MaxCompute では、DELETE および UPDATE 操作を使用して、トランザクションテーブルと Delta テーブルの行レベルでデータを削除または更新できます。
以下のプラットフォームで文を実行できます。
前提条件
DELETE または UPDATE 操作を実行する前に、ターゲットのトランザクションテーブルまたは Delta テーブルに対する Select および Update 権限が必要です。権限付与の詳細については、「MaxCompute の権限」をご参照ください。
機能紹介
従来のデータベースでの使用と同様に、MaxCompute の DELETE および UPDATE 機能は、テーブル内の特定の行を削除または更新できます。
DELETE または UPDATE 機能を使用すると、システムは削除または更新操作ごとに自動的に Delta ファイルを生成します。このファイルはユーザーには表示されず、削除または更新されたデータに関する情報を記録します。実装は次のように機能します。
DELETE:Delta ファイルはtxnid(BIGINT)およびrowid(BIGINT)フィールドを使用して、トランザクションテーブルのベースファイル内のどのレコードがどの削除操作で削除されたかを識別します。ベースファイルは、テーブルの基盤となるストレージフォーマットです。たとえば、テーブル t1 のベースファイルが f1 で、そのコンテンツが
a, b, c, a, bであると仮定します。DELETE FROM t1 WHERE c1='a';コマンドを実行すると、システムは別のf1.deltaファイルを生成します。txnidがt0の場合、f1.deltaのコンテンツは((0, t0), (3, t0))になります。 これは、トランザクション t0 で行 0 と行 3 が削除されたことを示しています。 別のDELETE操作を実行すると、システムはf2.deltaのような別の Delta ファイルを生成します。 このファイルも元のベースファイル f1 を参照します。 データをクエリすると、システムはベースファイル f1 とすべての現在の Delta ファイルを結合して、削除されていないレコードのみを取得します。UPDATE:UPDATE操作は、DELETE操作とINSERT INTO操作として実装されます。
DELETE および UPDATE 機能には、次の利点があります。
書き込みデータ量の削減
以前は、MaxCompute は
INSERT INTOまたはINSERT OVERWRITE操作を使用してテーブルデータを削除または更新していました。詳細については、「データの挿入または上書き (INSERT INTO | INSERT OVERWRITE)」をご参照ください。テーブルまたはパーティション内の少量のデータを更新する必要がある場合、INSERT操作を使用するには、まずテーブルからすべてのデータを読み取り、SELECT操作でデータを更新し、最後にINSERT操作ですべてのデータをテーブルに書き戻す必要がありました。この方法は非効率でした。DELETEまたはUPDATE機能を使用すると、システムはすべてのデータを書き戻す必要がなくなり、書き込まれるデータ量が大幅に削減されます。説明従量課金方法では、
DELETE、UPDATE、およびINSERT OVERWRITEジョブの書き込み操作には課金されません。ただし、DELETEおよびUPDATEジョブは、削除対象のレコードをマークしたり、更新されたレコードを書き戻したりするために、パーティションからデータを読み取る必要があります。これらの読み取り操作は、SQL ジョブの従量課金モデルに基づいて引き続き課金されます。したがって、DELETEおよびUPDATEジョブは、書き込まれるデータが少ないにもかかわらず、INSERT OVERWRITEジョブと比較して必ずしもコストを削減するわけではありません。サブスクリプション課金方法では、
DELETEおよびUPDATEは消費する書き込みリソースが少なくなります。INSERT OVERWRITEと比較して、同じリソースでより多くのジョブを実行できます。
テーブルの最新状態を直接読み取り
以前は、MaxCompute はバッチデータ更新にジッパーテーブルを使用していました。この方法では、レコードのライフサイクルを追跡するために、
start_dateやend_dateなどの補助列をテーブルに追加する必要がありました。テーブルの最新の状態をクエリするには、システムはタイムスタンプに基づいて大量のデータをフィルタリングして現在の状態を見つける必要があり、これは複雑でした。DELETEおよびUPDATE機能を使用すると、テーブルの最新の状態を直接読み取ることができます。システムはベースファイルと Delta ファイルを組み合わせて、データの現在のビューを提供します。
DELETE および UPDATE 操作を複数回実行すると、トランザクションテーブルの基盤となるストレージが増加します。これにより、ストレージコストが増加し、その後のクエリパフォーマンスが低下します。基盤となるデータは定期的にマージ (コンパクト化) する必要があります。マージ操作の詳細については、「トランザクションテーブルのマージ」をご参照ください。
同じターゲットテーブルで複数のジョブが同時に実行されると、ジョブの競合が発生する可能性があります。詳細については、「ACID セマンティクス」をご参照ください。
利用シーン
DELETE および UPDATE 機能は、テーブルまたはパーティション内の少量のデータのランダムで低頻度の削除または更新に適しています。たとえば、毎日 (T+1) ベースで、テーブルまたはパーティションの行の 5% 未満に対して定期的にバッチ削除または更新を実行できます。
DELETE および UPDATE 機能は、高頻度の更新、削除、またはターゲットテーブルへのリアルタイム書き込みには適していません。
制限事項
DELETEおよびUPDATE機能は、トランザクションテーブルと Delta テーブルでのみ使用でき、以下の制限があります。説明トランザクションテーブルと Delta テーブルの詳細については、「トランザクションテーブルと Delta テーブルのパラメーター」をご参照ください。
Delta テーブルの
UPDATE構文は、プライマリキー (PK) 列の変更をサポートしていません。
注意事項
DELETE または UPDATE 操作を使用してテーブルまたはパーティションのデータを削除または更新する場合は、次の項目を考慮してください。
テーブル内の少量のデータを削除または更新し、操作とその後の読み取りの両方が低頻度である場合は、
DELETEおよびUPDATE操作を使用します。複数の削除または更新操作を実行した後、テーブルのベースファイルと Delta ファイルをマージして、ストレージフットプリントを削減します。詳細については、「トランザクションテーブルのマージ」をご参照ください。多数の行 (5% 以上) を低頻度で削除または更新するが、その後のテーブルに対する読み取り操作が頻繁である場合は、
