このトピックでは、Model Studio API のレート制限メカニズムについて説明し、スループットを向上させ、サービス可用性を確保するための、さまざまなシナリオに応じたトラフィック制御戦略を提案します。
Model Studio API は、リクエスト数、トークン使用量、および時間経過に伴う増加率を制限します。これはレート制限と呼ばれます。大規模言語モデル (LLM) サービスはレイテンシーが長く、リクエスト数とトークン量の両方を制限する2次元レート制限を使用します。従来のエラー時のリトライ戦略はこれらのサービスには効果がないため、特定のトラフィック制御策を実装する必要があります。
このトピックでは、実装コストの低い順に 3 種類のソリューションを紹介します。
プラットフォーム設定ソリューション (コード変更なし):クォータ制限の引き上げ、PTU、Batch API。
クライアント側のトラフィック制御戦略 (クライアントコードの変更):エンジニアリングの複雑さが増す順に 4 つの戦略を紹介します。基本的なリトライから適応型輻輳制御までです。
アーキテクチャレベルのフォールバックソリューション (システムアーキテクチャーの変更):モデルフォールバックとメッセージキュー (MQ) を利用したピークシフト。
現在 429 エラーのトラブルシューティングを行っている場合は、「エラー診断と推奨戦略」に進み、原因を特定してください。
プラットフォームのレート制限メカニズム
レート制限は、ルートアカウントレベルで各モデルごとに個別に計算されます。レート制限がトリガーされた後、サービスは通常 1 分以内に再開します。各モデルの具体的なレート制限条件と現在の使用量については、「レート制限」および「モデルのモニタリング」をご参照ください。Model Studio API には、以下の 3 種類のレート制限ルールが含まれています。
分単位のクォータ制限 (RPM / TPM):1分あたりの最大リクエスト数 (RPM) と1分あたりの最大トークン使用量 (TPM)。
瞬間的な頻度制限 (RPS / TPS):1秒あたりの最大リクエスト数 (RPS) と1秒あたりの最大トークン使用量 (TPS)。1秒以内に API 呼び出しやトークン消費が集中すると、レート制限がトリガーされる可能性があります。
増加率制限 (トラフィックバースト):リクエスト量やトークン使用量が急増すると、レート制限がトリガーされます。しきい値はサービスの状況に応じて動的に調整されます。リクエスト量を徐々に増やすことで、この制限のトリガーを回避できます。
これらのレート制限メカニズムに基づき、以下のセクションではプラットフォーム設定、クライアント側のトラフィック制御、およびアーキテクチャレベルのフォールバックソリューションについて説明します。
エラー診断と推奨戦略
同じエラーコードが異なるレート制限ディメンションによってトリガーされることがあります。さらに、高い同時実行性下でのサーバー飽和も、レスポンスの遅延やタイムアウトにつながる可能性があります。この問題は、このトピックで後述する適応型輻輳制御戦略を使用して緩和できます。
エラーコード (DashScope / OpenAI) | トリガーディメンション | 特徴診断 | 推奨戦略 |
Throttling.RateQuota / limit_requests | リクエストレート超過 | 断続的なエラー。成功率は時間とともに低下します。 | トークンバケット:単位時間あたりのリクエストクォータを制御します。 |
