このトピックでは、MaxComputeでサポートされているMapReduce APIとその制限について説明します。
MaxComputeには、MapReduce APIの2つのバージョンがあります。
MaxCompute MapReduce: ネイティブMapReduce API。 このバージョンは高速に実行されます。 ファイルシステムを公開する必要なしにプログラムを開発すると便利です。
拡張MaxCompute MapReduce (MR2 ): このバージョンは、複雑なジョブスケジューリングロジックをサポートしています。 実装方法は、MaxCompute MapReduceの実装方法と同じです。MaxComputeが提供する拡張MapReduceモデル (MR2) は、最適化されたスケジューリングおよびI/Oモデルを使用して、ジョブ実行中の不要なI/O操作を削減します。
上記の2つのバージョンは、基本的な用語、ジョブ送信、入力と出力、およびリソース使用量が似ています。 唯一の違いはSDK for Javaです。 詳細については、「Hadoop MapReduce」をご参照ください。
MapReduceを使用して、外部テーブルからデータを読み書きすることはできません。
MapReduce
シナリオ
MapReduceは次のシナリオをサポートします。
検索: webクロール、逆インデックス、PageRank。
webアクセスログの分析:
webブラウジングやオンラインショッピングなど、ユーザーの行動の特性を分析して要約します。 分析を使用して、パーソナライズされた推奨を配信できます。
ユーザーアクセスの動作を分析します。
テキストの統計分析:
人気のある小説の単語数と用語頻度-逆文書頻度 (TFIDF) 分析。
学術論文および特許文書への参照の統計分析。
ウィキペディアのデータ分析。
大量のデータのマイニング: 非構造化データ、時空間データ、および画像データのマイニング。
機械学習: 教師あり学習、教師なし学習、および決定木やサポートベクターマシン (SVM) などの分類アルゴリズム。
自然言語処理 (NLP):
ビッグデータに基づくトレーニングと予測。
共起行列の構築、頻出アイテムセットデータのマイニング、および既存のライブラリに基づく重複文書検出。
広告の推奨事項: クリックスルー率 (CTR) とコンバージョン率 (CVR) の予測。
処理中
MapReduceプログラムは、マップステージとreduceステージの2つのステージでデータを処理します。 リデュースステージの前にマップステージを実行します。 マップおよびリダクションステージの処理ロジックを指定できます。 ただし、ロジックはMapReduceフレームワークの規則に準拠する必要があります。 次の手順は、MapReduceフレームワークがデータを処理する方法を示しています。
入力データ: マップ操作の前に、入力データを分割する必要があります。 分割とは、入力データを同じサイズのデータブロックに分割することを指す。 各データブロックは、単一のマッパに対する入力として処理される。 これにより、複数のマッパーを同時に使用できます。
マップステージ: 各マッパーは、そのパーティションデータを読み取り、データを計算し、各データレコードのキーを指定します。 キーは、データレコードが送信されるレデューサーを指定します。
説明キーとリデューサーは多対1の関係を共有しています。 同じキーを持つデータレコードは、同じレデューサーに送信されます。 レデューサーは、異なるキーを有するデータレコードを受信し得る。
シャッフルステージ: 縮小ステージの前に、MapReduceフレームワークはキーに基づいてデータレコードをソートし、同じキーを持つデータレコードが隣接するようにします。 コンバイナーを指定した場合、MapReduceフレームワークはコンバイナーを呼び出して、同じキーを共有するデータレコードを結合します。 コンバイナーのロジックを定義できます。 MaxComputeでは、従来のMapReduceフレームワークプロトコルとは異なり、コンバイナの入力パラメーターと出力パラメーターがリデューサーのパラメーターと一致している必要があります。 このプロセスはシャッフルと呼ばれます。
Reduce stage: 同じキーを持つデータレコードが同じリデューサーに転送されます。 単一のレデューサーは、複数のマッパーからデータレコードを受け取ることができる。 各レデューサーは、同じキーを持つ複数のデータレコードに対してreduce操作を実行します。 reduce操作の後、同じキーを持つすべてのデータレコードが単一の値に変換されます。