INSERT OVERWRITEまたはINSERT INTOを使用します。詳細については、「データの挿入または上書き (INSERT INTO | INSERT OVERWRITE)」をご参照ください。たとえば、あるビジネスシナリオでは、1 日に 10 回、データの 10% を削除または更新します。
DELETEおよびUPDATE操作によるコストとその後の読み取りパフォーマンスの低下が、各操作でINSERT OVERWRITEまたはINSERT INTOを使用する場合よりも低いかどうかを評価します。特定のシナリオで 2 つの方法の効率を比較して、より適切なオプションを選択してください。データを削除すると Delta ファイルが生成されます。つまり、この操作ではストレージはすぐには削減されません。
DELETE操作を使用してストレージを削減したい場合は、テーブルのベースファイルと Delta ファイルをマージする必要があります。詳細については、「トランザクションテーブルのマージ」をご参照ください。MaxCompute は
DELETEおよびUPDATEジョブをバッチプロセスとして実行します。各文はリソースを消費し、料金が発生します。データはバッチで削除または更新する必要があります。たとえば、Python スクリプトを使用して、各文が 1 行または数行のみを操作する多数の行レベルの更新ジョブを生成して送信する場合、各文は SQL によってスキャンされる入力データの量に基づいてコストが発生します。このような多数の文の累積コストは、費用を大幅に増加させ、システム効率を低下させます。以下にコマンドの例を示します。推奨される方法:
UPDATE table1 SET col1= (SELECT value1 FROM table2 WHERE table1.id = table2.id AND table1.region = table2.region);推奨されない方法:
UPDATE table1 SET col1=1 WHERE id='2021063001' AND region='beijing'; UPDATE table1 SET col1=2 WHERE id='2021063002' AND region='beijing';
データの削除 (DELETE)
DELETE 操作は、トランザクションテーブルまたは Delta テーブルから指定された条件を満たす 1 つ以上の行を削除します。
構文
DELETE FROM <table_name> [[AS] alias] [WHERE <condition>];パラメーター
パラメーター
必須
説明
table_name
はい
DELETE操作を実行するトランザクションテーブルまたは Delta テーブルの名前。alias
いいえ
テーブルのエイリアス。
where_condition
いいえ
条件を満たすデータをフィルタリングするための WHERE 句。WHERE 句の詳細については、「WHERE 句 (WHERE_condition)」をご参照ください。WHERE 句を含めない場合、テーブル内のすべてのデータが削除されます。
例
例 1:acid_delete という名前の非パーティションテーブルを作成し、データをインポートしてから、
DELETE操作を実行して指定された条件を満たす行を削除します。以下にコマンドの例を示します。-- acid_delete という名前のトランザクションテーブルを作成します。 CREATE TABLE IF NOT EXISTS acid_delete (id BIGINT) TBLPROPERTIES ("transactional"="true"); -- データを挿入します。 INSERT OVERWRITE TABLE acid_delete VALUES (1), (2), (3), (2); -- 挿入されたデータを表示します。 SELECT * FROM acid_delete; +------------+ | id | +------------+ | 1 | | 2 | | 3 | | 2 | +------------+ -- id が 2 の行を削除します。このコマンドを MaxCompute クライアント (odpscmd) で実行する場合、確認のために yes または no を入力する必要があります。 DELETE FROM acid_delete WHERE id = 2; -- 上記のコマンドは以下と同等です。 DELETE FROM acid_delete ad WHERE ad.id = 2; -- 結果を表示します。テーブルには 1 と 3 のデータのみが含まれるようになります。 SELECT * FROM acid_delete; +------------+ | id | +------------+ | 1 | | 3 | +------------+例 2:acid_delete_pt という名前のパーティションテーブルを作成し、データをインポートしてから、
DELETE操作を実行して指定された条件を満たす行を削除します。以下にコマンドの例を示します。-- acid_delete_pt という名前のトランザクションテーブルを作成します。 CREATE TABLE IF NOT EXISTS acid_delete_pt (id BIGINT) PARTITIONED BY (ds STRING) TBLPROPERTIES ("transactional"="true"); -- パーティションを追加します。 ALTER TABLE acid_delete_pt ADD IF NOT EXISTS PARTITION (ds = '2019'); ALTER TABLE acid_delete_pt ADD IF NOT EXISTS PARTITION (ds = '2018'); -- データを挿入します。 INSERT OVERWRITE TABLE acid_delete_pt PARTITION (ds = '2019') VALUES (1), (2), (3); INSERT OVERWRITE TABLE acid_delete_pt PARTITION (ds = '2018') VALUES (1), (2), (3); -- 挿入されたデータを表示します。 SELECT * FROM acid_delete_pt; +------------+------------+ | id | ds | +------------+------------+ | 1 | 2018 | | 2 | 2018 | | 3 | 2018 | | 1 | 2019 | | 2 | 2019 | | 3 | 2019 | +------------+------------+ -- パーティションが 2019 で id が 2 のデータを削除します。このコマンドを MaxCompute クライアント (odpscmd) で実行する場合、確認のために yes または no を入力する必要があります。 DELETE FROM acid_delete_pt WHERE ds = '2019' AND id = 2; -- 結果を表示します。パーティションが 2019 で id が 2 のデータが削除されました。 SELECT * FROM acid_delete_pt; +------------+------------+ | id | ds | +------------+------------+ | 1 | 2018 | | 2 | 2018 | | 3 | 2018 | | 1 | 2019 | | 3 | 2019 | +------------+------------+例 3:acid_delete_t という名前のターゲットテーブルと acid_delete_s という名前の関連テーブルを作成します。次に、JOIN 操作によって指定された条件を満たす行を削除します。以下にコマンドの例を示します。
-- acid_delete_t という名前のターゲットトランザクションテーブルと acid_delete_s という名前の関連テーブルを作成します。 CREATE TABLE IF NOT EXISTS acid_delete_t (id INT, value1 INT, value2 INT) TBLPROPERTIES ("transactional"="true"); CREATE TABLE IF NOT EXISTS acid_delete_s (id INT, value1 INT, value2 INT); -- データを挿入します。 INSERT OVERWRITE TABLE acid_delete_t VALUES (2, 20, 21), (3, 30, 31), (4, 40, 41); INSERT OVERWRITE TABLE acid_delete_s VALUES (1, 100, 101), (2, 200, 201), (3, 300, 301); -- acid_delete_s テーブルの id と一致しない id を持つ行を acid_delete_t テーブルから削除します。このコマンドを MaxCompute クライアント (odpscmd) で実行する場合、確認のために yes または no を入力する必要があります。 DELETE FROM acid_delete_t WHERE NOT EXISTS (SELECT * FROM acid_delete_s WHERE acid_delete_t.id = acid_delete_s.id); -- 上記のコマンドは以下と同等です。 DELETE FROM acid_delete_t a WHERE NOT EXISTS (SELECT * FROM acid_delete_s b WHERE a.id = b.id); -- 結果を表示します。テーブルには id 2 と 3 のデータのみが含まれるようになります。 SELECT * FROM acid_delete_t; +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 20 | 21 | | 3 | 30 | 31 | +------------+------------+------------+例 4:mf_dt という名前の Delta テーブルを作成し、データをインポートしてから、DELETE 操作を実行して指定された条件を満たす行を削除します。以下にコマンドの例を示します。
-- mf_dt という名前のターゲット Delta テーブルを作成します。 CREATE TABLE IF NOT EXISTS mf_dt (pk BIGINT NOT NULL PRIMARY KEY, val BIGINT NOT NULL) PARTITIONED BY(dd STRING, hh STRING) tblproperties ("transactional"="true"); -- データを挿入します。 INSERT OVERWRITE TABLE mf_dt PARTITION (dd='01', hh='02') VALUES (1, 1), (2, 2), (3, 3); -- 挿入されたデータを表示します。 SELECT * FROM mf_dt WHERE dd='01' AND hh='02'; -- 次の結果が返されます。 +------------+------------+----+----+ | pk | val | dd | hh | +------------+------------+----+----+ | 1 | 1 | 01 | 02 | | 3 | 3 | 01 | 02 | | 2 | 2 | 01 | 02 | +------------+------------+----+----+ -- パーティションが 01 と 02 で、val が 2 のデータを削除します。 DELETE FROM mf_dt WHERE val = 2 AND dd='01' AND hh='02'; -- 結果を表示します。テーブルには val が 1 と 3 のデータのみが含まれるようになります。 SELECT * FROM mf_dt WHERE dd='01' AND hh='02'; -- 次の結果が返されます。 +------------+------------+----+----+ | pk | val | dd | hh | +------------+------------+----+----+ | 1 | 1 | 01 | 02 | | 3 | 3 | 01 | 02 | +------------+------------+----+----+
列データのクリア
CLEAR COLUMN コマンドを使用して、標準テーブルの列からデータをクリアできます。この操作は、使用されなくなったデータをディスクから削除し、列の値を NULL に設定することで、ストレージコストの削減に役立ちます。
構文
ALTER TABLE <table_name> [PARTITION ( <pt_spec>[, <pt_spec>....] )] CLEAR COLUMN column1[, column2, column3, ...] [WITHOUT TOUCH];パラメーター
パラメーター
説明
table_name
列データをクリアするテーブルの名前。
column1 , column2 ...データをクリアする列の名前。
PARTITION
パーティションを指定します。指定しない場合、操作はすべてのパーティションに適用されます。
pt_spec
パーティションの説明。フォーマットは
(partition_col1 = PARTITION_col_value1, PARTITION_col2 = PARTITION_col_value2, ...)です。WITHOUT TOUCH
指定した場合、
LastDataModifiedTimeは更新されません。指定しない場合、LastDataModifiedTimeは更新されます。説明現在、`WITHOUT TOUCH` はデフォルトで指定されています。将来のリリースでは、`WITHOUT TOUCH` を指定せずに列データをクリアする動作がサポートされる予定です。つまり、`WITHOUT TOUCH` が指定されていない場合、
LastDataModifiedTimeは更新されます。制限事項
