LindormSearch では、クラスター管理システムを使用してコレクションを作成し、データを書き込み、クエリを実行し、コレクションを削除します。
基本概念
コレクション は LindormSearch のインデックステーブルであり、リレーショナルデータベースにおけるテーブルと概ね同等の概念です。各コレクションは分散ストレージのために 1 個以上の シャード に分割され、フォールトトレランスを確保するために各シャードには 1 個以上の レプリカ を設定できます。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
LindormSearch クラスター管理システムへのアクセス権限があること
少なくとも 1 個の LindormSearch ノードを含む Lindorm インスタンスが存在すること
コレクションの作成
LindormSearch 検索エンジンサービスが提供する クラスター管理システム にログインします。
左側のナビゲーションウィンドウで、[コレクション] をクリックします。
[コレクションの追加] をクリックします。
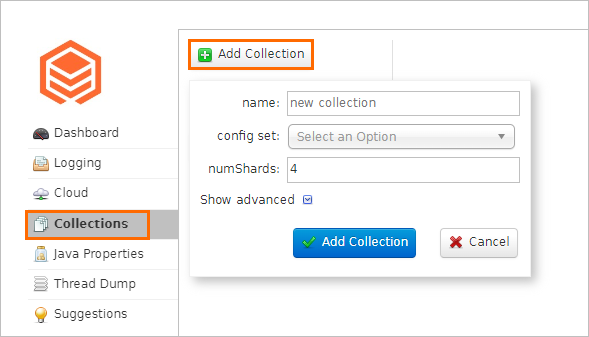
コレクションのパラメーターを設定します。以下の制約を満たす必要があります。違反した場合、コレクションの作成は失敗します。
パラメーター デフォルト 説明 [name] — コレクションの名前です。 config set _indexer_defaultコレクションの構成セットです。 [numShards] — シャード数です。LindormSearch ノード数の整数倍となるように設定してください。たとえば、ノード数が 2 の場合、[numShards] を 2または4に設定します。また、この値は [MaxShardsPerNode] より小さくなければなりません。[replicationFactor] 1各シャードのレプリカ数です。 maxShardsPerNode 1各ノード上のシャードの最大数です。 [autoAddReplica] — ノードが利用不可になった際に、他のノード上でシャードを復元するかどうかを指定します。 True(推奨)に設定すると、シャードの自動回復が有効になります。[maxShardsPerNode] × ノード数 ≥ [numShards] × [replicationFactor]ダイアログボックス内の [コレクションの追加] をクリックします。
データの書き込み
左側のナビゲーションウィンドウで、[コレクション選択] のドロップダウンリストから対象のコレクションを選択します。
[ドキュメント] をクリックして、データ書き込みページに移動します。
[ドキュメント種別] のドロップダウンリストから [CSV] を選択します。
[ドキュメント] フィールドにデータを入力します。次の例では 3 行のデータを書き込みます。
id,update_version_l,name_s,age_i 1,1,zhangsan,10 2,2,lisi,20 3,3,wangwu,30idおよびupdate_version_lの列は必須です。これらは LindormSearch が内部で使用するシステム定義列です。name_sの接尾辞_sは、その列が文字列(String)型であることを示し、age_iの接尾辞_iは、その列が整数(Integer)型であることを示します。
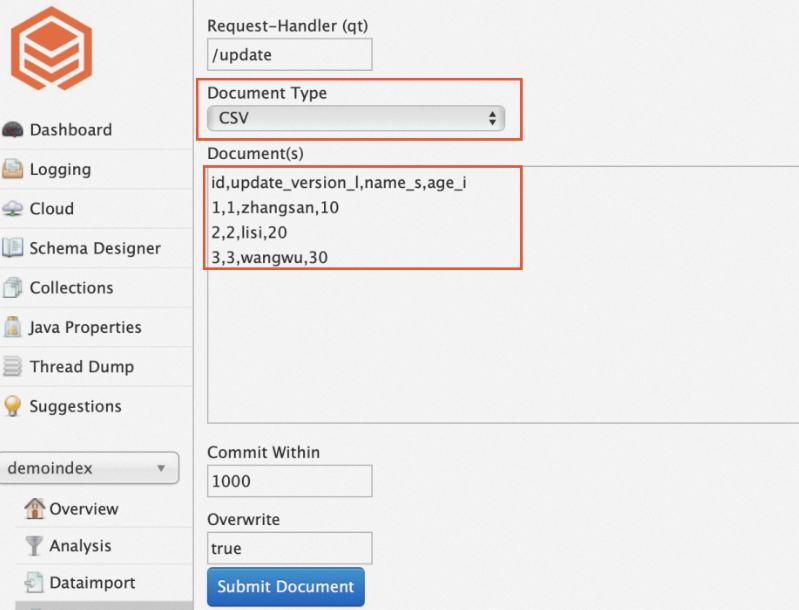
[ドキュメントの送信] をクリックします。
データのクエリ実行
左側のナビゲーションウィンドウで、[クエリ] をクリックします。
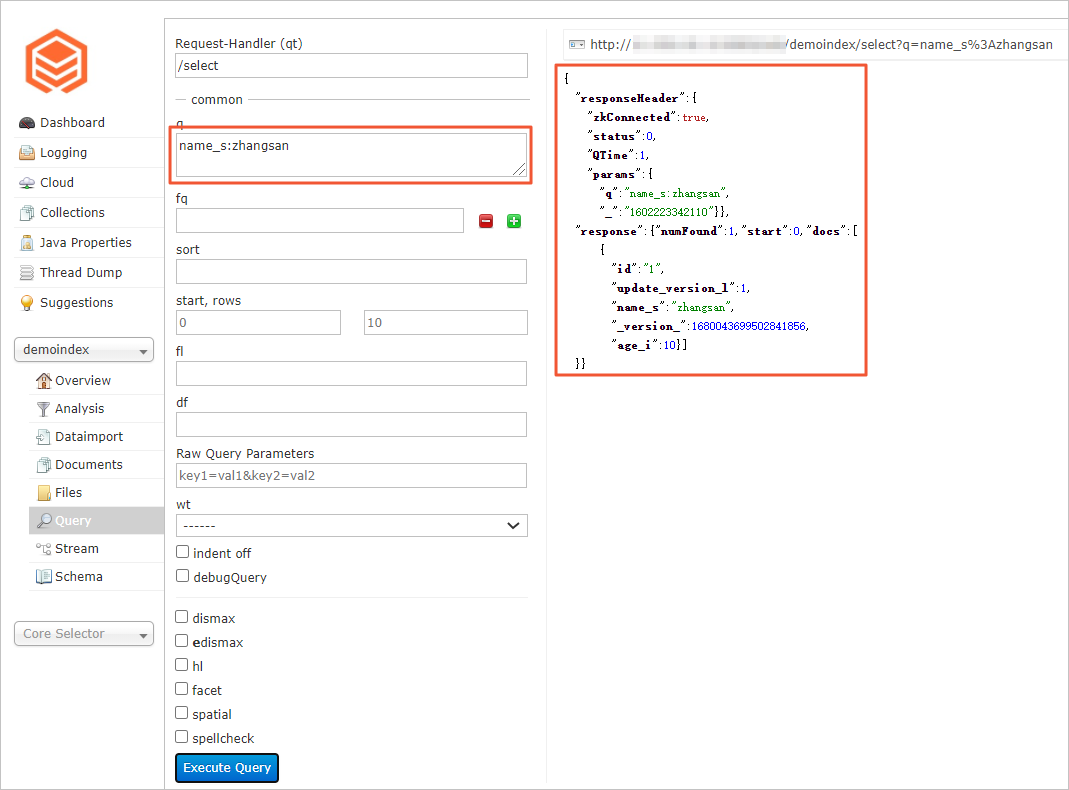
[q] フィールドにクエリ条件を入力します。
[クエリの実行] をクリックします。
コレクションの削除
左側のナビゲーションウィンドウで、[コレクション] をクリックします。
対象のコレクションを選択し、[削除] をクリックします。
[コレクション] テキストボックスに、削除を確認するためのコレクション名を入力します。
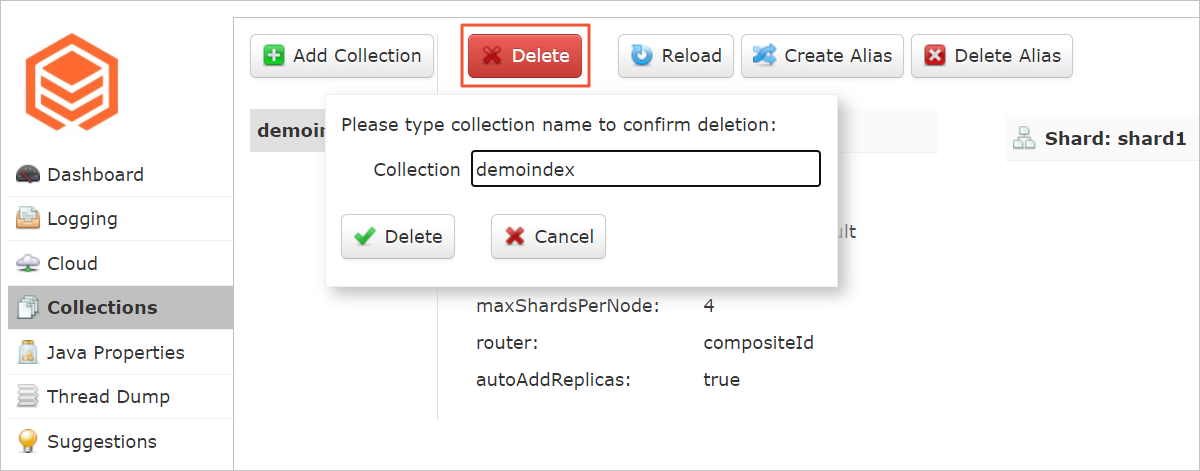
[削除] をクリックします。