優れたテーブル設計は、LindormTSDB におけるクエリおよびストレージパフォーマンスの基盤となります。SQL を記述する前に、クエリパターンとデータソースの特性を分析してください。スキーマ作成時に下した決定は、後で元に戻すのが困難です。
このトピックでは、大気質モニタリング (AQM) データを実行例として使用し、各設計上の決定事項について説明します。
データモデルの概要
LindormTSDB の時系列データテーブルの各レコードは、次の 4 つのコンポーネントで構成されています。
| コンポーネント | 説明 |
|---|---|
| テーブル | 同じ型の時系列データのコレクション。メジャーメントにマッピングされます。たとえば、すべての AQM 測定値に対する aqm などです。 |
| タグ | 監視対象を識別する属性で、キーと値のペアとして保存されます。デフォルトでは、LindormTSDB はすべてのタグのキーと値のペアにインデックスを付け、タグを時系列にマッピングして高速なフィルタリングを実現します。一部のシステムでは、ラベルまたはディメンションとも呼ばれます。 |
| タイムスタンプ | レコードが生成された時刻。 |
| フィールド | 測定値。1 つのレコードに複数のフィールドを含めることができます。LindormTSDB はフィールドにインデックスを付けません。 |
次の図は、AQM データを使用してこれらのコンポーネントがどのように関連しているかを示しています。
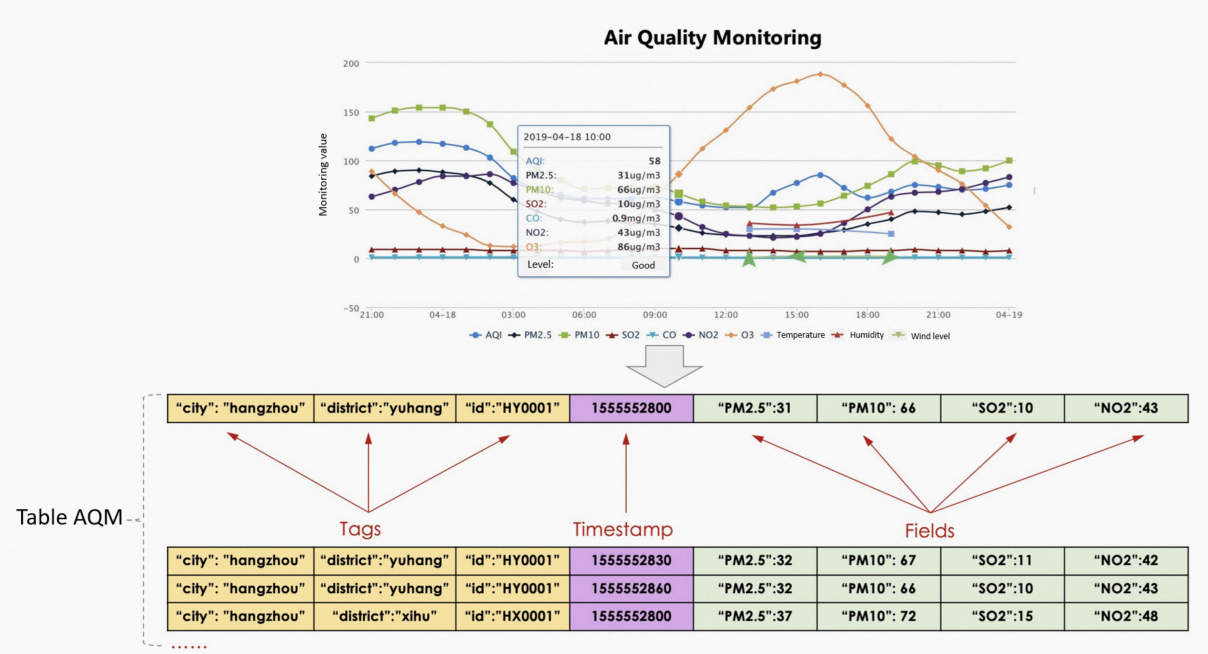
タグとして使用する列の決定
これは最も重要なスキーマ決定です。これを誤ると、時系列インデックスが際限なく増大し、書き込みおよびクエリパフォーマンスの両方が低下します。
タグは ID のため、フィールドは測定値のためです。
データのソースまたはコンテキスト (都市、デバイス ID、リージョン、ホストなど) を識別する場合は、列をタグとして定義します。
時間の経過とともに変化する測定値 (温度、CPU 使用率、PM2.5 濃度など) を保存する場合は、列をフィールドとして定義します。
チャーン率の高いタグの回避
プロセス ID や時間関連の属性など、値が頻繁に変化する属性は、データの型が STRING であってもタグとして使用しないでください。一意のタグのキーと値の組み合わせごとに、インデックスに新しい時系列エントリが作成されます。チャーン率の高い属性は、多数の異なる時系列を生成し、インデックスを急速に拡大させます。これにより、タグベースのルックアップに依存するクエリが遅くなります。
代わりに、チャーン率の高い属性をフィールドとして定義します。
テーブルの作成
テーブルには、それが表すメジャーメントの名前を付けます。CREATE TABLE 文で TAG キーワードを使用して、タグ列をマークします。TAG キーワードは LindormTSDB SQL 拡張です。TAG で宣言された列のみがプライマリキーとして使用できます。
次の例では、3 つのタグ列と 4 つのフィールド列を持つ AQM テーブルを作成します。
CREATE TABLE aqm (
city VARCHAR TAG,
district VARCHAR TAG,
id VARCHAR TAG,
time TIMESTAMP,
pm2_5 DOUBLE,
pm10 DOUBLE,
so2 DOUBLE,
no2 DOUBLE,
PRIMARY KEY (id) -- 単一ノードの Lindorm インスタンスではプライマリキーがサポートされていないため、この行を削除します。
);テーブルを作成した後、INSERT INTO を使用してレコードを挿入します。
