従来の MaxCompute バッチワークフローは、数時間~数日単位で増分データをインポートし、複雑な ETL マージジョブを必要とするため、高遅延・高ストレージコスト・メンテナンスの困難さといった課題がありました。ニアリアルタイムのフルおよび増分データストレージと処理の統合アーキテクチャは、Delta テーブルを導入することでこれらの課題を解決します。Delta テーブルは、プライマリキーによるアップサート、タイムトラベルクエリ、自動データガバナンスを単一のフルマネージドシステム内でサポートする統一テーブルフォーマットです。これにより、別途 ETL パイプラインを実行することなく、エンドツーエンドのデータ遅延を数時間~数日から 5~10 分に短縮できます。
背景情報
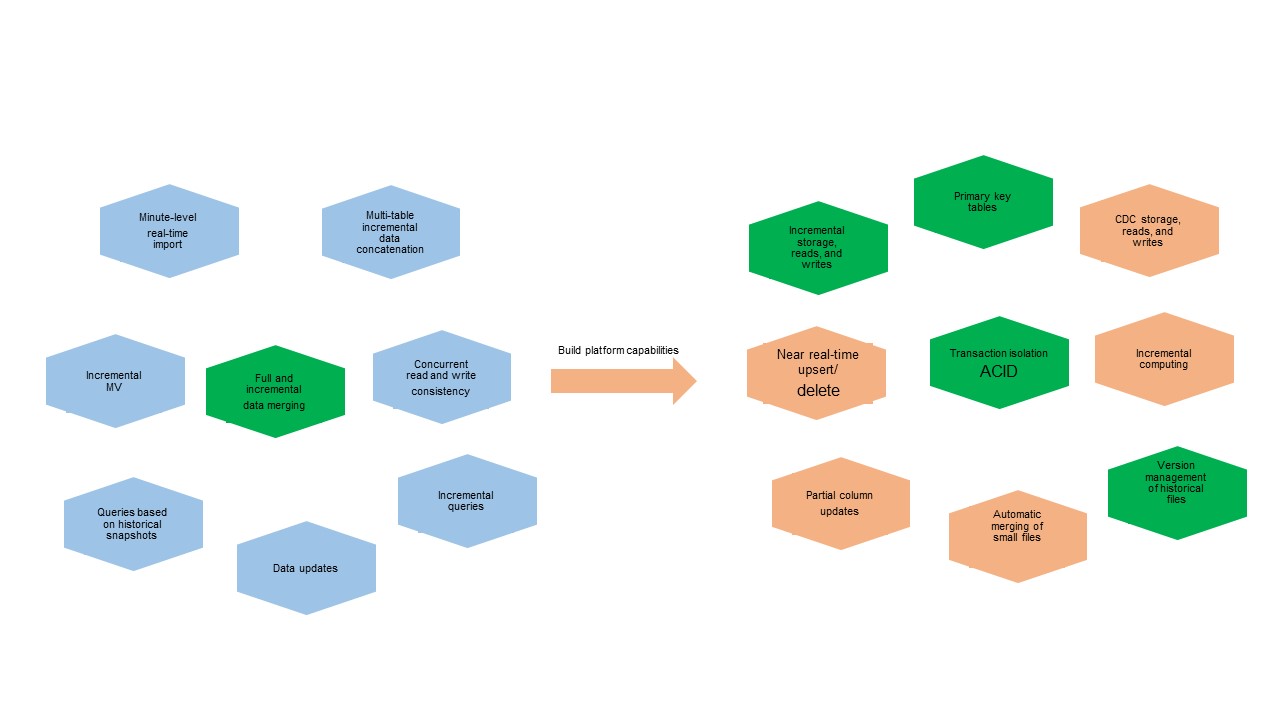
データ量が増加し、ビジネス要件が高度化するにつれ、ニアリアルタイムのデータインポートにはトランザクション隔離と自動小ファイルマージ機能を備えたプラットフォームエンジンが求められます。また、フルデータと増分データのマージには、プライマリキーを使用して増分データを格納・読み取り・書き込みできる能力が必要です。
この統合アーキテクチャ登場以前には、コスト・使いやすさ・遅延・スループットの観点でトレードオフのある 3 つの先行ソリューションが存在しました。
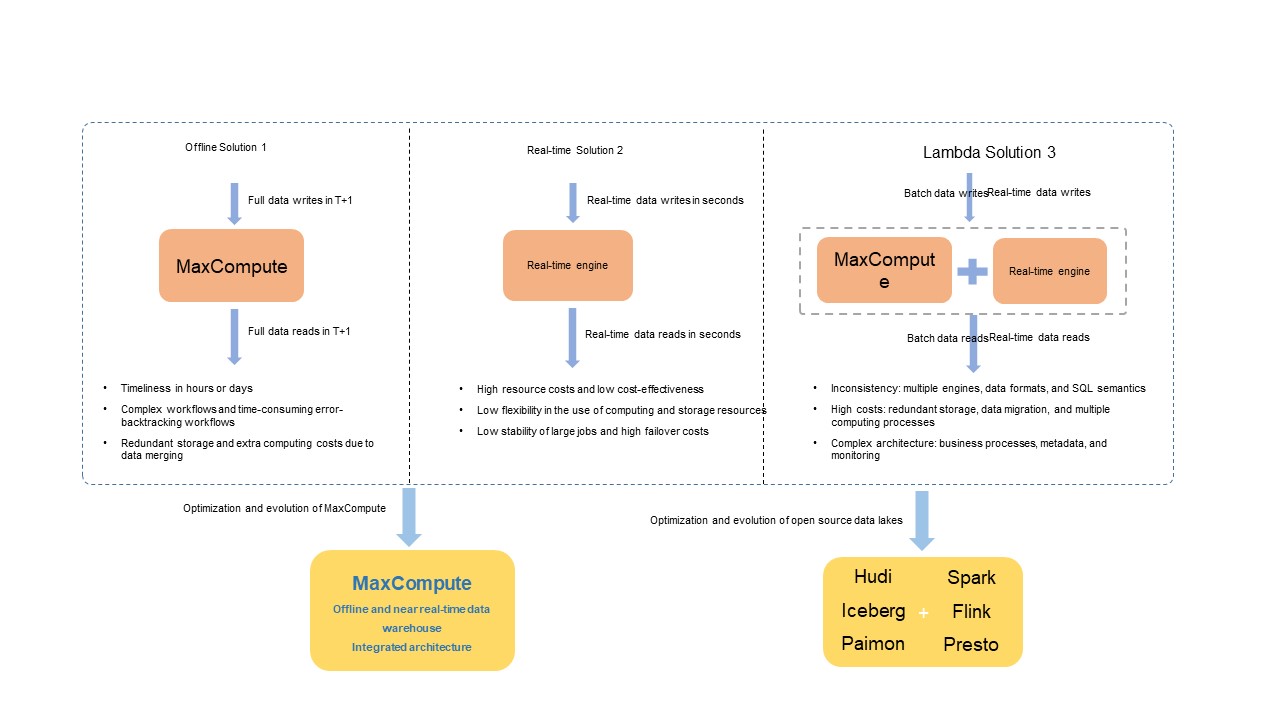
オープンソースエコシステムでは、Spark や Flink、Trino などのエンジンが Apache Hudi、Delta Lake、Apache Iceberg、Apache Paimon といったデータレイクフォーマットと統合され、オープンコンピュートエンジンと統一データストアを組み合わせることで、Lambda アーキテクチャにおける同様の課題を解決しています。
ニアリアルタイムのフルおよび増分データストレージと処理の統合アーキテクチャ
MaxCompute の統合アーキテクチャは幅広いデータソースに対応しています。カスタム開発ツールを使用して、フルおよび増分データを専用ストレージサービスにインポートできます。バックエンドのデータ管理サービスが自動的にデータストレージ構造を最適化・オーケストレーションします。統一されたコンピュートエンジンがニアリアルタイムの増分処理とバッチ処理の両方を担います。また、統一メタデータサービスがトランザクションおよびファイルのメタデータを管理します。
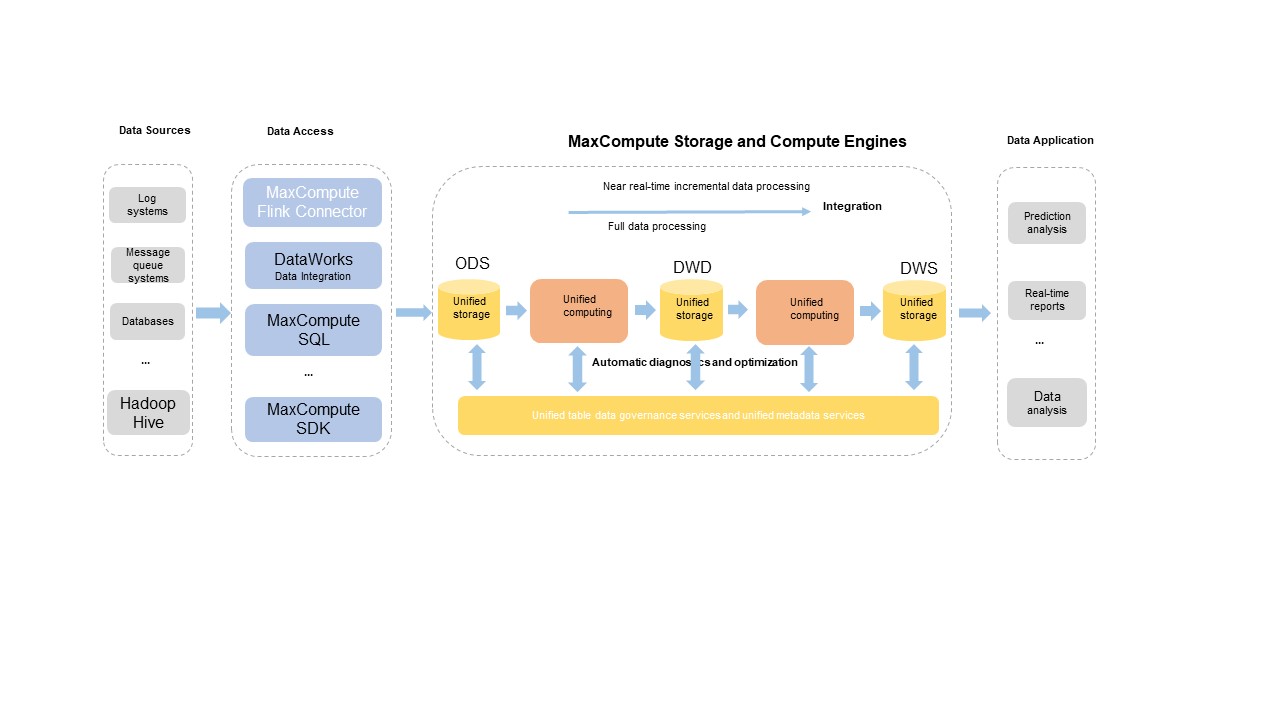
このアーキテクチャは以下のコア機能をサポートします。
-
プライマリキーテーブル
-
リアルタイムアップサート
-
タイムトラベルクエリ
-
増分クエリ
-
SQL データ操作言語 (DML) 操作
-
テーブルデータの自動ガバナンスと最適化
アーキテクチャの動作原理および関連操作の詳細については、「Delta テーブルの概要」および「基本操作」をご参照ください。
アーキテクチャのメリット
