Alibaba Cloud Model Studio Coding Plan の一部のモデル (qwen3.5-plus、kimi-k2.5 など) は、ネイティブの画像理解機能を備えており、イメージ入力を直接処理できます。glm-5 や MiniMax-M2.5 などのプレーンテキストモデルには、ローカルスキルを追加することで画像理解機能を有効にできます。
画像理解スキルを実行すると、ご利用の Coding Plan クォータが消費されます。追加料金は発生しません。
前提条件
Coding Plan にサブスクライブ済みであること。Coding Plan。詳細については、「使用開始」をご参照ください。
Coding Plan ツールで接続を構成済みであり、正常に会話できること。詳細については、「AI ツールへの接続」をご参照ください。
ビジュアルサポートステータス
モデル | ビジュアルサポート | 説明 |
| はい | 追加の構成は不要です。イメージを直接渡すことができます。 |
| いいえ | モデルにビジュアル機能を持たせるには、スキルまたはエージェントが必要です。 |
方法 1: ビジュアルモデルを直接使用 (推奨)
qwen3.5-plus および kimi-k2.5 モデルは、ネイティブの画像理解機能を備えています。頻繁に画像を処理する必要がある場合は、これらのモデルに切り替えることが最もシンプルで推奨されるアプローチです。
ツール | モデルの切り替え方法 |
Claude Code |
|
OpenCode |
|
Qwen Code |
|
他のプログラミングツールでのモデルの切り替え方法の詳細については、「AI ツールへの接続」をご参照ください。モデルを切り替えた後、会話内で画像パスを直接参照したり、画像をドラッグアンドドロップまたは貼り付けたりできます。
方法 2: スキルまたはエージェントを使用したビジュアル機能の追加
glm-5 や MiniMax-M2.5 など、画像理解機能を持たないモデルで画像を処理するには、スキルまたはエージェントを構成できます。
Claude Code
スキルの追加
プロジェクトディレクトリ内の
.claudeフォルダ内に、skills/image-analyzerフォルダを作成します。mkdir -p .claude/skills/image-analyzerこのフォルダ内に、
SKILL.mdファイルを作成し、以下のコンテンツを追加します。--- name: image-analyzer description: ビジュアル機能を持たないモデルが画像を理解するのを助けます。画像コンテンツの分析、画像からの情報、テキスト、UI 要素の抽出、またはスクリーンショット、チャート、アーキテクチャ図などのあらゆる視覚コンテンツの理解が必要な場合に、このスキルを使用します。画像パスを渡して説明を取得します。 model: qwen3.5-plus --- qwen3.5-plus は画像理解機能を備えています。画像理解には qwen3.5-plus モデルを直接使用します。結果のフォルダ構造は次のとおりです。