リクエストレート超過 | 起動時や同時実行数の急増時にエラーが集中します。 | 同時実行セマフォまたは平滑化レートリミッター:リクエスト間の間隔を広げます。 | |
Throttling.AllocationQuota / insufficient_quota | トークン使用量超過 | 長文テキスト処理時に断続的なエラーが発生します。 | デュアルトークンバケット:RPM と TPM の両方のクォータを同時に制限します。 |
トークン使用量超過 | 長文テキストの並行処理中に瞬間的なトークン消費量が高すぎます。 | ||
Throttling.BurstRate / limit_burst_rate | トラフィック増加率超過 | 起動後またはアイドル状態からの復帰後に、突然大量のリクエストが発生します。 | スロースタートを実装するために、 |
プラットフォーム設定ソリューション
以下のソリューションは、プラットフォーム側の設定やリソース調整を通じて、レート制限の問題を緩和または解消するのに役立ちます。
クォータ制限の引き上げ
デフォルトのクォータが不十分な場合、Model Studio コンソールでモデルの一時的なレート制限クォータを直接引き上げることができます。変更はすぐに有効になります。この機能は現在、中国 (北京) およびシンガポールリージョンでサポートされています。
シナリオ:ビジネスの成長によりデフォルトの RPM/TPM クォータが不十分な場合、または短期的なイベントのために一時的なスループットの増加が必要な場合。詳細については、「レート制限」をご参照ください。
クォータの引き上げは簡単です。クライアント側のトラフィック制御戦略を試す前に、このオプションを評価してください。
Provisioned Throughput Unit (PTU)
PTU サービスは、専用の予約済みコンピューティング能力を提供します。これは、リアルタイムで高いスループット要件を満たし、パブリックリソースプールでのコンピューティング能力の競合を回避するための推奨ソリューションです。
このソリューションは、サービスレベルアグリーメント (SLA) のコミットメントなど、ビジネスに確定的なスループット要件がある場合や、複雑なクライアント側のトラフィック制御開発なしで安定した高いスループットを達成したい場合に適しています。
PTU は予約済みリソースであり、完全に使用されていない場合でも継続的に課金されます。リソースの無駄を避けるために、実際のピークビジネス負荷に基づいて必要な仕様を評価してください。
非同期バッチ処理 (Batch API)
データクレンジングやバッチ分析など、厳密なリアルタイム要件がないタスクについては、Batch API を使用してバッチ処理のために送信できます。これらのタスクはオフピーク時に実行され、結果を非同期で提供し、リアルタイムのオンラインリクエスト頻度やトラフィック制限の対象にはなりません。
このソリューションは、データアノテーション、ログ分析、バッチ要約生成など、数時間から数日の結果返却時間を許容できるオフラインタスクに適しています。Batch API のコストは、通常、リアルタイム API 呼び出しよりも低くなります。
Batch API の結果返却時間は保証されていません。即時の応答を必要とするオンラインサービスには適していません。タスクを送信した後、ポーリングまたはコールバックを通じて結果を取得する必要があります。
クライアント側のトラフィック制御戦略
