Alibaba Cloud Model Studio の検索拡張生成 (RAG) 機能で、知識の取得が不完全であったり、コンテンツが不正確であったりする場合は、本トピックの提案と例を参照して RAG パフォーマンスを改善してください。
RAG ワークフロー
RAG(検索拡張生成)は、情報検索とテキスト生成を組み合わせた技術です。これにより、モデルが回答生成時に外部ナレッジベースからの関連情報を活用できるようになります。
そのワークフローには、解析とチャンク分割、ベクトルストレージ、取得とリコール、回答生成など、いくつかの重要なステージが含まれます。
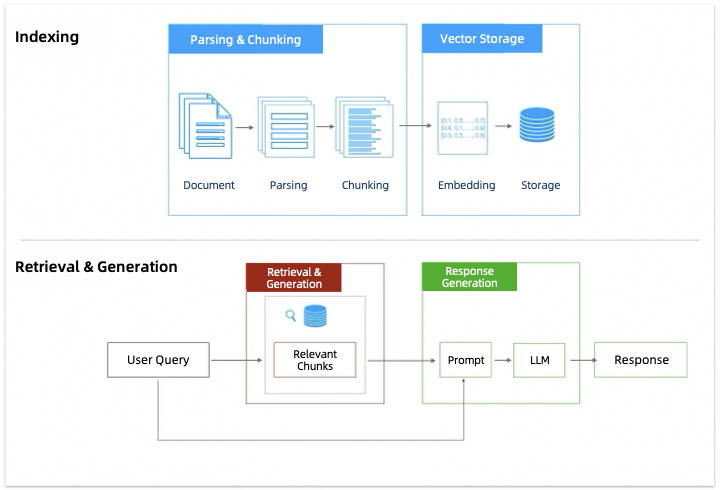
次のセクションでは、解析とチャンク分割、取得とリコール、回答生成の各ステージを最適化するための手法を説明します。
RAG パフォーマンスの最適化
準備
まず、Model Studio ナレッジベース にインポートするドキュメントが、次の要件を満たしていることを確認してください。
-
関連知識を含む: ナレッジベースに関連情報が不足している場合、モデルが関連質問に回答できない可能性があります。これを解決するには、ナレッジベースを更新して必要な知識を追加してください。
-
Markdown フォーマットの使用(推奨): PDF ファイルは複雑なレイアウトを持つことが多く、解析結果が不良になる可能性があります。PDF を Markdown、DOC、DOCX などのテキスト形式に事前に変換してください。たとえば、DashScopeParse を使用して PDF を Markdown に変換し、その後モデルを使用してフォーマットを整理します。「Alibaba Cloud 大規模モデル ACP コース」の RAG の章をご参照ください。
ナレッジベースは、現在ドキュメント内の動画または音声コンテンツを解析できません。
-
明確な表現、合理的な構造、特殊なスタイルの不使用: ドキュメントのレイアウト も RAG パフォーマンスに大きな影響を与えます。詳細については、「RAG の効果を高めるためのドキュメントフォーマット方法」をご参照ください。
-
プロンプト言語との一致: ユーザーのプロンプトが主に英語などの特定の言語で記述されている場合、ドキュメントコンテンツも同じ言語で記述されていることを確認してください。必要に応じて(例:ドキュメント内の専門用語)、2 つ以上の言語を使用できます。
-
エンティティの曖昧性解消: ドキュメント内で同一エンティティの異なる表現を統一します。たとえば、「ML」と「Machine Learning」を「Machine Learning」に標準化できます。
ドキュメントをモデルに入力し、用語を標準化するよう依頼できます。ドキュメントが長い場合は、複数の部分に分割して順次入力してください。
これらのステップを完了した後、RAG アプリケーションの各ステージを最適化します。
解析とチャンク分割
本セクションでは、RAG チャンク分割ステージを最適化するための Model Studio の設定項目のみを説明します。
まず、ナレッジベースはインポートされたドキュメントを解析およびチャンク分割します。チャンク分割の主な目的は、後続のベクトル化プロセス中のノイズを減らしつつ、セマンティック整合性を維持することです。したがって、ナレッジベース作成時に選択するドキュメントチャンク分割戦略は、RAG パフォーマンスに大きな影響を与えます。チャンク分割方法が不適切だと、次の問題が発生する可能性があります。
|
短いチャンク |
長いチャンク |
セマンティック切り捨て |
|
|
|
|
|
短いチャンクはセマンティック情報が不足し、取得が失敗する可能性があります。 |
長いチャンクは無関係なトピックを含み、リコールプロセスでノイズや無関係な情報が返される可能性があります。 |
強制的なセマンティック切り捨てにより、リコール時にコンテンツが欠落する可能性があります。 |



