このトピックでは、E-MapReduce(EMR)コンソールでオープンソースの Hadoop エコシステムに基づく DataLake クラスターをすばやく作成し、そのクラスターを使用して WordCount ジョブを送信する方法について説明します。WordCount ジョブは、Hadoop における最も基本的で典型的な分散コンピューティング ジョブです。 WordCount ジョブは、大量のテキストデータ内の単語数をカウントするために使用されます。 WordCount ジョブは、データ分析やデータマイニングなど、さまざまなシナリオで使用できます。
概要
このトピックに記載されている手順に従うことで、次のことができます。
DataLake クラスターをすばやく作成する
DataLake クラスターを使用して WordCount ジョブを送信および実行する
Alibaba Cloud EMR のコア機能と Hadoop エコシステムの基本的な使用方法を理解する
前提条件
Alibaba Cloud アカウントが作成され、実名登録が完了している。
デフォルトの EMR ロールと Elastic Compute Service(ECS)ロールが Alibaba Cloud アカウントに割り当てられている。 詳細については、「Alibaba Cloud アカウントへのロールの割り当て」をご参照ください。
注意事項
コードの実行環境は、環境の所有者によって管理および構成されます。
手順
ステップ 1:クラスターを作成する
クラスター作成ページに移動します。
EMR コンソール にログインします。左側のナビゲーションウィンドウで、[EMR On ECS] をクリックします。
上部のナビゲーションバーで、ビジネス要件に基づいてリージョンとリソースグループを選択します。
クラスターの作成後、クラスターのリージョンを変更することはできません。
デフォルトでは、アカウントのすべてのリソースグループが表示されます。
EMR on ECS ページで、[クラスターの作成] をクリックします。
表示されるページで、パラメーターを構成します。次の表にパラメーターを示します。
ステップ
パラメーター
例
説明
[ソフトウェア構成]
[リージョン]
中国 (杭州)
クラスターの ECS インスタンスが存在する地理的な場所です。
重要クラスターの作成後、リージョンを変更することはできません。ビジネス要件に基づいてリージョンを選択してください。
[ビジネスシナリオ]
Data Lake
クラスターのビジネスシナリオ。ビジネス要件に基づいてビジネスシナリオを選択します。Alibaba Cloud EMR は、コンポーネント、サービス、およびリソースを自動的に構成して、クラスター構成を簡素化し、特定のビジネスシナリオの要件を満たすクラスター環境を提供します。
[プロダクトバージョン]
EMR-5.18.1
EMR のバージョン。最新バージョンを選択してください。
[高サービス可用性]
オフ
EMR クラスターの高可用性(HA)を有効にするかどうかを指定します。[高サービス可用性] スイッチをオンにすると、EMR はマスターノードを異なる基盤となるハードウェアデバイスに分散させて、障害のリスクを軽減します。デフォルトでは、スイッチはオフになっています。
[オプションサービス]
Hadoop-Common、OSS-HDFS、YARN、Hive、Spark3、Tez、Knox、および OpenLDAP
クラスターのオプションサービス。ビジネス要件に基づいてサービスを選択できます。選択したサービスに関連するプロセスは自動的に開始されます。
説明サービスの Web UI にアクセスするには、Knox と OpenLDAP も選択する必要があります。
サービス運用ログの収集を許可する
オン
すべてのサービスのログ収集を有効にするかどうかを指定します。デフォルトでは、このスイッチはオンになっており、クラスターのサービス運用ログが収集されます。ログはクラスターの診断にのみ使用されます。