この統合アーキテクチャは、Apache Hudi や Apache Iceberg などのオープンソースデータレイクフォーマットが提供する主要な共通機能をサポートしており、ビジネスプロセス間の移行を容易にします。Alibaba Cloud が開発したプラットフォームネイティブなアーキテクチャとして、以下の利点も提供します。
| メリット | 説明 |
|---|---|
| 統一的な統合 | 統一されたストレージサービス、メタデータサービス、コンピュートエンジンを活用し、深く効率的な統合を実現します。これにより、コスト効率の高いストレージ、効率的なファイル管理、高いクエリ効率、増分データに対するタイムトラベルクエリを提供します。 |
| 完全な SQL 構文 | すべてのコア機能をサポートするために設計された汎用 SQL 構文システムを提供します。 |
| 最適化されたデータインポートツール | 複雑なビジネスシナリオ向けに深くカスタマイズされたデータインポートツールを提供します。 |
| シームレスな互換性 | 既存の MaxCompute ビジネスシナリオと統合可能で、データ移行や追加のストレージ・コンピュートコストは不要です。 |
| 自動ファイル管理 | 読み取り・書き込み操作の安定性とパフォーマンスを向上させるため、ファイル管理を完全に自動化し、ストレージ効率の自動最適化を実現します。 |
| フルマネージド、ゼロセットアップ | MaxCompute のフルマネージドサービスに基づいており、追加のアクセスコストなしで即時利用可能です。Delta テーブルを作成すると、すぐにアーキテクチャが有効になります。 |
| 自律的な開発スケジュール | 自律的かつ制御可能な開発スケジュールを維持します。 |
ビジネスシナリオ
テーブルフォーマットとデータガバナンス
テーブル作成

MaxCompute は、統合アーキテクチャをサポートするために、統一されたテーブルデータフォーマットである Delta テーブルを導入しました。Delta テーブルは、既存のバッチ処理ワークフローのすべての機能に加え、ニアリアルタイムの増分データストレージと処理といった新しいワークフローもサポートします。
Delta テーブルを作成するには、CREATE TABLE 文でプライマリキーを指定し、"transactional"="true" を設定します。
CREATE TABLE tt2 (pk BIGINT NOT NULL PRIMARY KEY, val STRING) tblproperties ("transactional"="true");
CREATE TABLE par_tt2 (pk BIGINT NOT NULL PRIMARY KEY, val STRING) PARTITIONED BY (pt STRING) tblproperties ("transactional"="true");プライマリキーは行の一意性を保証します。transactional プロパティにより、読み取り・書き込み操作に対してスナップショット隔離を備えた ACID (原子性、一貫性、独立性、永続性) トランザクションメカニズムが有効になります。詳細については、「テーブル操作」をご参照ください。