最良の結果を得るには、テキストチャンクをセマンティックに完全に保ちつつ、過剰なノイズを回避してください。Model Studio では、次の方法を推奨しています。
-
ナレッジベース作成時に、ドキュメントチャンク分割方法として インテリジェントチャンク分割 を選択します。
-
ドキュメントをナレッジベースに正常にインポートした後、テキストチャンクのコンテンツを手動で確認・修正します。
インテリジェントチャンク分割
ナレッジベースに最適なテキストチャンク長を選択するのは難しい場合があります。これは、次の複数の要因に依存するためです。
-
ドキュメントタイプ: 専門文献の場合、長いチャンクの方がより多くのコンテキストを保持できることが多いです。ソーシャルメディア投稿の場合、短いチャンクの方がセマンティクスをより正確に捉えられます。
-
プロンプトの複雑さ: 一般に、ユーザーのプロンプトが複雑で具体的な場合は、長いチャンクが必要になることがあります。そうでない場合は、短いチャンクの方が適している場合があります。
これらの結論は必ずしもすべての状況に当てはまるわけではありません。適切なツールを選択し、繰り返し実験して適切なテキストチャンク長を見つける必要があります。たとえば、LlamaIndex は異なるチャンク分割方法の評価機能を提供します。ただし、このプロセスは複雑で時間がかかる場合があります。
迅速かつ効果的なソリューションとして、ナレッジベース作成時に ドキュメントチャンク分割 を インテリジェント分割 に設定してください。

この戦略が適用されると、ナレッジベース:
-
まず、組み込みの文区切り文字を使用してドキュメントを段落に分割します。
-
分割された段落に基づき、固定長ではなくセマンティック関連性(セマンティックチャンク分割)に基づいてチャンク境界を適応的に選択します。
このプロセスにより、各ドキュメント部分のセマンティック整合性が確保され、不要な分割が回避されます。この戦略は、このナレッジベース内のすべてのドキュメント(後からインポートされたドキュメントを含む)に適用されます。
チャンクコンテンツの修正
もちろん、実際のチャンク分割プロセス中にも、予期しない分割やその他の問題が発生する可能性があります(例:テキスト中の スペース がチャンク分割後に %20 として解析される場合など)。

したがって、Model Studio ではドキュメントをインポートした後、チャンクコンテンツのセマンティック整合性と正確性を手動で確認することを推奨しています。予期しないチャンクやその他の解析エラーが見つかった場合は、テキストチャンクを直接編集して修正できます。保存後、テキストチャンクの元のコンテンツは無効になり、新しいコンテンツがナレッジベース取得に使用されます。
この操作はナレッジベース内のテキストチャンクのみを変更し、データ管理(一時ストレージ)内の元のドキュメントまたはデータテーブルは変更しません。したがって、ドキュメントを再度インポートする場合は、手動での確認と修正を再度行う必要があります。
取得とリコール
本セクションでは、取得とリコールステージを最適化するための Model Studio の設定項目のみを説明します。
取得とリコールステージの主な課題は、回答を含むナレッジベースから最も関連性の高いテキストチャンクを見つけることです。
|
問題タイプ |
改善戦略 |
|
マルチターン対話シナリオで、ユーザーのプロンプトが不完全または曖昧です。 |
マルチターン対話の書き換え を有効化します。ナレッジベースがユーザーのプロンプトをより完全な形に自動的に書き換えし、知識マッチングを改善します。 |
|
ナレッジベースに複数のカテゴリのドキュメントが含まれています。カテゴリ A に焦点を当てた検索でも、カテゴリ B など他のカテゴリのテキストチャンクがリコール結果に含まれます。 |
ドキュメントにタグを追加します。取得時に、ナレッジベースが検索前にタグで関連ドキュメントをフィルタリングします。 ドキュメント検索のナレッジベースでのみ、ドキュメントへのタグ追加がサポートされています。 |
|
ナレッジベースに類似の構造を持つ複数のドキュメントが含まれており(例:すべてに「特徴概要」セクションが含まれている)、ドキュメント A の「特徴概要」セクションを検索したいが、リコール結果に他の類似ドキュメントの情報が含まれます。 |
メタデータ抽出 を使用します。ナレッジベースがベクトル取得前にメタデータを使用して構造化検索を実行し、ターゲットドキュメントを正確に見つけて関連情報を抽出します。 ドキュメント検索のナレッジベースでのみ、ドキュメントメタデータがサポートされています。 |
|
リコール結果が不完全で、すべての関連テキストチャンクが含まれていません。 |
|
|
リコール結果に大量の無関係なテキストチャンクが含まれています。 |
類似度しきい値を上げて、ユーザーのプロンプトとの類似度が低い情報を除外します。 |
マルチターン対話の書き換え
マルチターン対話で、ユーザーが「Model Studio Phone X1」といった短いプロンプトで質問することがあります。これにより、取得時に必要なコンテキストが不足し、RAG システムが正確に動作しない可能性があります。その理由は次のとおりです。
-
スマートフォン製品は、複数の世代が同時に販売されていることがよくあります。
-
同一世代の製品でも、メーカーは通常 128 GB や 256 GB など、さまざまなストレージオプションを提供しています。
...
この重要な情報は、以前の会話ターンで提供されている可能性があります。これを効果的に活用することで、RAG はより正確な情報を取得できます。
これを解決するために、Model Studio の マルチターン対話改正 機能を使用できます。システムは会話履歴に基づいてユーザーのプロンプトをより完全な形に自動的に書き換えます。
たとえば、ユーザーが次のように質問します。
Model Studio Phone X1.マルチターン対話の書き換えを有効にすると、システムはユーザーの会話履歴に基づいて取得前にユーザーのプロンプトを書き換えます(例のみ)。
製品ライブラリにある Model Studio Phone X1 の利用可能なすべてのバージョンと、それぞれの具体的なパラメーターを提供してください。この書き換えられたプロンプトにより、RAG はユーザーの意図をより正確に理解し、より適切な応答を提供できます。
次の図は、マルチターン対話の書き換え機能を有効化する方法を示しています。この機能は、推奨構成 を選択した場合にも有効になります。

マルチターン対話の書き換え機能はナレッジベースに紐付いています。一度有効化されると、現在のナレッジベースに関連するクエリにのみ適用されます。この設定は後から変更できません。有効化するには、ナレッジベースを再作成する必要があります。
タグによるフィルタリング
本セクションは、ドキュメント検索のナレッジベースにのみ適用されます。
音楽アプリを使用する際、アーティストで曲をフィルタリングして、そのアーティストのすべての曲を素早く見つけることができます。
同様に、非構造化ドキュメントにタグを追加すると、追加の構造化情報が導入されます。ナレッジベースから取得する際、アプリケーションはまずタグでドキュメントをフィルタリングでき、取得の精度と効率が向上します。
Model Studio では、タグを設定する方法が次の 2 つあります。
-
ドキュメントアップロード時にタグを設定: コンソールでの手順については、「データのインポート」をご参照ください
-
Data Management ページでタグを編集: アップロード済みのドキュメントについて、ドキュメントの右側にある ラベル をクリックしてタグを編集できます

Model Studio では、タグを使用する方法が次の 2 つあります。
-
Model Studio アプリケーションを API で呼び出す 際、
tagsリクエストパラメーターでタグを指定できます。 -
コンソールでアプリケーションを編集する際にタグを設定します。ただし、この方法は エージェントアプリケーション にのみ適用されます。
この設定は、このエージェントアプリケーションに対する以降のすべてのユーザー質問と回答に適用されます。

メタデータ抽出
本セクションは、ドキュメント検索のナレッジベースにのみ適用されます。
テキストチャンクにメタデータを埋め込むことで、各チャンクのコンテキストが効果的に強化されます。特定のシナリオでは、この方法によりドキュメント検索のナレッジベースにおける RAG パフォーマンスが大幅に向上することがあります。
次のシナリオを考えてみましょう。
ナレッジベースには多数のスマートフォン製品マニュアルが含まれています。ドキュメント名は端末モデル(例:Model Studio X1、Model Studio Zephyr Z9)であり、すべてのドキュメントに「特徴概要」の章が含まれています。
このナレッジベースでメタデータが有効になっていない場合、ユーザーは取得のために次のようなプロンプトを入力する可能性があります。
Model Studio Phone X1 の特徴概要。取得テストにより、リコールされたチャンクが明らかになります。すべてのドキュメントに「特徴概要」が含まれているため、ナレッジベースはクエリエンティティ(Model Studio Phone X1)とは無関係だがプロンプトと類似したテキストチャンク(図中のチャンク 1 およびチャンク 2 など)をリコールします。これらのチャンクのランキングが、必要なテキストチャンクよりも高くなる可能性があり、RAG パフォーマンスに悪影響を及ぼします。
取得テストの結果はランキングのみを保証しますが、絶対的な類似度スコアは参考値です。絶対値の差が小さい場合(5% 以内)、リコール確率は同等とみなせます。