クラスターの作成後、[基本情報] タブで [サービス運用ログの収集ステータス] パラメーターを変更できます。
重要このスイッチをオフにすると、EMR クラスターのヘルスチェックとサービス関連のテクニカルサポートが制限されます。ログ収集を無効にする方法と、ログ収集の無効化による影響については、「サービス運用ログの収集を停止するにはどうすればよいですか?」をご参照ください。
Metadata
組み込み MySQL
メタデータに組み込み MySQL を選択すると、メタデータは MySQL に保存されます。
重要組み込み MySQL はテスト環境に適しています。本番環境では組み込み MySQL を使用しないことをお勧めします。本番環境でメタデータサービスを使用する予定の場合は、ビジネス要件に基づいてセルフマネージド RDS または DLF 統合メタデータを選択することをお勧めします。
クラスターストレージのルートパス
oss://******.cn-hangzhou.oss-dls.aliyuncs.com
クラスターデータのルートストレージディレクトリ。このパラメーターは、OSS-HDFS サービスを選択した場合にのみ必須です。
説明OSS-HDFS サービスを使用する前に、クラスターを作成するリージョンで OSS-HDFS サービスが利用可能であることを確認してください。リージョンで OSS-HDFS サービスが利用できない場合は、リージョンを変更するか、OSS-HDFS の代わりに HDFS を使用できます。OSS-HDFS が利用可能なリージョンについては、「OSS-HDFS を有効にし、アクセス権限を付与する」をご参照ください。
新しいデータレイクシナリオ、Dataflow クラスター、DataServing クラスター、または EMR V5.12.1、EMR V3.46.1 以降のマイナーバージョンのカスタムクラスターで DataLake クラスターを作成するときに、OSS-HDFS サービスを選択できます。
[ハードウェア構成]
[課金方法]
従量課金
クラスターの課金方法。テストを実行する場合は、[従量課金] 課金方法を使用することをお勧めします。テストが完了したら、クラスターをリリースし、本番環境で [サブスクリプション] クラスターを作成できます。
[ゾーン]
ゾーン I
クラスターが存在するゾーン。クラスターの作成後、ゾーンを変更することはできません。ビジネス要件に基づいてゾーンを選択してください。
[VPC]
vpc_Hangzhou/vpc-bp1f4epmkvncimpgs****
クラスターがデプロイされる仮想プライベートクラウド(VPC)。現在のリージョンで VPC を選択します。利用可能な VPC がない場合は、[VPC の作成] をクリックして VPC を作成します。VPC が作成されたら、[更新] アイコンをクリックして、作成された VPC を選択します。
[vSwitch]
vsw_i/vsw-bp1e2f5fhaplp0g6p****
クラスターの vSwitch。指定したゾーンで vSwitch を選択します。ゾーンに利用可能な vSwitch がない場合は、vSwitch を作成します。
[デフォルトセキュリティグループ]
sg_seurity/sg-bp1ddw7sm2risw****
重要ECS コンソールで作成された高度なセキュリティグループを使用することはできません。
クラスターを追加するセキュリティグループ。EMR でセキュリティグループを作成している場合は、ビジネス要件に基づいてセキュリティグループを選択できます。セキュリティグループを作成することもできます。
[ノードグループ]
マスターノードグループの [パブリックネットワーク IP の割り当て] スイッチをオンにし、その他のパラメーターのデフォルト設定を使用します
クラスター内のインスタンス。ビジネス要件に基づいて、マスターノード、コアノード、およびタスクノードを構成します。詳細については、「ハードウェア仕様とネットワーク構成を選択する」をご参照ください。
[基本構成]
[クラスター名]