Delta テーブルの主なパラメーター
全パラメーターのリファレンスについては、「テーブル操作」の「Delta テーブルのパラメーター」セクションをご参照ください。
write.bucket.num
パーティション化テーブルまたは非パーティション化テーブルごとのバケット数および同時書き込みノード数を指定します。デフォルト値は 16 です。有効値:(0, 4096]。
-
パーティションテーブルの場合:値を変更でき、新規パーティションに自動適用されます。
-
非パーティション化テーブルの場合:作成後に値を変更できません。
バケット数を増やすと書き込みおよびクエリの並列度が向上しますが、小ファイルが増加し、ストレージコストが上昇し、読み取り効率が低下する可能性があります。バケットサイズを決定する際は、以下のガイドラインに従ってください。
| シナリオ | 推奨事項 |
|---|---|
| データ量 < 1 GB (非パーティション化またはパーティション化) | 4~16 バケット |
| データ量 > 1 GB | 各バケットを 128 MB~256 MB に維持 |
| データ量 > 1 TB | 各バケットを 500 MB~1 GB に維持 |
| > 500 パーティションを持つパーティションテーブルで、各パーティションが数十 MB 程度 | 小ファイルの肥大化を避けるため、パーティションあたり 1~2 バケット |
acid.data.retain.hours
タイムトラベルクエリで利用可能な履歴データの期間を指定します。デフォルト値は 24 です。有効値:[0, 168] (単位:時間)。
-
0に設定すると、タイムトラベルクエリが無効になり、履歴データのストレージコストが大幅に削減されます。 -
168 時間 (7 日) を超える履歴データについては、MaxCompute テクニカルサポートまでお問い合わせください。
ビジネス要件に合った保持期間を設定してください。保持期間を長くするとストレージコストが増加し、クエリが遅くなる可能性があります。保持期間が経過すると、システムは操作ログやデータファイルを含む履歴データを自動的に回収・削除します。その後は、そのデータをタイムトラベルでクエリできなくなります。保持期間が経過する前に強制的に履歴データをクリアするには、purge コマンドを実行します。
スキーマ進化
Delta テーブルは、カラムの追加・削除を含む完全なスキーマ進化をサポートします。タイムトラベルで履歴データをクエリする際、システムはその履歴バージョン時点のスキーマに基づいてデータを読み取ります。
プライマリキーは変更できません。
以下の例はカラムを追加するものです。
ALTER TABLE tt2 ADD columns (val2 string);DDL 構文の詳細については、「テーブル操作」をご参照ください。
テーブルデータフォーマット
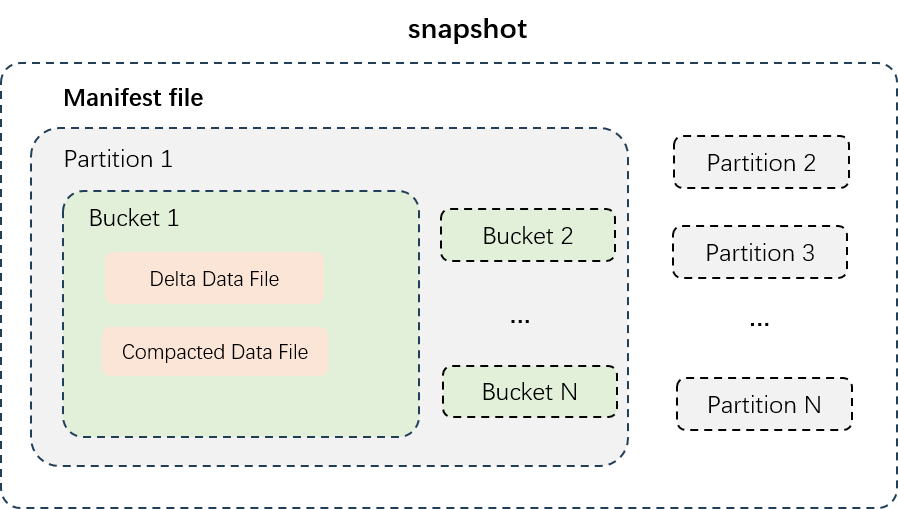