次に、「メタデータ抽出」の手順に従って、端末名をメタデータとして設定します。これにより、対応する端末名情報が各ドキュメントのテキストチャンクにアタッチされます。その後、同じテストを実行して比較します。

この時点で、ナレッジベースはベクトル検索の前に構造化検索レイヤーを追加します。完全なプロセスは次のとおりです。
-
プロンプトからメタデータ {"key": "name", "value": "Model Studio Phone X1"} を抽出します。
-
抽出されたメタデータに基づき、「Model Studio Phone X1」メタデータを含むすべてのテキストチャンクを見つけます。
-
次に、ベクトル(セマンティック)検索を実行して、最も関連性の高いテキストチャンクを見つけます。
メタデータを有効にした後、ナレッジベースは「Model Studio Phone X1」に関連し、「特徴概要」を含むテキストチャンクを正確に見つけられるようになります。

メタデータのもう一つの一般的な用途は、テキストチャンクに日付情報を埋め込んで最新のコンテンツをフィルタリングすることです。「メタデータ抽出」をご参照ください。
類似度しきい値
ナレッジベースがユーザーのプロンプトに関連するテキストチャンクを見つけた後、まずそれらを カスタムパラメーター設定(ナレッジベース作成時に設定)で設定された Rank モデルに送信して並べ替えます。次に、類似度しきい値を使用して並べ替えられたテキストチャンクをフィルタリングします。しきい値を超える類似度スコアを持つテキストチャンクのみがモデルに提供されます。

このしきい値を下げると、より多くのテキストチャンクがリコールされる可能性がありますが、関連性の低いテキストチャンクもリコールされる可能性があります。しきい値を上げると、リコールされるテキストチャンクの数が減少する可能性があります。
しきい値が高すぎると、ナレッジベースがすべての関連テキストチャンクを破棄する可能性があります。これにより、モデルが回答を生成するために十分なバックグラウンド情報を得られなくなります。

最適なしきい値はシナリオに依存します。取得テストを通じてさまざまな類似度しきい値を実験し、リコール結果を観察して、ニーズに最も合うソリューションを見つける必要があります。
|
取得テストの推奨手順 |
|
|
|

取得チャンク数
取得チャンク数は、マルチチャネルリコール戦略における K 値です。類似度しきい値フィルタリング後、テキストチャンク数が K を超える場合、システムは類似度スコアが最も高い K 個のテキストチャンクをモデルに提供します。このため、K 値が不適切だと、RAG が正しいテキストチャンクを見逃し、モデルが完全な回答を生成できなくなる可能性があります。
たとえば、ユーザーが次のプロンプトで情報を取得します。
Model Studio X1 スマートフォンの利点は何ですか?ターゲットナレッジベースには、ユーザーのプロンプトに関連し返すべきテキストチャンクが 7 件あります(左側の緑色でマーク)。しかし、この数は現在設定されている最大取得チャンク数(K)を超えているため、「利点 5(超長時間スタンバイ)」および「利点 6(クリアな写真)」を含むテキストチャンクは破棄され、モデルに提供されません。
RAG は「完全な」回答に必要なテキストチャンク数を判断できないため、モデルは提供されたチャンク(不完全であっても)に基づいて回答を生成します。
多くの実験により、「リスト...」、「要約...」、「X と Y を比較...」などのシナリオでは、上位 10 件または上位 5 件だけを提供するよりも、より多くの高品質なテキストチャンク(例:K=20)をモデルに提供する方が効果的であることが示されています。これによりノイズが混入する可能性がありますが、テキストチャンクの品質が高ければ、高性能なモデルは通常その影響を処理できます。
Model Studio でアプリケーションを編集する際に、取得されたチャンクの数 を調整できます。