Emr-DataLake
クラスターの名前。名前は 1 ~ 64 文字で、文字、数字、ハイフン(-)、およびアンダースコア(_)のみを含めることができます。
[ID 資格情報]
パスワード
クラスターのマスターノードにリモートアクセスするために使用する ID 資格情報。
説明パスワードを入力せずに認証を実行する場合は、このパラメーターに [キーペア] を選択できます。詳細については、「SSH キーペアの管理」をご参照ください。
[パスワード] と [パスワードの確認]
カスタムパスワード
クラスターにアクセスするために使用するパスワード。後続の操作のためにこのパスワードを記録してください。
[次へ: 確認] をクリックします。画面の指示に従って作成を完了します。
クラスターが [実行中] 状態の場合、クラスターは正常に作成されています。クラスターパラメーターの詳細については、「クラスターの作成」をご参照ください。
ステップ 2:データを準備する
クラスターの作成後、クラスターのプリセット WordCount プログラムを使用してデータを分析するか、自作のビッグデータプログラムをアップロードして実行できます。このトピックでは、プリセット WordCount プログラムを例として使用して、データを準備し、データ分析用のジョブを送信する方法について説明します。
SSH モードでクラスターにログインします。詳細については、「クラスターへのログイン」をご参照ください。
データファイルを準備します。
WordCount プログラムの入力データとして、
wordcount.txtという名前のテキストファイルを作成します。サンプルコード:hello world hello wordcountデータファイルをアップロードします。
説明ビジネス要件に基づいて、データファイルを HDFS、OSS、または OSS-HDFS にアップロードできます。この例では、データファイルは OSS-HDFS にアップロードされます。OSS にファイルをアップロードする方法については、「シンプルアップロード」をご参照ください。
inputという名前のディレクトリを作成するには、次のコマンドを実行します。hadoop fs -mkdir oss://<yourBucketname>.cn-hangzhou.oss-dls.aliyuncs.com/input/ローカルルートディレクトリの
wordcount.txtファイルを OSS-HDFS のinputディレクトリにアップロードするには、次のコマンドを実行します。hadoop fs -put wordcount.txt oss://<yourBucketname>.cn-hangzhou.oss-dls.aliyuncs.com/input/
ステップ 3:ジョブを送信する
WordCount プログラムを使用して、テキストデータ内の単語の頻度を分析できます。
WordCount ジョブを送信するには、次のコマンドを実行します。
hadoop jar /opt/apps/HDFS/hadoop-3.2.1-1.2.16-alinux3/share/hadoop/mapreduce/hadoop-mapreduce-examples-3.2.1.jar wordcount -D mapreduce.job.reduces=1 "oss://<yourBucketname>.cn-hangzhou.oss-dls.aliyuncs.com/input/wordcount.txt" "oss://<yourBucketname>.cn-hangzhou.oss-dls.aliyuncs.com/output/"次の表に、コマンドのパラメーターを示します。
パラメーター | 説明 |
| 特定のサンプル MapReduce プログラムを含む組み込み Hadoop JAR パッケージ。 |
| MapReduce ジョブに許可される reduce タスクの数。 デフォルトでは、Hadoop は入力データボリュームに基づいて reduce タスクの数を自動的に決定します。このパラメーターを構成しない場合、 |