INSERT INTO aqm (city, district, id, time, pm2_5, pm10, so2, no2)
VALUES ('hangzhou', 'yuhang', 'HY00001', '2019-04-18 10:00:00', 31.0, 66.0, 10.0, 43.0);
INSERT INTO aqm (city, district, id, time, pm2_5, pm10, so2, no2)
VALUES ('hangzhou', 'yuhang', 'HY00001', '2019-04-18 10:01:00', 31.2, 66.0, 10.5, 43.1);単一の文で複数のレコードを挿入するには、次のようにします。
INSERT INTO aqm (city, district, id, time, pm2_5, pm10, so2, no2)
VALUES
('hangzhou', 'yuhang', 'HY00001', '2019-04-18 10:02:00', 31.3, 66.0, 10.0, 42.9),
('hangzhou', 'yuhang', 'HY00001', '2019-04-18 10:03:00', 31.2, 66.4, 10.3, 43.0);プライマリキーの選択
LindormTSDB はプライマリキーを使用してデータをパーティション分割し、クエリを最適化します。WHERE 句にプライマリキーを含むクエリは、より高速に実行されます。
時系列データテーブルはリレーショナルデータベースのテーブルとは異なります。プライマリキー列に一意の値を含める必要はありません。プライマリキー列はタグ付けされている必要があります (TAG キーワードで宣言)。
単一ノードの Lindorm インスタンスはプライマリキーをサポートしていません。
データソースの一意の識別子をプライマリキーとして使用します。
| シナリオ | 推奨されるプライマリキー |
|---|---|
| IoT (モノのインターネット) / IIoT (産業用モノのインターネット) | デバイス ID |
| IoV (車のインターネット) | 車両の一意の識別子 |
| アプリケーションモニタリング | アプリ ID または host:port |
AQM の例では、id は各監視ステーションを一意に識別します。ほとんどのクエリがステーション ID でフィルタリングする場合、id をプライマリキーとして使用します。
PRIMARY KEY (id)データの型の選択
タグ列
タグ列は VARCHAR である必要があります。このデータの型は、テーブル作成後に変更することはできません。
タイムスタンプ列
LindormTSDB は、タイムスタンプを内部的に BIGINT 値として LindormDFS に UNIX エポック形式で保存し、タイムスタンプの圧縮を最適化します。テーブル作成時に、アプリケーションがタイムスタンプをどのように処理するかに基づいて列の型を選択します。
| 型 | 使用する状況 |
|---|---|
TIMESTAMP | アプリケーションが人間が判読可能な日時文字列を扱い、データベースに変換を自動的に処理させたい場合。 |
BIGINT | アプリケーションが UNIX エポック値を直接扱う場合、またはタイムスタンプに対して算術演算 (たとえば、持続時間の計算) を実行する場合。 |
フィールド列
フィールド列はすべてのデータの型をサポートしています。フィールド列に VARCHAR を使用することは避けてください。これは圧縮効率が悪く、数値型と比較してクエリを遅くします。
サポートされているデータの型の完全なリストについては、「データの型」をご参照ください。