上図はパーティションテーブルのデータ構造を示しています。データファイルはパーティション単位で物理的に分離され (別ディレクトリに格納)、各パーティションのデータはバケットに分割されます。Delta テーブルは次の 2 種類のデータファイルを使用します。
| ファイルタイプ | 説明 | ストレージフォーマット | 最適な用途 |
|---|---|---|---|
| Delta データファイル | 各トランザクション書き込みまたは小ファイルマージ後に生成される増分データです。ニアリアルタイムの読み取り・書き込みをサポートするために、すべての行の中間履歴データを格納します。 | 行指向 (Avro) | ニアリアルタイムの取り込み、最近のバージョン間でのタイムトラベル |
| コンパクト済みデータファイル | Delta ファイルのコンパクション後に生成されます。プライマリキーごとの最新レコードのみを保持し、中間履歴は保持しません。高速クエリ向けに最適化されています。 | 列指向 (AliORC) | 分析クエリ、高スループットのバッチ読み取り |
自動データガバナンスと最適化
課題:小ファイルの肥大化
Delta テーブルは数分単位でのニアリアルタイム増分データインポートをサポートします。多くのバケットを持つ高トラフィック書き込みシナリオでは、小規模な増分データファイルの数が急速に増加し、過剰なアクセスリクエスト、高コスト、低い I/O 効率を引き起こす可能性があります。大量の UPDATE および DELETE 操作は、多数の冗長な中間履歴レコードを生成することで、この問題をさらに悪化させます。
解決策:4 つの自動ガバナンスサービス
MaxCompute ストレージエンジンは、手動設定なしで格納データを自動的にガバナンス・最適化します。ストレージエンジンは複数のディメンションでデータ特性をスマートに識別し、ポリシーを自動適用します。
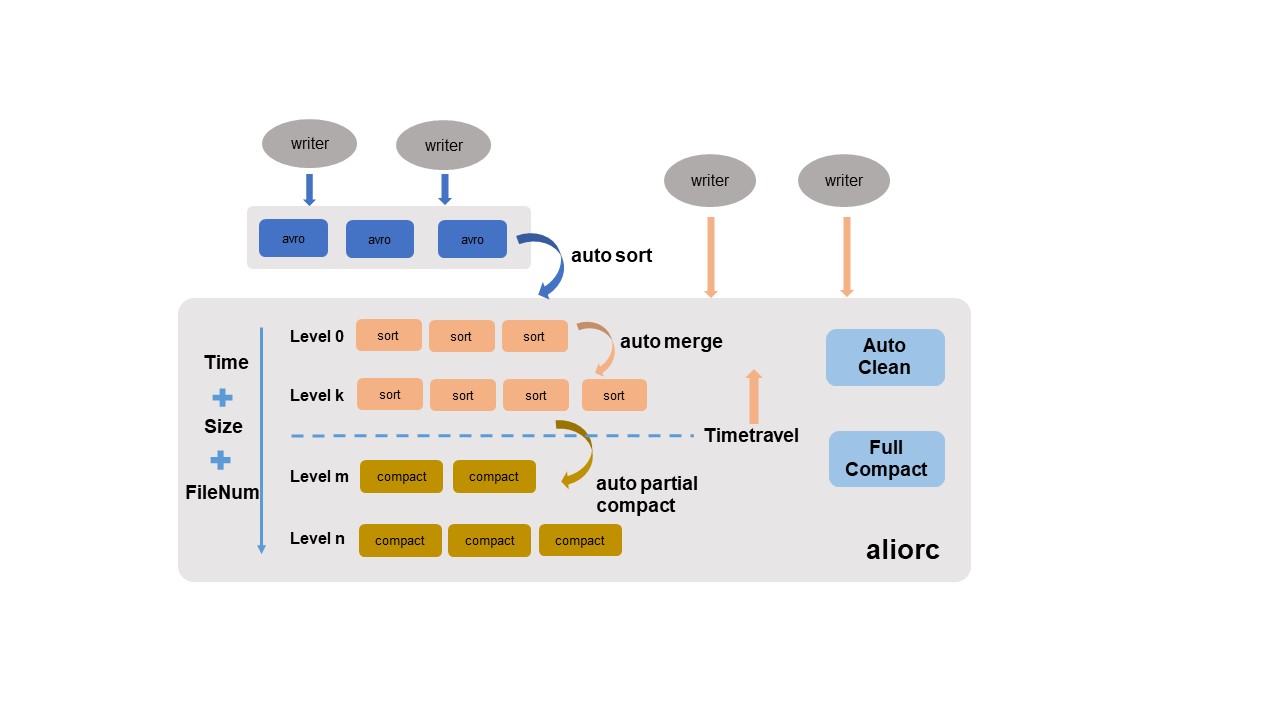
| サービス | 機能 |
|---|---|
| Auto sort | リアルタイムで書き込まれた行指向 Avro ファイルを列指向 AliORC ファイルに変換します。これにより、ストレージコストを削減し、読み取りパフォーマンスを向上させます。 |
| Auto merge | ファイルサイズ、数量、書き込み時系列を分析し、レベル別に小ファイルを定期的にマージします。タイムトラベルの整合性を維持するために、中間履歴データは保持されます。 |
| Auto partial compact | タイムトラベル保持期間外の履歴レコードをマージしてクリアします。これにより、大量の UPDATE/DELETE ワークロードによるストレージコストを削減し、読み取り効率を向上させます。 |
| Auto clean | Auto sort、Auto merge、または Auto partial compact によって新しい置き換えファイルが生成された後、元のファイルを削除します。これにより、ストレージスペースをリアルタイムで解放します。 |