| WordCount ジョブの入力パス。これは、前のステップでアップロードされたデータファイルが保存されているパスです。 |
| WordCount ジョブの出力パス。ジョブの計算結果を保存するために使用されます。 |
ステップ 4:結果を表示する
ジョブの実行結果を表示する
Hadoop シェルコマンドを実行して、ジョブの実行結果を表示できます。
SSH モードでクラスターにログインします。詳細については、「クラスターへのログイン」をご参照ください。
ジョブの実行結果を表示するには、次のコマンドを実行します。
hadoop fs -cat oss://<yourBucketname>.cn-hangzhou.oss-dls.aliyuncs.com/output/part-r-00000次の図は出力を示しています。

ジョブの詳細を表示する
YARN は Hadoop のリソース管理フレームワークであり、クラスターに送信されたジョブのスケジュールと管理に使用されます。YARN の Web UI でジョブの詳細を表示できます。たとえば、ジョブのステータス、タスクの詳細、ログ、およびリソース使用量を表示できます。
ポート 8443 を有効にします。詳細については、「セキュリティグループの管理」をご参照ください。
ユーザーを追加します。詳細については、「OpenLDAP ユーザーの管理」をご参照ください。
Knox アカウントを使用して YARN の Web UI にアクセスするには、Knox アカウントのユーザー名とパスワードを取得する必要があります。
[EMR On ECS] ページで、クラスターを見つけ、[アクション] 列の [サービス] をクリックします。
表示されるページで、[アクセスリンクとポート] タブをクリックします。
[アクセスリンクとポート] タブで、[YARN UI] の [Knox プロキシアドレス] 列のインターネットの右側にあるリンクをクリックします。
追加したユーザーをログオン認証に使用して、YARN Web UI にアクセスできます。
[すべてのアプリケーション] ページで、ジョブの ID をクリックして、ジョブの詳細を表示します。
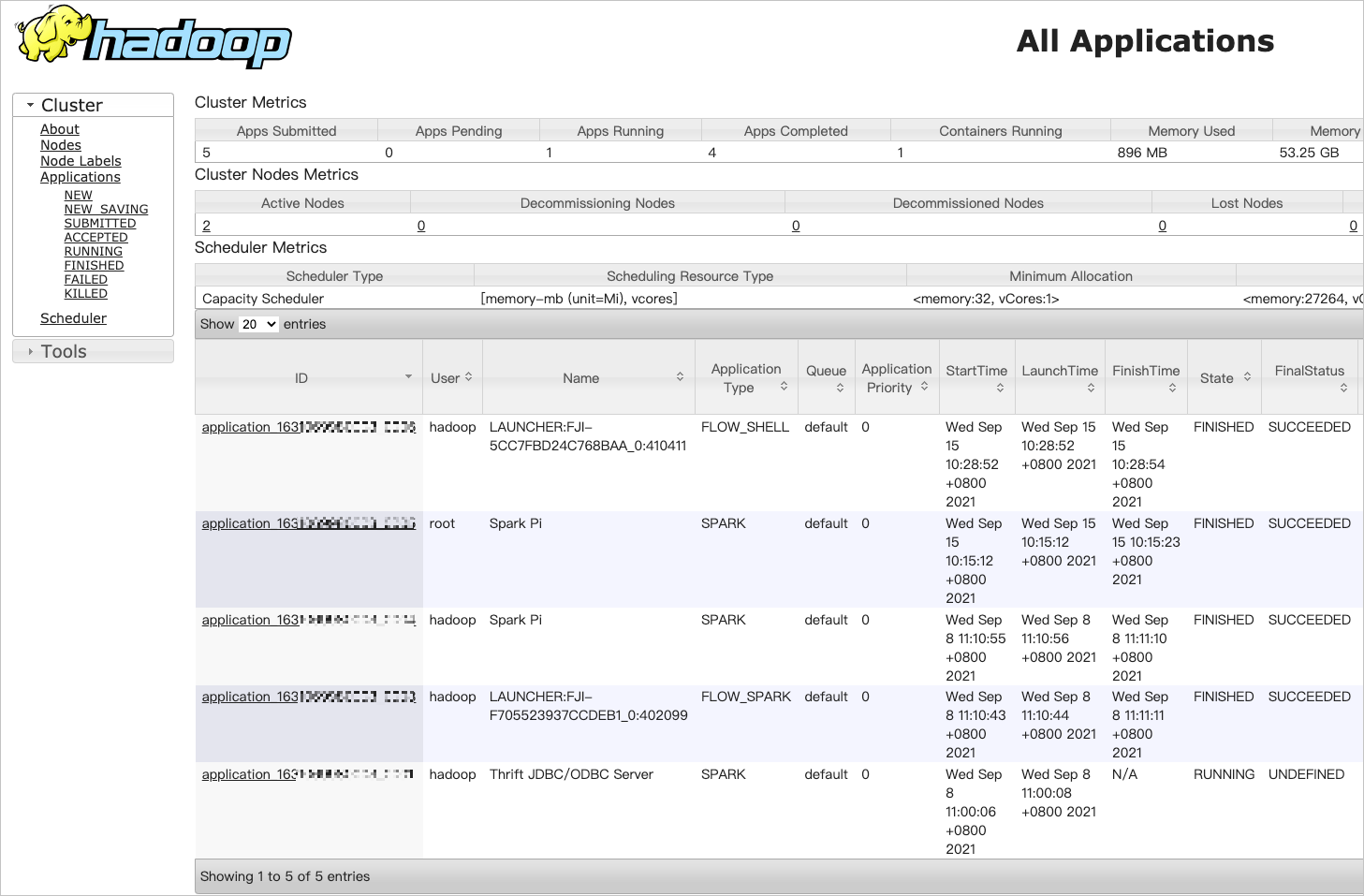
(オプション)ステップ 5:クラスターをリリースする
クラスターを使用する必要がなくなった場合は、クラスターをリリースしてコストを削減できます。クラスターのリリースを確認すると、システムはクラスターに対して次の操作を実行します。
クラスター内のすべてのジョブを強制終了します。
クラスター用に作成されたすべての ECS インスタンスを終了してリリースします。
クラスターのリリースに必要な時間は、クラスターのサイズによって異なります。ほとんどのクラスターは数秒でリリースできます。大規模なクラスターのリリースには 5 分以上かかりません。
従量課金クラスターはいつでもリリースできます。サブスクリプションクラスターは、クラスターの有効期限が切れた後にのみリリースできます。
クラスターをリリースする前に、クラスターが初期化中、実行中、またはアイドル状態であることを確認してください。
[EMR On ECS] ページで、クラスターを見つけ、
 アイコンにポインターを移動し、[リリース] を選択します。
アイコンにポインターを移動し、[リリース] を選択します。次の操作を実行して、クラスターをリリースすることもできます。クラスターの名前をクリックします。[基本情報] タブの右上隅で、 を選択します。
[クラスターのリリース] メッセージで、[OK] をクリックします。
関連情報
EMR で頻繁に使用されるファイルのパスについては、「頻繁に使用されるファイルのパス」をご参照ください。
クラスター管理とクラスターサービス管理で使用可能な API 操作の詳細については、「機能別の操作リスト」をご参照ください。
よくある質問
EMR についてよく寄せられる質問については、「FAQ」をご参照ください。