このトピックでは、ニアリアルタイム データウェアハウス ソリューションで対処できるビジネス上の課題とその主なアーキテクチャ上の特徴について説明します。
背景情報
データ処理のシナリオが複雑になるにつれて、更新されたデータの秒単位での表示や行レベルの更新は、多くのビジネス シナリオでは必要ありません。代わりに、分単位または時間単位のニアリアルタイム データ処理と大量データのバッチ処理が必要になります。MaxCompute は、ニアリアルタイムでの完全データと増分データのストレージと処理に関するビジネス要件を満たすために、Delta テーブルを提供します。
現状分析
大量のデータをバッチ処理する必要がある、適時性の低いビジネス シナリオでは、MaxCompute を使用してビジネス要件を満たすことができます。秒単位のリアルタイム データ処理またはストリーミング処理が必要な、適時性の高いビジネス シナリオでは、リアルタイム データ処理システムまたはストリーミング システムを使用してビジネス要件を満たす必要があります。分単位または時間単位のニアリアルタイム データ処理と大量データのバッチ処理の組み合わせなど、包括的なビジネス シナリオでは、単一のエンジンを使用するか、複数の連携エンジンを使用するかに関係なく、特定の問題が発生する可能性があります。

前の図に示すように、特定のシナリオでバッチ処理に MaxCompute のみを使用すると、特定の問題が発生する可能性があります。たとえば、ユーザーの分単位の増分データと完全データを継続的にマージして保存する必要があるシナリオで MaxCompute を使用すると、追加の計算コストとストレージ コストが発生します。複雑なデータ処理リンクと処理ロジックを T+1 日以内のデータのバッチ処理に変換する必要があるシナリオで MaxCompute を使用すると、データ処理リンクの複雑さが増し、適時性がビジネス要件を満たせなくなります。上記のシナリオでリアルタイム データ処理システムのみを使用すると、リソース コストが高くなり、費用対効果が低くなり、大規模データのバッチ処理が不安定になります。ほとんどの場合、Lambda アーキテクチャがソリューションとして使用されます。Lambda アーキテクチャでは、完全データのバッチ処理に MaxCompute が使用され、増分データ処理にはリアルタイム データ処理システムが使用されて、高い適時性の要件が満たされます。ただし、Lambda アーキテクチャでは、複数の処理セットとストレージ エンジン間のデータの不整合、複数のデータ コピーの冗長ストレージと計算による追加コスト、複雑なアーキテクチャ、長い開発サイクルなど、既知の問題が発生する可能性があります。
上記の課題に対処するために、ビッグデータ オープンソース エコシステムは近年、さまざまなソリューションを立ち上げました。最も一般的なソリューションは、オープンソース データ処理エンジン Spark、Flink、または Presto をオープンソース データレイク Hudi、Delta Lake、Iceberg と緊密に統合して、統合コンピューティング エンジンとデータ ストレージを実装することです。このソリューションは、Lambda アーキテクチャによって発生する一連の問題を解決するのに役立ちます。MaxCompute のアーキテクチャに基づいて、増分データ ストレージおよび処理アーキテクチャが開発されています。このアーキテクチャは、バッチ データ処理とニアリアルタイムの増分データ処理のための統合ソリューションを提供します。このアーキテクチャは、バッチ処理の費用対効果を維持し、分単位の増分データの読み取り、書き込み、および処理に関するビジネス要件を満たします。また、このアーキテクチャは、UPSERT 操作やタイムトラベル機能などの実用的な機能を提供して、ビジネス シナリオを拡張することもできます。これにより、データの計算、ストレージ、および移行のコストを削減し、ユーザー エクスペリエンスを向上させることができます。
MaxCompute ニアリアルタイム アーキテクチャ
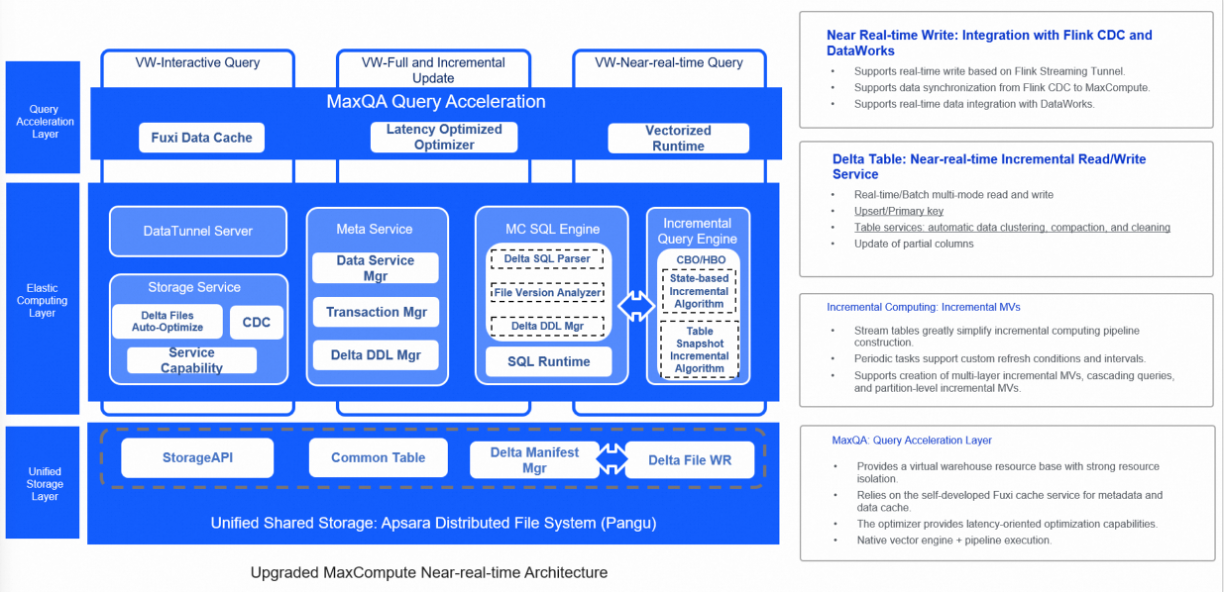
上の図は、MaxCompute が上記の包括的なビジネス シナリオを効率的にサポートする新しいアーキテクチャを示しています。新しいアーキテクチャでは、MaxCompute はさまざまなデータソースをサポートしており、カスタマイズされたアクセス ツールを使用して、増分データと完全データを統合ストレージ システムに簡単にインポートできます。バックグラウンド データ管理サービスは、データ ストレージ構造を自動的に最適化します。統合コンピューティング エンジンを使用して、ニアリアルタイムの増分データ処理と大規模データのバッチ処理をサポートします。統合メタデータ サービスを使用して、トランザクション管理とファイル メタデータ管理をサポートします。新しいアーキテクチャには、バッチ処理システムのみを使用した場合に発生する問題(冗長な計算とストレージ、低い適時性など)の解決、リアルタイム データ処理システムまたはストリーミング システムの高いリソース消費の防止、Lambda アーキテクチャにおける複数のシステム セット間のデータの不整合の解消、複数のデータ コピーの冗長ストレージ コストとシステム間のデータ移行コストの削減など、複数の利点があります。
エンドツーエンドの統合アーキテクチャは、増分データ処理と分単位の適時性の計算とストレージの最適化に関するビジネス要件を満たし、バッチ処理の全体的な効率を確保し、リソース コストを効果的に削減できます。
主な機能
MaxCompute ニアリアルタイム データウェアハウスは、主に 3 つの主要な機能を提供します。分単位のデータ インポートをサポートする MC Delta テーブル、レイテンシとスループットのバランスをより適切に保つ増分計算機能、そして秒単位のクエリ応答を可能にする新しくアップグレードされた MCQA2.0 です。
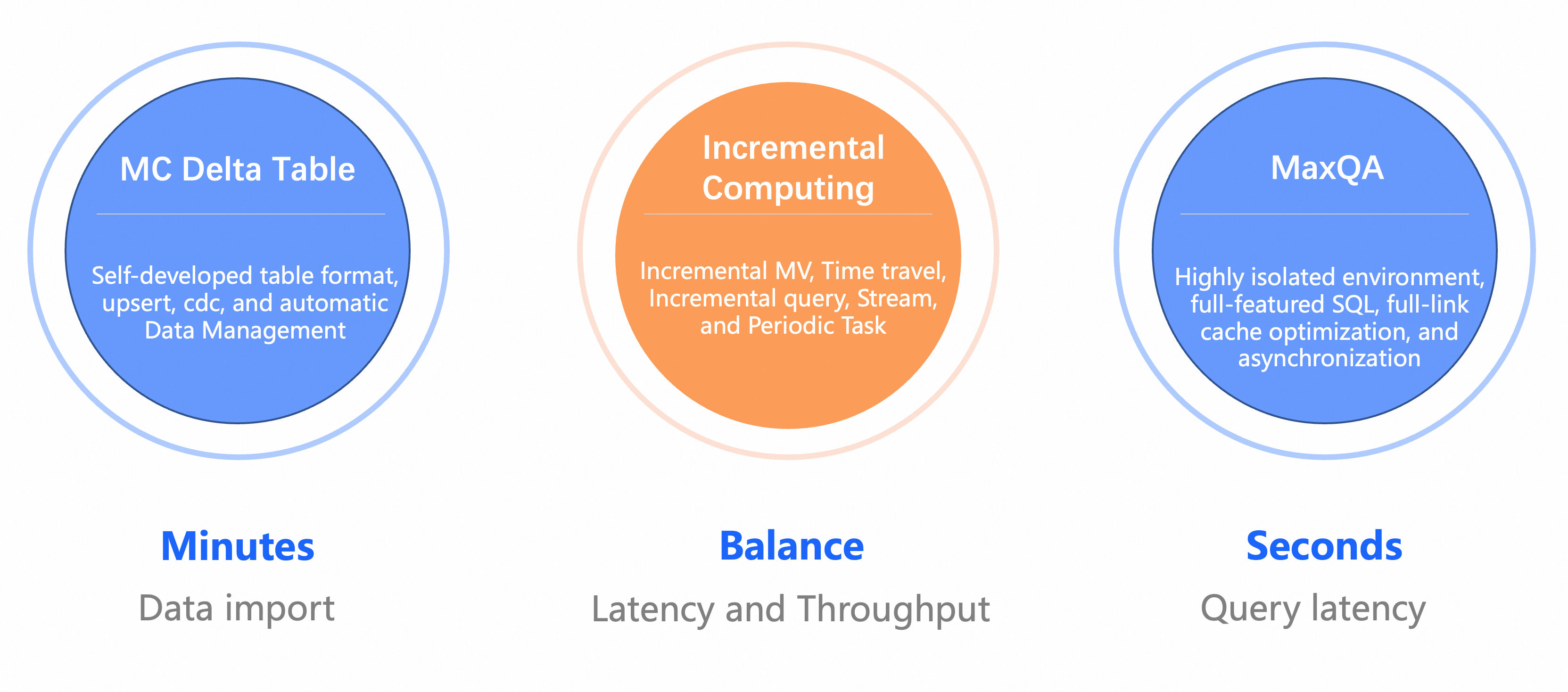
3 つの主要な機能は次のとおりです。
Delta テーブル形式:分単位のデータ インポートをサポートします。このテーブル形式は、AliORC を基盤となるファイル形式として使用し、UPSERT セマンティクスをサポートし、増分データの読み取りと書き込みのための標準 CDC(Change Data Capture)メソッドを提供します。自動データ管理のために、MaxCompute ストレージ サービスとグローバル メタサービスに依存しています。