結果が生成される。
MapReduceフレームワークの詳細については、「機能」をご参照ください。
次のセクションでは、WordCountを例として、MaxCompute MapReduceの関連概念をさまざまな段階で説明します。
a.txtという名前のファイルが存在し、ファイルの各行に数字が含まれているとします。 各桁が表示される回数をカウントします。 各桁は単語と呼ばれ、使用される回数がカウントを表します。 次の図は、MaxCompute MapReduceが単語をカウントする方法を示しています。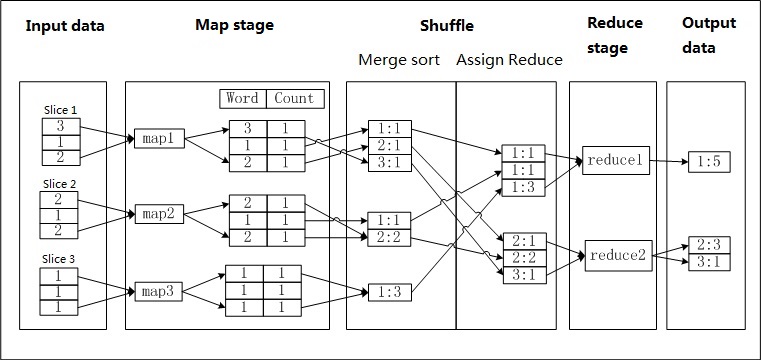
手順
MaxCompute MapReduceはa.txtファイルのデータをパーティション分割し、各パーティションのデータをマッパーの入力として使用します。
マッパは、入力データを処理し、得られた各桁についてCountパラメータの値を1として記録する。 このようにして、<Word, Count> 対が生成される。 Wordパラメーターの値は、新しく生成されたペアのキーとして使用されます。
初期のシャッフル段階では、各マッパーによって生成されたデータレコードは、キー (Wordパラメータの値) に基づいてソートされます。 データレコードがソートされた後、レコードは結合される。 これには、同じキーを共有するCount値を累積して、新しい <Word、Count> ペアを生成する必要があります。 これはマージおよびソートプロセスです。
後半のシャッフル段階では、データレコードがリデューサーに転送されます。 リデューサは、キーに基づいて受信したデータレコードをソートする。
各リデューサーは、コンバイナと同じロジックを使用してデータを処理します。 各レデューサーは、同じキー (Wordパラメータの値) でCount値を蓄積します。
結果が生成される。
すべてのMaxComputeデータはテーブルに保存されます。 したがって、MaxCompute MapReduceの入力と出力はテーブル形式のみにすることができます。 出力形式は指定できず、ファイルシステムに似たインターフェイスは提供されません。
制限事項
MaxCompute MapReduceの制限の詳細については、「MaxCompute MapReduceの制限」をご参照ください。
ローカルモードでのMaxCompute MapReduceの実行制限の詳細については、「ローカル実行」をご参照ください。
拡張MapReduceモデル
拡張MapReduceモデルでは、Map関数とReduce関数はMaxComputeと同じ方法で記述されます。 違いは、ジョブの実行方法にあります。 詳細については、「Pipelineの例」をご参照ください。
背景情報
MapReduceモデルは、複数のMapReduceジョブで構成されます。 従来のMapReduceモデルでは、各MapReduceジョブの出力は、HDFSなどの分散ファイルシステムのディスクまたはMaxComputeテーブルに書き込む必要があります。 ただし、後続のMapタスクは、シャッフル段階の準備のために出力を1回読み取るだけでよい場合があります。 このメカニズムは、冗長なI/O動作をもたらす。
MaxComputeのコンピューティングおよびスケジューリングロジックは、より複雑なプログラミングモデルをサポートします。 Map操作は、Map-Reduce-Reduceなど、間にMap操作を必要とせずに、任意の数の連続したReduce操作によって成功させることができます。
Hadoop ChainMapperとChainReducerとの比較
同様に、Hadoop ChainMapperとChainReducerもシリアル化されたMapまたはReduce操作をサポートします。 ただし、拡張MapReduceモデルとは基本的に異なります。
Hadoop ChainMapperとChainReducerは、従来のMapReduceモデルに基づいています。 元のMapまたはReduce操作の後にMap操作のみをサポートします。 1つの利点は、Mapperビジネスロジックを再利用して、MapまたはReduce操作を複数のMapperステージに分割できることです。 ただし、これはスケジューリングまたはI/Oモデルを変更しません。