.claude/ └── skills/ └── image-analyzer/ └── SKILL.md使用開始
プロジェクトディレクトリで
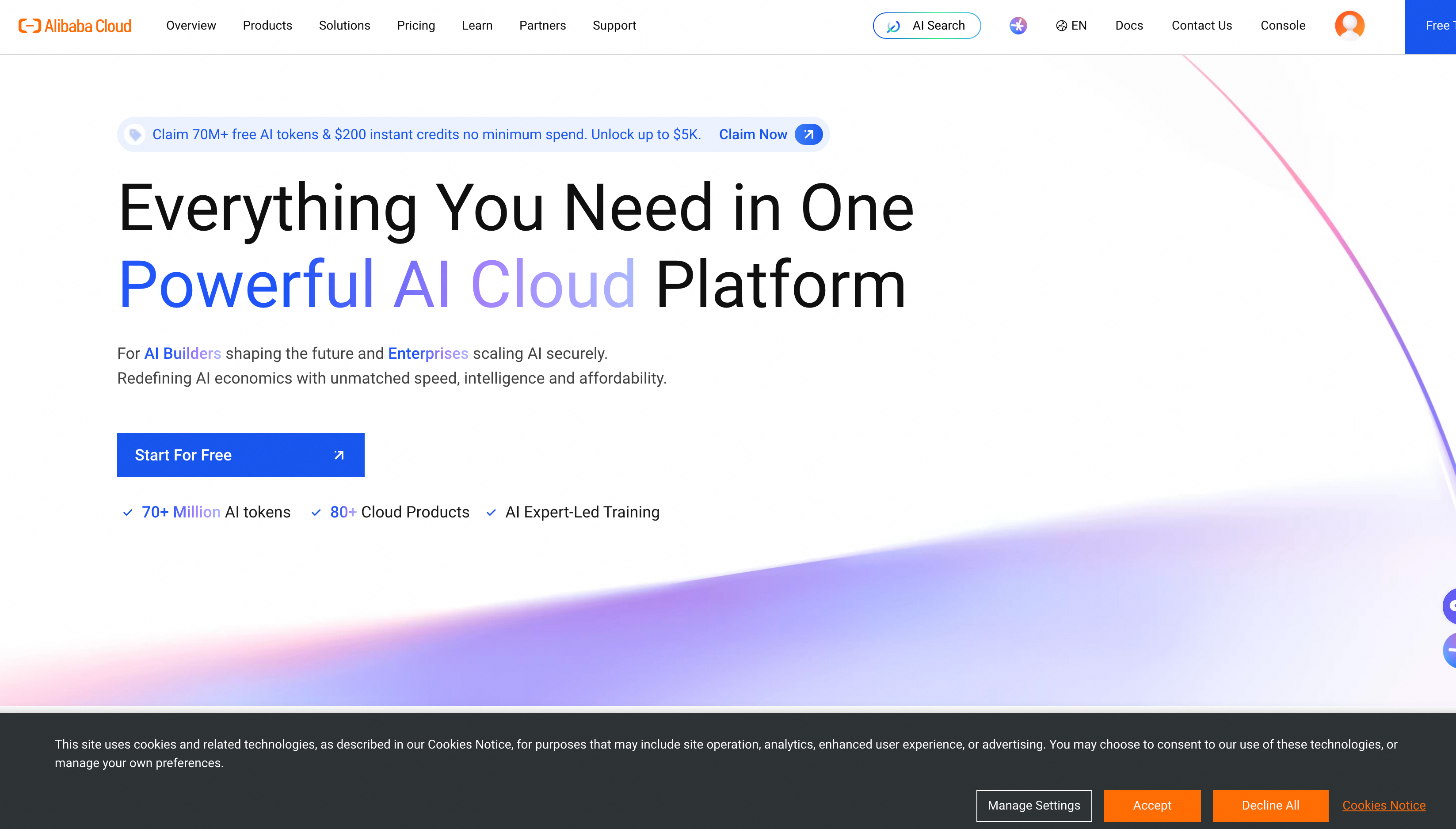
claudeを実行して Claude Code を起動し、次に/model glm-5を実行してglm-5モデルに切り替えます。と alibabacloud.png をプロジェクトディレクトリにダウンロードし、次の質問をします:
Load the image-analyzer skill and describe the information displayed in the alibabacloud.png banner.次の応答が返されます:
{kind=link}
OpenCode
エージェントの追加
プロジェクトディレクトリ内の
.opencodeフォルダ内に、新しいagentsフォルダを作成します。mkdir -p .opencode/agentsこのフォルダ内に、
image-analyzer.mdファイルを作成し、以下のコンテンツを追加します。説明モデルフィールドは、OpenCode 構成ファイルで定義されているプロバイダーとモデル名を使用する必要があります。たとえば、OpenCode ドキュメントの構成に基づくと、値は
bailian-coding-plan/qwen3.5-plusです。--- description: ビジョン対応モデルを使用して画像を分析します。ユーザーが画像コンテンツの理解、スクリーンショット、図、UI モックアップ、またはあらゆる視覚コンテンツからの情報抽出を必要とする場合に、このエージェントを使用します。@image-analyzer の後に画像パスと質問を続けて呼び出します。 mode: subagent model: bailian-coding-plan/qwen3.5-plus tools: write: false edit: false --- あなたはビジョン機能を備えています。提供された画像を分析し、ユーザーが尋ねている内容に焦点を当てた、明確で構造化された説明を返します。結果のフォルダ構造は次のとおりです。
.opencode/ └── agents/ └── image-analyzer.md使用開始
プロジェクトディレクトリで
opencodeを実行して OpenCode を起動し、次にglm-5モデルに切り替えます。プロジェクトフォルダに および alibabacloud.png をダウンロードし、
@アットマークを使用してimage-analyzerを呼び出し、その後以下の質問を行います:@image-analyzer alibabacloud.png のバナーに表示されている情報を説明してください。次の応答が返されます: