Delta LakeおよびApache Hudiストレージメカニズムは、データレイクソリューションで一般的に使用されています。 これらのストレージメカニズムは、データレイクにストリーム処理およびバッチ処理機能を提供します。 MaxComputeを使用すると、Delta LakeまたはApache Hudiストレージメカニズムをサポートするデータレイクハウスのソリューションを構築できます。 このソリューションは、オープンソースのHadoopクラスターに基づいて開発されています。 MaxComputeを使用して、リアルタイムデータをクエリし、ビジネスデータの変化を即座に把握できます。
背景情報
MaxComputeを使用すると、オープンソースのHadoopクラスターとAlibaba Cloud E-MapReduce (EMR) に基づいて、Delta LakeおよびApache Hudiストレージメカニズムをサポートするデータレイクハウスソリューションを構築できます。 次の図は、このようなデータレイクハウスソリューションのアーキテクチャを示しています。
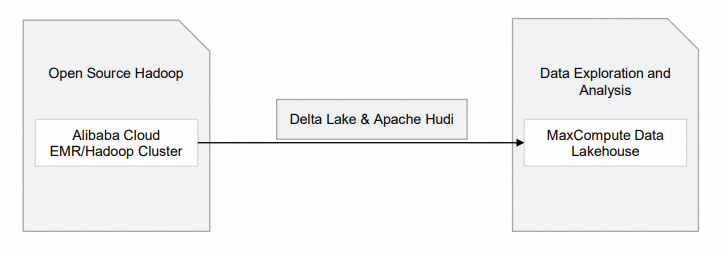
モジュール | Alibaba Cloud サービス | 説明 |
オープンソースHadoop |
| 生データはHadoopクラスターに保存されます。 |
Hadoopクラスターに基づくDelta LakeまたはApache Hudiストレージメカニズムをサポートするデータ湖沼ソリューションを構築する
前提条件
MaxComputeプロジェクトが作成されます。 このプロジェクトは外部プロジェクトではありません。 MaxComputeプロジェクトの作成方法の詳細については、「MaxComputeプロジェクトの作成」をご参照ください。
制限事項
Hadoopクラスターに基づいてDelta LakeまたはApache Hudiストレージメカニズムをサポートするデータレイクハウスソリューションを構築する場合、次の制限事項に注意してください。
データレイクハウスソリューションは、中国 (杭州) 、中国 (上海) 、中国 (北京) 、中国 (深セン) 、中国 (香港) 、シンガポール、ドイツ (フランクフルト) の各リージョンでのみサポートされています。
手順
このトピックでは、データレイクハウスソリューションはEMR Hadoopクラスターに基づいて構築されています。 以下の手順を実行します。
データセンターに構築されている、またはクラウド内の仮想マシン上に構築されているHadoopクラスターが存在する場合は、クラスターを作成する必要はありません。
クラスターにデータベースを作成し、データを準備します。
手順3: MaxComputeに基づいてHadoopクラスター内のデータをリアルタイムで分析します。
DataWorksコンソールのLake and Warehouse Integration (Data Lakehouse) ページで外部プロジェクトを作成し、Hadoopクラスターのデータを分析します。
手順1: EMRクラスターの作成
EMRコンソールでHadoopクラスターを作成します。
EMR Hadoopクラスターの作成方法の詳細については、「EMRのクイックスタート」の「手順1: クラスターの作成」をご参照ください。 次の表に、Hadoopクラスターを作成するときに注意する必要があるパラメーターを示します。 その他のパラメーターの詳細については、EMRドキュメントのパラメーターの説明をご参照ください。
ステップ
パラメーター
例
説明
ソフトウェア設定
ビジネスシナリオ
カスタムクラスター
ビジネス要件に基づいてビジネスシナリオを選択します。
制品バージョン
EMR-3.43.0
Hadoop 2.XまたはHive 2.Xの上に構築されたEMR V3.Xバージョンを選択します。
オプションサービス (少なくとも1つ選択)
Hadoop-共通、HDFS、Hive、YARN、Spark3、Deltalake、Hudi、およびZooKeeper
Hadoop、HDFS、Hive、Spark、Delta Lake、およびHudiコンポーネントを選択すると、関連するサービスプロセスが自動的に有効になります。
メタデータ
組み込みMySQL
[組み込みMySQL] または [自己管理RDS] を選択します。
セルフマネージドRDS: メタデータはセルフマネージドApsaraDB RDSデータベースに保存されます。
[自己管理RDS] を選択した場合、データベース接続に関連するパラメーターを設定する必要があります。 詳細については、「自己管理型ApsaraDB RDS For MySQLデータベースの設定」をご参照ください。
組み込みMySQL: メタデータはクラスターのオンプレミスMySQLデータベースに保存されます。
説明このオプションは、テストシナリオでのみ選択します。 運用シナリオでは、自己管理RDSを選択することを推奨します。
クラスターの作成後、クラスターのアクション列にあるノードをクリックします。
ノードタブで、宛先ノードのIDをクリックします。emr-masterノードグループでElastic Compute Service (ECS) コンソールに移動します。
ECSインスタンスに接続するツールを選択します。 詳細については、「接続方法」をご参照ください。
説明この例では、Workbenchを使用してインスタンスに接続します。 ログインパスワードは、クラスターの作成時に設定するパスワードです。
ステップ2: データを準備する
クラスターにログインした後、Spark SQLを使用してDelta LakeテーブルまたはHudiテーブルを作成できます。
EMR Hudi 0.8.0では、Spark SQLを使用してHudiテーブルに対する読み取りおよび書き込み操作を実行できます。 詳細については、「HudiとSpark SQLの統合」をご参照ください。 この例では、Hudiテーブルが作成されます。 ターミナルで次のコマンドを実行してSpark SQLを起動します。
spark-sql \ --conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \ --conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'Spark SQLを起動したら、次のステートメントを実行してテーブルを作成し、テーブルにデータを挿入します。