プラットフォーム設定ソリューションでニーズを満たせない場合は、クライアント側にトラフィック制御メカニズムを導入する必要があります。基本原則は、バーストトラフィックがレート制限をトリガーするのを避けるため、タイムウィンドウ内でリクエストを可能な限り均等に分散させることです。システムが起動したときや長時間のアイドル状態の後には、最大レベルを即座に使用するのではなく、同時実行レベルを徐々に上げる必要があります。
以下の 4 つの戦略は、エンジニアリングの複雑さが増す順にリストされています。各戦略は、前の戦略の機能を含み、それらを強化します。
基本的なリトライは受動的な防御のみを提供します。
リクエストレート制限はアクティブなキューイングを追加します。
トラフィックシェーピングはさらにトークンレベルの制御とスムーズな送信を導入します。
適応型輻輳制御はリアルタイムのフィードバックに基づいて送信レートを動的に調整します。
ビジネスニーズを満たす最も実装コストの低い戦略を選択してください。
各戦略のスループット性能比較
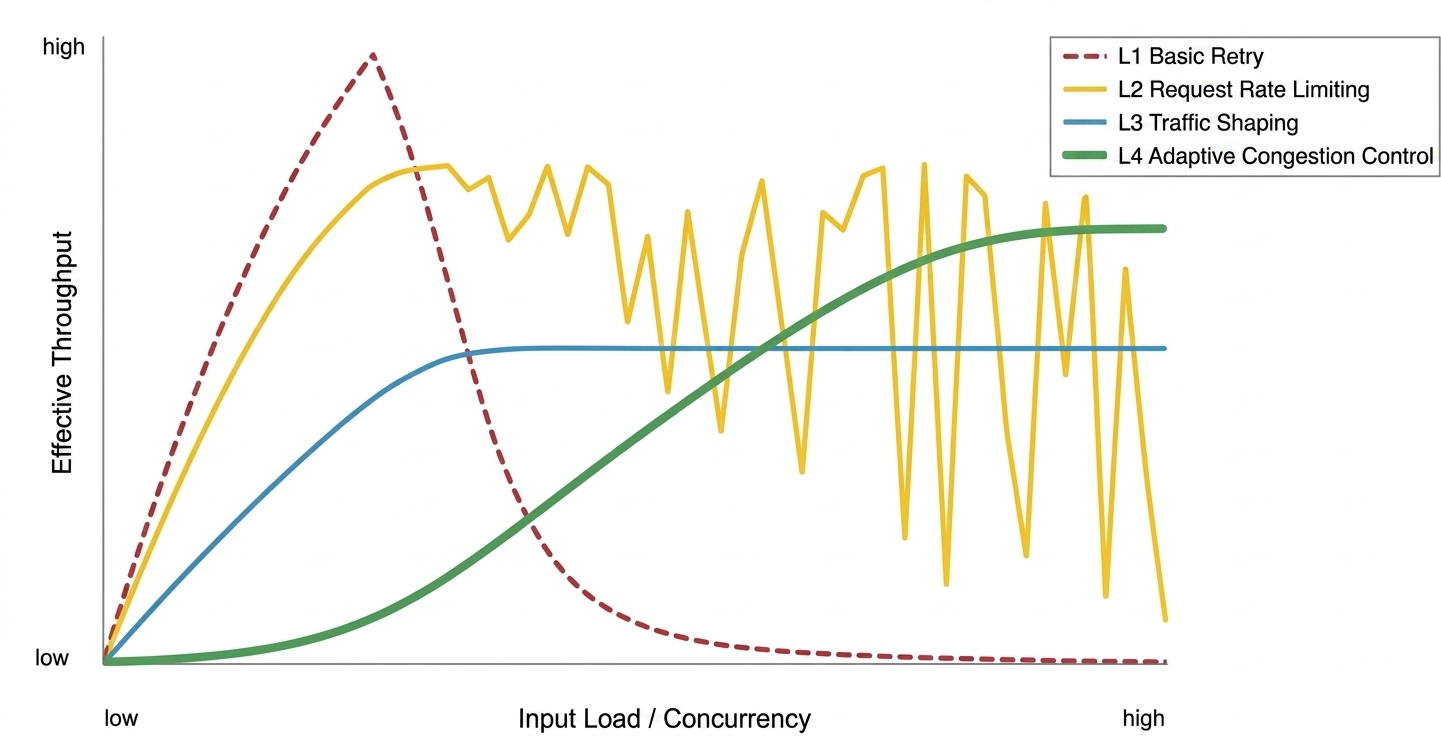
以下は、異なる負荷下での 4 つのクライアント側トラフィック制御戦略の有効スループット性能を比較したものです。
基本的なリトライ戦略:低負荷下では効果的です。高い同時実行性下では輻輳崩壊を起こしやすく、スループットが急激に低下する原因となります。
リクエストレート制限戦略:輻輳崩壊に対する強力な保護を提供します。しかし、長文テキストを含む混合ワークロード下では、トークン制御がないため、スループットはのこぎり状の変動を示します。
トラフィックシェーピング戦略:高い安定性を持ちます。一部のピークスループットを犠牲にすることで、スムーズな出力を実現します。
適応型輻輳制御戦略:高負荷下で安定した高いスループットポイントに動的に収束できますが、コールドスタート時の探索オーバーヘッドがあります。
基本的なリトライ戦略
この戦略は、個人テスト、ローカルスクリプト、低頻度のバックグラウンドタスクなど、高い同時実行性を伴わないシナリオに適しています。デフォルトでは送信レートを制限しません。429 または 5xx エラーを受け取った場合にのみ、ランダムジッター付きのエクスポネンシャルバックオフリトライをトリガーします。
この戦略には積極的なトラフィック制御がありません。マルチスレッドの同時実行下では、レート制限を容易にトリガーし、多くのリクエストが滞留して失敗する原因となります。
上記のコードでは、固定間隔のリトライではなく、エクスポネンシャルバックオフを使用しています。固定間隔のリトライ (例えば、失敗したすべてのリクエストを 3 秒後にリトライするなど) は、すべてのリクエストが同時に再送信される原因となります。これにより、再びレート制限がトリガーされ、持続的な輻輳につながる可能性があります。ランダムジッター付きのエクスポネンシャルバックオフは、リトライを「分散」させます。
待機時間が段階的に倍増:例えば、
1s, 2s, 4s...のようにします。これにより、短時間での繰り返しリクエストを回避します。ランダムジッターの追加:
2s +/- 0.5sのようにランダムな値を導入することで、リトライのトラフィックを分散させます。これにより、多くのリクエストが同時にリトライして二次的なフラッド (サンダーリングハード効果) を引き起こすのを防ぎます。
これにより、システムは「失敗→一斉リトライ→再失敗」という悪循環に陥ることなく、分散的に回復できます。
リクエストレート制限戦略
実際のビジネストラフィックに対しては、受動的なリトライだけに頼るのでは不十分です。頻繁なリトライはレスポンスレイテンシーを大幅に増加させます。リクエストレート制限戦略は、アクティブなトラフィック制御を導入します。リクエストを送信する前に自己チェックと調整を行い、大量の無秩序なリクエストの流入を、プラットフォームの RPM 制限に準拠したスムーズなキューに整理します。レート制限がトリガーされた後、回復には通常時間がかかります。リクエストのリズムを積極的に平滑化することで、小さく制御可能なキューイング遅延が発生します。しかし、これは受動的な「エラー→待機→リトライ」ループで費やされる時間よりもはるかにコストが低いです。要するに、予測不能な大きな遅延を避けるために、小さく予測可能なコストを負担するということです。
この戦略は、チャットボットやその他の軽量なリクエスト・レスポンス型のインタラクションなど、最初のトークンまでの時間 (TTFT) に敏感なオンラインサービスに適しています。
この戦略は、クライアント側で 2 段階の制御を持つアクティブなキューイングを実装します。
RPM トークンバケット:1分あたりの総リクエスト数を制限します。バケットの容量は RPM クォータであり、トークンは一定のレートで補充されます。この方法は借用をサポートします。トークンが不十分な場合、リクエストは将来のクォータから借用できますが、厳密に先入れ先出し (FIFO) の順序に従う必要があります。
同時実行セマフォ:同時リクエスト数を制限します。非同期セマフォが処理中のリクエストを制御し、瞬間的な高い同時実行性が RPS 制限をトリガーするのを防ぎ、クライアントの過負荷を回避します。
これら 2 段階の制御は、まず RPM トークンを取得し、次に同時実行セマフォを取得するという厳密な順序で実行する必要があります。同時実行スロットは希少なリソースであり、実行条件を満たしたリクエストにのみ割り当てるべきです。順序が逆 (スロットを先に占有し、次にトークンを待つ) の場合、高負荷下でhead-of-line ブロッキングを容易に引き起こす可能性があります。リクエストがスロットを占有しても利用可能なトークンがなく、実行されずに長時間スロットを保持します。すべてのスロットが占有されますが、実際にはリクエストは送信されません。基本原則は、希少なリソースを保持している間は、潜在的に長時間の待機を実行しないことです。
以下のコードでは、トークンバケットをフルの状態 (initial_tokens=rpm_limit) で初期化しています。これは、軽量なオンラインサービスが起動時に即座にリクエストを処理するのに適しています。フルバケットで開始するとレート制限エラーがトリガーされる場合は、初期トークン数を下げることができます。例えば、initial_tokens=0 に設定すると、「空バケットスタート」となり、システムがより緩やかなペースで動作状態に入ることができます。
この戦略はトークン使用量を追跡しません。長文テキストのタスクでは、TPM クォータを使い果たすことでレート制限がトリガーされる可能性があります。
トラフィックシェーピング戦略
リアルタイム RAG インジェスチョンや長文ドキュメントの一括分析など、高く安定したスループットを必要とするバッチ処理シナリオでは、リクエストレート制限戦略には重大なTPM の死角があります。これに対処するため、トラフィックシェーピング戦略はデュアルリソース認識 (RPM & TPM) を提供します。また、送信側にシェーピングメカニズムを導入し、バースト的なトラフィックをピークシフトしてスムーズなフローに変換します。
この戦略は、元のリクエストレート制限戦略を以下の機能で強化します。
デュアルリソース制御 (RPM & TPM):RPM と TPM の両方のトークンバケットを維持します。すべてのリクエストは、送信される前に両方のディメンションのクォータチェックを通過する必要があります。
