ナレッジベースは、非公開データや最新情報で大規模言語モデル (LLM) を補完します。検索拡張生成 (RAG) を使用することで、LLM は応答を生成する前に、まずナレッジベースから関連コンテンツを取得して回答の精度を向上させます。
ナレッジベース機能は、中国 (北京) リージョンでのみ利用可能です。シンガポールやドイツ (フランクフルト) などの他のリージョンでは利用できません。
-
コンソールアクセスの制限: 2025年4月21日より前に シンガポールリージョン で Alibaba Cloud Model Studio アプリケーションを作成したユーザーのみが [アプリケーション開発] タブにアクセスできます。
このタブには、アプリケーション (エージェントアプリケーションおよびワークフローアプリケーション)、コンポーネント (プロンプトエンジニアリングおよびプラグイン)、およびデータ (ナレッジベースおよびアプリケーションデータ) の機能が含まれています。これらはすべてプレビュー機能です。本番環境での使用にはご注意ください。
-
API 呼び出しの制限: 2025年4月21日より前に シンガポールリージョン で Alibaba Cloud Model Studio アプリケーションを作成したユーザーのみが、アプリケーションデータ、ナレッジベース、およびプロンプトエンジニアリングの API を呼び出すことができます。
|
専用ナレッジベースのないアプリケーション 専用のナレッジベースがない場合、LLM はドメイン固有の質問に正確に答えることができません。 例えば、ユーザーがチャットインターフェイスで「Alibaba Cloud Model Studio から、予算 3,000 元以内で最高のカメラ付きスマートフォンを選んでください」と送信した場合、AI アシスタントは関連するナレッジベースがないため、正確な製品推奨を提供できません。 |
専用ナレッジベースのあるアプリケーション 専用のナレッジベースがあれば、LLM はドメイン固有の質問に正確に答えることができます。
|

サポート対象モデル
以下のモデルはナレッジベースで使用できます。ナレッジベースを使用するための Qwen の設定
-
Qwen-Max/Plus/Turbo
-
QwenVL-Max/Plus
-
Qwen オープンソースバージョン (例:Qwen2.5)
利用可能なモデルの最新リストについては、アプリケーション作成時に アプリケーション管理 ページをご参照ください。
クイックスタート
このクイックスタートでは、「Alibaba Cloud Model Studio phones」を例に、ドメイン固有の質問に回答するためのノーコードの LLM Q&A アプリケーションを構築する方法を紹介します。
1. ナレッジベースの構築
-
[ナレッジベース] ページに移動し、ナレッジベースの作成 をクリックします。ナレッジベース名 と ナレッジベース説明 を入力し、他の設定はデフォルト値のままにして、次へ をクリックします。
-
[デフォルトカテゴリ]を選択し、Alibaba Cloud Model Studio Phone Series Product Introduction.docx ファイルをアップロードします。次へをクリックし、次にインポート完了をクリックします。
2. ビジネスアプリケーションとの連携
ナレッジベースを作成した後、同じワークスペース内の Alibaba Cloud Model Studio アプリケーションまたは外部アプリケーションに関連付けて、取得リクエストを処理できます。
エージェントアプリケーション
-
App Center ページに移動し、エージェントアプリケーションを見つけ、そのカードで 設定 をクリックし、アプリケーションのモデルを選択します。
-
[ドキュメントナレッジベース] の横にある + アイコンをクリックして、先ほど作成したナレッジベースを追加します。類似度のしきい値と重みはデフォルト値のままでかまいません。
-
右側の入力ボックスに質問を入力します。LLM はナレッジベースを使用して回答を生成します。
例:「3,000 元以内で最高のカメラを搭載した Alibaba Cloud Model Studio のスマートフォンを選ぶのを手伝ってください。」
ワークフローアプリケーション
-
[App Center] ページに移動し、ワークフローアプリケーションを見つけ、そのカードの[設定]をクリックします。[ナレッジベース] ノードをキャンバスにドラッグし、開始 ノードの後に接続します。
-
ナレッジベースノードを設定します:
-
入力:
content変数の右側にある [値] ドロップダウンリストから、 を選択します。ドロップダウンリストはツリー構造になっているため、query 変数を選択するには、「組み込み変数」グループを展開する必要がある場合があります。 -
ナレッジベースの選択:ノードのナレッジベースは 2 つの方法で選択できます。
-
固定ナレッジベースの選択:前のステップで作成したナレッジベースをドロップダウンメニューから選択します。すべての呼び出しで同じナレッジベースが必要な場合に使用します。
-
動的選択:
CodeList変数を設定して、上流ノードの出力に基づいてナレッジベースを動的に指定します。これは、異なる入力に基づいて異なるナレッジベースを取得する必要があるシナリオに適しています。
-
-
TopK の設定 (オプション):この設定は、下流ノード (通常は LLM ノード) に返されるチャンクの数を決定します。
この値を大きくすると、通常は LLM の回答の精度が向上しますが、LLM の入力トークンの消費量も増加します。
-
-
LLM ノードをキャンバスにドラッグし、ナレッジベースノードの後、終了ノードの前に接続します。
-
LLM ノードを設定します:
-
モデル設定 リストから、ノードのモデルを選択します。
-
プロンプト に、LLM にナレッジベースを使用するよう指示するプロンプトを入力します。「/」を入力して
result変数を挿入します (これはナレッジベースの取得で返された結果を表します)。例えば、プロンプトのタイトルに
# ナレッジベース、本文に以下の資料 {ナレッジベース 1/result} を覚えておいてください。質問に答えるのに役立つかもしれません。と入力します。
-
-
終了ノードを設定します:
/を入力し、 を選択して LLM からの結果を出力します。 -
ページの右上隅にあるテストをクリックします。右側の入力ボックスに、質問を入力します。LLM がナレッジベースを使用して回答を生成します。
例:「3,000 元以内で最高のカメラを搭載した Alibaba Cloud Model Studio のスマートフォンを選ぶのを手伝ってください。」
外部アプリケーション
Alibaba Cloud Model Studio 内でアプリケーションを構築するだけでなく、Model Studio SDK を使用して、外部の AI アプリケーションのためにナレッジベースからデータを取得することもできます。
詳細な連携手順については、「ナレッジベース API ガイド」をご参照ください。
3. RAG パフォーマンスの最適化 (オプション)
Q&A プロセスで不完全または不正確な結果を受け取った場合は、「RAG パフォーマンスの最適化」をご参照ください。
操作手順
ナレッジベース ページでは、現在のワークスペース内のすべてのナレッジベースを表示および管理できます。
ナレッジベース ID:各ナレッジベースの ID は、API 呼び出しに使用されます。
ナレッジベースの作成
ナレッジベースの作成 をクリックした後、「基本情報の入力とナレッジベースタイプの選択」、「データソースの設定」、「インデックスパラメーターの設定」の 3 つのステップでナレッジベースを作成します。
-
ナレッジベース ページで、ナレッジベースの作成 をクリックします。
-
基本情報
ユースケースに応じて ナレッジベースの種類 を選択します。1 つのナレッジベースでサポートされるタイプは 1 種類のみです。[ドキュメント検索] タイプを選択した場合は、[ユースケース] として、[基本ドキュメント Q&A]、[リッチテキスト返信] のいずれかを選択する必要もあります。
-
基本的なドキュメント Q&A:プレーンテキストドキュメントのセマンティック検索に最適です。
-
リッチテキスト返信:テキストと画像の両方を含む応答が必要なユースケースに最適です。
ナレッジベースのタイプは、ナレッジベース作成後に変更できません。
-
ドキュメント検索
-
ユースケース:
-
社内文書や製品マニュアルなど、非構造化データからの情報取得に最適です。非構造化データとは、事前定義されたデータモデルやスキーマで整理されておらず、テキスト、テーブル、画像などを含む情報です。
-
アプリケーションが応答に含めたい画像がファイルに含まれている場合、ドキュメント検索を選択します。
-
-
データソース:ローカルファイルをアップロードするか、Object Storage Service (OSS) からインポートできます。
-
-
データクエリ
-
ユースケース:
-
FAQ、製品データ、または人事情報のクエリ用アシスタントなど、構造化データ (事前定義されたテーブルスキーマに従って整理されたデータ) に基づく Q&A システムの構築に最適です。
-
データが完全な FAQ の質問と回答のペアで構成されている場合は、データクエリを選択します。例えば、Excel ファイルに