説明データベースが作成されていない場合、データはデフォルトのデータベースに自動的に格納されます。
-- Create a table. CREATE TABLE h0 ( id BIGINT, name STRING, price DOUBLE, ts LONG ) USING hudi tblproperties ( primaryKey="id", preCombineField="ts" ); -- Insert data into the table. INSERT INTO h0 VALUES (1, 'a1', 10, 1000); -- Query data from the table. SELECT id, name, price, ts FROM h0;
ステップ3: MaxComputeに基づいてHadoopクラスター内のデータをリアルタイムで分析する
作成したMaxComputeプロジェクトとHadoopクラスターのテーブルデータに基づいて、Hadoopクラスターの外部プロジェクトを作成し、その外部プロジェクトをMaxComputeプロジェクトにマップします。 これにより、マッピングされたMaxComputeプロジェクトを使用して、外部プロジェクトのデータを分析できます。 外部プロジェクトを作成できるのは、MaxComputeプロジェクトの所有者またはAdminロールまたはSuper_Administratorロールが割り当てられているユーザーのみです。
MaxComputeコンソールの [ユーザー] タブで、テナントレベルのSuper_Administratorロールをユーザーに割り当てることができます。 ユーザーにロールを割り当てることができるのは、テナントレベルのSuper_Administratorロールが割り当てられているAlibaba CloudアカウントまたはRAMユーザーのみです。 詳細については、「ユーザーへのロールの割り当て」をご参照ください。
DataWorksコンソールで外部プロジェクトを作成します。
にログインします。DataWorksコンソールリージョンを選択します。
DataWorksコンソールの左側のナビゲーションウィンドウで、[その他] > [レイクとウェアハウスの統合 (データレイクハウス)] を選択します。
[Lake and Warehouse Integration (Data Lakehouse)] ページで、[開始] をクリックします。
[データレイクハウスの作成] ページで、パラメーターを設定します。 次の表にパラメーターを示します。
表 1. Create Data Lakehouseステップのパラメータ
パラメーター
説明
外部プロジェクト名
外部プロジェクトの名前。 例: test_extproject_ddd。
MaxComputeプロジェクト
MaxCompute プロジェクトの名前を設定します。 例: test_lakehouse。
表 2. [データレイク接続の作成] ステップのパラメーター
パラメーター
説明
異種データプラットフォームタイプ
[Alibaba Cloud E-MapReduce/Hadoopクラスター] を選択します。
ネットワーク接続
既存のネットワーク接続を選択します。 詳細については、「外部データレイク接続の作成」をご参照ください。
外部データソース
既存の外部データソースを選択します。 詳細については、「外部データレイク接続の作成」をご参照ください。
表 4. データマッピングの作成
パラメーター
説明
外部データソースオブジェクト
デフォルトでは、このパラメーターはExternal Data Sourceの値に設定されています。
宛先データベース
Hadoopクラスター内のデータベース。
[作成とプレビューの完了] をクリックし、[プレビュー] をクリックします。 Hadoopクラスター内のデータベーステーブルに関する情報をプレビューできる場合、操作は成功します。
説明外部プロジェクトはDataWorksコンソールで作成されます。 SQL文を使用して外部プロジェクトを管理する方法の詳細については、「SQL文を使用して外部プロジェクトを管理する」をご参照ください。
DataWorksコンソールで、アドホッククエリページにODPS SQLノードを作成し、外部プロジェクトのテーブルを表示します。 サンプル文:
SHOW TABLES IN test_extproject_ddd; -- The following result is returned: ALIYUN$***@test.aliyunid.com:h0説明DataWorksでアドホッククエリを実行する方法の詳細については、「アドホッククエリノードを使用してSQL文を実行する (オプション) 」をご参照ください。
DataWorksコンソールの [アドホッククエリ] ページで、外部プロジェクトのテーブルデータを照会します。 サンプル文:
SELECT * FROM test_extproject_ddd.h0;次の図は、返された結果を示しています。

Workbenchを使用してHadoopクラスターにログインし、Spark SQLターミナルに移動します。 コマンド実行セクションで、h0テーブルのデータを更新するためのSQL文を入力します。 サンプル文:
INSERT INTO h0 VALUES (2, 'a2', 11, 1000);DataWorksコンソールの [アドホッククエリ] ページで、データ更新結果を表示します。 サンプル文:
SELECT * FROM test_extproject_ddd.h0 WHERE id ='2';次の図は、返された結果を示しています。

関連ドキュメント
DLF、ApsaraDB RDSまたはRealtime Compute For Apache Flink、およびOSSに基づくDelta LakeまたはApache Hudiストレージメカニズムをサポートするデータ湖を構築する方法の詳細については、「DLFに基づくDelta LakeまたはApache Hudiストレージメカニズム、ApsaraDB RDSまたはRealtime Compute for Apache Flink、およびOSS」をご参照ください。