増分計算:Delta テーブル形式に基づいて、MaxCompute は増分マテリアライズド ビュー、タイムトラベル、ストリーム テーブルなど、一連の増分計算機能を追加しました。さらに、増分マテリアライズド ビューと定期的にスケジュールされたタスクは、異なるトリガー頻度を提供し、ユーザーにレイテンシとスループットのバランスをとるためのより多くのオプションを提供します。
MCQA2.0 クエリ アクセラレーション:これは、MaxCompute クエリ アクセラレーションの完全なアップグレードです。厳密にフェンスで囲まれた環境を通じてパフォーマンスの安定性を向上させ、MCQA 1.0 の DQL SELECT クエリのみのサポートを DDL や DML を含む完全な SQL 機能に拡張します。ジョブ送信パイプラインの複数ステップの非同期処理などのエンドツーエンドのキャッシュと最適化手法を通じて、パフォーマンスがさらに向上します。
最も重要なことは、これらの新しい機能は MaxCompute の元の SQL エンジンに基づいて構築および実装されていることです。MaxCompute ユーザーは、開発習慣を変更することなく、より高い費用対効果で大規模なデータ分析を実行できます。
メリット
オープンソース データレイク Hudi および Iceberg のビジネス シナリオとビジネス移行をサポートするために、新しいアーキテクチャは特定の共通機能を提供します。独自に開発された新しいアーキテクチャは、機能、パフォーマンス、安定性、および統合の面でも次の利点を提供します。
ストレージ、メタデータ、およびコンピューティング エンジンの統合設計を提供して、エンジンの緊密かつ効率的な統合を実現します。新しいアーキテクチャは、低いストレージ コスト、効率的なデータ ファイル管理、高いクエリ効率などの利点を提供します。さらに、MaxCompute バッチ クエリ用の多数の最適化ルールを、タイムトラベルおよび増分クエリで再利用できます。
新しいアーキテクチャのすべての機能をサポートする完全な統合 SQL 構文セットを提供します。これはユーザー操作を容易にします。
さまざまな複雑なビジネス シナリオをサポートするために、詳細にカスタマイズおよび最適化されたデータ インポート ツールを提供します。
MaxCompute の既存のビジネス シナリオとシームレスに統合して、移行、ストレージ、および計算のコストを削減します。
データ ファイルの自動管理をサポートして、より優れた読み取りと書き込みの安定性を確保し、ストレージ効率とコストの自動最適化をサポートします。
MaxCompute で完全に管理されます。追加のアクセス コストなしで、新しいアーキテクチャをすぐに使用できます。新しいアーキテクチャの機能を使用するには、Delta テーブルを作成するだけです。
独自に開発されたアーキテクチャです。新しいアーキテクチャに基づいて、ビジネス要件に合わせてデータ開発を管理できます。