質問と回答の 2 つの列が含まれている場合、データクエリナレッジベースは質問列を取得に使用し、回答列を LLM の応答のコンテキストとして使用できます。この列固有の処理は、ドキュメント検索ナレッジベースタイプでは利用できません。
-
複数の Excel ファイルをインポートできますが、それらのテーブルスキーマは同一である必要があります。
-
-
データソースの統合:ローカルの XLS または XLSX ファイルをアップロードできます。
-
-
画像 Q&A
-
ユースケース:
-
製品発見アシスタントや視覚 Q&A アシスタントなど、画像による検索や画像とテキストによる検索をサポートするマルチモーダル検索アプリケーションの構築に最適です。
-
-
データソースの統合:ローカルの XLS または XLSX ファイルをアップロードできます。
XLS および XLSX ファイルには、画像インデックスを構築するために公開アクセス可能な画像 URL が含まれている必要があります。詳細については、以下の作成手順をご参照ください。
-
要件に応じて、基本的なドキュメント Q&A、リッチテキスト返信 などのユースケースを選択できます。
-
ピーク時には、データ量によってはナレッジベースの作成に数時間かかることがあります。
ナレッジベースの更新
ナレッジベースへの変更は、参照しているすべてのアプリケーションとリアルタイムで同期されます。
ドキュメント検索
-
自動更新 (推奨)
OSS、FC、および Model Studio ナレッジベース API を統合することで、自動更新を設定できます。以下の手順に従ってください:
-
バケットの作成:OSS コンソールに移動し、ソースファイルを保存するための OSS バケットを作成します。
-
ナレッジベースの作成:非公開コンテンツを保存するための非構造化ナレッジベースを作成します。
-
ユーザー定義関数の作成:FC コンソールに移動し、ファイルの作成や削除などのファイル変更イベントを処理する関数を作成します。詳細については、「関数の作成」をご参照ください。この関数は、ナレッジベース API ガイドから関連する API を呼び出して、OSS のファイル変更とナレッジベースを同期させます。
-
OSS トリガーの作成:FC で、前のステップで作成したユーザー定義関数に OSS トリガーを関連付けます。OSS に新しいファイルがアップロードされるなどのファイル変更イベントが発生すると、トリガーは FC で関数を実行します。
-
-
手動更新
ナレッジベースページで、更新するナレッジベースを見つけ、そのカードの詳細を表示するをクリックします。
-
新しいファイルを追加するには: データのインポート をクリックし、データコネクタから既存のファイルを選択します。
-
ファイルを削除するには:削除したいファイルを見つけ、その右側にある [削除] をクリックします。
-
ファイルの内容を修正するには:インプレース更新や上書きアップロードはサポートされていません。まずナレッジベースから古いバージョンのファイルを削除し、その後新しいバージョンをインポートする必要があります。
注意:古いバージョンを削除しないと、古いコンテンツが応答に表示される可能性があります。
-
データクエリと画像 Q&A
注意:画像 Q&A ナレッジベースの詳細ページには、直接の [データをアップロード] ボタンはありません。[データソースを表示] リンクをクリックしてデータコネクタの詳細ページを開き、データを更新します。
-
自動更新
サポートされていません。
-
手動更新
ナレッジベースのデータソースがアプリケーションデータのデータテーブルである場合、2 つのステップで手動で更新する必要があります。
-
ステップ 1:データテーブルの更新
[アプリケーションデータ] タブに移動します。 左側のペインで、対象のデータテーブルを選択し、データのインポート をクリックします。
-
新規データを挿入するには: インポートタイプとして 増分アップロード を選択します。ヘッダー行と新しいデータ行のみを含む Excel ファイルをアップロードする必要があります。
ファイルヘッダーは、現在のテーブルスキーマと一致する必要があります。テンプレートをダウンロード をクリックして標準ヘッダー付きのテンプレートファイルを取得し、それに新しいデータを追加できます。
-
データの削除:インポートタイプとして アップロードと上書き を選択します。ヘッダー行と、保持したいデータレコードのみを含む Excel ファイルをアップロードする必要があります。
完全なデータセットを取得するには、
 アイコンをクリックしてデータを XLSX 形式でダウンロードします。