ただし、取得チャンク数を大きくすればよいというわけではありません。場合によっては、リコールされたテキストチャンクをアセンブルした後の合計長がモデルの入力長制限を超え、切り捨てが発生して RAG パフォーマンスに悪影響を及ぼす可能性があります。
インテリジェントアセンブリ を選択してください。この戦略は、モデルの最大入力長を超えない範囲で可能な限り多くの関連テキストチャンクをリコールします。
回答生成
本セクションでは、回答生成ステージを最適化するための Model Studio がサポートする設定項目のみを説明します。
この時点で、モデルはユーザーのプロンプトとナレッジベースから取得されたコンテンツに基づいて最終的な回答を生成できます。ただし、返された結果が期待通りでない可能性があります。
|
問題タイプ |
改善戦略 |
|
モデルが知識とユーザーのプロンプトの関係を理解できず、つなぎ合わせたような回答になります。 |
適切なモデルを選択することで、知識とユーザーのプロンプトとの関係を効果的に理解できます。 |
|
返された結果が命令に従っていなかったり、包括的でなかったりします。 |
|
|
返された結果の正確性が不十分で、モデル自身の一般的な知識が含まれており、ナレッジベースに完全に根ざしていません。 |
拒否を有効化するして、回答をナレッジベースから取得された知識のみに制限します。 |
|
類似のプロンプトに対して、結果を一貫性のあるものにするか、多様なものにするかを制御したい場合があります。 |
|
モデル選択
さまざまな大規模モデルは、命令の遵守、言語サポート、長文処理、知識理解などの分野で異なる能力を持っています。これにより、次の状況が発生する可能性があります。
モデル A は取得された知識とプロンプトの関係を効果的に理解できず、生成された応答がユーザーのプロンプトに正確に対応できませんでした。モデル B(パラメーター数が多い、または専門的な能力が強い)に切り替えることで、この問題を解決できる可能性があります。
Model Studio でアプリケーションを編集する際に、実際のニーズに基づいて Select Model できます。

Alibaba Cloud Model Studio アプリケーションを編集する際に、実際のニーズに基づいて Select Model できます。商用 Qwen モデル(Qwen-Max や Qwen-Plus など)を選択してください。これらの商用大規模モデルは、オープンソース版と比較して最新の機能と改善が提供されています。
-
シンプルな情報クエリや要約の場合は、パラメーター数が少ない大規模モデル(
Qwen-Turboなど)で十分です。 -
RAG に複雑な論理的推論を実行させたい場合は、パラメーター数が多く推論能力が強い大規模モデル(
Qwen-Maxなど)を選択してください。 -
クエリで多数のドキュメントスニペットを参照する必要がある場合は、コンテキスト長が長い大規模モデル(
Qwen-Plusなど)を選択してください。 -
法律分野などの専門分野向けに RAG アプリケーションを構築する場合は、その特定の分野向けにトレーニングされたモデル(
Qwen-Legalなど)を使用してください。
プロンプトテンプレートの最適化
取得された知識の使用方法をガイドするプロンプトを設計することで、モデルの動作に影響を与え、RAG パフォーマンスを向上させることができます。
以下に、一般的な最適化方法を 3 つ紹介します。
方法 1: 出力コンテンツの制約
プロンプトテンプレートにコンテキスト情報、命令、期待される出力フォーマットを提供してモデルに指示できます。たとえば、次の出力命令を追加できます。
提供された情報で質問に回答できない場合は、「既存の情報に基づくと、この質問には回答できません」と明確に述べてください。回答をでっち上げないでください。これにより、モデルのハルシネーションの可能性が低減されます。
方法 2: 例を追加
フューショットプロンプティング の方法を使用して、モデルが模倣すべき質問と回答の例をプロンプトに追加します。これにより、モデルが取得された知識を正しく使用するようにガイドされます。次の例では Qwen-Plus を使用しています。
|
プロンプトテンプレート |
結果 |
|
|
|
|


方法 3: コンテンツ デリミタの追加
取得されたテキストチャンクがプロンプトテンプレートにランダムに混在していると、大規模モデルはプロンプトの全体構造を理解するのが難しくなります。${documents} 変数とプロンプトを明確に分離してください。
さらに、最良の結果を確保するには、${documents} 変数がプロンプトテンプレート内に1 回のみ出現することを確認してください。参考として、左側の正しい例をご覧ください。
|
正しい例 |
誤った例 |
|
|
プロンプト最適化方法の詳細については、「プロンプトエンジニアリング」をご参照ください。
拒否
Model Studio アプリケーションの結果をナレッジベースから取得された知識のみに基づき、モデル自身の一般的な知識の影響を除外したい場合は、アプリケーション編集時に回答範囲を ナレッジベースのみ に設定できます。
ナレッジベースで関連知識が見つからないケースについては、固定された自動返答を設定することもできます。
|
回答範囲: ナレッジベース + LLM 知識 |
回答範囲: ナレッジベースのみ |
|
|
|
|
Model Studio アプリケーションの結果は、ナレッジベースから取得された知識とモデル自身の一般的な知識を組み合わせたものになります。 |
Model Studio アプリケーションの結果は、ナレッジベースから取得された知識のみに基づいたものになります。 |