Auto partial compact は、タイムトラベル保持期間を超えて作成された履歴レコードのみをクリアします。
ピーク時のクエリパフォーマンスが必要なシナリオでは、手動でメジャーコンパクションをトリガーします。
SET odps.merge.task.mode=service;
ALTER TABLE tt2 compact major;メジャーコンパクションは、各バケット内のすべてのデータを統合し、すべての履歴データをクリアして列指向 AliORC ファイルを生成します。これには追加の実行オーバーヘッドがかかり、新規ファイルのストレージコストが増加します。必要な場合にのみ使用してください。
詳細については、「COMPACTION」をご参照ください。
データ書き込み
数分単位のニアリアルタイムアップサート
Delta テーブルの利点: 従来のバッチ処理では、数時間~数日かけて増分データを新しいテーブルまたはパーティションにインポートし、オフライン ETL プロセスをトリガーして既存テーブルデータと結合・マージしていました。これには長い遅延と高いリソース・ストレージコストがかかります。
Delta テーブルでは、アップサートパイプラインがデータ書き込みからクエリまでの遅延を 5~10 分 に維持します。複雑な ETL マージプロセスが不要なため、コンピュートおよびストレージコストの両方が削減されます。
本番環境では、データベース、ログシステム、メッセージキューなど、さまざまなデータソースが一般的です。MaxCompute はオープンソースのFlink コネクタプラグインを提供しており、DataWorks Data Integration や他のデータインポートツールと連携します。これにより、高い同時実行性、フォールトトレランス、トランザクションコミットシナリオ向けにカスタム設計・開発最適化が可能です。
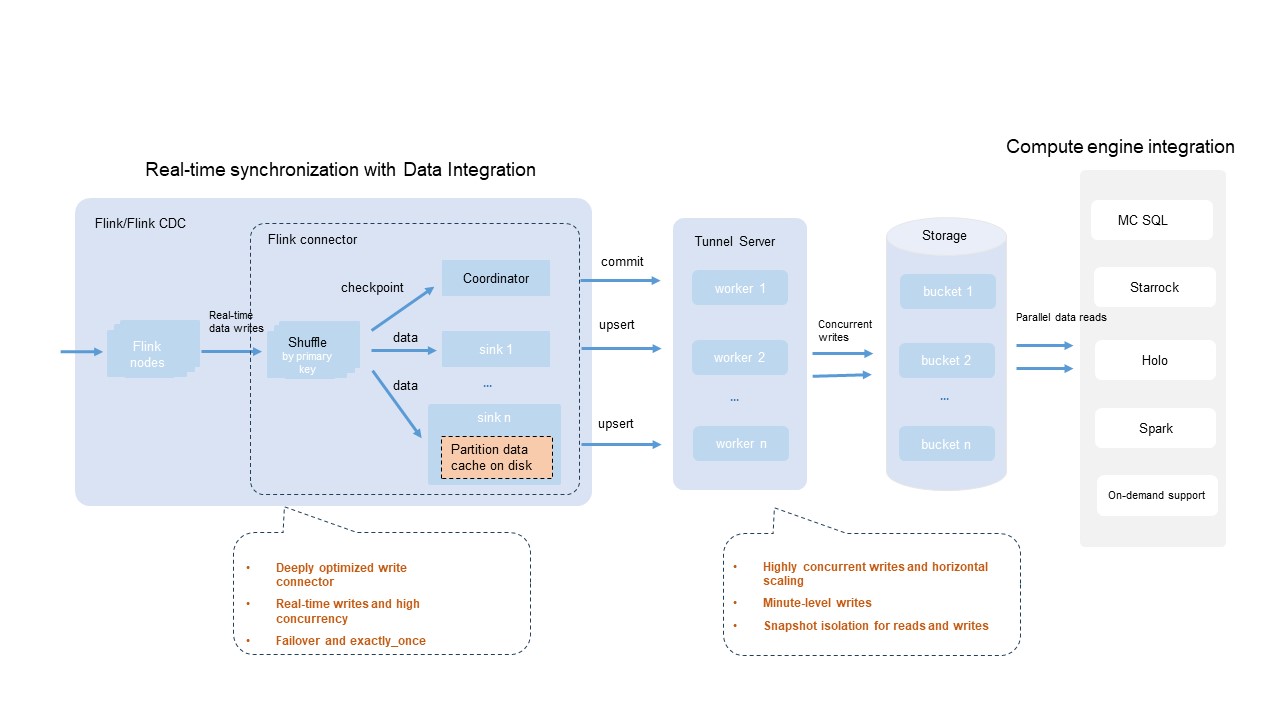
Flink コネクタ統合の主な機能:
| 機能 | 説明 |
|---|---|
| 広範なエンジン互換性 | Flink エコシステムと互換性のあるほとんどのコンピュートエンジンおよびツールは、MaxCompute Flink コネクタを使用した Flink デプロイメントをサポートし、Delta テーブルへのリアルタイムデータ書き込みが可能です。 |
| 設定可能な書き込み並列度 | write.bucket.num パラメーターを調整して書き込み並列度をチューニングできます。最適な書き込みパフォーマンスを得るには、write.bucket.num を Flink シンク並列度の整数倍に設定してください。 |
| 1 回限りのセマンティクス | 組み込みの Flink チェックポイントメカニズムを使用してフォールトトレランスを実現し、データ処理が 1 回限りのセマンティクスに従うことを保証します。 |
| 大規模パーティション書き込み | 数千のパーティションへの同時書き込みをサポートします。 |
| ニアリアルタイム可視性 | データは数分以内に可視化され、読み取り・書き込み操作に対してスナップショット隔離が提供されます。 |