NOT NULL 制約のある列に対して列クリア操作を実行することはできません。NOT NULL 制約は手動で削除できます。
ALTER TABLE <table_name> change COLUMN <old_col_name> NULL;ACID テーブルでは列データのクリアはサポートされていません。
クラスター化テーブルでは列データのクリアはサポートされていません。
ネストされた型内の列データのクリアはサポートされていません。
すべての列のクリアはサポートされていません。`DROP TABLE` コマンドは同じ効果をより良いパフォーマンスで実現します。
注意事項
`CLEAR COLUMN` 操作は、テーブルの Archive プロパティを変更しません。
ネストされた型の列に対する `CLEAR COLUMN` 操作は失敗する可能性があります。
この失敗は、ネストされた型の列指向ストレージが無効になっている間に、列指向のネストされた型を含むテーブルに対して `CLEAR COLUMN` 操作を実行した場合に発生します。
`CLEAR COLUMN` コマンドはオンラインのストレージサービスに依存します。ジョブ量が多い期間中は、タスクがキューに入れられる必要がある場合、遅くなる可能性があります。
`CLEAR COLUMN` 操作には、データの読み取りと書き込みのためのコンピューティングリソースが必要です。サブスクリプションユーザーの場合、これはコンピューティングリソースを消費します。従量課金ユーザーの場合、SQL ジョブと同じ料金が発生します。(この機能は現在、招待プレビュー中であり、一時的に無料です。)
例
-- テーブルを作成します。 CREATE TABLE IF NOT EXISTS mf_cc(key STRING, value STRING, a1 BIGINT , a2 BIGINT , a3 BIGINT , a4 BIGINT) PARTITIONED BY(ds STRING, hr STRING); -- パーティションを追加します。 ALTER TABLE mf_cc ADD IF NOT EXISTS PARTITION (ds='20230509', hr='1641'); -- データを挿入します。 INSERT INTO mf_cc PARTITION (ds='20230509', hr='1641') VALUES("key","value",1,22,3,4); -- データをクエリします。 SELECT * FROM mf_cc WHERE ds='20230509' AND hr='1641'; -- 次の結果が返されます。 +-----+-------+------------+------------+--------+------+---------+-----+ | key | value | a1 | a2 | a3 | a4 | ds | hr | +-----+-------+------------+------------+--------+------+---------+-----+ | key | value | 1 | 22 | 3 | 4 | 20230509| 1641| +-----+-------+------------+------------+--------+------+---------+-----+ -- 列データをクリアします。 ALTER TABLE mf_cc PARTITION(ds='20230509', hr='1641') CLEAR COLUMN key,a1 WITHOUT TOUCH; -- データをクエリします。 SELECT * FROM mf_cc WHERE ds='20230509' AND hr='1641'; -- 次の結果が返されます。key 列と a1 列のデータが null になりました。 +-----+-------+------------+------------+--------+------+---------+-----+ | key | value | a1 | a2 | a3 | a4 | ds | hr | +-----+-------+------------+------------+--------+------+---------+-----+ | null| value | null | 22 | 3 | 4 | 20230509| 1641| +-----+-------+------------+------------+--------+------+---------+-----+次の図は、`CLEAR COLUMN` コマンドを使用して各列がクリアされるにつれて、
lineitemテーブル (AliORC フォーマット) の合計ストレージサイズがどのように変化するかを示しています。lineitemテーブルには、BIGINT、DECIMAL、CHAR、DATE、VARCHAR など、さまざまな型の 16 列があります。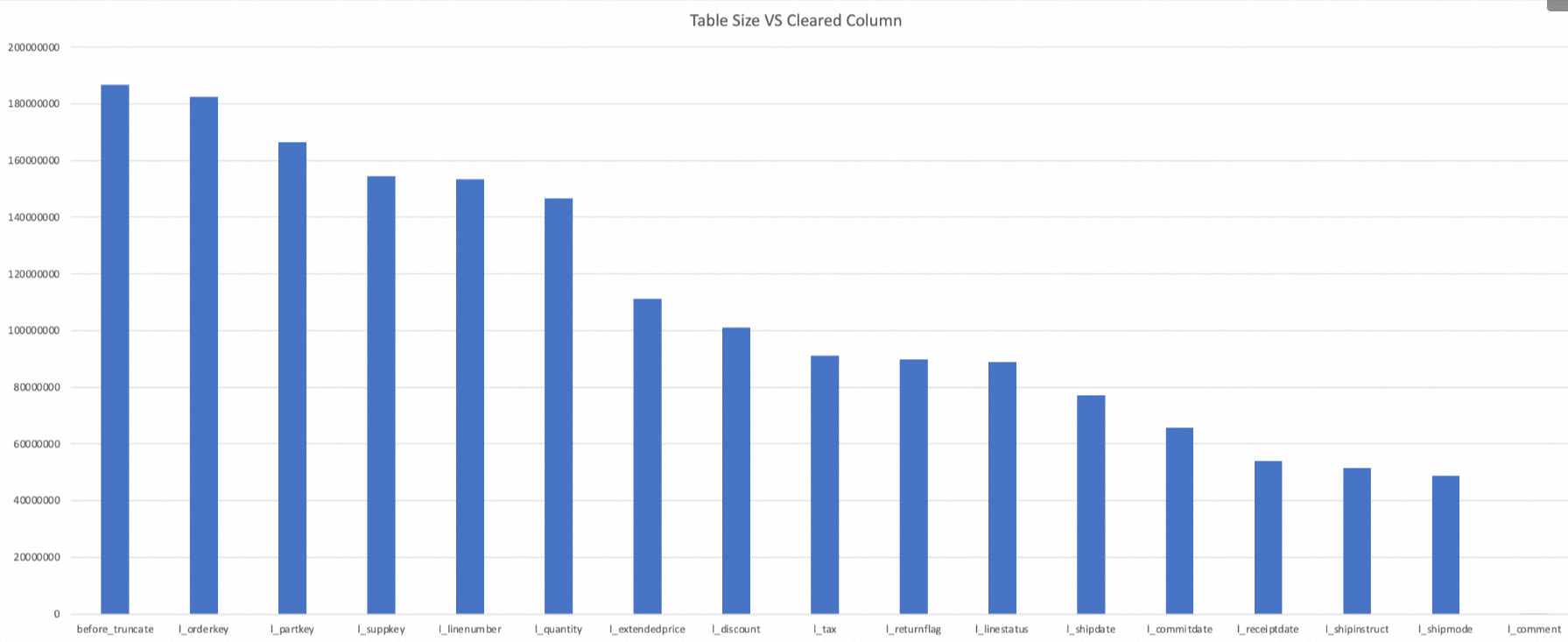
ご覧のとおり、`CLEAR COLUMN` コマンドによってテーブルの 16 列が順次 NULL に設定された後、合計ストレージスペースは 99.97% 削減されました (初期の 186,783,526 バイトから 236,715 バイトへ)。
説明`CLEAR COLUMN` 操作によって節約されるスペースの量は、列のデータ型と実際に保存されている値によって異なります。たとえば、DECIMAL 型の
l_extendedprice列をクリアすると、スペースが 24.2% 節約され (146,538,799 バイトから 111,138,117 バイトへ)、これは平均よりも大幅に優れています。すべての列が NULL に設定されると、テーブルサイズは 236,715 バイトになり、0 にはなりません。これは、テーブルのファイル構造がまだ存在するためです。NULL フィールドは少量のストレージスペースを占有し、システムはファイルフッター情報も保持する必要があります。
データの更新 (UPDATE)
UPDATE 操作は、トランザクションテーブルまたは Delta テーブルの行の 1 つ以上の列の値を更新します。
構文
-- 方法 1 UPDATE <table_name> [[AS] alias] SET <col1_name> = <value1> [, <col2_name> = <value2> ...] [WHERE <where_condition>]; -- 方法 2 UPDATE <table_name> [[AS] alias] SET (<col1_name> [, <col2_name> ...]) = (<value1> [, <value2> ...]) [WHERE <where_condition>]; -- 方法 3 UPDATE <table_name> [[AS] alias] SET <col1_name> = <value1> [, <col2_name> = <value2>, ...] [FROM <additional_tables>] [WHERE <where_condition>];パラメーター