知識範囲を決定するため、しきい値の検索 + LLM 判定 方法を選択してください。この戦略は、まず類似度しきい値を使用して潜在的なテキストチャンクをフィルタリングします。次に、モデルがレフェリーとして機能し、設定した 判定プロンプト を使用して関連性を詳細に分析します。これにより、判断の精度がさらに向上します。

以下は参考のための判定プロンプトの例です。また、ナレッジベースで関連知識が見つからない場合の固定返答も設定されています:申し訳ありませんが、関連するスマートフォンモデルは見つかりませんでした。
# 判定ルール:
- 質問とドキュメントが一致するのは、質問に含まれるエンティティがドキュメントで説明されているエンティティと完全に同一の場合のみです。
- ドキュメントに質問がまったく言及されていない場合。|
成功したクエリ |
失敗したクエリ |
|
|
|


モデルパラメーター
類似のプロンプトに対してモデルが一貫性のある応答を提供するか、多様な応答を提供するかを制御したい場合は、アプリケーション編集時に パラメータ設定 を変更してモデルパラメーターを調整できます。

上図の 温度 パラメーターは、モデルが生成するコンテンツのランダム性を制御します。温度が高いほど生成されるテキストは多様になり、逆に低いほど決定論的なテキストになります。
-
多様なテキストは、創造的なライティング(小説や広告コピーなど)、ブレインストーミング、チャットアプリケーションのシナリオに適しています。
-
決定論的なテキストは、明確な回答を必要とするシナリオ(問題分析、多肢選択問題、事実確認など)や、正確な表現が求められるシナリオ(技術文書、法的文書、ニュース記事、学術論文など)に適しています。
その他の 2 つのパラメーターは次のとおりです。
最大応答長: このパラメーターは、モデルが生成するトークンの最大数を制御します。詳細な説明を生成するにはこの値を増やし、短い回答を生成するには減らします。
コンテキストターン数: このパラメーターは、モデルが参照する過去の会話ターン数を制御します。1 に設定すると、モデルは回答時に過去の会話情報を参照しません。
よくある質問
ドキュメントコンテンツレイアウトの推奨事項
-
明確な見出しレベルを使用します。各見出しの下のコンテンツが明確で自己完結的であるようにします。
-
ウォーターマークを避けてください。
-
リストの中間項目の下にリストレベルをネストしないでください。
-
可能であればテーブルや画像を避けます。複雑なテーブルは解析品質に悪影響を及ぼす可能性があります。
不明瞭な見出しレベル:例
元のドキュメント
レベル 1 見出しが「IV. 賞品の使用ルール:」で、コンテンツに「賞品 1:...」および「賞品 2:...」が含まれています。

処理後の問題
「賞品 2:...」が「賞品 1:...」のサブ見出しとして解析されます。ドキュメントで「賞品 1:...」および「賞品 2:...」を番号付きのレベル 2 見出しとして設定してください。
ドキュメント内のウォーターマーク:例
元のドキュメント
ドキュメントにウォーターマークが含まれており、合計で 3 つの項目があります。

処理後の問題
3 番目の項目が単一のチャンクに分割されます。しかし、ウォーターマークがテキストとして認識されるため、「(V) 第 11 学年農地:120,000 元/エーカー」の後に「政府公報」などの余分な単語が表示されます。「政府公報」というウォーターマークがテキストの早い段階に現れるため、項目 (I) ~ (V) の順序が (I)、(V)、(III)、(IV)、(II) に乱されることもあります。
中間項目の下のネストリスト:例
元のドキュメント
レベル 1 見出し「アクティビティルール」の下には、順序付きリストがあります。その 3 番目の項目「アクティビティ紹介」には、別のリスト(項目 a および b)が含まれています。

処理後の問題
3 番目の項目にネストリストが含まれているため、「キャンペーン紹介」がレベル 2 見出しとして誤読され、その後のすべてのコンテンツがその下にグループ化されます。ネストリストは避けてください。必要であれば、ネストリストを親リストの末尾に配置してください。
良い例
-
各見出しの下のコンテンツが明確で比較的独立しています。
-
ウォーターマークがありません。
-
見出しの下にリストが表示されますが、ネストリストは含まれていません。
-
テーブルや画像がありません。
