ユーザー定義集計関数 (UDAF) は、複数の入力行を 1 つの出力値に集約します。これは、SUM や AVG などのビルトイン関数と同様の動作ですが、そのロジックは Java で独自に定義します。
仕組み
MaxCompute では、UDAF が分散パイプライン上で 3 つのフェーズに分けて処理されます。
| フェーズ | 呼び出されるメソッド | 処理内容 |
|---|---|---|
| Map(イテレート) | iterate() | 各ワーカーが割り当てられた入力行のパーティションを読み込み、各行ごとに iterate() を 1 回呼び出して、結果をローカルバッファーに累積します。 |
| Combine/Shuffle(マージ) | merge() | ワーカー間で部分的なバッファーを交換します。merge() は、他のワーカーから受け取った部分バッファーをメインバッファーに統合し、Map タスク間の結果を集約します。 |
| Reduce(ターミネート) | terminate() | すべてのバッファーがマージされた後、terminate() がバッファーから最終的な出力値を抽出します。 |
データが分散ワーカー間で移動するため、集約バッファーはシリアル化可能である必要があります。Writable インターフェイスを実装することで、メモリ上のオブジェクトをネットワーク転送およびディスクストレージ用のバイト列に変換できます。
UDAF のコード構造
Java UDAF は、以下のコンポーネントで構成されます。
| コンポーネント | 必須 | 説明 |
|---|---|---|
| Java パッケージ | 不要 | クラスを JAR ファイルにパッケージ化します |
| 基底クラス | はい | com.aliyun.odps.udf.Aggregator および com.aliyun.odps.udf.annotation.Resolve |
com.aliyun.odps.udf.UDFException | いいえ | 初期化および終了メソッドで使用されます |
@Resolve アノテーション | はい | 入力および出力のデータ型を宣言します |
| カスタム Java クラス | はい | Aggregator を継承し、バッファーおよびロジックを定義します |
必須メソッド
com.aliyun.odps.udf.Aggregator を継承し、以下のメソッドを実装します。
import com.aliyun.odps.udf.ContextFunction;
import com.aliyun.odps.udf.ExecutionContext;
import com.aliyun.odps.udf.UDFException;
public abstract class Aggregator implements ContextFunction {
// 処理開始前に 1 回呼び出されます。初期化に使用します。
@Override
public void setup(ExecutionContext ctx) throws UDFException {}
// 処理終了後に 1 回呼び出されます。クリーンアップに使用します。
@Override
public void close() throws UDFException {}
// 各グループごとに新しい空の集約バッファーを作成します。
abstract public Writable newBuffer();
// Map フェーズ:各行ごとに 1 回呼び出されます。データをバッファーに累積します。
// args は null になりませんが、args 内の個々の値は null になる場合があります(SQL NULL 入力を示します)。
abstract public void iterate(Writable buffer, Writable[] args) throws UDFException;
// Combine/Reduce フェーズ:部分バッファー(partial)をメインバッファーにマージします。
abstract public void merge(Writable buffer, Writable partial) throws UDFException;
// Reduce フェーズ:完全にマージされたバッファーから最終的な出力値を抽出します。
abstract public Writable terminate(Writable buffer) throws UDFException;
}必須メソッドと任意メソッド:
| メソッド | 必須 | 実行タイミング |
|---|---|---|
newBuffer() | 常に | 各グループの処理開始前 |
iterate() | 常に | Map フェーズ — 各入力行ごとに 1 回 |
merge() | 常に | Combine/Shuffle フェーズ — 異なるワーカーからの部分バッファーを統合 |
terminate() | 常に | Reduce フェーズ — 最終出力を生成 |
setup() | 初期化が必要な場合のみ | タスク開始前 |
close() | クリーンアップが必要な場合のみ | タスク終了後 |
iterate()およびmerge()は、同一グループ内で同じバッファーインスタンスを共有します。両方のメソッドから競合せずにデータを累積できるよう、バッファーを設計してください。
集約バッファー
集約バッファーは、分散パイプラインを通過するデータの途中結果を保持します。Writable インターフェイスを実装することで、シリアル化可能になります。
import com.aliyun.odps.io.Writable;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
private static class MyBuffer implements Writable {
// バッファーのフィールドをネットワーク転送用のバイトストリームにシリアル化します。
@Override
public void write(DataOutput out) throws IOException {
// 各フィールドを固定順序で書き込みます。
}
// バイトストリームからフィールドをデシリアライズします。
@Override
public void readFields(DataInput in) throws IOException {
// write() と同じ順序で各フィールドを読み込みます。
}
}フィールドの読み書きは、必ず同一の順序で行う必要があります。write() と readFields() の順序が一致しないと、デバッグが困難な静かなデータ破損が発生します。
@Resolve アノテーション
@Resolve アノテーションを使用して、入力および戻り値のデータ型を宣言します。MaxCompute は、セマンティック解析時に型の整合性をチェックし、不一致があるとジョブ実行前にエラーを返します。
書式:
@Resolve('<arg_type_list> -> <return_type>')| 項目 | 説明 |
|---|---|
arg_type_list | カンマ区切りの入力型です。* を指定すると任意の引数数を受け付け、空白のままにすると引数を一切受け付けません。 |
return_type | 単一の戻り値型です。UDAF は常に 1 列を返します。 |
サポートされる型には、BIGINT、STRING、DOUBLE、BOOLEAN、DATETIME、DECIMAL、FLOAT、BINARY、DATE、DECIMAL(precision,scale)、CHAR、VARCHAR、ARRAY、MAP、STRUCT、およびネストされた複合型が含まれます。
データ型のエディションに基づいてデータ型を選択してください。詳細については、「データ型のエディション」をご参照ください。
例:
| アノテーション | 入力型 | 戻り値型 |
|---|---|---|
@Resolve('bigint,double->string') | BIGINT または DOUBLE | STRING |
@Resolve('*->string') | 任意 | STRING |
@Resolve('->double') | なし | DOUBLE |
@Resolve('array<bigint>->struct<x:string, y:int>') | ARRAY<BIGINT> | STRUCT<x:STRING, y:INT> |
データ型
UDAF を Java オブジェクト型または Java Writable 型で記述します。Java 型名の先頭文字は大文字にする必要があります(例:String、string は不可)。プリミティブ型は使用しないでください。これらは SQL NULL 値を表現できず、MaxCompute では Java の null にマップされます。
Java Writable 型を入力または戻り値型として使用する場合は、MaxCompute V2.0 データ型エディション以降が必要です。
| MaxCompute の型 | Java 型 | Java Writable 型 |
|---|---|---|
| TINYINT | java.lang.Byte | ByteWritable |
| SMALLINT | java.lang.Short | ShortWritable |
| INT | java.lang.Integer | IntWritable |
| BIGINT | java.lang.Long | LongWritable |
| FLOAT | java.lang.Float | FloatWritable |
| DOUBLE | java.lang.Double | DoubleWritable |
| DECIMAL | java.math.BigDecimal | BigDecimalWritable |
| BOOLEAN | java.lang.Boolean | BooleanWritable |
| STRING | java.lang.String | Text |
| VARCHAR | com.aliyun.odps.data.Varchar | VarcharWritable |
| BINARY | com.aliyun.odps.data.Binary | BytesWritable |
| DATE | java.sql.Date | DateWritable |
| DATETIME | java.util.Date | DatetimeWritable |
| TIMESTAMP | java.sql.Timestamp | TimestampWritable |
| INTERVAL_YEAR_MONTH | 該当なし | IntervalYearMonthWritable |
| INTERVAL_DAY_TIME | 該当なし | IntervalDayTimeWritable |
| ARRAY | java.util.List | 該当なし |
| MAP | java.util.Map | 該当なし |
| STRUCT | com.aliyun.odps.data.Struct | 該当なし |
UDAF の作成
例 1:平均値計算(AggrAvg)
この例では、MaxCompute Studio を使用して、DOUBLE 型のカラムの平均値を計算する UDAF AggrAvg を開発します。
バッファーには、累積和と行数の 2 つのフィールドが格納されます。iterate() は Map フェーズで各行の入力を累積し、merge() は Combine フェーズで異なるワーカーからの部分バッファーを統合し、terminate() は Reduce フェーズで総和を総数で除算して平均値を算出します。
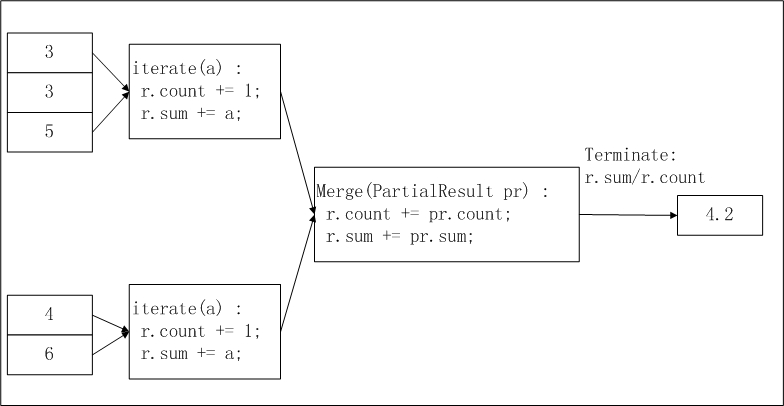
入力データはスライス分割され、ワーカーに分散されます。odps.stage.mapper.split.size パラメーターを設定することで、各スライスのサイズを調整できます。各ワーカーは自身のスライス内のレコード数および合計値をカウント(中間結果)、ワーカーがスライス情報を収集した後、最終出力では r.sum / r.count を平均値として計算します。
前提条件
開始する前に、以下の準備が完了していることを確認してください。
MaxCompute Studio をインストール済みであること。詳細については、「MaxCompute Studio のインストール」をご参照ください。
MaxCompute Studio をプロジェクトに接続済みであること。詳細については、「MaxCompute プロジェクトへの接続」をご参照ください。
MaxCompute Java モジュールを作成済みであること。詳細については、「MaxCompute Java モジュールの作成」をご参照ください。
UDAF クラスの作成
プロジェクト タブで、src > main > java に移動し、java を右クリックして、新規 > MaxCompute Java を選択します。
新しい MaxCompute Java クラスの作成 ダイアログボックスで、UDAF をクリックし、名前 フィールドにクラス名を入力して Enter キーを押します。この例では
AggrAvgを使用します。パッケージが未作成の場合は、名前 フィールドにpackagename.classname形式で指定してください。システムが自動的にパッケージを生成します。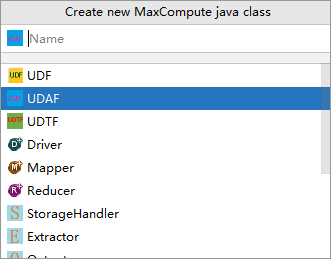
エディターで UDAF コードを記述します。
import java.io.DataInput; import java.io.DataOutput; import java.io.IOException; import com.aliyun.odps.io.Text; import com.aliyun.odps.io.Writable; import com.aliyun.odps.udf.Aggregator; import com.aliyun.odps.udf.UDFException; import com.aliyun.odps.udf.annotation.Resolve; // 入力: STRING 型の列、STRING 型の区切り文字。出力: 連結された STRING。 @Resolve("string,string->string") public class AggrConcat extends Aggregator { // バッファー: 蓄積されたテキストと値間で使用する区切り文字。 private static class ConcatBuffer implements Writable { private StringBuilder sb = new StringBuilder(); private String separator = ","; @Override public void write(DataOutput out) throws IOException { // StringBuilder を文字列としてシリアル化して、ネットワーク転送中にデータが保持されるようにします。 out.writeUTF(sb.toString()); out.writeUTF(separator); } @Override public void readFields(DataInput in) throws IOException { sb = new StringBuilder(in.readUTF()); separator = in.readUTF(); } } private Text ret = new Text(); @Override public Writable newBuffer() { return new ConcatBuffer(); } // マップフェーズ: null でない各値をバッファーに追加します。 @Override public void iterate(Writable buffer, Writable[] args) throws UDFException { Text value = (Text) args[0]; Text sep = (Text) args[1]; ConcatBuffer buf = (ConcatBuffer) buffer; if (value != null) { if (sep != null) { buf.separator = sep.toString(); } if (buf.sb.length() > 0) { buf.sb.append(buf.separator); } buf.sb.append(value.toString()); } } // コンバインフェーズ: 別のワーカーからの部分的なバッファーをマージします。 @Override public void merge(Writable buffer, Writable partial) throws UDFException { ConcatBuffer buf = (ConcatBuffer) buffer; ConcatBuffer p = (ConcatBuffer) partial; if (p.sb.length() > 0) { if (buf.sb.length() > 0) { buf.sb.append(buf.separator); } buf.sb.append(p.sb); } } // リデュースフェーズ: 連結された結果を返します。 @Override public Writable terminate(Writable buffer) throws UDFException { ConcatBuffer buf = (ConcatBuffer) buffer; ret.set(buf.sb.toString()); return ret; } }
ローカルでのデバッグ
UDAF を本番環境にデプロイする前に、ローカルマシンで実行してロジックを検証します。「UDF のローカル実行によるデバッグ」の手順については、「UDF の開発」をご参照ください。
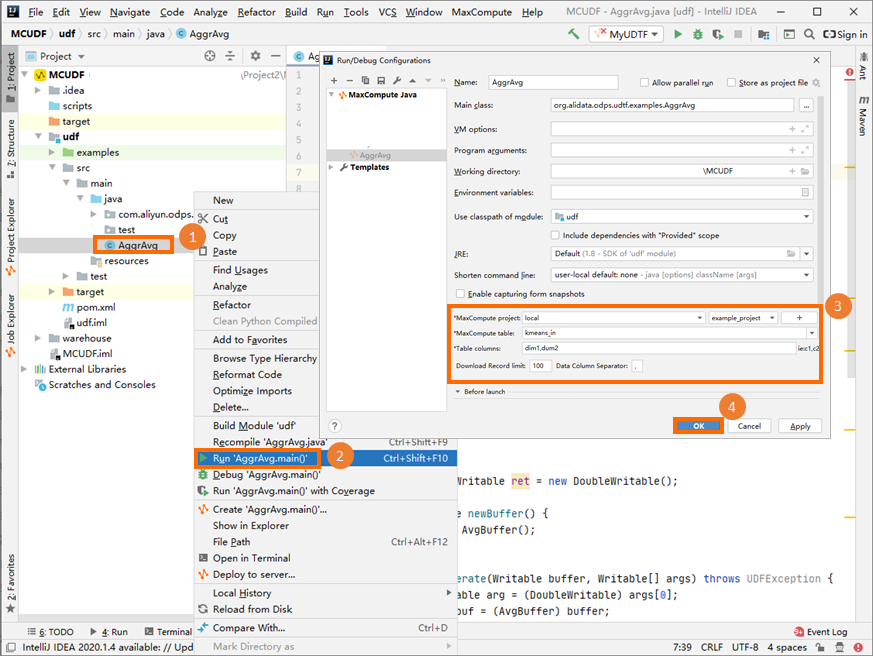
上記図のパラメータ設定は参考用です。
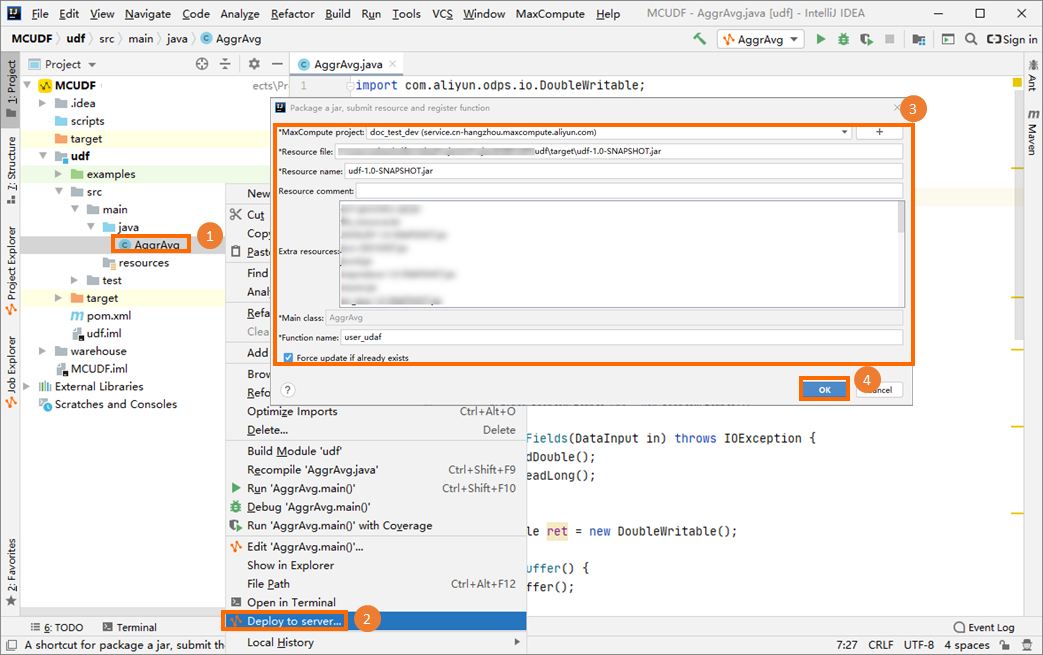
UDAF のパッケージ化および登録
UDAF コードを JAR ファイルにパッケージ化し、MaxCompute プロジェクトにアップロードして UDAF を作成します。「Java プログラムのパッケージ化、パッケージのアップロード、および MaxCompute UDF の作成」の手順については、「Java プログラムのパッケージ化、パッケージのアップロード、および MaxCompute UDF の作成」をご参照ください。
この例では、UDAF を user_udaf として登録します。
UDAF の呼び出し
プロジェクトエクスプローラー で MaxCompute プロジェクトを右クリックし、MaxCompute クライアントを開きます。その後、SQL ステートメントを実行して UDAF を呼び出します。
次の入力テーブル(my_table)を想定します。
+------------+------------+
| col0 | col1 |
+------------+------------+
| 1.2 | 2.0 |
| 1.6 | 2.1 |
+------------+------------+以下のステートメントを実行します。
SELECT user_udaf(col0) AS c0 FROM my_table;結果:
+----+
| c0 |
+----+
| 1.4|
+----+例 2:文字列連結(AggrConcat)
AggrAvg ではシンプルな数値バッファーを使用しています。この例では、より現実的なパターンを示します。すなわち、複数の行から文字列値を収集し、区切り文字で連結する処理です。
バッファーには StringBuilder と区切り文字の文字列が格納されます。StringBuilder は直接シリアル化できないため、バッファーはこれを単純な String としてシリアル化します。これは、バッファーが非プリミティブ型を保持する場合の一般的なパターンです。write() でワイヤ安全な形式にシリアル化し、readFields() でメモリ上の形式を再構築します。
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import com.aliyun.odps.io.Text;
import com.aliyun.odps.io.Writable;
import com.aliyun.odps.udf.Aggregator;
import com.aliyun.odps.udf.UDFException;
import com.aliyun.odps.udf.annotation.Resolve;
// 入力:STRING 型のカラム、STRING 型の区切り文字。出力:連結された STRING。
@Resolve("string,string->string")
public class AggrConcat extends Aggregator {
// バッファー:累積されたテキストおよび値間の区切り文字。
private static class ConcatBuffer implements Writable {
private StringBuilder sb = new StringBuilder();
private String separator = ",";
@Override
public void write(DataOutput out) throws IOException {
// StringBuilder をネットワーク転送に耐えるように String としてシリアル化します。
out.writeUTF(sb.toString());
out.writeUTF(separator);
}
@Override
public void readFields(DataInput in) throws IOException {
sb = new StringBuilder(in.readUTF());
separator = in.readUTF();
}
}
private Text ret = new Text();
@Override
public Writable newBuffer() {
return new ConcatBuffer();
}
// Map フェーズ:null でない各値をバッファーに追加します。
@Override
public void iterate(Writable buffer, Writable[] args) throws UDFException {
Text value = (Text) args[0];
Text sep = (Text) args[1];
ConcatBuffer buf = (ConcatBuffer) buffer;
if (value != null) {
if (sep != null) {
buf.separator = sep.toString();
}
if (buf.sb.length() > 0) {
buf.sb.append(buf.separator);
}
buf.sb.append(value.toString());
}
}
// Combine フェーズ:他のワーカーからの部分バッファーをマージします。
@Override
public void merge(Writable buffer, Writable partial) throws UDFException {
ConcatBuffer buf = (ConcatBuffer) buffer;
ConcatBuffer p = (ConcatBuffer) partial;
if (p.sb.length() > 0) {
if (buf.sb.length() > 0) {
buf.sb.append(buf.separator);
}
buf.sb.append(p.sb);
}
}
// Reduce フェーズ:連結された結果を返します。
@Override
public Writable terminate(Writable buffer) throws UDFException {
ConcatBuffer buf = (ConcatBuffer) buffer;
ret.set(buf.sb.toString());
return ret;
}
}主な設計上の判断:
| 判断事項 | 説明 |
|---|---|
StringBuilder を String | StringBuilder はシリアル化可能ではありません。write() メソッド内で String に変換し、readFields() メソッド内で再構築します。 |
バッファー内に separator を保持する | iterate() メソッドの引数として渡される区切り文字は、merge() メソッドへのシリアル化時に存続させる必要があります。そのため、バッファー内に格納します。 |
merge() | ワーカーのパーティションに一致する行が存在しない場合、そのバッファーは空になります。先頭に不要な区切り文字が付加されないよう、追加前に空かどうかを確認します。 |
文字列の連結順序は、Map フェーズのパーティション割り当てが実行エンジンによって決定されるため、ワーカー間で保証されません。順序が重要な場合は、SQL ステートメントに ORDER BY 句を含め、シングルレデューサー戦略を採用するか、連結後の出力を別途ソートしてください。SQL での UDAF の呼び出し
Java UDAF の開発および登録後、MaxCompute SQL で呼び出します。開発全体の流れについては、「概要」の「開発プロセス」セクションをご参照ください。
呼び出しには、以下の 2 つの方法があります。
同一プロジェクト内: UDAF は、ビルトイン関数と同様に呼び出します。
プロジェクト間:プロジェクト A 内からプロジェクト B の UDAF を呼び出すには、以下の構文を使用します。プロジェクト間のリソース共有の詳細については、「パッケージに基づくプロジェクト間リソースアクセス」をご参照ください。
SELECT B:udf_in_other_project(arg0, arg1) AS res FROM table_t;
制限事項
インターネットアクセス
デフォルトでは、MaxCompute は UDAF のインターネットアクセスを許可していません。インターネットアクセスを有効にするには、業務要件に基づきネットワーク接続申請フォームを提出してください。承認後、MaxCompute のテクニカルサポートチームが接続の確立を支援します。「フォームの記入方法」については、「ネットワーク接続の手順」をご参照ください。
VPC アクセス
デフォルトでは、MaxCompute は UDAF の仮想プライベートクラウド(VPC)内リソースへのアクセスを許可していません。VPC アクセスを有効にするには、MaxCompute と VPC 間のネットワーク接続を確立します。「UDF を使用した VPC 内リソースへのアクセス」をご参照ください。
テーブル読み取りの制限
UDF、UDAF、およびユーザー定義のテーブル値関数(UDTF)は、以下のテーブルタイプからデータを読み取ることができません。
スキーマ進化が実行されたテーブル
複合データ型を含むテーブル
JSON データ型を含むテーブル
トランザクショナルテーブル
注意事項
異なるロジックを持つ同名のクラスを、異なる UDAF の JAR ファイルにパッケージ化しないでください。2 つの UDAF が別々の JAR ファイルで同一のクラス名(例:
com.aliyun.UserFunction.class)を使用し、同一の SQL ステートメントで呼び出された場合、MaxCompute は予測不可能な順序でいずれかのファイルからクラスをロードし、誤った結果やコンパイル失敗を引き起こす可能性があります。UDAF の Java データ型はオブジェクト型です。先頭文字は大文字にする必要があります(例:
String、stringは不可)。MaxCompute SQL の NULL 値は Java の
nullにマップされます。Java のプリミティブ型は使用しないでください。これらはnullを表現できません。
次のステップ
テーブル値関数など、より複雑な UDF を追加するには、「概要」をご参照ください。
サポートされるすべてのデータ型およびエディションについて学ぶには、「データ型のエディション」をご参照ください。