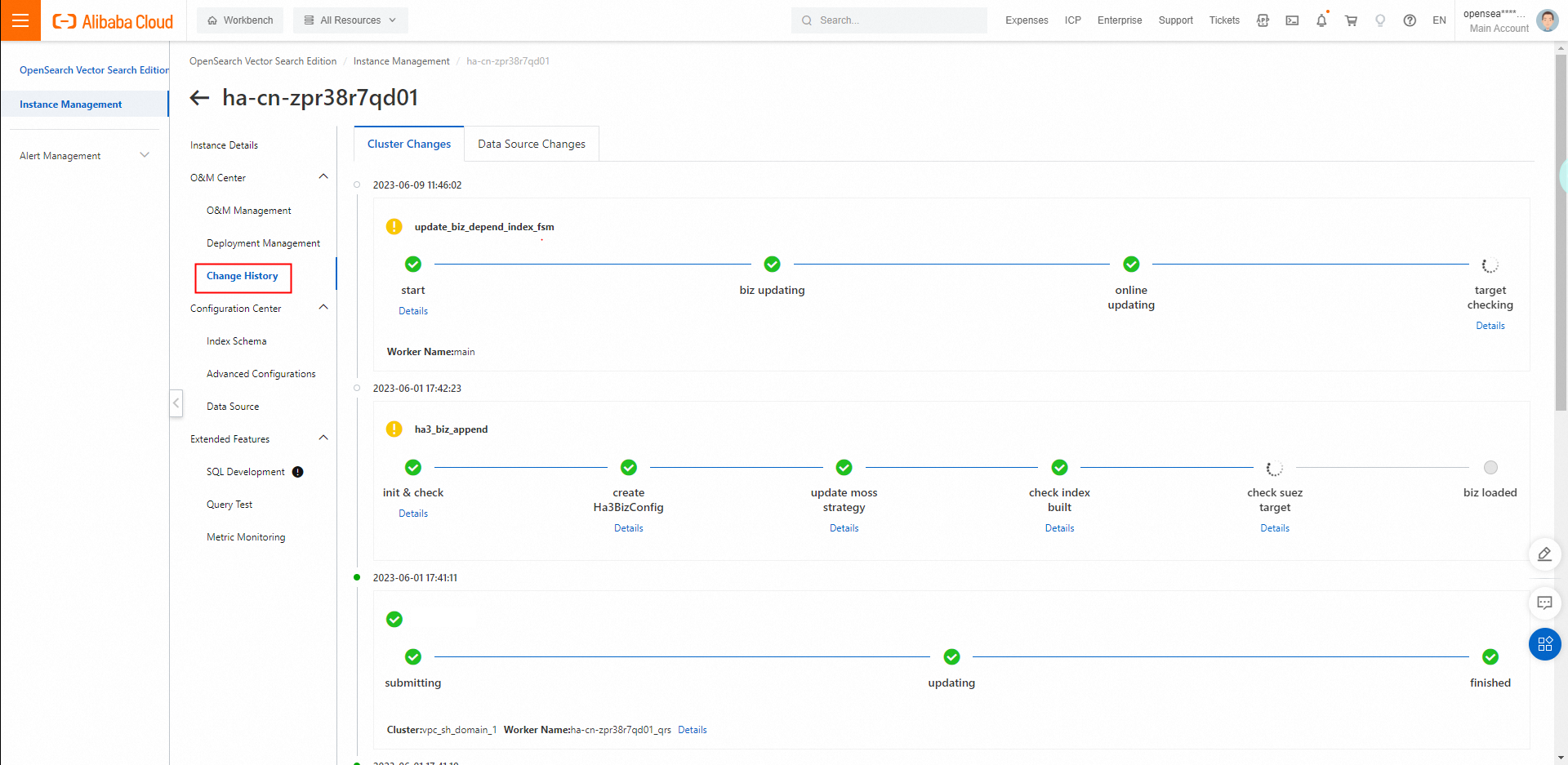
左側のナビゲーションペインで、[O&Mセンター] > [変更履歴] を選択し、[データソースの変更] タブをクリックします。[データソースの変更] タブで、再インデックス作成の進捗状況を確認できます。再インデックス作成が完了したら、クエリテストを実行できます。
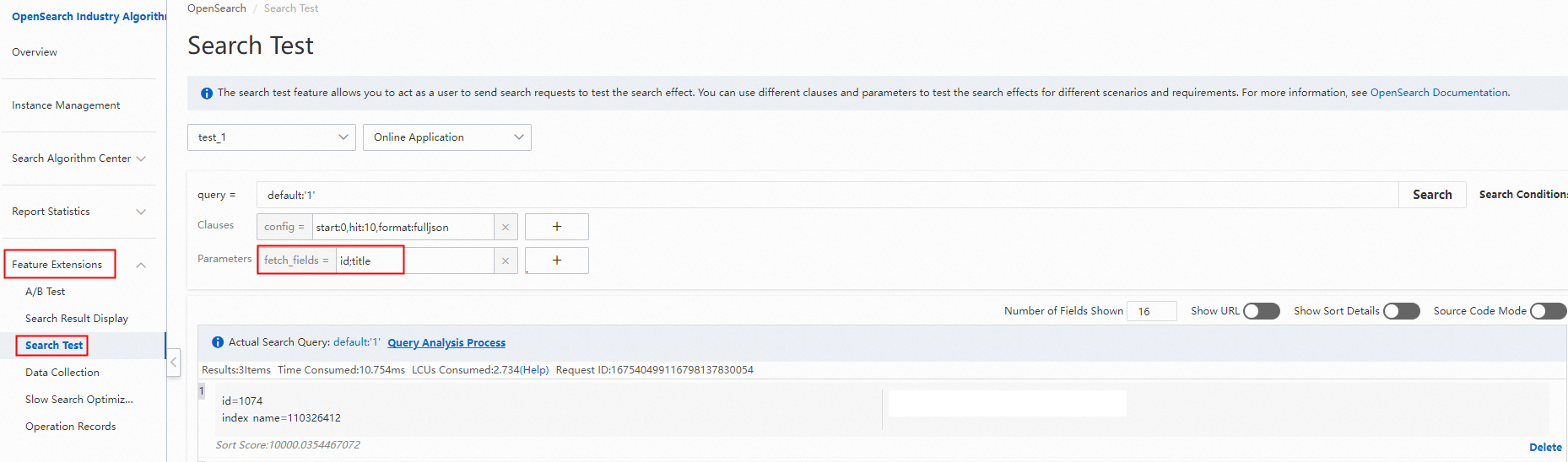
クエリテストページでテストを実行します。
クエリの構文
通常のクエリの構文
HA3構文
query=index_name:'0.1,0.2,0.98,0.6;0.3,0.4,0.98,0.6...'
// 注: index_name パラメーターはベクトルインデックスの名前を指定します。コロン (:) の後にクエリするベクトルを指定します。SQL構文
query=select proxima_score('index_name') as score,id from table_name where MATCHINDEX('index_name', ?) order by score asc limit 5&&kvpair=timeout:1000,iquan.plan.cache.enable:true;urlencode_data:false;iquan.plan.prepare.level:jni.post.optimize;dynamic_params:[["0.892704,0.783731"]]
// 注: index_name パラメーターはベクトルインデックスの名前を指定します。kvpair 句の dynamic_params パラメーターは、クエリ対象のベクトルを指定します。上位 n 個のベクトルをクエリする構文
HA3構文
query=index_name:'0.1,0.2,0.98,0.6;0.3,0.4,0.98,0.6&n=10'
// 注: index_name パラメーターはベクトルインデックスの名前を指定します。コロン (:) の後、アンパサンド (&) の前にクエリ対象のベクトルを指定します。n パラメーターは返される上位 n 個のベクトルを指定します。
SQL構文
query=select proxima_score('index_name') as score,id from table_name where MATCHINDEX('index_name', ?) order by score asc limit 5&&kvpair=timeout:1000,iquan.plan.cache.enable:true;urlencode_data:false;iquan.plan.prepare.level:jni.post.optimize;dynamic_params:[["0.892704,0.783731&n=10"]]
// 注: index_name パラメーターはベクトルインデックスの名前を指定します。kvpair 句の dynamic_params パラメーターは、クエリ対象のベクトルを指定します。n パラメーターは、返される上位 n 個のベクトルを指定します。
特定のしきい値を含むクエリの構文
HA3構文
query=index_name:'0.1,0.2,0.98,0.6;0.3,0.4,0.98,0.6&n=10&sf=0.8'
注: index_name パラメーターはベクトルインデックスの名前を指定します。コロン (:) の後、最初のアンド記号 (&) の前に、クエリ対象のベクトルを指定します。sf パラメーターは、システムがドキュメントをフィルタリングする際のしきい値を指定します。
SQL構文