table_name:必須。
UPDATE操作の対象となるトランザクションテーブルまたは Delta テーブルの名前。alias:任意。テーブルのエイリアス。
col1_name, col2_name:必須。変更する列の名前。少なくとも 1 つの列を更新する必要があります。
value1, value2:必須。列の新しい値。少なくとも 1 つの列の値を更新する必要があります。
where_condition:任意。データをフィルタリングするための WHERE 句。WHERE 句の詳細については、「SELECT 構文」をご参照ください。WHERE 句を含めない場合、テーブル内のすべてのデータが更新されます。
additional_tables:任意。FROM 句。
UPDATE文は FROM 句をサポートしており、これによりUPDATE文を簡素化できます。次の表は、FROM 句を使用する UPDATE 文と使用しない UPDATE 文を比較したものです。シナリオ
サンプルコード
FROM 句なし
UPDATE target SET v = (SELECT MIN(v) FROM src GROUP BY k WHERE target.k = src.key) WHERE target.k IN (SELECT k FROM src);FROM 句あり
UPDATE target SET v = b.v FROM (SELECT k, MIN(v) AS v FROM src GROUP BY k) b WHERE target.k = b.k;コード例が示すように:
ソーステーブルの複数の行を使用してターゲットテーブルの 1 行を更新する場合、システムはどのソース行を使用するかを判断できないため、集約操作を使用してソースデータが一意であることを保証する必要があります。`FROM` 句を使用しない構文は、あまり簡潔ではありません。`FROM` 句を使用する構文は、よりシンプルで理解しやすいです。
JOIN 更新を実行する場合、データの共通部分のみを更新したい場合、`FROM` 句を使用しない構文は追加の `WHERE` 条件が必要となり、`FROM` 句を使用する構文よりも簡潔ではありません。
例
例 1:acid_update という名前の非パーティションテーブルを作成し、データをインポートしてから、
UPDATE操作を実行して指定された条件を満たす行の列を更新します。以下にコマンドの例を示します。-- acid_update という名前のトランザクションテーブルを作成します。 CREATE TABLE IF NOT EXISTS acid_update(id BIGINT) tblproperties ("transactional"="true"); -- データを挿入します。 INSERT OVERWRITE TABLE acid_update VALUES(1),(2),(3),(2); -- 挿入されたデータを表示します。 SELECT * FROM acid_update; -- 次の結果が返されます。 +------------+ | id | +------------+ | 1 | | 2 | | 3 | | 2 | +------------+ -- id が 2 のすべての行の id 値を 4 に更新します。 UPDATE acid_update SET id = 4 WHERE id = 2; -- 更新結果を表示します。2 が 4 に更新されました。 SELECT * FROM acid_update; -- 次の結果が返されます。 +------------+ | id | +------------+ | 1 | | 3 | | 4 | | 4 | +------------+例 2:acid_update という名前のパーティションテーブルを作成し、データをインポートしてから、
UPDATE操作を実行して指定された条件を満たす行の列を更新します。以下にコマンドの例を示します。-- acid_update_pt という名前のトランザクションテーブルを作成します。 CREATE TABLE IF NOT EXISTS acid_update_pt(id BIGINT) PARTITIONED BY(ds STRING) tblproperties ("transactional"="true"); -- パーティションを追加します。 ALTER TABLE acid_update_pt ADD IF NOT EXISTS PARTITION (ds= '2019'); -- データを挿入します。 INSERT OVERWRITE TABLE acid_update_pt PARTITION (ds='2019') VALUES(1),(2),(3); -- 挿入されたデータを表示します。 SELECT * FROM acid_update_pt WHERE ds = '2019'; -- 次の結果が返されます。 +------------+------------+ | id | ds | +------------+------------+ | 1 | 2019 | | 2 | 2019 | | 3 | 2019 | +------------+------------+ -- 指定された行の列を更新します。パーティションが 2019 で id が 2 のすべての行の id 値を 4 に設定します。 UPDATE acid_update_pt SET id = 4 WHERE ds = '2019' AND id = 2; -- 更新結果を表示します。2 が 4 に更新されました。 SELECT * FROM acid_update_pt WHERE ds = '2019'; -- 次の結果が返されます。 +------------+------------+ | id | ds | +------------+------------+ | 4 | 2019 | | 1 | 2019 | | 3 | 2019 | +------------+------------+例 3:acid_update_t という名前のターゲットテーブルと acid_update_s という名前の関連テーブルを作成して、複数の列値を同時に更新します。以下にコマンドの例を示します。
