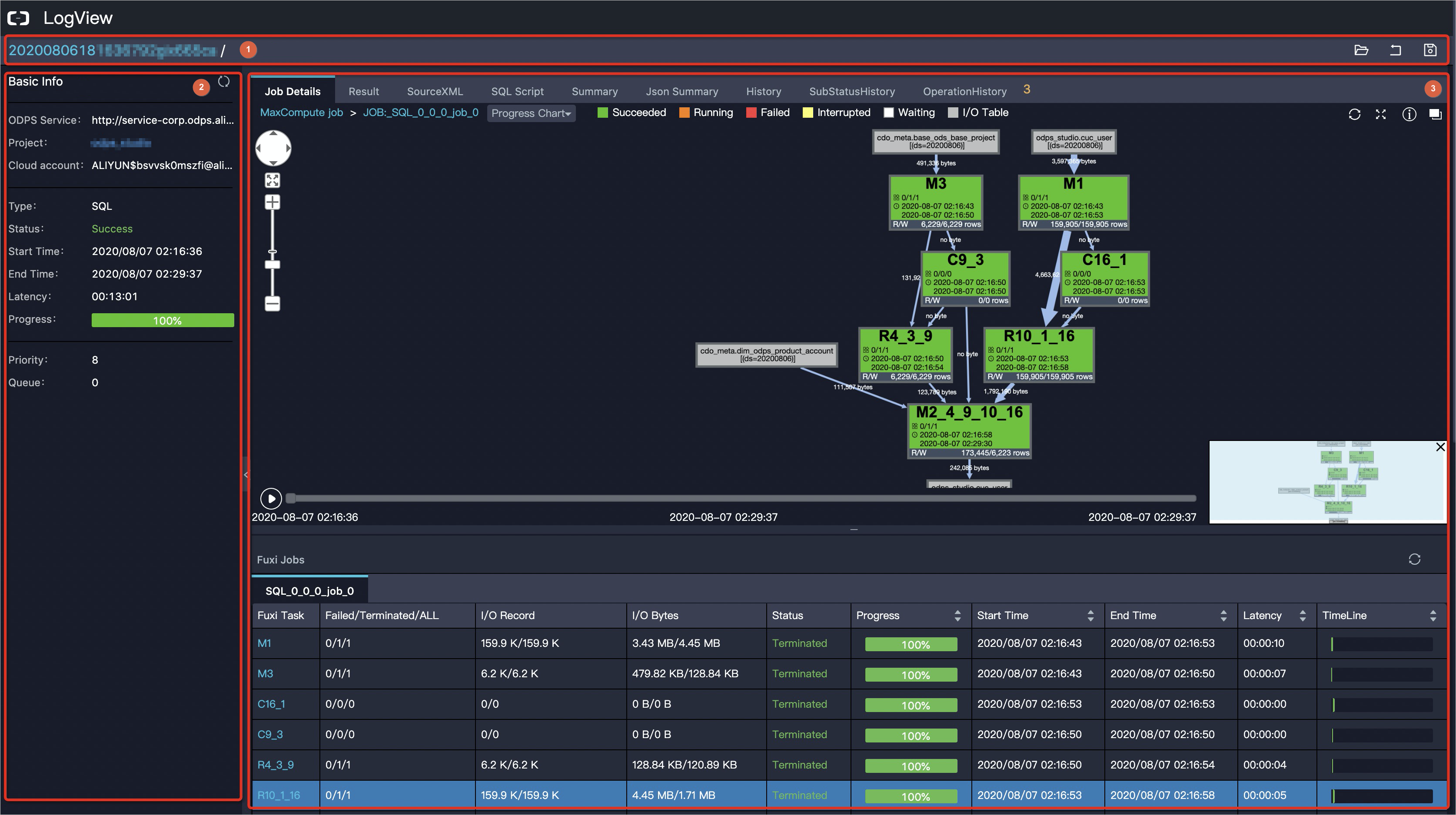
LogView は MaxCompute ジョブのステータスを記録・表示します。ジョブを送信した後、LogView の URL を開いて、実行進捗のモニタリング、実行詳細の確認、障害の診断を行います。インタラクティブな有向非循環グラフ(DAG)、実行再生機能、および Fuxi Sensor リソースチャートにより、遅延タスクの特定、失敗インスタンスの位置特定、CPU やメモリのボトルネック分析が可能になります。
LogView へのアクセス
MaxCompute ジョブを送信すると、システムは自動的に https://logview.aliyun.com/logview で始まる URL を生成します。
MaxCompute クライアント:URL をコピーし、ブラウザに貼り付けます。
DataWorks:URL を直接クリックして LogView ページを開きます。
LogView ページは以下の 3 つのセクションで構成されます:
| 番号 | セクション |
|---|---|
| 1 | タイトルおよび機能セクション |
| 2 | 基本情報セクション |
| 3 | ジョブ詳細セクション |
タイトルおよび機能セクション
このセクションにはジョブ ID とジョブ名が表示されます。ジョブ ID は MaxCompute ジョブを一意に識別するものであり、ジョブ送信時に生成されます。ジョブ名は SDK 経由でジョブを送信した場合にのみ表示されます。
右側のアイコンを使用して、以下の操作を行います:
| アイコン | 操作 |
|---|---|
| Logview_detail.txt ファイル(ジョブ詳細を含む)を開きます。ファイルはご利用のコンピューターに保存されます。 | |
| LogView V1.0 ページに戻ります。 | |
| ジョブ詳細をファイルとしてご利用のコンピューターに保存します。 |
基本情報セクション
基本情報セクションには、ジョブに関するメタデータが表示されます。
| パラメーター | 説明 |
|---|---|
| MaxCompute サービス | ジョブが実行される MaxCompute のエンドポイントです。詳細については、「エンドポイント」をご参照ください。 |
| プロジェクト | ジョブが属する MaxCompute プロジェクトです。 |
| クラウドアカウント | ジョブ送信に使用された Alibaba Cloud アカウントです。 |
| タイプ | ジョブの種類です。有効な値:SQL、SQLRT、LOT、XLib、CUPID、AlgoTask、Graph。 |
| ステータス | ジョブのステータスです。「ジョブステータス値」をご参照ください。 |
| 開始時刻 | ジョブが送信された時刻です。 |
| 終了時刻 | ジョブが完了した時刻です。 |
| レイテンシー | 合計実行時間です。 |
| 進捗 | 現在の完了率です。 |
| 優先度 | ジョブの優先度です。 |
| キュー | ジョブがリソースクォータグループのキュー内で占める位置です。 |
ジョブステータス値
| ステータス | 説明 |
|---|---|
| Waiting(待機中) | ジョブは MaxCompute 内でキューに登録されていますが、まだジョブスケジューラーに送信されていません。 |
| Running(実行中) | ジョブはジョブスケジューラーによって処理されています。 |
| Success(成功) | ジョブが正常に完了しました。 |
| Failed(失敗) | ジョブが失敗しました。 |
| Canceled(キャンセル済み) | ジョブがキャンセルされました。 |
| Terminated(終了済み) | ジョブが完了しました。 |
ジョブ詳細セクション
ジョブ詳細セクションには複数のタブが含まれています。下表では各タブの診断目的を対応付けており、適切なビューに直接移動できます。
| タブ | 使用タイミング |
|---|---|
| ジョブ詳細 | 実行構造を理解し、DAG、ヒートチャート、インスタンスレベルのステータスを確認することで、遅延または停止状態のタスクを特定します。 |
| Fuxi Sensor | リソース消費量を分析します。たとえば、メモリ不足(OOM)エラーの原因を調査したり、タスクの予想より遅い実行理由を解明します。 |
| 結果 | ジョブが成功した場合は出力結果を表示し、失敗した場合は失敗理由を表示します。 |
| SubStatusHistory | ジョブが各ステージで何を実行していたか、および待機または失敗した理由を理解します。 |
| SourceXML | ジョブの生の構成(XML、設定、フラグ値)を確認します。 |
| SQL スクリプト | 現在のタスクの SQL スクリプトを表示します。 |
| 履歴 | 現在のタスクの実行履歴を表示します。 |
ジョブ詳細タブ
ジョブ詳細 タブは、実行構造を理解し、ジョブの遅延や停止箇所を特定するための主要なビューです。
進捗チャート
このタブ上部の進捗チャートでは、Fuxi ジョブ、Fuxi タスク、およびオペレーター間の依存関係をインタラクティブな有向非循環グラフ(DAG)として表示します。
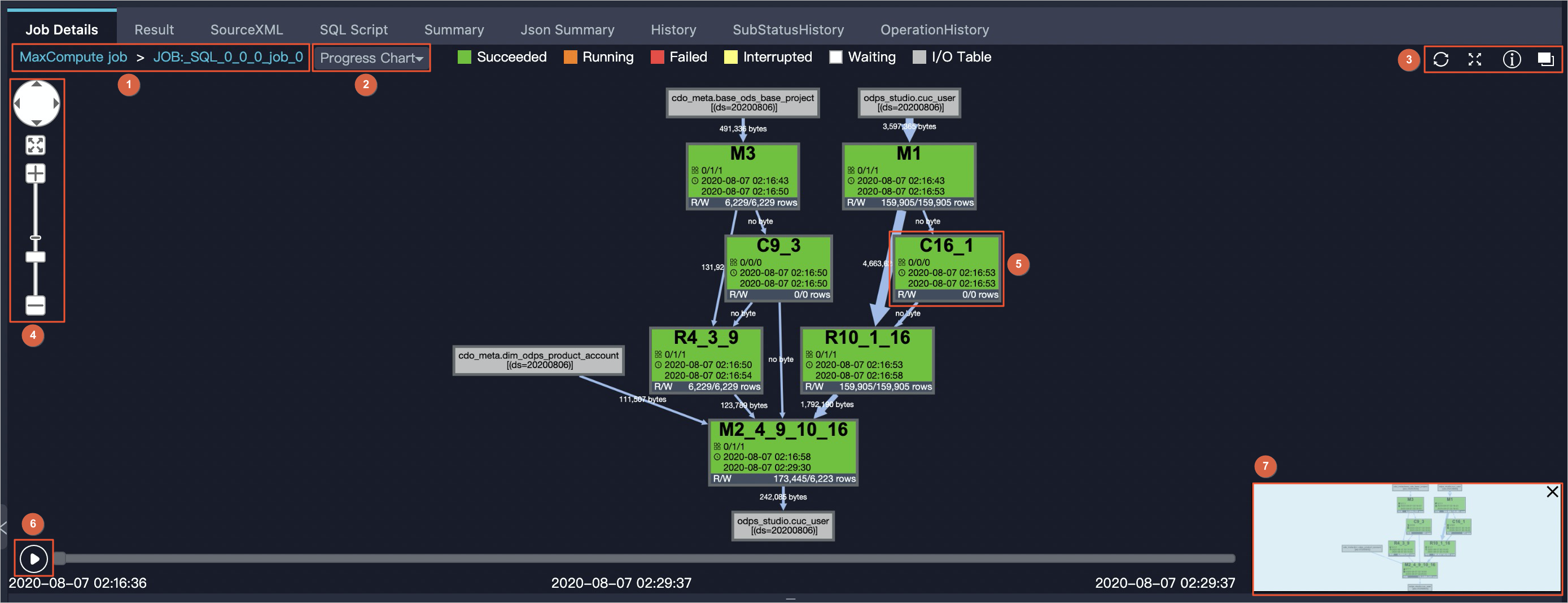
| 番号 | 要素 |
|---|---|
| 1 | Fuxi ジョブ間の切り替え用のパンくずナビゲーション。例:JOB:_SQL_0_0_0_job_0 は Fuxi ジョブ名です。 |
| 2 | トラブルシューティングツール:進捗チャート、入力ヒートチャート、出力ヒートチャート、TaskTime ハートチャート、InstanceTime ハートチャート。 |
| 3 | ツールバーのアイコン:ジョブステータスのリフレッシュ、拡大/縮小、MaxCompute Studio のドキュメントの開示、親レベルへの切り替え。 |
| 4 | ズームツール。 |
| 5 | Fuxi タスク。詳細については、「Fuxi タスク構造」をご参照ください。 |
| 6 | 再生コントロール。再生/停止アイコンをクリックすると再生または停止が開始されます。プログレスバーをドラッグするとシーク可能です。左右に開始時刻および終了時刻が表示され、中央に現在の再生時刻が表示されます。 |
| 7 | 完全 DAG のサムネイル。 |
ジョブが単一の Fuxi ジョブで構成される場合、チャートには Fuxi タスク間の依存関係が表示されます。
ジョブが複数の Fuxi ジョブで構成される場合、チャートにはそれらの Fuxi ジョブ間の依存関係が表示されます。
Fuxi タスクが「Running(実行中)」ステータスの場合、再生機能は利用できません。AlgoTask ジョブ(Platform for AI(PAI)ジョブなど)は単一の Fuxi タスクのみを含むため、進捗チャートは表示されません。非 SQL ジョブでは、Fuxi ジョブおよび Fuxi タスクのみが表示されます。
Fuxi タスク構造
MaxCompute ジョブは 1 つ以上の Fuxi ジョブで構成され、各 Fuxi ジョブは 1 つ以上の Fuxi タスクで構成されます。各 Fuxi タスクは 1 つ以上の Fuxi インスタンス上で実行され、入力データ量の増加に応じてインスタンス数が追加されます。
Fuxi タスクのプレフィックスはタスクの種類を示します:
| プレフィックス | タスクの種類 |
|---|---|
| M | データスキャン |
| R | Reduce |
| J | JOIN |
| C | 仮想ノード(ブランチ選択専用。計算処理なし) |
タスク名には依存関係がエンコードされています。例:
R4_3_9— タスク R4 は、タスク M3 および C9_3 の完了後にのみ実行可能です。M2_4_9_10_16— タスク M2 は、タスク R4_3_9、C9_3、R10_1_16、および C16_1 の完了後にのみ実行可能です。各タスクノードに表示される R/W は、読み取りおよび書き込みの行数を示します。
タスクノードをクリックまたは右クリックすると、そのタスクのオペレーター依存関係およびオペレーターグラフを表示できます。
ジョブステータスパネル
ジョブ詳細 タブの下部には、Fuxi タスクおよびインスタンスの詳細が一覧表示されます。
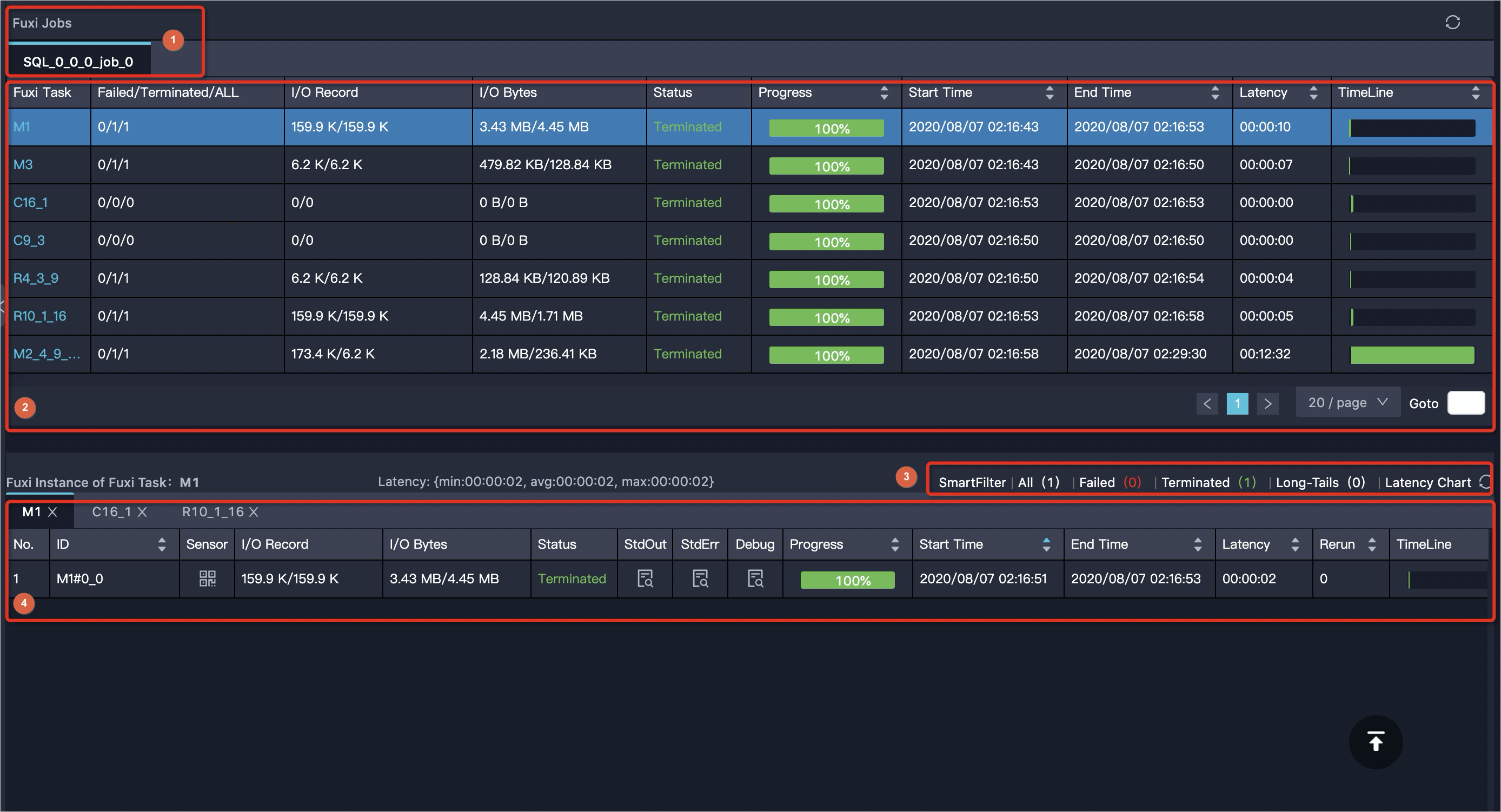
| 番号 | 要素 |
|---|---|
| 1 | Fuxi ジョブ間の切り替え用の Fuxi ジョブ タブ。 |
| 2 | Fuxi タスクの詳細です。Fuxi タスクをクリックすると、そのインスタンスに関する情報を表示します。デフォルトでは、最初の Fuxi ジョブの最初の Fuxi タスクのインスタンスが表示されます。AlgoTask ジョブおよび Cupid コンソールで実行中のジョブでは、Sensor 列が表示されます。センサー アイコンをクリックすると、該当インスタンスの CPU およびメモリ情報を表示できます。 |
| 3 | ステータスごとのインスタンスグループです。「Failed(失敗)」の横にあるカウントをクリックすると、失敗したインスタンスを確認できます。 |
| 4 | 個別の Fuxi インスタンスおよびその詳細です。 |
Fuxi インスタンス ID は M1#0_0 の形式です:
最初の数字は自動インクリメントのインスタンス ID です。
2 番目の数字は再実行回数です(0 は Fuxi タスクの再実行に失敗したことを意味します)。
各インスタンスでは以下の情報を公開しています:
StdOut / StdErr:出力およびエラーメッセージ(ダウンロード可能)。
Debug:デバッグおよびトラブルシューティングのためのツール。
Fuxi タスクが Interrupted ステータスを示す場合、タスクは再実行される可能性があります。この場合、進捗 列には再実行の進捗のみが反映されるため、全体のジョブが成功してもタスクの進捗が 100 % 未満となることがあります。これは想定された動作です。Fuxi インスタンスの使用制限
次のいずれかの条件が SQL ステートメントに該当する場合、Fuxi インスタンス数は 1 に制限されます:
LIMIT句が使用されている。ウィンドウ関数が
PARTITION BY KEY句なしで使用されている。集計関数が
GROUP BY KEY句なしで使用されている。JOIN 操作に等結合キーがない。
ORDER BY句が使用されている。
Fuxi Sensor タブ
Fuxi Sensor を使用してリソース消費量を分析します。たとえば、メモリ不足(OOM)エラーの原因を調査したり、タスクの予想より遅い実行理由を理解します。
Fuxi Sensor では、個々の Fuxi インスタンスの CPU 使用率およびメモリ使用量を表示します。
Fuxi Sensor は、中国(成都)、中国(深セン)、中国(上海)、中国(杭州)、中国(張家口)、および中国(北京)のリージョンで利用可能です。
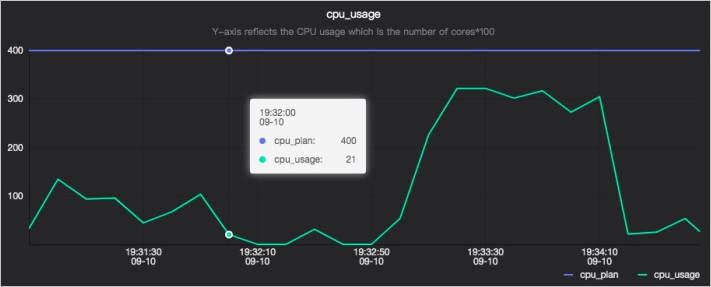
CPU 使用率
cpu_usage チャートには 2 本のラインがあります:
cpu_plan:要求された CPU 数。cpu_usage:実際に使用された CPU 数。
Y 軸の値 400 は 4 個のプロセッサを表します。要求される CPU 数はプロセッサ数を変更することで調整できますが、使用可能な CPU 数は個別に設定できません。
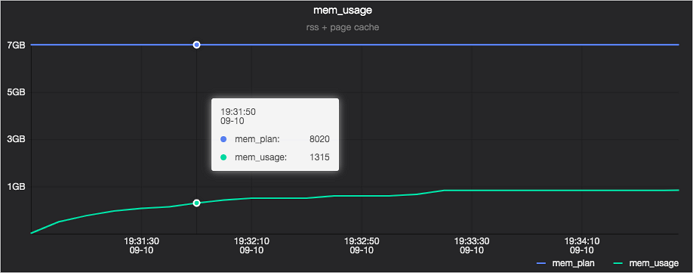
メモリ使用量
mem_usage チャートには 2 本のラインがあります:
mem_plan:要求されたメモリ量。mem_usage:実際に使用されたメモリ量。
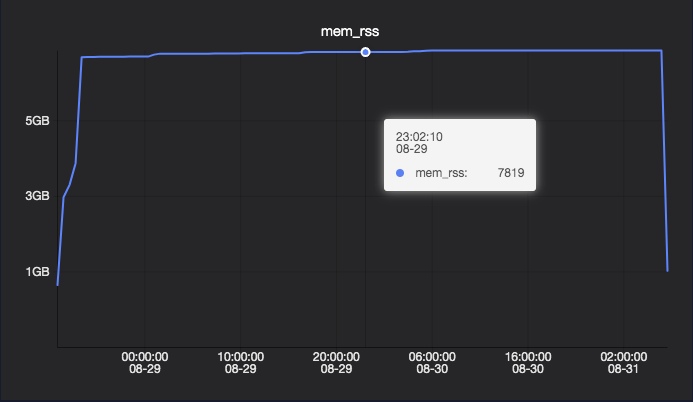
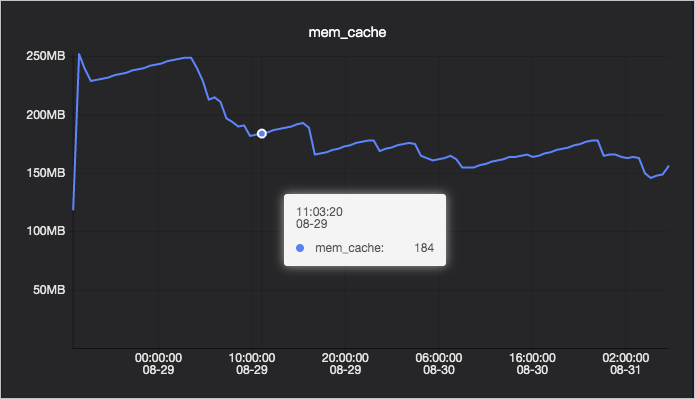
mem_usage は、以下の 2 つのコンポーネントの合計です:
| コンポーネント | 説明 | 再利用可能 |
|---|---|---|
| RSS(Resident Set Size) | カーネルのページフォールト後に割り当てられたメモリで、malloc が非ファイルマッピングに対して呼び出された際に使用されます。 | いいえ |
| PageCache | カーネルが読み書き操作(例:ログファイル)のためにキャッシュに使用するメモリです。 | はい |
このタブでは、メモリ分析のための以下の 3 つのサブチャートが提供されます:
メモリ詳細
RSS 使用量
PageCache 使用量
結果タブ
結果 タブでは、ジョブの結果に応じて異なる内容が表示されます:
成功:ジョブの結果が表示されます。
失敗:失敗理由が表示されます。
自動結果表示を無効にするには、以下のコマンドを実行します:
setproject odps.forbid.fetch.result.by.bearertoken=true;結果表示フォーマットを変更するには、odps.sql.select.output.format を設定します:
-- CSV 形式で結果を表示
set odps.sql.select.output.format=csv;
-- プレーンテキスト形式で結果を表示
set odps.sql.select.output.format=HumanReadable;SubStatusHistory タブ
SubStatusHistory タブでは、現在のタスクのステータス遷移を表示します。このタブを使用して、ジョブが各ステージで何を実行していたか、および待機または失敗した理由を理解します。
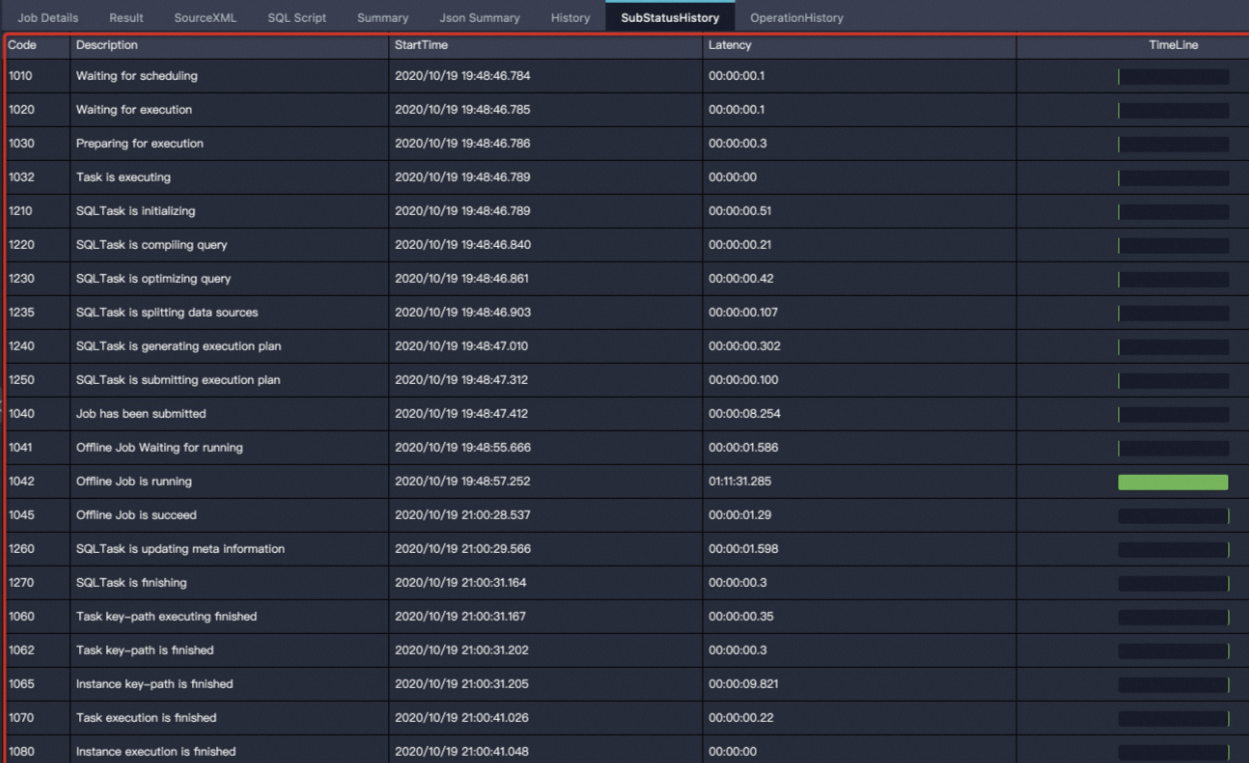
| ステータスコード | 説明 |
|---|---|
| Waiting for scheduling(スケジューリング待ち) | ジョブが送信され、MaxCompute フレームワークによるスケジューリングを待っています。通常、待機時間は短時間です。 |
| Waiting for cluster resource(クラスターリソース待ち) | MaxCompute フレームワークが Fuxi コンピューティングクラスター内のリソース不足を検出しました。 |
| Waiting for concurrent task slot(同時タスクスロット待ち) | プロジェクトレベルの速度制限がトリガーされました。プロジェクトには、同時に実行できる SQL タスク数の上限があります。 |
| Waiting for data replication(データレプリケーション待ち) | ジョブがデータレプリケーションの完了を待っています。 |
| Waiting for execution slot(実行スロット待ち) | システムレベルの速度制限がトリガーされました。 |
| Waiting for cleaning up of previous task attempt(前回のタスク試行のクリーンアップ待ち) | ジョブが前回のタスク試行のクリーンアップを待っています。 |
| Waiting for execution(実行待ち) | ジョブが親プロセスのキューから子プロセスへ配布されるのを待っています。通常、待機時間は短時間です。 |
| Preparing for execution(実行準備中) | ジョブが子プロセスへ配布されています。子プロセスが異常な場合、このフェーズに時間がかかることがあります。 |
| Task is executing(タスク実行中) | ジョブが MaxCompute フレームワーク上で実行されています。 |
| SQLTask is initializing(SQLTask 初期化中) | SQL タスクが初期化されています。 |
| SQLTask is compiling query(SQLTask クエリコンパイル中) | SQL タスクはコンパイル中です。 |
| SQLTask is optimizing query(SQLTask クエリ最適化中) | SQL タスクがクエリプランを最適化しています。複雑な実行プランの場合、このフェーズに時間がかかることがあります。最適化に異常に長い時間がかかる場合、エラーが発生することがあります。 |
| SQLTask is splitting data sources(SQLTask データソース分割中) | SQL タスクが最適化のためにデータソースを分割しています。 |
| SQLTask is generating execution plan(SQLTask 実行計画生成中) | SQL タスクが実行計画を生成しています。ここで長時間かかる場合、過剰なパーティション数または多数の小規模ファイルからデータが読み込まれている可能性があります。 |
| SQLTask が実行計画を送信しています | SQL タスクが実行計画を送信しています。 |
| Job has been submitted(ジョブ送信済み) | ジョブがコンピューティングクラスターに送信されました。 |
| Offline Job Waiting for running(オフラインジョブ実行待ち) | ジョブはリソースが利用可能であると判断された時点で Fuxi クラスターに送信されましたが、送信後にリソースが利用不可となりました。ジョブはリソースの確保を待っています。このステータスは 1 回のみ表示されます。 |
| Offline Job is running(オフラインジョブ実行中) | 実行中の Fuxi ジョブがリソース不足の状態です(例:優先度の高いジョブがリソースを先行占有)。一部の Fuxi インスタンスが ready ステータスで実行待ちとなっています。 |
| Offline Job is failed(オフラインジョブ失敗) | Fuxi ジョブが失敗しました。 |
| オフライン ジョブは成功しました | Fuxi ジョブが正常に完了しました。 |
| SQLTask is updating meta information(SQLTask メタ情報更新中) | SQL タスクがメタデータを更新し、動的パーティションを生成しています。この処理には時間がかかることがあります。 |
| SQLTask is finishing(SQLTask 終了中) | SQL タスクが終了しています。 |
| オンライン ジョブは fuxi によってキャンセルされました。 | service mode で実行中のジョブがキャンセルされました。 |
| Task rerun(タスク再実行) | ジョブが再実行されています。service mode で実行中のジョブが失敗しオフラインモードに切り替わった場合、またはデータがクラスター間でレプリケーションされた場合に発生します。 |
| Online Job Waiting for running(オンラインジョブ実行待ち) | service mode のジョブは実行を待っています。 |
| Online Job is running(オンラインジョブ実行中) | service mode で実行中のジョブです。 |
| Online Job is failed(オンラインジョブ失敗) | service mode で実行中のジョブが失敗しました。 |
| Online Job is succeed(オンラインジョブ成功) | service mode で実行中のジョブが正常に完了しました。 |
| オンライン ジョブは fuxi によってキャンセルされました。 | service mode で実行中のジョブがキャンセルされました。 |
| Task key-path executing finished(タスクのキーパス実行完了) | ジョブのキーエグゼクションパスは完了しましたが、DetailStatus などのデータはまだ生成されていません。 |
| Task key-path is finished(タスクのキーパス完了) | ジョブのキーエグゼクションパスは完了しました。 |
| Instance key-path is finished(インスタンスのキーパス完了) | インスタンスのキーエグゼクションパスは完了しました。 |
| Task execution is finished(タスク実行完了) | ジョブは完了し、DetailStatus が生成されました。 |
| Instance execution is finished(インスタンス実行完了) | ジョブは完了しました。 |
| Execution failed(実行失敗) | ジョブが失敗しました。 |
SourceXML タブ
SourceXML タブには、以下の 3 つのサブタブがあります:
| サブタブ | 内容 |
|---|---|
| XML | XML 形式のジョブレベルおよびタスク情報。 |
| 設定項目 | 現在のタスクの構成設定。 |
| コマンド | 現在のタスクのフラグ設定。 |
SQL スクリプトタブ
SQL スクリプト タブでは、現在のタスクの SQL スクリプトを表示します。
履歴タブ
履歴 タブでは、現在のタスクの実行履歴を表示します。