query=select proxima_score('index_name') as score,id from table_name where MATCHINDEX('index_name', ?) order by score asc limit 5&&kvpair=timeout:1000,iquan.plan.cache.enable:true;urlencode_data:false;iquan.plan.prepare.level:jni.post.optimize;dynamic_params:[["0.892704,0.783731&n=10&sf=0.8"]]
取得パラメーターを使用したクエリの構文
HA3構文
query=index_name:'0.1,0.2,0.98,0.6;0.3,0.4,0.98,0.6&n=10&sf=0.8&search_params={"proxima.qc.searcher.scan_ratio":0.001,"proxima.general.searcher.scan_count":10000}'
注: search_params パラメーターは、ベクトル検索用に構成するパラメーターを指定します。値は JSON 形式である必要があります。 proxima.qc.searcher.scan_ratio パラメーターの詳細については、「ベクトルインデックス」トピックの「パラメーターの説明」セクションを参照してください。 proxima.general.searcher.scan_count パラメーターは、min_scan_doc_cnt パラメーターと同等です。
注: n、sf、および search_params パラメーターの順序は変更できません。SQL構文
query=select proxima_score('index_name') as score,id from table_name where MATCHINDEX('index_name', ?) order by score asc limit 5&&kvpair=timeout:1000,iquan.plan.cache.enable:true;urlencode_data:false;iquan.plan.prepare.level:jni.post.optimize;dynamic_params:[["0.892704,0.783731&n=10&sf=0.8&search_params={"proxima.qc.searcher.scan_ratio":0.001,"proxima.general.searcher.scan_count":10000}"]]
// 注: index_name パラメーターは、ベクトルインデックスの名前を指定します。kvpair 句の dynamic_params パラメーターは、クエリするベクトルを指定します。search_params パラメーターは、ベクトル検索用に構成するパラメーターを指定します。値は JSON 形式である必要があります。proxima.qc.searcher.scan_ratio パラメーターの詳細については、「ベクトルインデックス」トピックの「パラメーターの説明」セクションを参照してください。proxima.general.searcher.scan_count パラメーターは、min_scan_doc_cnt パラメーターと同等です。
// 注: n、sf、および search_params パラメーターの順序は変更できません。ベクトルインデックスにカテゴリフィールドが設定されている場合は、クエリ構文にカテゴリフィールドを含める必要があります。そうしないと、データを取得できません。例:
query=select proxima_score('vector_index_name') as score, cate_id from table_name where MATCHINDEX('vector_index_name', ?) &&kvpair=timeout:1000,iquan.plan.cache.enable:true;urlencode_data:false;iquan.plan.prepare.level:jni.post.optimize;trace:INFO;formatType:json;dynamic_params:[["168#0.01747940666973591,-0.03125246614217758,-0.03254068270325661..."]]dynamic_params パラメーターでは、168 はカテゴリフィールドの値を示します。カテゴリフィールドの値と値の後のコンテンツは、番号記号(#)で区切ります。