-- 更新対象の acid_update_t という名前のターゲットトランザクションテーブルと、acid_update_s という名前の関連テーブルを作成します。 CREATE TABLE IF NOT EXISTS acid_update_t(id INT,value1 INT,value2 INT) tblproperties ("transactional"="true"); CREATE TABLE IF NOT EXISTS acid_update_s(id INT,value1 INT,value2 INT); -- データを挿入します。 INSERT OVERWRITE TABLE acid_update_t VALUES(2,20,21),(3,30,31),(4,40,41); INSERT OVERWRITE TABLE acid_update_s VALUES(1,100,101),(2,200,201),(3,300,301); -- 方法 1:定数で更新します。 UPDATE acid_update_t SET (value1, value2) = (60,61); -- 方法 1 のターゲットテーブルの結果データをクエリします。 SELECT * FROM acid_update_t; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 60 | 61 | | 3 | 60 | 61 | | 4 | 60 | 61 | +------------+------------+------------+ -- 方法 2:JOIN 更新。ルールは acid_update_t から acid_update_s への左 JOIN です。 UPDATE acid_update_t SET (value1, value2) = (SELECT value1, value2 FROM acid_update_s WHERE acid_update_t.id = acid_update_s.id); -- 方法 2 のターゲットテーブルの結果データをクエリします。 SELECT * FROM acid_update_t; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 200 | 201 | | 3 | 300 | 301 | | 4 | NULL | NULL | +------------+------------+------------+ -- 方法 3 (方法 2 の結果に基づく更新):JOIN 更新。ルールは、共通部分のみを更新するためのフィルター条件を追加することです。 UPDATE acid_update_t SET (value1, value2) = (SELECT value1, value2 FROM acid_update_s WHERE acid_update_t.id = acid_update_s.id) WHERE acid_update_t.id IN (SELECT id FROM acid_update_s); -- 方法 3 のターゲットテーブルの結果データをクエリします。 SELECT * FROM acid_update_t; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 200 | 201 | | 3 | 300 | 301 | | 4 | NULL | NULL | +------------+------------+------------+ -- 方法 4 (方法 3 の結果に基づく更新):集約結果を使用した JOIN 更新。 UPDATE acid_update_t SET (id, value1, value2) = (SELECT id, MAX(value1),MAX(value2) FROM acid_update_s WHERE acid_update_t.id = acid_update_s.id GROUP BY acid_update_s.id) WHERE acid_update_t.id IN (SELECT id FROM acid_update_s); -- 方法 4 のターゲットテーブルの結果データをクエリします。 SELECT * FROM acid_update_t; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 200 | 201 | | 3 | 300 | 301 | | 4 | NULL | NULL | +------------+------------+------------+例 4:2 つのテーブルを含む単純な JOIN クエリ。以下にコマンドの例を示します。
-- 更新用のターゲットテーブル acid_update_t と、関連テーブル acid_update_s を作成します。 CREATE TABLE IF NOT EXISTS acid_update_t(id BIGINT,value1 BIGINT,value2 BIGINT) tblproperties ("transactional"="true"); CREATE TABLE IF NOT EXISTS acid_update_s(id BIGINT,value1 BIGINT,value2 BIGINT); -- データを挿入します。 INSERT OVERWRITE TABLE acid_update_t VALUES(2,20,21),(3,30,31),(4,40,41); INSERT OVERWRITE TABLE acid_update_s VALUES(1,100,101),(2,200,201),(3,300,301); -- acid_update_t テーブルからデータをクエリします。 SELECT * FROM acid_update_t; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 20 | 21 | | 3 | 30 | 31 | | 4 | 40 | 41 | +------------+------------+------------+ -- acid_update_s テーブルからデータをクエリします。 SELECT * FROM acid_update_s; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 1 | 100 | 101 | | 2 | 200 | 201 | | 3 | 300 | 301 | +------------+------------+------------+ -- JOIN 更新。ターゲットテーブルにフィルター条件を追加して、共通部分のみを更新します。 UPDATE acid_update_t SET value1 = b.value1, value2 = b.value2 FROM acid_update_s b WHERE acid_update_t.id = b.id; -- 上記のコマンドは以下と同等です。 UPDATE acid_update_t a SET a.value1 = b.value1, a.value2 = b.value2 FROM acid_update_s b WHERE a.id = b.id; -- 更新結果を表示します。20 は 200 に、21 は 201 に、30 は 300 に、31 は 301 に更新されます。 SELECT * FROM acid_update_t; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 4 | 40 | 41 | | 2 | 200 | 201 | | 3 | 300 | 301 | +------------+------------+------------+例 5:複数のテーブルを含む複雑な JOIN クエリ。以下にコマンドの例を示します。