アイコンをクリックしてデータを XLSX 形式でダウンロードします。 -
データを変更するには: インポートタイプとして アップロードと上書き を選択します。ヘッダー行と、変更済みの完全なデータセットを含む Excel ファイルをアップロードする必要があります。
-
-
ステップ 2:変更をナレッジベースに同期
ナレッジベース リストに戻り、目的のナレッジベースを見つけ、そのカードにある詳細を表示するをクリックします。データテーブルの左上隅にある
 アイコンをクリックし、プロンプトを確認して、データテーブルの最新のコンテンツをナレッジベースと同期します。
アイコンをクリックし、プロンプトを確認して、データテーブルの最新のコンテンツをナレッジベースと同期します。手動で更新するたびに、これらの手順を繰り返す必要があります。
-
オーディオおよびビデオ検索
-
自動更新
サポートされていません。
-
手動更新
ナレッジベース ページで、更新するナレッジベースを探し、カード上の 詳細を表示する をクリックします。
-
新しいファイルを追加するには、データのインポート をクリックして、アプリケーションデータから既存のファイルを選択します。
-
ファイルを削除するには:削除したいファイルを見つけ、その右側にある [削除] をクリックします。
この操作はナレッジベースからファイルを削除するだけで、 アプリケーションデータ のソースファイルは削除しません。
-
ファイルの内容を修正するには:インプレース更新や上書きアップロードはサポートされていません。まずナレッジベースから古いバージョンのファイルを削除し、その後新しいバージョンをインポートする必要があります。
注意:古いバージョンを削除しないと、古いコンテンツが応答に表示される可能性があります。
-
ナレッジベースの編集
ナレッジベースを作成した後、変更できるのはナレッジベース名、ナレッジベースの説明、および類似度のしきい値のみです。他の設定を変更するには、ナレッジベースを削除して再作成する必要があります。この操作はコンソールでのみ利用可能で、対応する API はありません。
手順: [ナレッジベース] ページで、対象のナレッジベースを見つけ、そのカードにある ![]() アイコンをクリックし、次に 編集 をクリックします。 注意:ナレッジベースの構成は、1 暦日あたり 1 回のみ変更できます。 それ以降の試行はサイレントに拒否されます。
アイコンをクリックし、次に 編集 をクリックします。 注意:ナレッジベースの構成は、1 暦日あたり 1 回のみ変更できます。 それ以降の試行はサイレントに拒否されます。
ナレッジベースの削除
この操作は元に戻せません。
ナレッジベースを削除する前に、公開済みの Model Studio アプリケーションすべてから関連付けを解除することを推奨します。
未公開のアプリケーションに関連付けられているナレッジベースは、削除できます。
-
ナレッジベースに関連付けられている各公開済みアプリケーションについて:
-
[App Center] ページで、ナレッジベースに関連付けられたアプリケーションを探し、設定 をクリックします。
-
ナレッジベースのリストで、ナレッジベースを削除します。 ページの右上隅にある公開をクリックし、プロンプトに従ってアプリケーションを再公開します。
-
-
[ナレッジベース] ページで、対象のナレッジベースを見つけ、そのカードにある
 アイコンをクリックし、次に 削除 をクリックします。
アイコンをクリックし、次に 削除 をクリックします。
構成の変更
Enterprise Edition は RCU を使用して高い QPS での高性能な取得を保証し、より大きなストレージ容量をサポートします。Standard Edition は、開発、テスト、または低同時実行数のシナリオに適しています。
Standard Edition と Enterprise Edition を切り替えることができ、Enterprise Edition の RCU 数を変更できます。
ナレッジベースの構成は、1 暦日に 1 回しか変更できません。
RCU:Retrieval Compute Unit (RCU) は、ナレッジベースの取得同時実行数の指標です。1 RCU は、オンライン取得で約 50 QPS までをサポートします。RCU 数が多いほど、より高い同時実行数をサポートします。
-
注意:
-
Enterprise Edition のナレッジベースがプラットフォームストレージを使用している場合、Standard Edition にスペックダウンする前に、使用済みストレージ容量を 80 GB 未満に減らす必要があります。
ナレッジベースからファイルやデータを削除することで、ストレージ容量を解放できます。
