MaxCompute は、特定の使用制限がある 2 つの MapReduce プログラミングインターフェイスを提供します。
MaxCompute は、2 つの MapReduce プログラミングインターフェイスを提供します。
-
MaxCompute MapReduce:MaxCompute のネイティブインターフェイスです。高速な実行、迅速な開発が可能で、ファイルシステムは公開されません。
-
MaxCompute 拡張 MapReduce (MR2):ネイティブインターフェイスと同じ実装で、より複雑なジョブスケジューリングをサポートします。従来の MapReduce とは異なり、MR2 は基盤となるスケジューリングモデルと I/O モデルを変更して、冗長な I/O 操作を排除します。
これらのインターフェイスは、用語、ジョブ送信、入力と出力、リソース使用量の点でほぼ同じですが、Java SDK のみが異なります (Hadoop MapReduce チュートリアル)。
MapReduce は、外部テーブルの読み取りまたは書き込みができません。
MapReduce
ユースケース
MapReduce は、以下のユースケースをサポートしています。
-
検索:Web クロール、転置インデックス、 PageRank。
-
Web アクセスログ分析:
-
パーソナライズされたレコメンデーションのために、ユーザーの閲覧行動やショッピング行動を分析します。
-
ユーザーのアクセスパターンを分析します。
-
-
テキスト分析:
-
人気小説の単語カウント (WordCount) および TF-IDF 分析。
-
学術論文や特許の引用分析。
-
Wikipedia のデータ分析。
-
-
ビッグデータマイニング:非構造化データ、時空間データ、画像データ。
-
機械学習:教師あり学習、教師なし学習、および決定木や SVM などの分類アルゴリズム。
-
自然言語処理 (NLP):
-
ビッグデータを使用したトレーニングと予測。
-
単語共起行列の構築、頻出アイテムセットのマイニング、重複ドキュメントの検出。
-
-
広告レコメンデーション:クリックスルー率 (CTR) とコンバージョン率 (CVR) の予測。
MapReduceの仕組み
MapReduce は、Map と Reduce の 2 つのフェーズでデータを処理します。ユーザーは、MapReduce フレームワーク内で両方のフェーズの処理ロジックを実装します。完全なワークフローは次のとおりです。
-
入力:入力データを同じサイズのブロックに分割します。各ブロックは、並列処理のために個別の Map ワーカーに送られます。
-
Map:各 Map ワーカーがデータを読み取って処理し、各出力レコードにキーを割り当てます。このキーによって、どの Reduce ワーカーがレコードを受け取るかが決まります。
説明キーと Reduce ワーカーは多対 1 の関係です。同じキーを持つレコードは同じ Reduce ワーカーに送られ、1 つの Reduce ワーカーは異なるキーを持つレコードを受け取ることができます。
-
シャッフル:Reduce フェーズの前に、フレームワークはキーによってデータをソートし、同じキーを持つレコードが隣接するようにします。[Combiner] を指定した場合、フレームワークは同じキーを持つレコードを集約します。ユーザーは、カスタムの Combiner ロジックを実装できます。従来の MapReduce とは異なり、MaxCompute では、Combiner の入力パラメーターと出力パラメーターが Reduce のパラメーターと一致する必要があります。このプロセスは [シャッフル] とも呼ばれます。
-
Reduce:同じキーを持つレコードは、同じ Reduce ワーカーに送信されます。各 Reduce ワーカーは複数の Map ワーカーからデータを受け取り、キーでグループ化されたレコードに対して Reduce 操作を実行し、キーごとに 1 つの出力値を生成します。
-
結果を出力します。
これは MapReduce フレームワークの簡単な概要です。詳細については、「用語」をご参照ください。
次の単語カウントの例は、各 MapReduce ステージを示しています。
テキストファイル a.txt に 1 行に 1 つの数字が含まれており、各数字の出現回数をカウントするとします。各数字を単語 (Word)、その出現回数をカウント (Count) とします。次の図は、MapReduce がこのタスクを完了する仕組みを示しています。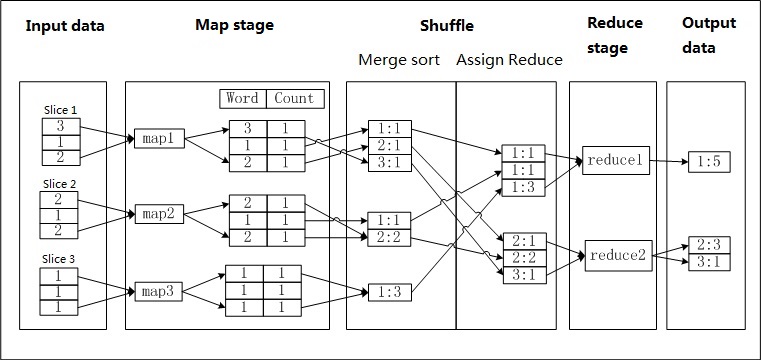
[手順]
-
入力:テキストをブロックに分割し、各ブロックを Map ワーカーに送ります。
-
Map:読み取られた各数値について、そのカウントを 1 に設定し、単語をキーとして <Word, Count> のペアを出力します。
-
シャッフル > 結合とソート:各 Map ワーカーの出力をキー (Word) でソートし、Combiner を実行して同じ Word を持つレコードのカウントを集約し、新しい <Word, Count> ペアを生成します。
-
シャッフル > Reduce への分配:データを Reduce ワーカーに送信します。各 Reduce ワーカーは、受信したデータをキーで再ソートします。
-
Reduce:各 Reduce ワーカーは、Combiner と同じロジックを使用して、同じ Word を持つレコードのカウントを集約し、最終結果を出力します。
-
結果を出力します。
MaxCompute のすべてのデータはテーブルに保存されます。したがって、MapReduce の入力と出力はテーブルのみです。カスタムの出力形式とファイルシステムインターフェイスはサポートされていません。
制限事項
拡張 MapReduce (MR2)
MR2 は、Map 関数と Reduce 関数の記述方法において、MaxCompute MapReduce とほぼ同じです。主な違いはジョブの実行にあります。例については、「パイプラインの例」をご参照ください。
背景
従来の MapReduce では、各ラウンドの出力データを分散ファイルシステム (HDFS や MaxCompute のテーブルなど) に保存する必要があります。複数ジョブで構成される MapReduce パイプラインでは、各ジョブの後に中間データがディスクに書き込まれますが、後続の Map タスクは、シャッフルフェーズのためにそのデータを一度読み取るだけでよい場合が多く、結果として冗長なディスク I/O が発生します。
MaxCompute は、より複雑なプログラミングモデルをサポートしています。中間的な Map ステップなしで、ある Reduce の直後に別の Reduce を連鎖させることができます。これにより、Map > Reduce > Reduce のように、Map の後に任意の数の Reduce 操作を連鎖させるパイプラインが可能になり、不要な I/O を排除できます。
Hadoop Chain Mapper/Reducer との比較
Hadoop Chain Mapper/Reducer は、同様の連鎖的な Map または Reduce 操作をサポートしますが、MaxCompute MR2 とは根本的に異なります。
Chain Mapper/Reducer は、従来の MapReduce モデルを基盤としており、既存の Mapper または Reducer の後に 1 つ以上の Mapper 操作を追加することのみを許可します (追加の Reducer は不可)。これにより、Map または Reduce を複数の Mapper ステージに分割して既存の Mapper ロジックを再利用できますが、基盤となるスケジューリングモデルや I/O モデルは変更されません。