-- 更新用のターゲットテーブル acid_update_t と、関連テーブル acid_update_s を作成します。 CREATE TABLE IF NOT EXISTS acid_update_t(id BIGINT,value1 BIGINT,value2 BIGINT) tblproperties ("transactional"="true"); CREATE TABLE IF NOT EXISTS acid_update_s(id BIGINT,value1 BIGINT,value2 BIGINT); CREATE TABLE IF NOT EXISTS acid_update_m(id BIGINT,value1 BIGINT,value2 BIGINT); -- データを挿入します。 INSERT OVERWRITE TABLE acid_update_t VALUES(2,20,21),(3,30,31),(4,40,41),(5,50,51); INSERT OVERWRITE TABLE acid_update_s VALUES (1,100,101),(2,200,201),(3,300,301),(4,400,401),(5,500,501); INSERT OVERWRITE TABLE acid_update_m VALUES(3,30,101),(4,400,201),(5,300,301); -- acid_update_t テーブルからデータをクエリします。 SELECT * FROM acid_update_t; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 2 | 20 | 21 | | 3 | 30 | 31 | | 4 | 40 | 41 | | 5 | 50 | 51 | +------------+------------+------------+ -- acid_update_s テーブルからデータをクエリします。 SELECT * FROM acid_update_s; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 1 | 100 | 101 | | 2 | 200 | 201 | | 3 | 300 | 301 | | 4 | 400 | 401 | | 5 | 500 | 501 | +------------+------------+------------+ -- acid_update_m テーブルからデータをクエリします。 SELECT * FROM acid_update_m; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 3 | 30 | 101 | | 4 | 400 | 201 | | 5 | 300 | 301 | +------------+------------+------------+ -- JOIN 更新、WHERE 句でソーステーブルとターゲットテーブルの両方をフィルタリングします。 UPDATE acid_update_t SET value1 = acid_update_s.value1, value2 = acid_update_s.value2 FROM acid_update_s WHERE acid_update_t.id = acid_update_s.id AND acid_update_s.id > 2 AND acid_update_t.value1 NOT IN (SELECT value1 FROM acid_update_m WHERE id = acid_update_t.id) AND acid_update_s.value1 NOT IN (SELECT value1 FROM acid_update_m WHERE id = acid_update_s.id); -- 更新結果を表示します。acid_update_t テーブルの id 5 のデータのみが条件を満たします。対応する value1 は 500 に、value2 は 501 に更新されます。 SELECT * FROM acid_update_t; -- 次の結果が返されます。 +------------+------------+------------+ | id | value1 | value2 | +------------+------------+------------+ | 5 | 500 | 501 | | 2 | 20 | 21 | | 3 | 30 | 31 | | 4 | 40 | 41 | +------------+------------+------------+例 6:次のコマンドは、mf_dt という名前の Delta テーブルを作成し、データをインポートし、
UPDATE操作を実行して指定された条件を満たす行を削除する方法の例です。-- mf_dt という名前のターゲット Delta テーブルを作成します。 CREATE TABLE IF NOT EXISTS mf_dt (pk BIGINT NOT NULL PRIMARY KEY, val BIGINT NOT NULL) PARTITIONED BY(dd STRING, hh STRING) tblproperties ("transactional"="true"); -- データを挿入します。 INSERT OVERWRITE TABLE mf_dt PARTITION (dd='01', hh='02') VALUES (1, 1), (2, 2), (3, 3); -- 挿入されたデータを表示します。 SELECT * FROM mf_dt WHERE dd='01' AND hh='02'; -- 次の結果が返されます。 +------------+------------+----+----+ | pk | val | dd | hh | +------------+------------+----+----+ | 1 | 1 | 01 | 02 | | 3 | 3 | 01 | 02 | | 2 | 2 | 01 | 02 | +------------+------------+----+----+ -- 指定された行の列を更新します。パーティションが 01 と 02 で、pk が 3 のすべての行の val 値を 30 に設定します。 -- 方法 1 UPDATE mf_dt SET val = 30 WHERE pk = 3 AND dd='01' AND hh='02'; -- 方法 2 UPDATE mf_dt SET val = delta.val FROM (SELECT pk, val FROM VALUES (3, 30) t (pk, val)) delta WHERE delta.pk = mf_dt.pk AND mf_dt.dd='01' AND mf_dt.hh='02'; -- 更新結果を表示します。 SELECT * FROM mf_dt WHERE dd='01' AND hh='02'; -- 次の結果が返されます。pk=3 の行の val 値が 30 に更新されます。 +------------+------------+----+----+ | pk | val | dd | hh | +------------+------------+----+----+ | 1 | 1 | 01 | 02 | | 3 | 30 | 01 | 02 | | 2 | 2 | 01 | 02 | +------------+------------+----+----+