-
-
手順:
-
ナレッジベース ページで、再設定するナレッジベースを見つけます。そのカードの
アイコンをクリックし、[編集] をクリックします。 -
ダイアログボックスで、現在のエディションに基づいてアクションを選択します:
-
Standard Edition:[スペックアップ] を選択します。
-
Enterprise Edition:[スペックダウン] または [RCU 数を変更] を選択します。
-
-
画面の指示に従ってプロセスを完了します。[OK] をクリックすると、新しい設定がすぐに有効になります。
-
ヒットテスト
ヒットテストを使用して、ナレッジベースが AI アプリケーションに正確なコンテキストを提供していることを確認します。このプロセスには、ユーザーのクエリのシミュレーション、取得結果の評価、類似度のしきい値の微調整が含まれます。
ヒットテストの再ランキングモデルは、Q&A モード (デフォルト)、ドキュメントの内容と完全に一致しないクエリ向けに設計されたモード、ドキュメントの内容と非常に類似したクエリに最適な類似度モード、およびカスタム詳細モードの 3 つのモードをサポートしています。同じクエリでも、選択したモードによってランキングスコアは大きく異なる場合があります。例えば、同じテキストセグメントが Q&A モードでは 47% のスコアになるかもしれませんが、類似度モードでは最大 69% になることがあります。
ヒットテストを使用すると、次のことができます:
-
ナレッジベースが AI アプリケーションに効果的なコンテキストを提供していることを確認する
-
再現率と精度のバランスを取るために類似度のしきい値を微調整する
-
ナレッジベースのコンテンツのギャップや品質問題を特定する
ユースケース
-
シナリオ 1:製品価格のクエリ
テスト入力:「Model Studio スマートフォンの価格はいくらですか?」 期待される結果:価格情報を含む関連テキストセグメントを取得する。 -
シナリオ 2:技術的な問題のトラブルシューティング
テスト入力:「デバイスが Wi-Fi に接続できない場合はどうすればよいですか?」 期待される結果:Wi-Fi 接続問題のトラブルシューティングに関する関連テキストセグメントを取得する。 -
シナリオ 3:視覚理解による取得
視覚理解ナレッジベースは、テキストのみ、画像のみ、画像+テキストの 3 つのクエリモードをサポートします。 モード 1 (テキストのみ):「Object Storage Service」と入力して、ドキュメントや画像から関連セグメントを取得します。 モード 2 (画像のみ):製品のスクリーンショットをアップロードします。システムは視覚理解を使用して、意味的に類似したセグメントを照合します。 モード 3 (画像+テキスト):画像をアップロードし、説明テキストを入力します。この組み合わせクエリにより、取得の関連性が向上します。 -
シナリオ 4: Express Q&A
高速 Q&A ナレッジベースは、テキストのみのクエリをサポートし (画像入力は非対応)、構造化ドキュメントからの高速取得に最適です: テスト入力:「Qwen Pro 8 の価格はいくらですか?」 期待される結果:価格情報を含む関連 FAQ セグメントを迅速に取得します。
手順
-
ナレッジベースページで、対象のナレッジベースのカードにある命中テスト をクリックします。
-
テストインターフェイスで、質問 (理想的にはユーザーからの一般的な質問) を入力し、取得結果を確認します。
-
取得結果:このセクションには、現在のテストの取得結果が類似度の降順で表示されます。任意のテキストセグメントをクリックして、その内容を表示します。
-
 アイコン:画像 Q&A ナレッジベースの場合、システムはまず入力画像をベクトルに変換し、関連セグメントを取得します。次に、これらのセグメントを質問とともに LLM に送信して回答を生成します。ドキュメント検索、データクエリナレッジベースの場合、システムはアップロードされた画像を取得に使用しません。ただし、「視覚理解」用に設定されたドキュメント検索ナレッジベースは、画像を取得に使用し、テキストのみ、画像のみ、および画像+テキストのクエリモードをサポートします。この組み合わせクエリにより、取得の関連性が向上します。
アイコン:画像 Q&A ナレッジベースの場合、システムはまず入力画像をベクトルに変換し、関連セグメントを取得します。次に、これらのセグメントを質問とともに LLM に送信して回答を生成します。ドキュメント検索、データクエリナレッジベースの場合、システムはアップロードされた画像を取得に使用しません。ただし、「視覚理解」用に設定されたドキュメント検索ナレッジベースは、画像を取得に使用し、テキストのみ、画像のみ、および画像+テキストのクエリモードをサポートします。この組み合わせクエリにより、取得の関連性が向上します。
-
-
関連するテキストセグメントが取得されていることを確認します。そうでない場合は、類似度のしきい値を調整し、前のステップを繰り返します。
-
リコール履歴の表示 をクリックすると、さまざまな しきい値設定ごとの取得性能を比較できます。

クォータと制限
-
ナレッジベースでサポートされているデータソース、容量、およびその他の制限については、「ナレッジベースのクォータと制限」をご参照ください。
-
ナレッジベースを Model Studio アプリケーションに関連付ける場合、以下の制限が適用されます。
-
ドキュメント検索:最大 5
-
データクエリ:最大 5
-
画像 Q&A:最大 1
複数のナレッジベースタイプにわたる合計制限は 11 です。
-
課金
ナレッジベース機能の使用は無料ですが、この機能を利用する Alibaba Cloud Model Studio アプリケーションの呼び出しには料金が発生する場合があります。
|
手順 |
課金 |
|
|
|
無料です。 |
|
|
|
Alibaba Cloud Model Studio アプリケーションを呼び出す際、ナレッジベースから取得されたテキストチャンクが大規模言語モデル (LLM) の入力トークン数を増加させ、モデル推論料金が増加します。詳細については、「課金項目と料金」をご参照ください。 注:Retrieve API のみを使用して取得を行い、Alibaba Cloud Model Studio アプリケーションを使用して応答を生成しない場合は、課金されません。 |
|
|
|
無料です。 |
|
API リファレンス
-
ナレッジベース API とそのパラメーターの完全なリストについては、API ディレクトリ (ナレッジベース) をご参照ください。
-
詳細な使用方法とコード例については、ナレッジベース API ガイド をご参照ください。
よくある質問
ナレッジベースの構築
画像とマルチモーダルコンテンツの取り扱い
-
ドキュメント検索
-
ナレッジベースを作成する際に、[ナレッジベースタイプ] を [ドキュメント検索] に、図と文を交えた回答 を 図と文を交えた回答 に設定します。
[図あり] を選択すると、ナレッジベースはファイル内のイラストから要約を抽出します。その後、大規模言語モデルが、要約とユーザーの質問との関連性に基づいて画像を挿入するかどうかを決定します。
重要ドキュメントをアップロードする際に、[電子ドキュメント解析] を選択しないでください。この解析方法では画像が認識されないため、[図あり] 機能が正しく動作しなくなります。
-
エージェントアプリケーションを作成または編集する際に、Qwen-Plus または Qwen-Plus-Latest モデルを選択します (テストではこれらのモデルが最高のパフォーマンスを示しています)。[ドキュメントナレッジベース] の右側にある [+] ボタンをクリックし、前のステップで作成したナレッジベースを追加します。
説明リコール長はドキュメントの長さより短くする必要があります。リコール長がドキュメントの長さを超えると、システムはドキュメント全体を返し、「図あり」機能のロジックが適用されなくなります。
注:「図あり」機能と「回答ソースの表示」機能は同時に有効にできません。
-
実際の Q&A 結果:
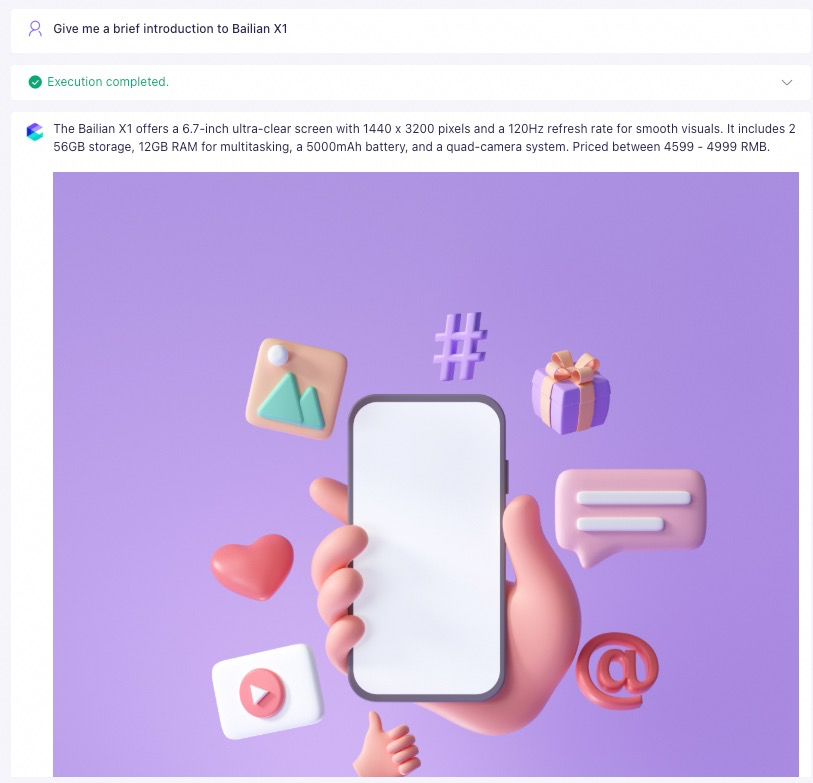
-
画像をパブリックにアクセス可能な場所にアップロードし、その完全な URL を取得します。OSS の使用を推奨します。手順については、「画像を OSS にアップロードしてファイル URL を使用する」をご参照ください。
-
完全な URL をファイルに挿入します。相対パスはサポートされていません。画像ファイルをドキュメントに直接埋め込まないでください (例:コピー&ペーストやメニューからのローカル画像の挿入)。画像は、パブリックにアクセス可能な URL を使用して参照する必要があります。
画像が表示されない場合は、チャンク内の URL が完全であることを確認してください。解析エラーの原因となる可能性のある余分なスペースや特殊文字を削除します。チャンクを直接編集してこれらの修正を行うことができます。
ファイル内で画像を正しく参照する例
プロンプトテンプレートのサンプル
実際の Q&A 結果

