Lingma は、コード補完のためにナレッジベースに基づくコンテキスト分析を提供します。開発者が Lingma を使用すると、企業がアップロードしたコードリポジトリをコンテキストとして組み込みます。これにより、コード補完が企業のコーディング標準とビジネス特性により厳密に一致するようになります。このトピックでは、管理者向けの高品質な企業コードリポジトリを構築する方法について説明し、バックエンド開発者とフロントエンド開発者のためのベストプラクティスを提供します。
サポートされているエディションと言語
エディション | バックエンド | フロントエンド |
Enterprise Dedicated Edition | Java、C#、C/C++、Go、Python | JavaScript、TypeScript、Vue、React |
管理者向け: 高品質な企業コードリポジトリを構築する方法
開発者向け: コード補完のコンテキストとしてナレッジベースを使用する方法
バックエンドのシナリオ
コメントからコードへ
Lingma は、自然言語のコメントを使用してコードを生成できます。バックエンド開発のベストプラクティスを以下に示します。
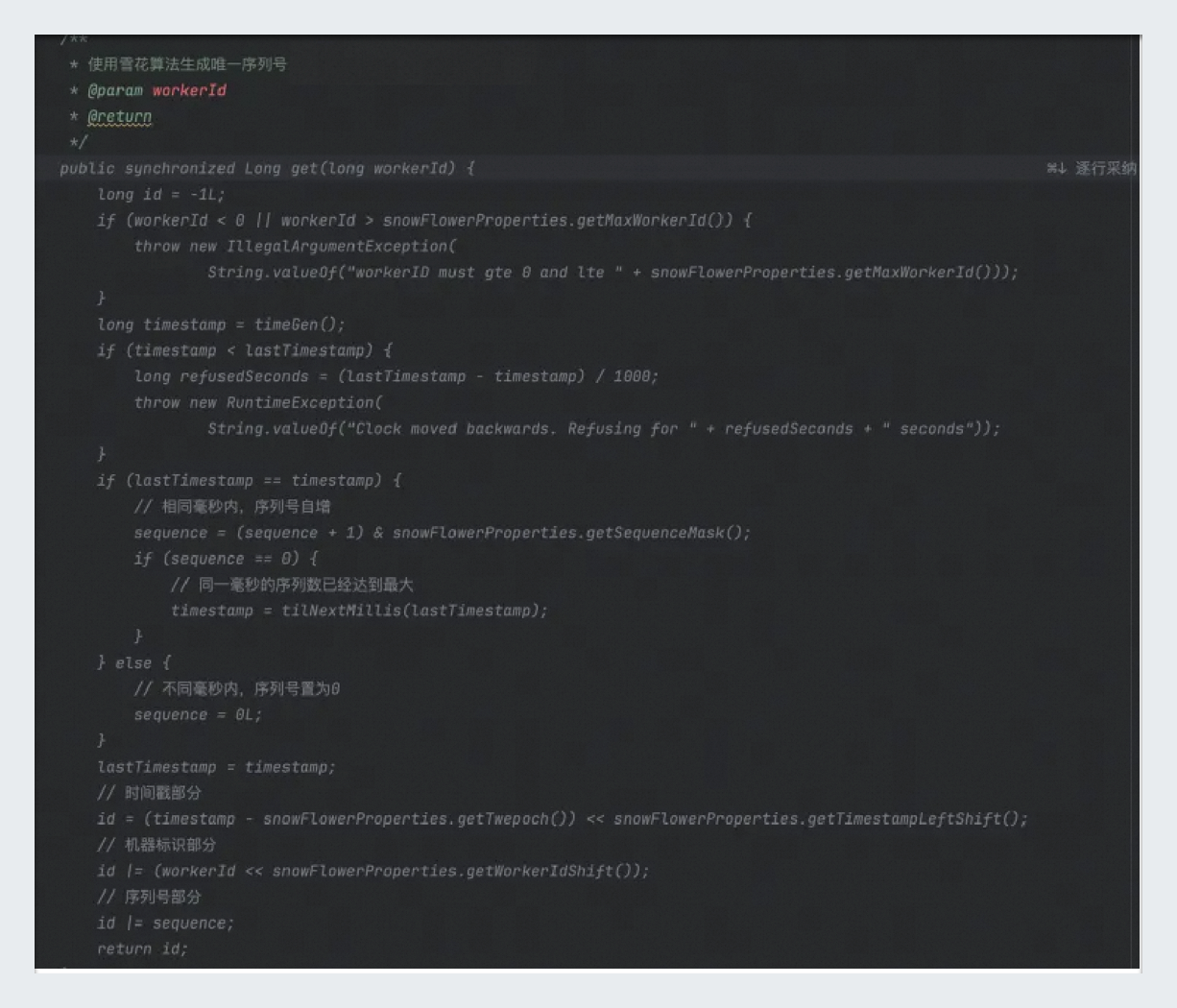
企業コードリポジトリにコードをアップロードする: 必要な機能コードを zip ファイルに入れて、コードリポジトリにアップロードします。関数がコメントの仕様に従っていることを確認します。関数の前にコメントを追加します。詳細については、「管理者向け: 高品質な企業コードリポジトリを構築する」を参照してください。Snowflake アルゴリズムのコメントを例にとります。
/** * Snowflake アルゴリズムを使用して一意の ID を生成します * @param workerId * @return */ public synchronized Long getSnowFlowerId(long workerId){ long id = -1L; if (workerId < 0 || workerId > snowFlowerProperties.getMaxWorkerId()) { throw new IllegalArgumentException( String.valueOf("workerID は 0 以上 " + snowFlowerProperties.getMaxWorkerId() + " 以下である必要があります")); } // アルゴリズム実装コード return id; }コメントを入力する: IDE で Java クラスを見つけ、呼び出す関数に一致するコメントを追加します。説明が明確で、スタイルが一貫していることを確認します。
スタイル 1
//Snowflake アルゴリズムを使用して一意の ID を生成し、生成された ID を返すコードを生成してくださいスタイル 2
/** * Snowflake アルゴリズムを使用して一意の ID を生成します * @param wId * @return */コメントの仕様:
コメントの長さ: コーディングするときは、短いコメントを使用しないでください。少なくとも 15 文字を目指してください。コメントが短すぎると、呼び出しがトリガーされません。
コメントの意味: コメントが明確で正確であることを確認します。Lingma がコードをより正確に理解できるように、キーワードと戻り値の説明を含めます。
多言語サポート: 英語と中国語の両方のコメントがサポートされています。リポジトリコメントで使用される言語は、コードで使用される言語と異なる場合があります。
パラメーター名: 柔軟なパラメーター名を使用できます。Lingma は、呼び出されたコードに一致するようにパラメーターを調整します。
悪い例を以下に示します。
//Snowflake アルゴリズム問題: コメントが短すぎて詳細が不十分です。//一意の ID を生成する問題: コメントにキーワードがなく、混乱を招く可能性があります。
コード生成: Enter キーを初めて押すと、Lingma はコメントに基づいてコードを提案します。もう一度押すと、Lingma は企業コードリポジトリを使用してコードを完成させます。
関数シグネチャを使用してコードを生成する
企業コードリポジトリにコードをアップロードします。
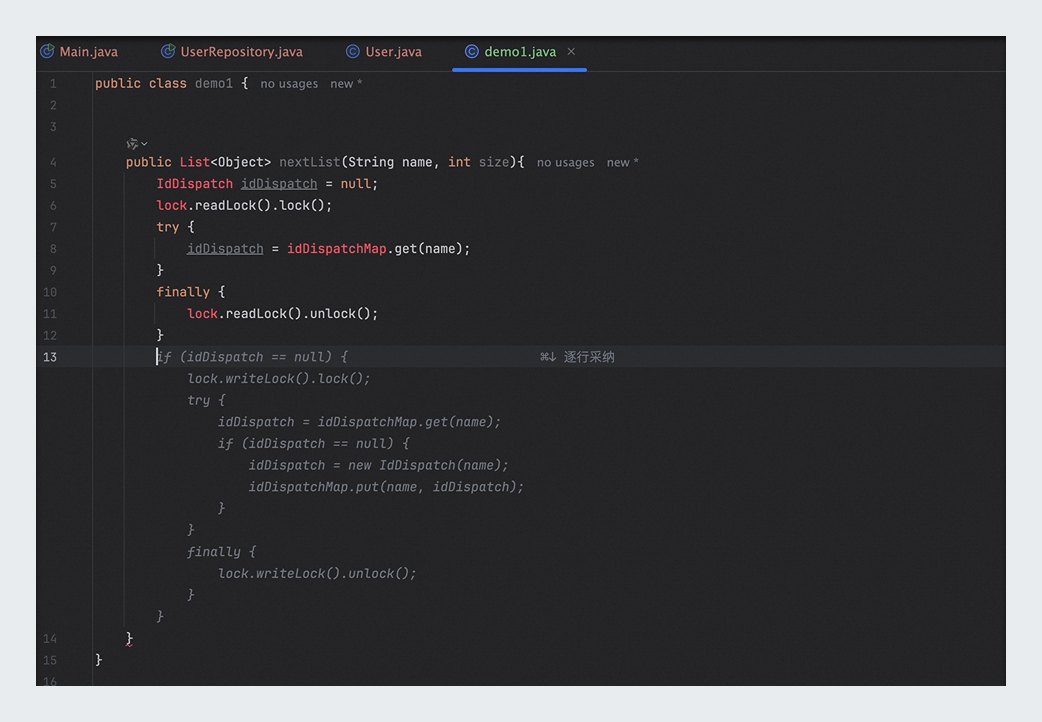
関数シグネチャを入力する: IDE で Java クラスを見つけ、関連する関数のシグネチャを入力します。柔軟なパラメーター名を使用できます。Lingma は、呼び出されたコードに一致するようにパラメーターを変更します。
public List nextList(String name, int size)関数シグネチャの説明:
関数名: 類似の意味を一致させるために、明確で意味のある関数名を使用します。
パラメーターと戻り値: 型と順序はターゲット関数と一致する必要がありますが、パラメーター名は変更できます。Lingma は、呼び出されたコードに一致するようにパラメーターを自動的に調整します。パラメーター名の悪い例を次に示します。
public List func1(String name, int size): 関数名が不明確で、関数を正確に反映していません。public List nextList(int orderId): パラメーター型と戻り値型がターゲット関数と一致しません。
コード補完: Enter キーを初めて押すと、Lingma はコード補完の提案を提供します。もう一度押すと、Lingma は企業コードリポジトリのコードに基づいてコードを自動的に完成させます。
フロントエンドのシナリオ
タグを使用してフロントエンドカスタムコンポーネントコードを完成させる
Lingma は、フロントエンドカスタムコンポーネントのタグを使用してコードを生成できます。ベストプラクティスを以下に示します。
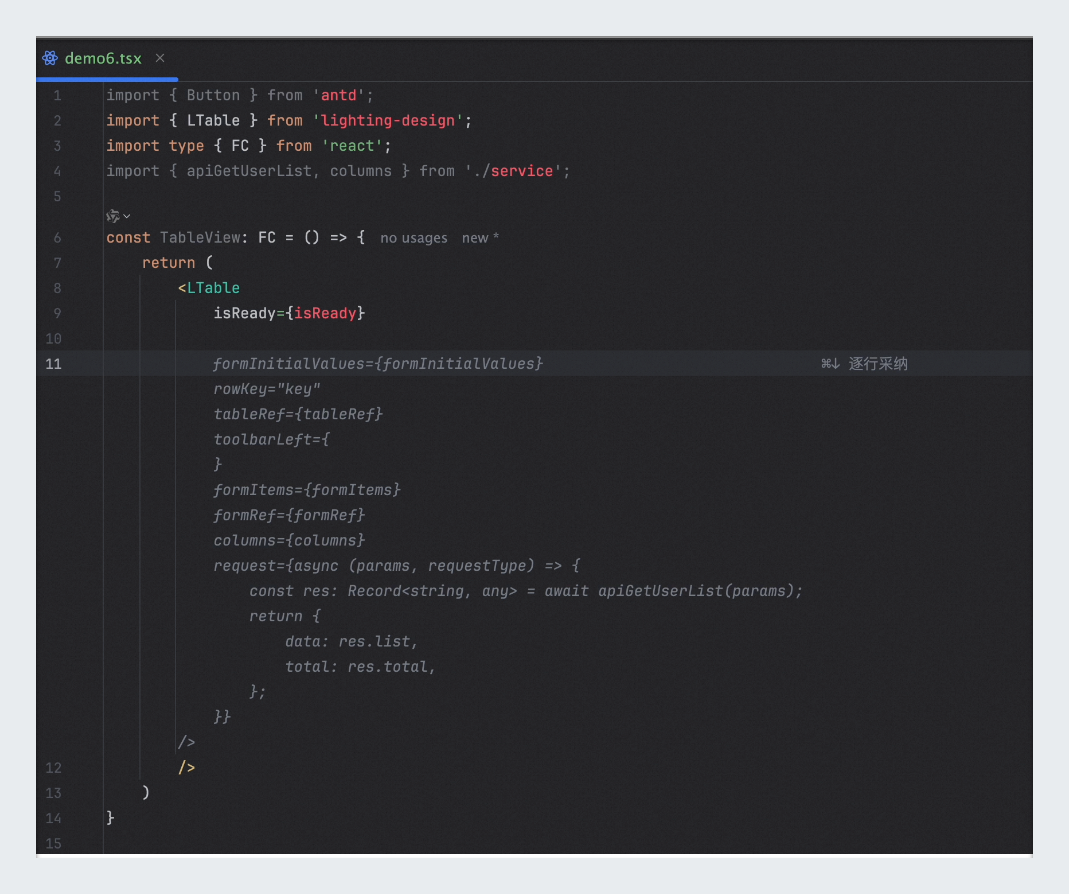
企業コードリポジトリにコードをアップロードする: 開始する前に、必要なフロントエンドコンポーネントのすべてのコードがコードリポジトリにアップロードされていることを確認します。React フレームワークの例を次に示します。
New } formItems={formItems} formRef={formRef} columns={columns} request={async (params, requestType) => { const res: Record = await apiGetUserList(params); return { data: res.data, total: res.total, }; }} />コンポーネントコードを記述する: IDE で
.jsxファイルを開き、コーディングを開始します。<LTable />などの基本的な HTML タグまたはカスタムコンポーネントタグを使用します。コード補完を有効にする: ライブラリで一致をトリガーするのに十分なコードを入力すると、IDE は完全なコンポーネントコードを生成します。[Enter] キーを押して、コードを手動で完成させることもできます。
 重要
重要完全なコンポーネントラベル内でコード補完をトリガーします。
コメントからコードへ
Lingma は、自然言語のコメントを使用してコードを生成できます。ベストプラクティスを以下に示します。
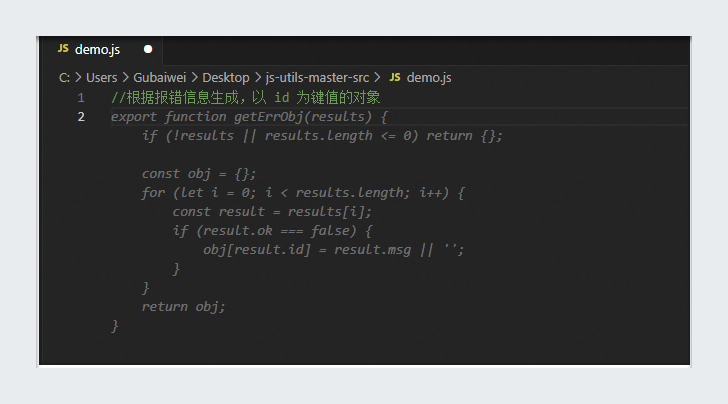
企業コードリポジトリにコードをアップロードする: 必要な機能コードを zip ファイルに入れて、コードリポジトリにアップロードします。関数がコメントの仕様に従っており、上部にコメントがあることを確認します。詳細については、「管理者向け: 高品質な企業コードリポジトリを構築する」を参照してください。例:
/** * エラーメッセージに基づいて、id をキー値とするオブジェクトを生成します * @param {Array} results * @return {Record} */ function getErrObj(results) { // 関数実装コード }コメントを入力する: IDE で必要な JavaScript ファイルを開き、コメントを追加します。例を次に示します。
//エラーメッセージに基づいて、id をキー値とするオブジェクトを生成しますコメントの仕様:
コメントの長さ: コーディングするときは、短いコメントを使用しないでください。少なくとも 15 文字を目指してください。コメントが短すぎると、呼び出しがトリガーされません。
コメントの意味: コメントが明確で正確であることを確認します。Lingma がコードをより正確に理解できるように、キーワードと戻り値の説明を含めます。
多言語サポート: 英語と中国語の両方のコメントがサポートされています。リポジトリコメントで使用される言語は、コードで使用される言語と異なる場合があります。
パラメーター名: 柔軟なパラメーター名を使用できます。Lingma は、呼び出されたコードに一致するようにパラメーターを調整します。
コード生成: Enter キーを初めて押すと、Lingma はコメントに基づいてコードを提案します。Enter キーをもう一度押すと、Lingma は企業コードリポジトリを使用してコードを完成させます。
コメントまたは関数シグネチャにパラメーターがある場合、Lingma は、命名の一貫性を確保するために、生成されたコードのパラメーター名を自動的に変更します。
最新のデータを取得するには、キャッシュをリフレッシュします。 macOS では
⌥(option)Pキーを、Windows ではAltPキーを押して、コード補完を手動でトリガーします。
FAQ: コードを呼び出せないのはなぜですか?
Lingma をインストールした後、コードの呼び出しに問題がある場合は、次の手順を実行します。
macOS: Lingma プロセスを再起動し、関連するキャッシュをクリアします。
ps -ef|grep lingma|grep start|awk '{print $2}'|xargs -I {} kill -9 {}Windows: [タスク マネージャー] で Lingma プロセスを終了します。