入力時の事前控除、出力時の事後精算:モデルの出力長はリクエスト前には不明です。TPM トークンバケットは、送信時に入力トークンのみを事前控除します。リクエスト完了後、実際の出力トークンが精算されます。精算時にクォータが不足していても (マイナストークン)、後続のリクエストはトークン数がプラスになるのを待つため、自然にフローレートが平滑化されます。
継続的なウォームアップ:コールドスタート時、トークン発行レートは時間とともに線形に増加し、初期バーストのリスクを排除します。
平滑化レートリミッター (ペーシング):リクエスト間の最小間隔を強制することで送信レートを平滑化し (ペーシング)、レート制限がトリガーされるリスクを低減します。
代替ソリューションの参考:ビジネスが起動時のわずかなキューイング遅延に敏感でない場合は、標準のトークンバケットロジックを再利用 (initial_tokens=0 に設定) することで、クライアントの複雑さを軽減しつつ安全なスタートを実現できます。また、このトピックの Python トークンバケット実装は設計概念を実証するためのものです。本番環境では、Java の Guava の SmoothRateLimiter など、言語のエコシステムから成熟したレート制限コンポーネントを使用してください。
コード例では、平滑化待機は head-of-line ブロッキングによるリクエストバーストを避けるために、同時実行ロックの内側に配置されています。複数のリクエストが待機終了後に同時に同時実行セマフォを競合し、平滑化されたトラフィックが出口で再び輻輳する可能性があります。これにより同時実行効率はわずかに低下しますが、送信間隔の正確な制御が保証されます。
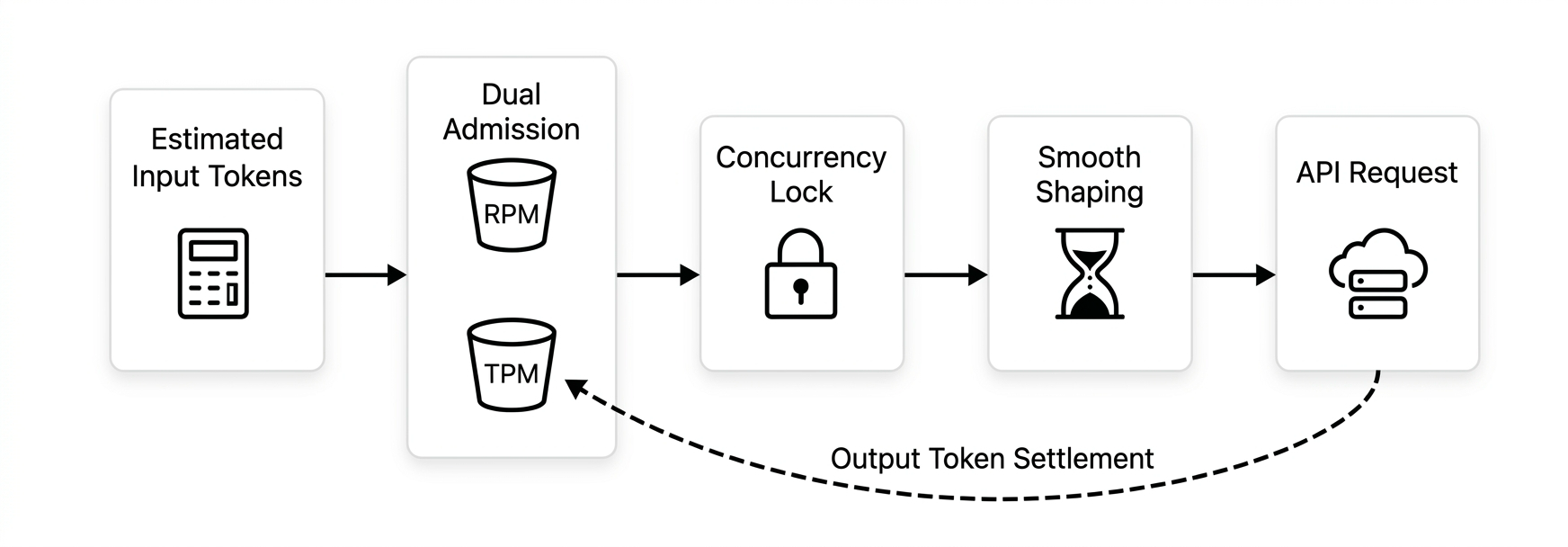
完全なトラフィックシェーピングパイプラインは次のとおりです:入力トークンの推定 → デュアルアドミッション (RPM & TPM) → 同時実行ロック → トラフィックシェーピング → 送信 → 出力トークンの精算。
この戦略は、保守的な平滑化メカニズムのために、理論上の最大同時実行数の一部を犠牲にします。極めて低いレイテンシーを必要とするオンラインサービスには適していません。
適応型輻輳制御戦略
この戦略は、API ゲートウェイ、複雑なプロキシ、マルチテナントシステムなど、大規模で動的な混合負荷シナリオに適しています。
選択のヒント:この戦略は万能のソリューションではありません
適応型輻輳制御戦略の核心的な価値は、非常に不確実で変動の激しいビジネス環境に対応することです。これは万能の選択肢ではありません。
パフォーマンスのパラドックス:定量的なバッチ処理など、ビジネス負荷が予測可能で比較的安定している場合、経験に基づいて最適な静的パラメータを直接設定する方が、通常、「試行と収束」を必要とする動的な探索よりも優れたパフォーマンスを発揮します。
探索のオーバーヘッド:境界を見つけるために、動的アルゴリズムには必然的にコールドスタートのランプアップと探索的な変動が伴います。既知のシナリオでは、この「探索コスト」は不要なパフォーマンス損失です。
メンテナンスコスト:クローズドループのフィードバックメカニズムを導入すると、システムの複雑さとトラブルシューティングの難易度が大幅に増加します。
ビジネスが非常に大規模で、複雑な負荷を持ち、著しい変動性がない限り、よりシンプルな最初の 3 つの戦略のいずれかを選択してください。