# Knowledge Base Please remember the following materials. They may be helpful for answering questions. ${documents} # Requirements If there are images, please display them.ファイル内で画像を誤って参照する例
プロンプトテンプレートのサンプル
実際の Q&A 結果

# Knowledge Base Please remember the following materials. They may be helpful for answering questions. ${documents} # Requirements If there are images, please display them.チャットテストインターフェイスでプロンプトを入力すると、AI の応答は画像を含まないプレーンテキストコンテンツのみを返します。
説明:画像をファイルに直接埋め込むと、Model Studio アプリケーションはその画像を応答に表示しません。
イメージ Q&A
-
画像をパブリックにアクセス可能な場所にアップロードし、その完全な URL を取得します。OSS の使用を推奨します。手順については、「画像を OSS にアップロードしてファイル URL を使用する」をご参照ください。
-
[テーブル] タブで、新しいデータテーブルを作成し、image_url 型のフィールドを追加して画像の完全な URL を格納します。
説明-
image_url フィールドは相対パスをサポートしていません。
-
1 つの image_url フィールドに複数の画像 URL を格納することはできません。1 つのレコードに複数の画像を関連付けるには、
image_urlフィールドを画像ごとに個別に作成する必要があります (例:image_1、image_2)。 -
image_url フィールドで参照される各画像は 3 MB 以下である必要があります。画像がこの制限を超えると、ナレッジベースの作成は失敗します。
-
データテーブル作成後に image_url 型のフィールドを追加または変更することはできません。したがって、最初のテーブルスキーマ設計時に、必要なすべての画像フィールドを含める必要があります。
フィールドの [タイプ] は、string、double、long、datetime、image_url をサポートしています。構成後、[データをインポート] エリアで xlsx または xls 形式のファイル (20 MB 以下) をアップロードできます。
-
-
ナレッジベースを作成する際に、[ナレッジベースタイプ] を [イメージ Q&A] に設定します。
-
エージェントアプリケーションを作成または編集する際に、画像 (イメージ Q&A ナレッジベース) の右側にある [+] ボタンをクリックし、作成したナレッジベースを追加してから、プロンプトテンプレートを次のように変更します。
# Knowledge Base Please remember the following materials. They may be helpful for answering questions. ${documents} # Requirements If there are images, please display them. -
ページの右側にある入力ボックスで質問します。
例:「アリババモバイル X1 について簡単に紹介してください。」
画像を正しく参照する例
プロンプトテンプレートのサンプル
ユーザープロンプトと Model Studio アプリケーションの応答
Alibaba Cloud Model Studio のナレッジベースデータプレビューページで、Model Studio フォンのデータにインポート成功と表示されます。構造化データテーブルには、モデル (string)、ナレッジベース説明 (string)、イメージ (image_url) の 3 つの列が含まれています。サンプルデータ行では、モデルは Model Studio X1、説明フィールドには画面 (6.7 インチ 1440x3200 ピクセル 120Hz)、ストレージ (256GB+12GB RAM)、バッテリー (5000mAh)、カメラ (超高感度クアッドカメラ)、参考価格 4,599~4,999 元が含まれており、イメージ列は対応する画像リソースの URL です。
# Knowledge Base Please remember the following materials. They may be helpful for answering questions. ${documents} # Requirements If there are images, please display them.
-