トラフィックスループットは環境および構成によって異なります。単一バケットの処理能力 (1 MB/s) を基に最大スループットを推定してください。MaxCompute Tunnel ではデフォルトで共有 Tunnel リソースグループが使用されるため、リソース競合が激しい状況ではスループットが不安定になる可能性があります。また、リソース消費には制限が設けられています。
DataWorks Data Integration を使用したデータベースからのリアルタイムデータ同期
多くの本番システムでは、オンライントランザクション処理 (OLTP)、オンライン分析処理 (OLAP)、オフライン分析エンジンが組み合わされています。一般的なワークフローとして、単一テーブルまたはデータベース全体の新規レコードをリアルタイムで MaxCompute に同期し、分析に使用します。
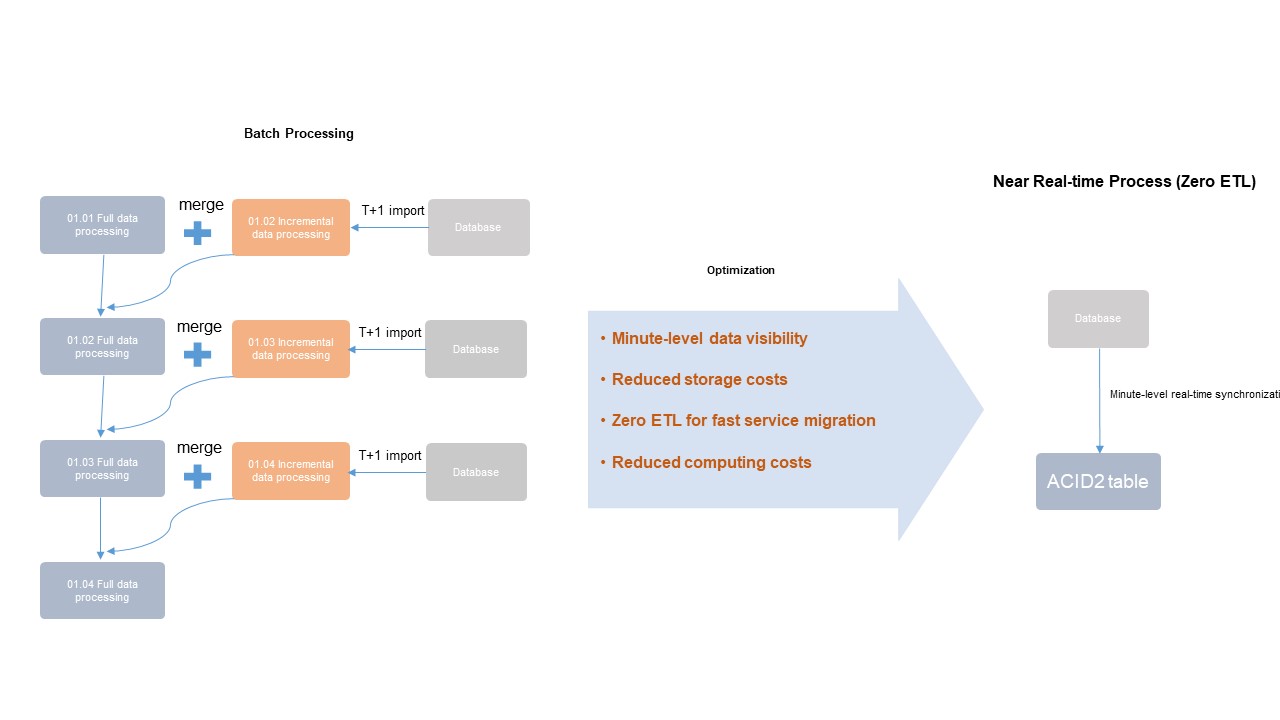
上図は 2 つのアプローチを比較しています。
-
左 (バッチ処理): 増分データは数時間~数日かけて新しいテーブルまたはパーティションにインポートされます。その後、オフライン ETL プロセスで増分データと既存テーブルデータを結合・マージします。これには高い遅延と高いリソース・ストレージコストがかかります。
-
右 (統合アーキテクチャ): 新規レコードは数分単位でデータベースから読み取られます。定期的なデータ抽出やマージは不要で、Delta テーブルが直接更新を処理するため、コンピュートおよびストレージコストを最小限に抑えます。
SQL DML ステートメントとアップサートによるバッチ処理
SQL エンジンの Compiler、Optimizer、Runtime モジュールは、Delta テーブル操作向けに修正・最適化されています。これには、構文解析、最適化プラン、プライマリキーに基づく重複排除ロジック、ランタイムアップサートが含まれ、完全な SQL 構文サポートを実現します。
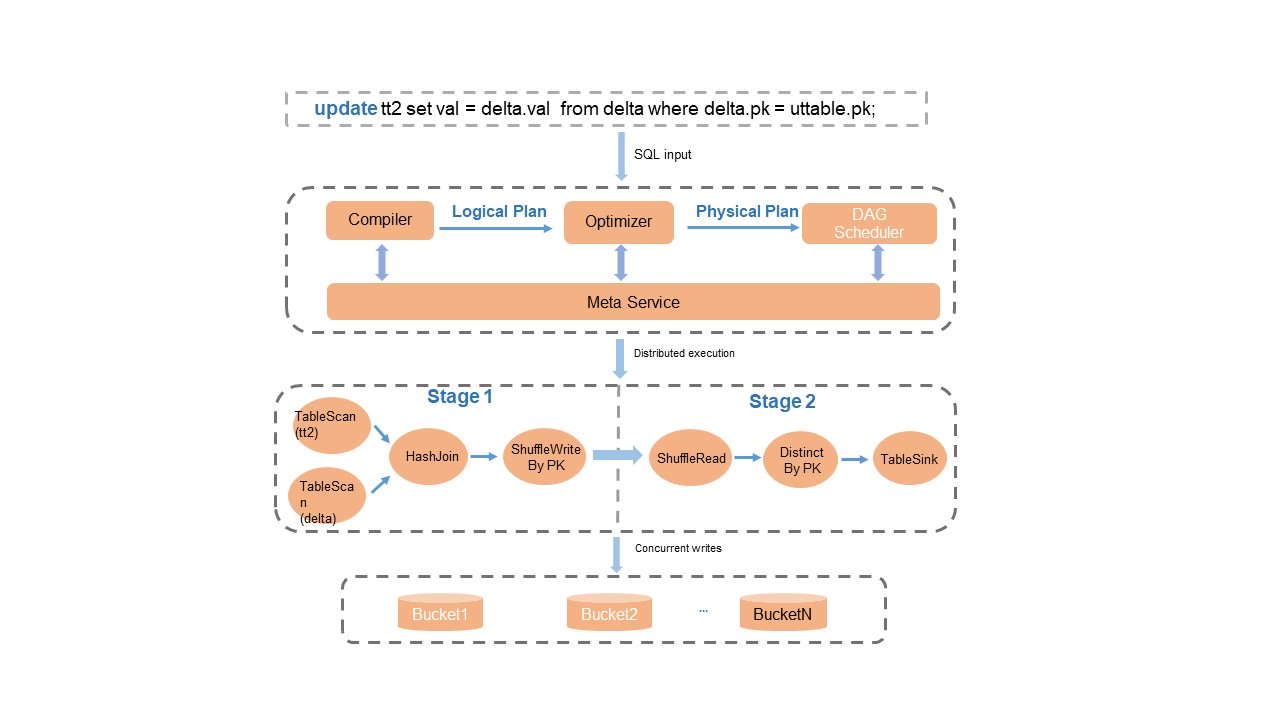
主な動作:
-
トランザクション一貫性: データ処理完了後、メタデータサービスがトランザクション競合検出およびアトミックなメタデータ更新を実行し、読み取り・書き込み隔離およびトランザクション一貫性を保証します。
-
簡素化されたアップサート: Delta テーブルに対するクエリ時に、システムはプライマリキーに基づいて自動的にレコードをマージします。INSERT と UPDATE 操作を混在させるシナリオでは、複雑な
UPDATEまたはMERGE INTO構文の代わりにINSERT INTOを使用してください。これにより、読み取り I/O が削減され、コンピュートリソースが節約されます。
SQL DML 構文の詳細については、「DML 操作」をご参照ください。
データクエリ
タイムトラベルクエリ
タイムトラベルクエリを使用すると、Delta テーブルの履歴バージョンをクエリできます。主なユースケースは以下のとおりです。
-
データ復旧: 誤って変更または削除されたデータを、指定された履歴バージョンに復元します。