トランザクションテーブルのマージ
トランザクションテーブルの基盤となる物理ストレージは、直接読み取り不可能なベースファイルと Delta ファイルで構成されています。トランザクションテーブルに対して UPDATE または DELETE 操作を実行すると、ベースファイルは変更されず、代わりに Delta ファイルが追加されます。これは、更新や削除を実行するほど、テーブルが占有するストレージが増えることを意味します。多数の Delta ファイルが蓄積されると、ストレージと後続のクエリコストが増加する可能性があります。
同じテーブルまたはパーティションに対して複数の UPDATE または DELETE 操作を実行すると、多数の Delta ファイルが生成されます。システムがデータを読み取る際、これらの Delta ファイルをロードして、どの行が更新または削除されたかを判断する必要があります。多数の Delta ファイルは、データ読み取りパフォーマンスを低下させる可能性があります。この場合、ベースファイルと Delta ファイルをマージして、ストレージを削減し、データ読み取りパフォーマンスを向上させることができます。
構文
ALTER TABLE <table_name> [PARTITION (<partition_key> = '<partition_value>' [, ...])] compact {minor|major};パラメーター
パラメーター
必須
説明
table_name
はい
ファイルをマージするトランザクションテーブルの名前。
partition_key
いいえ
トランザクションテーブルがパーティションテーブルの場合、パーティションキー列名を指定します。
partition_value
いいえ
トランザクションテーブルがパーティションテーブルの場合、パーティションキー列の値を指定します。
major|minor
はい
どちらかを選択する必要があります。違いは次のとおりです。
minor:ベースファイルとその基盤となるすべての Delta ファイルのみをマージし、Delta ファイルを削除します。major:ベースファイルとその基盤となるすべての Delta ファイルをマージして Delta ファイルを削除するだけでなく、テーブルの対応するベースファイル内の小さなファイルもマージします。ベースファイルが小さい (32 MB 未満) 場合、または Delta ファイルが存在する場合、これはテーブルに対してINSERT OVERWRITE操作を再度実行するのと同等です。ただし、ベースファイルが十分に大きい (32 MB 以上) 場合で、Delta ファイルが存在しない場合は、書き換えられません。注意事項
`compact` 操作によってマージされた小さなファイルは 1 日後に削除されます。ローカルバックアップ機能を使用してこれらの小さなファイルに依存する履歴を復元する場合、ファイルが見つからないため回復は失敗します。
例
例 1:トランザクションテーブル acid_delete のファイルをマージします。以下にコマンドの例を示します。
ALTER TABLE acid_delete compact minor;次の結果が返されます。
Summary: Nothing found to merge, set odps.merge.cross.paths=true if cross path merge is permitted. OK例 2:トランザクションテーブル acid_update_pt のファイルをマージします。以下にコマンドの例を示します。
ALTER TABLE acid_update_pt PARTITION (ds = '2019') compact major;次の結果が返されます。
Summary: table name: acid_update_pt /ds=2019 instance count: 2 run time: 6 before merge, file count: 8 file size: 2613 file physical size: 7839 after merge, file count: 2 file size: 679 file physical size: 2037 OK
よくある質問
問題 1:
問題の説明:
UPDATE文を実行すると、ODPS-0010000:System internal error - fuxi job failed, caused by: Data Set should contain exactly one rowというエラーが報告されます。原因:更新対象の行がサブクエリの結果のデータと 1 対 1 で対応していません。システムはどの行を更新すればよいかを判断できません。以下にコマンドの例を示します。
UPDATE store SET (s_county, s_manager) = (SELECT d_country, d_manager FROM store_delta sd WHERE sd.s_store_sk = store.s_store_sk) WHERE s_store_sk IN (SELECT s_store_sk FROM store_delta);サブクエリ
SELECT d_country, d_manager FROM store_delta sd WHERE sd.s_store_sk = store.s_store_skは store_delta との JOIN に使用され、store_delta のデータが store の更新に使用されます。store テーブルの s_store_sk 列に[1, 2, 3]の 3 行のデータが含まれているとします。store_delta テーブルの s_store_sk 列に[1, 1]の 2 行のデータがある場合、1 対 1 の対応が存在せず、実行は失敗します。解決策:更新対象の行がサブクエリの結果のデータと 1 対 1 で対応していることを確認してください。
問題 2:
問題の説明:DataWorks DataStudio で
compactコマンドを実行すると、ODPS-0130161:[1,39] Parse exception - invalid token 'minor', expect one of 'StringLiteral','DoubleQuoteStringLiteral'というエラーが報告されます。原因:DataWorks の専用リソースグループの MaxCompute クライアントバージョンが
compactコマンドをサポートしていません。解決策:DataWorks の DingTalk グループを通じてテクニカルサポートチームに連絡し、専用リソースグループの MaxCompute クライアントバージョンをアップグレードしてください。