SDK を使用してベクトルベースの検索を実行する
次の依存関係を追加します。
pip install alibabacloud-ha3engine検索デモ:
from alibabacloud_ha3engine import models, client
from alibabacloud_tea_util import models as util_models
from Tea.exceptions import TeaException, RetryError
def search():
Config = models.Config(
endpoint="",
instance_id="",
protocol="http",
access_user_name="",
access_pass_word=""
)
# リクエストの完了に時間がかかる場合、このパラメータを設定してリクエストの待機時間を増やすことができます。単位:ミリ秒。
# このパラメータは、search_with_options メソッドで使用できます。
runtime = util_models.RuntimeOptions(
connect_timeout=5000,
read_timeout=10000,
autoretry=False,
ignore_ssl=False,
max_idle_conns=50
)
# OpenSearch Vector Search Edition クライアントを初期化します。
ha3EngineClient = client.Client(Config)
optionsHeaders = {}
try:
# 例 3: OpenSearch Vector Search Edition で SQL クエリ文字列を使用してデータをクエリします。
# =====================================================
sql_str = '''query=select proxima_score('index_name') as score,id from table_name where MATCHINDEX('index_name', ?) order by score asc limit 5&&kvpair=timeout:1000,iquan.plan.cache.enable:true;urlencode_data:false;iquan.plan.prepare.level:jni.post.optimize;dynamic_params:[["0.892704,0.783731&n=10"]]'''
sqlsearchQuery = models.SearchQuery(sql=sql_str)
sqlSearchRequestModel = models.SearchRequestModel(optionsHeaders, sqlsearchQuery)
sqlstrSearchResponseModel = ha3EngineClient.search(sqlSearchRequestModel)
print(sqlstrSearchResponseModel)
except TeaException as e:
print(f"send request with TeaException : {e}")
except RetryError as e:
print(f"send request with Connection Exception : {e}")
if(__name__ == "__main__"):
search()