-
履歴バックトラッキング: 過去の時点のビジネスデータを監査または再分析します。
クエリ例:
-- 特定のタイムスタンプ時点の履歴データをクエリします。
SELECT * FROM tt2 TIMESTAMP AS OF '2024-04-01 01:00:00';
-- 現在時刻から 5 分前の履歴データをクエリします。
SELECT * FROM tt2 TIMESTAMP AS OF CURRENT_TIMESTAMP() - 300;
-- 最後のコミットの 1 つ前のコミット時点の履歴データをクエリします。
SELECT * FROM tt2 TIMESTAMP AS OF GET_LATEST_TIMESTAMP('tt2', 2);以下の図は、タイムトラベルクエリの動作を示しています。
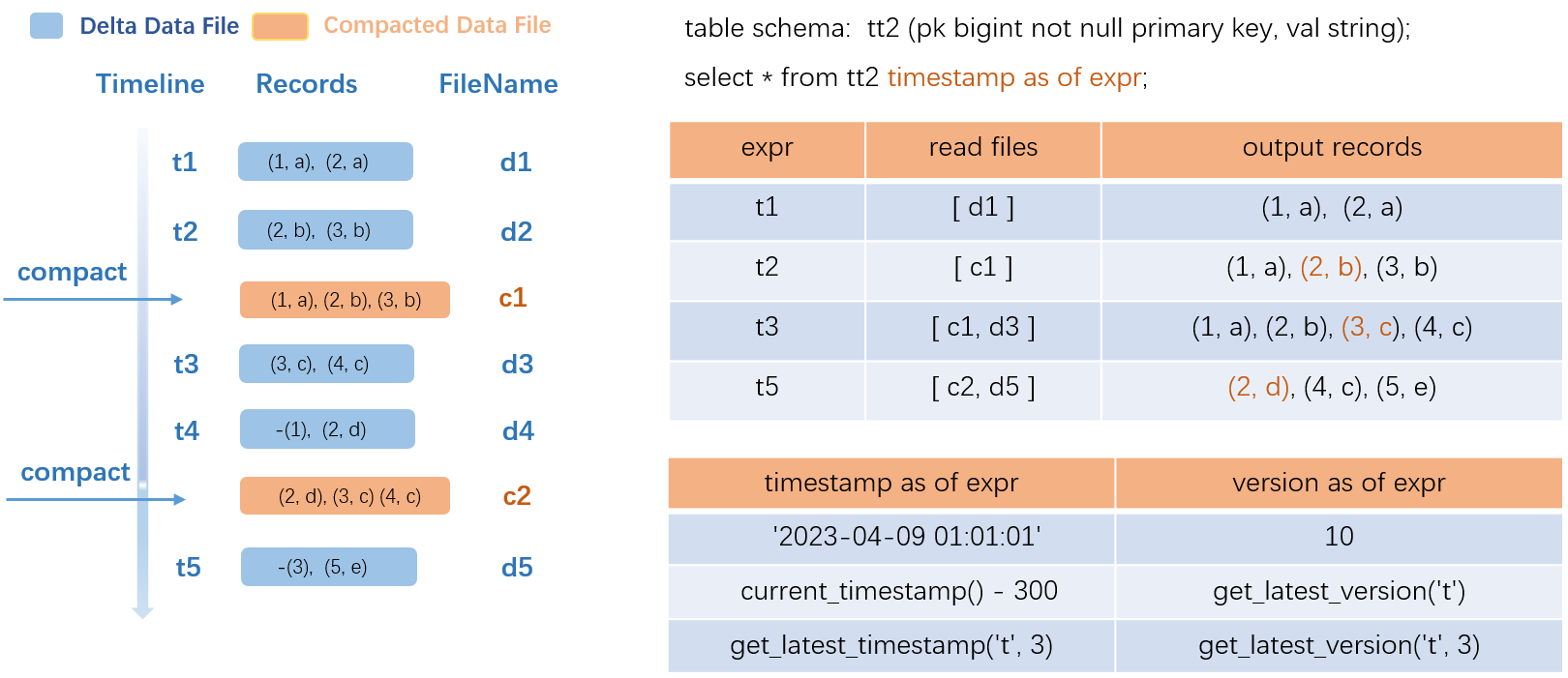
この例では、src という名前のトランザクションテーブルを使用しています。
-
左側 (データ更新プロセス): トランザクション t1~t5 がそれぞれ Delta データファイルを生成します。t2 および t4 で COMPACTION が実行され、コンパクト済みファイル c1 および c2 が生成されます。c1 では、中間履歴レコード
(2,a)が削除され、最新レコード(2,b)が保持されます。 -
クエリ解決: t1 時点の履歴データをクエリする場合、システムは Delta ファイル d1 のみを読み取ります。t2 時点をクエリする場合、コンパクト済みファイル c1 を読み取り、3 つのレコードを返します。t3 時点をクエリする場合、c1 と Delta ファイル d3 を読み取り、マージして出力します。COMPACTION を頻繁に実行するとクエリが高速化しますが、運用オーバーヘッドが増加します。要件に基づいてトリガーポリシーを選択してください。
SQL 構文では、定数、一般的な関数、および正確な履歴クエリのための TIMESTAMP AS OF expr 句および VERSION AS OF expr 句をサポートします。詳細については、「タイムトラベルクエリ」をご参照ください。
増分クエリ
MaxCompute は、Delta テーブル向けの増分クエリおよび増分計算を最適化するために、新しい SQL 増分クエリ構文を設計・開発しました。SQL 増分クエリ文を送信すると、MaxCompute エンジンはクエリ対象の履歴増分データバージョンを解析し、関連するコンパクト済みデータファイルを取得し、ファイルデータをマージして出力を返します。
以下の図は、増分クエリプロセスを示しています。

この例では、同じトランザクションテーブル src を使用し、トランザクション t1~t5 および t2 で生成されたコンパクト済みファイル c1、t4 で生成された c2 を想定しています。
-
beginが t1-1 でendが t1 の場合、システムは t1 の Delta ファイル d1 のみを読み取ります。 -
endが t2 の場合、システムは Delta ファイル d1 および d2 を読み取ります。 -
beginが t1 でendが t2-1 の場合、クエリ範囲は t1 から t2 に及びますが、この範囲内に増分データが存在しないため、空の行が返されます。
COMPACTION によって生成されたコンパクト済みファイル c1 および c2 のデータは、増分クエリ出力の新規データとは見なされません。
増分クエリ構文およびパラメーターの制限については、「タイムトラベルクエリと増分クエリ」の「増分クエリのパラメーターと制限事項」セクションをご参照ください。
プライマリキーに基づく最適化されたデータスキッピング
Delta テーブルのデータ分散およびインデックスは、プライマリキー列の値に基づいて構築されています。プライマリキーでクエリすると、システムは複数レベルでフィルタリングを行い、読み取るデータ量を大幅に削減します。これにより、クエリ効率が数百~数千倍向上します。
例: Delta テーブルに 1 億レコードが含まれている場合、単一のプライマリキー値でフィルタリングすると、読み取りが必要なレコード数は約 1 万件にまで減少する可能性があります。
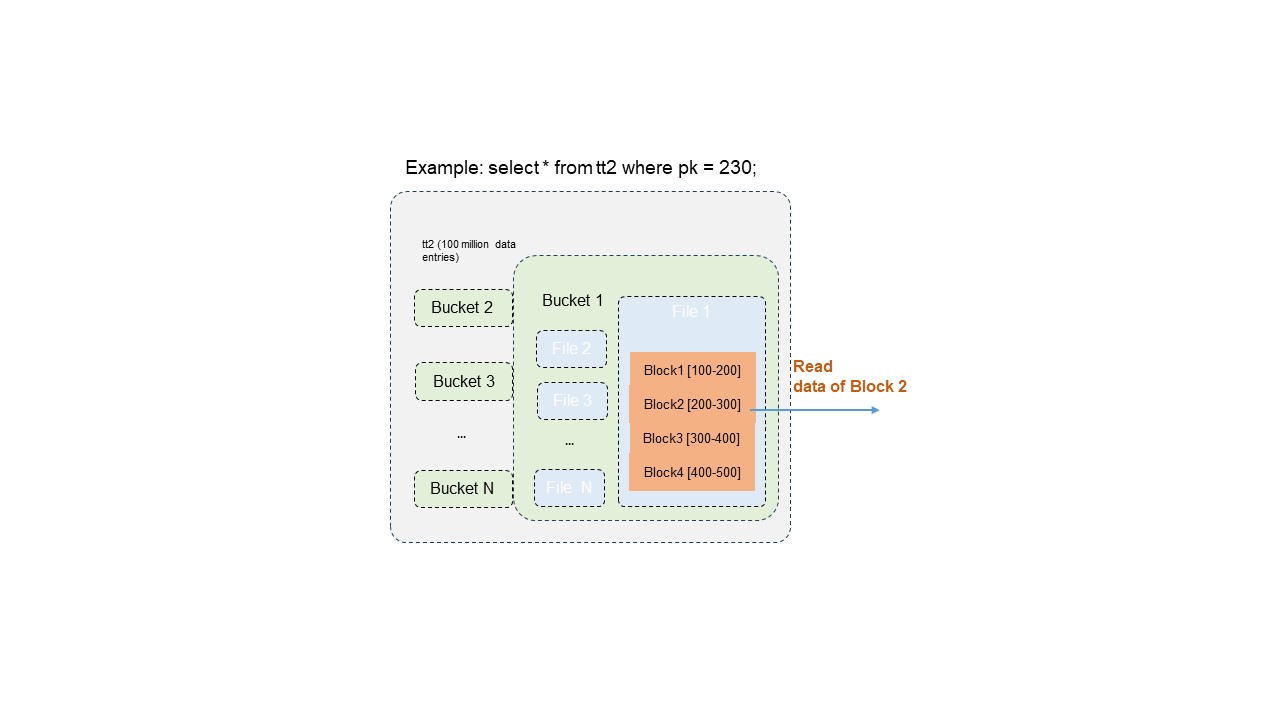
3 段階のフィルタリングプロセス:
-
バケットプルーニング: 対象プライマリキーを含むバケットを特定し、他のすべてのバケットのスキャンを省略します。
-
データファイルプルーニング: 対象バケット内で、プライマリキー値を含むデータファイルのみを特定します。
-
ブロックレベルの範囲フィルタリング: ファイルブロック内のプライマリキー値分布に基づいて正確なフィルタリングを適用し、対象値を含むブロックのみを抽出します。
最適化された SQL クエリと分析プラン
Delta テーブルの各バケットには、プライマリキー値で一意かつソートされたデータが格納されています。SQL オプティマイザーはこれらの特性を活用して、高コストな操作を排除します。
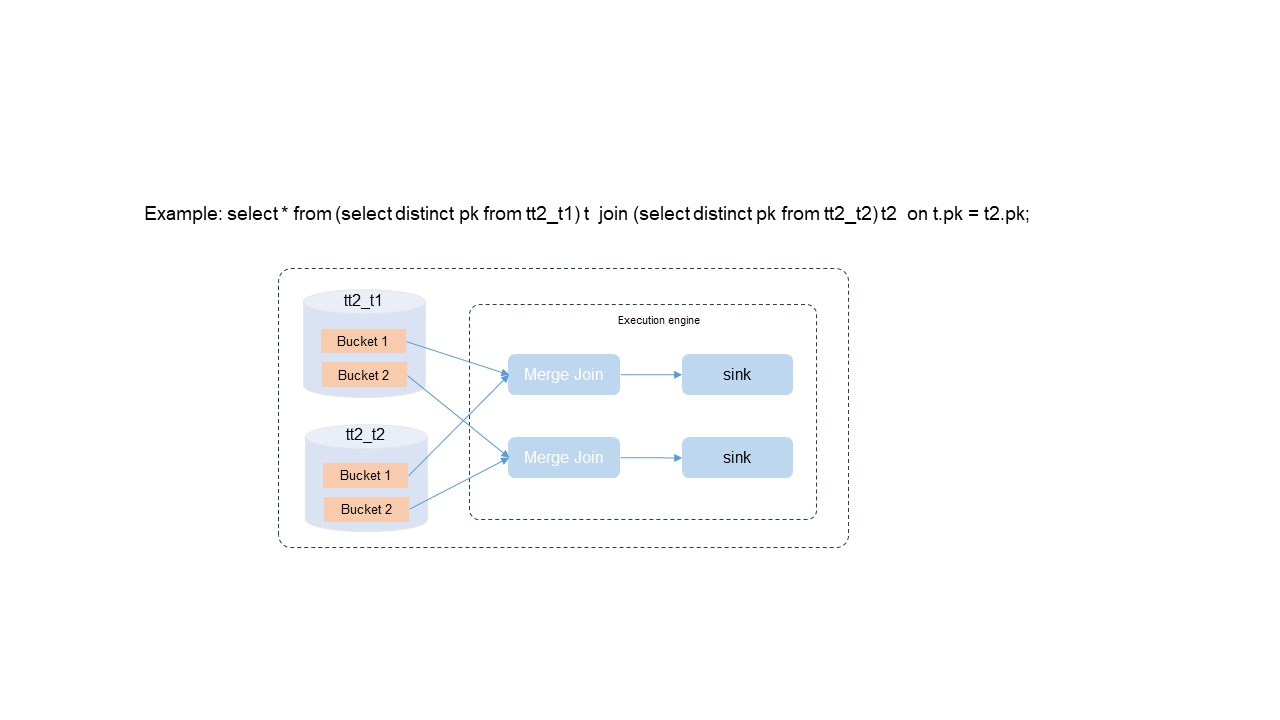
| 最適化 | 仕組み | メリット |
|---|---|---|
| DISTINCT の排除 | プライマリキーの一意性により重複が存在しないため、オプティマイザーは DISTINCT 操作を完全にスキップします。 | 不要なコンピュートオーバーヘッドを削減します。 |
| バケットローカル結合 | 結合キーがプライマリキーと一致する場合、オプティマイザーはグローバルシャッフリングではなくバケットローカル結合ポリシーを選択します。 | ノード間の大規模データ交換を削減し、リソース消費を抑え、スループットを向上させます。 |
| ソート不要のマージ結合 | 各バケットのデータはすでにプライマリキーでソートされています。オプティマイザーは事前ソートの代わりにマージ結合アルゴリズムを使用します。 | 計算を簡素化し、コンピュートリソースを節約します。 |
DISTINCT、ソート、グローバルシャッフリングを排除することで、クエリパフォーマンスが 100% 向上します。