リクエストレート制限とトラフィックシェーピング戦略は、静的クォータに基づく古典的な防御戦略です。これらは、安定して予測可能な負荷を持つシナリオで完全に適用可能です。しかし、複雑なゲートウェイレベルのシナリオでは、ビジネスは両側から動的な変化に直面します。下流の負荷は複雑で変動し、高い同時実行性の短いリクエストと長時間実行される深い推論タスクが混在しています。プラットフォームのレート制限しきい値は、秒単位のレート制限と増加率検出のしきい値がサービス状況に基づいて調整されるため、動的に変動します。静的な戦略では、効率と安定性のバランスを取るのが困難です。
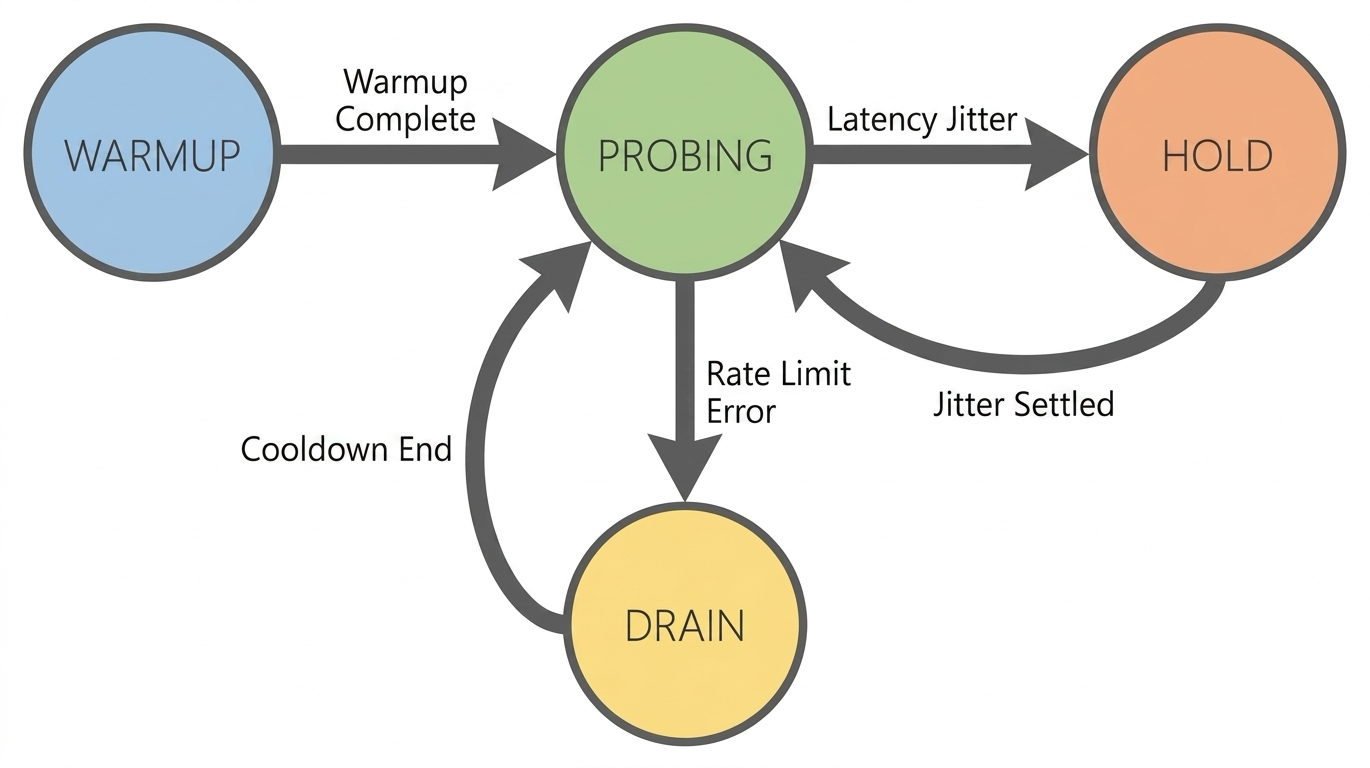
このポリシーは、BBR (Bottleneck Bandwidth and RTT) に着想を得ており、EBP (Elastic Bandwidth Probing) に基づくクローズドループ制御システムを確立します。RPM/TPM クォータを指針となる上限として使用し、このシステムはレイテンシーの変化やレート制限がアクティブかどうかなどのリアルタイムフィードバックに基づいて、スループットを最大化するための最適な送信レートを動的に計算します。
Elastic Bandwidth Probing (EBP):このメソッドは、過去の最高の成功ウォーターマークを保存します。現在の同時実行レベルと最高のウォーターマークとの距離に基づいて、バネの張力をシミュレートして探索ゲインを計算します。距離が遠いほど加速は速く、距離が近いほど減速は遅くなります。飽和度の高い区間でも継続的な境界探索を保証するために、小さな線形推力が追加されます。
TPT 輻輳認識:大規模モデルの生成時間はその長さに比例します。長文テキストの高いレイテンシーは、必ずしも輻輳を示しているわけではありません。TPT (Time Per Token)、つまりトークンあたりの処理時間をメトリックとして使用し、コンテンツ長からのノイズを除去します。TPT が著しく悪化した場合にのみ、計算飽和による輻輳と判断されます。
アンチバーストレートガバナー:EBP によって計算された目標同時実行レベルに関係なく、レートガバナーは同時実行数の増加の加速度を強制的に制限します。これにより、トラフィックがスムーズに増加し、増加率制限をトリガーする可能性のあるステップ状の変化を回避します。
ネイティブ BBR と比較して、この戦略には大規模モデル向けに以下の主要な変更が含まれています。
ガイド付き探索:既知の RPM/TPM クォータを「指針となる上限」として導入し、盲目的な探索による頻繁な衝突を回避します。
信号ソースの変更 (RTT → TPT):ネイティブ BBR は RTT に依存します。しかし、大規模モデルのシナリオでは、コンテンツ長によるレイテンシーの差はネットワークジッターよりもはるかに大きいです。代わりに TPT を使用して、コンテンツ長からの干渉を排除します。
応答メカニズムの強化 (ProbeRTT → Hold):レイテンシーの変動に直面した場合、積極的にバックオフしてスループットを低下させるのではなく、現在の同時実行レベルを維持することを選択します。
ハードレート制限への応答 (Packet Loss → 429 Drain):
429エラーがトリガーされると、即座に積極的な Drain 状態に入り、クールダウン期間後に高速回復を実行します。
この戦略には以下の制限があります。
輻輳信号ノイズ (TPT Noise):現在の TPT は「総レイテンシー / 総トークン数」として大まかに推定されます。総レイテンシーには、ネットワークの往復レイテンシ、キューイング時間、最初のトークンまでの時間が含まれます。ネットワークジッターや長い入力によって水増しされやすく、誤って Hold 状態をトリガーする可能性があります。
