本トピックでは、MaxCompute のジョブ優先度機能について説明し、ジョブの優先度を有効化、設定、表示する方法を解説します。
背景情報
MaxCompute の計算リソースには限りがあります。データ開発中、システムは重大なジョブを優先して、必要なリソースを確実に取得できるようにする必要があります。たとえば、特定のデータを午前 6 時までに準備する必要がある場合、そのデータを生成する一連のジョブ (ワークフロー) は、他のジョブよりも先に計算リソースを確保できなければなりません。
この要件は、プロジェクトレベルでジョブの優先度を設定することで満たせます。優先度の高いジョブに、まず計算リソースが割り当てられます。優先度の高いジョブが開始されると、優先度の低いジョブからリソースをプリエンプト (横取り) することができます。
優先度の概要
MaxCompute の各ジョブには、0 から 9 までの優先度の値があります。数値が小さいほど優先度が高くなります。優先度の高いジョブは、優先度の低いジョブよりも先に計算リソースが割り当てられます。
ジョブ優先度機能が無効の場合、プロジェクト内のすべてのジョブのデフォルトの優先度は 9 です。PAI アルゴリズムジョブの場合、デフォルトの優先度は 1 です。
優先度の有効化
プロジェクトレベルでの優先度の有効化
プロジェクトオーナーまたは Super_Administrator ロールを持つユーザーのみが、次のコマンドを実行して優先度機能を有効にできます。
setproject odps.instance.priority.enable=true;優先度機能を有効にすると、プロジェクト内のすべてのジョブで優先度がすぐに使用されるようになります。ただし、優先度が誤って設定されていると、ジョブが予期せずキューに入る可能性があります。
優先度機能を有効にする前に、Information Schema を使用して既存のジョブの優先度を確認してください。その後、必要に応じて、9 以外の優先度を 9 にリセットします。その後に、優先度機能を有効にしてください。
クォータレベルでの優先度の有効化
優先度機能を有効にすると、このクォータで実行されるジョブは優先度を使用します。これは、プロジェクトレベルで優先度を有効にするのと同じように機能します。
優先度を有効にする前に、クォータテンプレートとクォータプランを作成していることを確認してください。詳細については、「クォータの設定」をご参照ください。
操作手順
MaxCompute コンソールにログインし、左上のコーナーでリージョンを選択します。
左側のナビゲーションウィンドウで、 を選択します。
クォータ管理 ページで、対象のクォータを見つけ、操作 列の クォータ設定 をクリックします。
クォータ設定 ページで、基本設定 タブをクリックし、基本設定の編集 をクリックします。
対象のレベル 2 クォータに対して 優先度を開く オプションを選択します。
説明レベル 2 クォータの データ型 が インタラクティブ の場合、[優先度を有効にする] パラメーターはデフォルトで利用できません。
決定 をクリックします。
ジョブ優先度の確認
ジョブ優先度の分布統計
コマンド例:
SELECT get_json_object( REPLACE(settings, '.', '_') ,'$.odps_instance_priority' ) AS priority ,task_type ,COUNT(1) AS cnt FROM information_schema.tasks_history WHERE ds = '${bizdate}' -- bizdate は日付パーティションです。 GROUP BY get_json_object( REPLACE(settings, '.', '_') ,'$.odps_instance_priority' ) ,task_type ORDER BY cnt DESC LIMIT 100 ;応答は次のとおりです。
+----------+-----------+------------+ | priority | task_type | cnt | +----------+-----------+------------+ | 9 | SQL | 4 | | NULL | SQL | 1 | | 2 | SQL | 1 | +----------+-----------+------------+このサンプルは、NULL、2、9 の優先度を示しています。優先度が 2 または NULL のジョブを特定します。NULL は通常、DDL タスクを意味し、無視できます。
優先度の値が 9 以外のジョブを検索します。
コマンド例:
SELECT inst_id ,owner_name ,task_name ,task_type ,settings FROM information_schema.tasks_history WHERE ds = '${bizdate}' AND get_json_object(REPLACE(settings, '.', '_'), '$.odps_instance_priority') = '${priority}' LIMIT 100 ;bizdate:日付パーティション (例:20200517)。
priority:9 以外の優先度の値 (例:2)。
次の結果が返されます。
+---------+------------+-----------+-----------+----------+ | inst_id | owner_name | task_name | task_type | settings | +---------+------------+-----------+-----------+----------+ | 20200517160200907g4jm**** | ALIYUN$odps_dev_****@prod.trusteeship.aliyunid.com | console_query_task_158973132**** | SQL | {"SKYNET_ID": "21000041****", "odps.instance.priority": "2", "SKYNET_ONDUTY": "113058643178****", "user_agent": "JavaSDK Revision:33acd11 Version:0.30.9 JavaVersion:1.8.0_112 CLT(0.30.2 : 9da012b); Linux(/)", "biz_id": "210000416174_20200517_211843317416_210033365461_1_habai_test_1130586431784115_39419845061****", "SKYNET_NODENAME": "test_priority"} | +---------+------------+-----------+-----------+----------+SKYNET_ID:DataWorks のスケジューリングノード ID。このフィールドがない場合、ジョブは DataWorks を通じて送信されていません。owner_name と user_agent フィールドを使用してソースを特定します。
SKYNET_ONDUTY:定期ジョブを示します。
ジョブの優先度を確認します。
DataWorks を通じて送信されたジョブ:ジョブにベースラインがある場合、ベースラインが妥当かどうかを確認します。妥当でない場合は、ベースラインを削除します。詳細については、「ベースライン管理」をご参照ください。
DataWorks を通じて送信されていないジョブ:クエリ結果を使用してオーナーとコードを見つけます。コードから優先度設定を削除して、デフォルトの優先度 9 に戻します。
優先度の設定
ジョブの優先度は、次の方法で設定できます。
方法 1:MaxCompute クライアントを実行し、プロジェクトに入り、ジョブの優先度を設定します。
この方法はアドホッククエリに使用します。コマンド例:
SET odps.instance.priority=values; -- values は 0 から 9 までの整数です。方法 2:MaxCompute クライアントを実行し、プロジェクトに入り、SQL 文をパラメーターとして渡してジョブの優先度を設定します。
この方法はアドホッククエリに使用します。コマンド例:
bin/odpscmd --config=xxx --project=xxx --instance-priority=x -e "<sql>"方法 3:Java SDK を使用してジョブの優先度を設定します。
この方法は、カスタムの優先度ロジックを構築するために使用します。詳細については、「Java SDK の概要」をご参照ください。コード例:
import com.aliyun.odps.Instance; import com.aliyun.odps.LogView; import com.aliyun.odps.Odps; import com.aliyun.odps.OdpsException; import com.aliyun.odps.account.Account; import com.aliyun.odps.account.AliyunAccount; import com.aliyun.odps.task.SQLTask; public class OdpsPriorityDemo { public static void main(String args[]) throws OdpsException { // Alibaba Cloud の AccessKey は、完全な API アクセス権限を持ち、高いセキュリティリスクをもたらします。代わりに RAM ユーザーを作成して使用することを強く推奨します。RAM ユーザーを作成するには、RAM コンソールにログインしてください。 // この例では、AccessKey ID と AccessKey Secret は環境変数に保存されています。必要に応じて、設定ファイルに保存することもできます。 // AccessKey ID と AccessKey Secret をコードに保存しないでください。認証情報が漏洩する可能性があります。 Account account = new AliyunAccount(System.getenv("ALIBABA_CLOUD_ACCESS_KEY_ID"),System.getenv("ALIBABA_CLOUD_ACCESS_KEY_SECRET")); Odps odps = new Odps(account); // パブリッククラウドのエンドポイント。 String odpsUrl = "http://service.odps.aliyun.com/api"; odps.setEndpoint(odpsUrl); odps.setDefaultProject("xxxxxxxxxx"); SQLTask task = new SQLTask(); task.setName("adhoc_sql_task_1"); task.setQuery("select count(*) from aa;"); // 5 はジョブの優先度です。 Instance instance = odps.instances().create(task, 5); LogView logView = new LogView(odps); // LogView の URL を出力してインスタンスのステータスを確認します。任意。 System.out.println(logView.generateLogView(instance, 24)); // インスタンスが完了するのを待ちます。任意。 instance.waitForSuccess(); } }方法 4:DataWorks のベースライン管理を使用してジョブの優先度を設定します。
この方法は、定期ジョブとその上流ジョブのタイムリーな出力を保証するために使用します。ベースライン管理を使用すると、データパイプライン全体のすべてのジョブの優先度を一度に設定でき、各ジョブを個別に設定する必要はありません。DataWorks のベースライン管理の詳細については、「ベースライン管理」をご参照ください。
DataWorks では、ベースラインの優先度は 1、3、5、7、または 8 です。数値が大きいほど優先度が高くなります。DataWorks のベースライン管理を通じて MaxCompute のジョブ優先度を設定すると、MaxCompute のジョブ優先度は 9 から DataWorks のベースライン優先度を引いた値になります。
説明デフォルトでは、DataWorks のアドホッククエリにはベースラインがありません。したがって、それらが開始する MaxCompute ジョブの最低優先度は 9 です。
DataWorks のワークフローには、デフォルトのベースライン優先度 1 があります。したがって、それらが開始する MaxCompute ジョブの最低優先度は 8 です。
方法 5:DataWorks ノードで直接ジョブの優先度を設定します。
この方法はアドホッククエリに使用します。コマンド例:
set odps.instance.priority=x; -- x は優先度の値です。
優先度の表示
Logview 2.0 で、[Json Summary] タブに移動し、odps.instance.priority パラメーターを見つけてジョブの優先度を表示します。Logview 2.0 のその他の操作については、「Logview 2.0 を使用したジョブ実行詳細の表示」をご参照ください。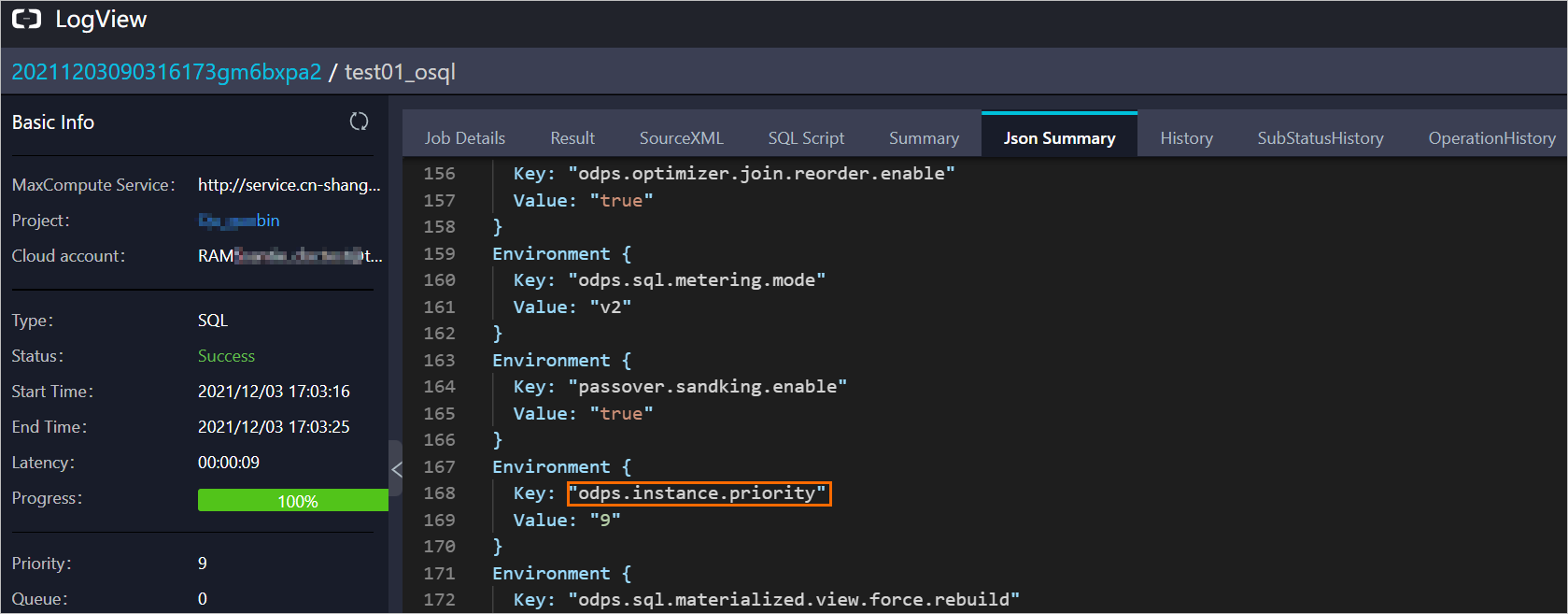
Logview ページの XML に表示される優先度は正確ではありません。優先度が無効になっているプロジェクトの場合、システムは不公平なキューイングを防ぐために、9 以外の優先度値を XML 上で 9 に変更します。