大規模リクエストのスターベーション (Starvation Risk):最大のスケジューリング性能を達成するために、この戦略は非厳密な FIFO ウェイクアップメカニズムを使用します。クォータが不足している場合、短いトークンのリクエストが「割り込み」してリソースを先取りし、長いトークンのリクエストが長期間待たされる原因となる可能性があります。
コールドスタート問題:この戦略は、統計モデルを構築するためにウォームアップ期間を必要とします。低負荷または短命のタスクでは、ゼロから探索するため、スループットが最初の 3 つの戦略よりも低くなる可能性があります。
アーキテクチャレベルのフォールバックソリューション
プラットフォーム設定とクライアント側のトラフィック制御でも、可用性やピークスループットに関するビジネス要件を満たせない場合、システムアーキテクチャーレベルでフォールバックメカニズムを導入できます。
モデルフォールバック
プライマリモデルがレート制限やサービス例外により応答できない場合、より寛容なクォータを持つ代替モデルに自動的にフォールバックし、メインプロセスが応答を継続できるようにします。
フォールバックパスの設計原則
異なるシリーズのモデルを選択:Model Studio では、レート制限はモデルごとに個別に計算されます。あるモデルがレート制限された場合、別のモデルをフォールバックとして選択できます。例えば、
qwen3.6-plusからqwen3.6-flashにフォールバックできます。レート制限エラー時のみフォールバックをトリガー:フォールバックは、すべての例外ではなく、
429レート制限エラーに対してトリガーされるべきです。モデルを切り替えても、ネットワークタイムアウトやパラメータエラーなどの問題は解決しません。フォールバックモデルを事前に検証:フォールバック後に機能的な例外を避けるため、フォールバックモデルが Function Calling や構造化出力など、ビジネスで必要な機能をサポートしていることを確認してください。
モデルフォールバックは、クライアント側のトラフィック制御戦略と組み合わせることができます。例えば、リクエストレート制限戦略のリトライメカニズムにフォールバックロジックを統合することができます。リトライが尽きてもレート制限がトリガーされる場合は、フォールバックモデルに切り替えます。
メッセージキュー (MQ) を利用したピークシフト
即時応答を必要としないバックエンドサービスの場合、RabbitMQ や Kafka などのメッセージミドルウェアを導入してピークシフトを行うことができます。バーストトラフィックはまず MQ に書き込まれ、コンシューマー側がレート制限クォータに従って安定したレートでプルして処理します。このアーキテクチャーは、フロントエンドのピークとバックエンドの呼び出しを分離し、根本的にレート制限エラーを防ぐことができます。
シナリオ:チケット処理、コンテンツモデレーション、バッチデータアノテーションなど、ユーザーがタスクを送信した後に非同期通知メッセージを受け入れることができるビジネス。MQ はバッファレイヤーとして機能し、フロントエンドからのトラフィックスパイクを吸収し、コンシューマー側は安定したレートで Model Studio API にリクエストを送信します。
主要なアーキテクチャー設計のポイント:
コンシューマーのレート制御:コンシューマー側は、メッセージを無制限にプルするのではなく、RPM/TPM クォータに基づいて安定したレートでメッセージを消費するために、リクエストレート制限またはトラフィックシェーピング戦略を使用すべきです。
デッドレター処理:複数回のリトライ後に失敗したメッセージは、デッドレターキューに移動し、アラートをトリガーします。これにより、無限リトライが消費をブロックするのを防ぎます。
バックプレッシャーの伝播:MQ のバックログがしきい値を超えた場合、例えばキューイングステータスを返すなどして、上流に圧力を伝播させます。これにより、キューが無限に増大するのを防ぎます。
本番環境での考慮事項
上記のコード例は、Python の asyncio シングルスレッドループに基づいており、コアアルゴリズムを実証することを目的としています。大規模な本番環境に適用する前に、以下の問題を考慮してください。
非テキストモデルへの適応
上記の戦略はテキストモデルを例としていますが、コアとなる制御原則は、画像生成や音声合成などのマルチモーダルモデルサービスにも適用されます。測定単位が異なるだけで、本質は同じです。つまり、送信レートと処理能力を制限することです。
音声認識などのモデルは、通常、単位時間あたりのリクエスト数 (RPM など) と使用量 (音声の持続時間など) の両方によって制約されます。戦略は基本的にテキストモデルと同じです。
画像や動画のモデルは、通常、タスク送信レートと同時タスク数によって制約されます。リクエストレート制限戦略と同じアプローチを使用できます。つまり、タスク送信レートを制限し、セマフォを使用して同時実行数を制御します。
レート制限メトリクスがどのように変化しても、クライアント側のスロットリングの原則は同じです。カウンター (RPM トークンバケットなど) や探索メトリック (TPT など) を対応するモダリティのメトリックに置き換えるだけです。モデルの具体的なレート制限ルールとメトリック定義については、「レート制限」をご参照ください。
並行モデルにおけるアトミック性
実装例:
asyncioはシングルスレッドの協調スケジューリングを使用するため、コード例の状態変更操作は本質的にアトミックであり、単一プロセス内で追加の同時実行保護は必要ありません。本番環境での推奨事項:マルチスレッドまたはマルチプロセス環境で実装する場合、状態更新の正しさを保証するために、トークンバケットと統計ウィンドウの同時実行安全性を確保してください。そうしないと、競合状態がトラフィック制御の失敗を引き起こします。
分散レート制限
実装例:コード例のトラフィック制御コンポーネントはすべてインメモリ実装です。
本番環境での推奨事項:マルチインスタンスの分散デプロイメントでは、各インスタンスが独立してローカルのトラフィック制御を行います。実際の総使用量が制限を超え、グローバルなレート制限がトリガーされる可能性があります。Redis などの集中カウンターを使用して、すべてのノードの使用量を一元的に管理してください。
優先度付きキューとスターベーション防止
実装例:どのコード例も優先度による差別化を実装していません。特に適応型輻輳制御戦略は、最大のスケジューリング性能を達成するために非厳密な FIFO ウェイクアップメカニズムを使用しています。
本番環境での推奨事項:ビジネスに高優先度と低優先度のリクエストがある場合、高優先度リクエストの帯域幅を保証するために重み付き優先度付きキューを実装してください。また、継続的な高負荷時に低優先度キューが完全にスケジューリング不能になるのを防ぐために、低優先度キューに最小限のクォータを予約するスターベーション防止メカニズムを導入してください。