時系列テーブルを使用すると、クエリパフォーマンスとストレージパフォーマンスを向上させることができます。このトピックでは、時系列データのソースと、時系列データが使用されるビジネスシナリオに基づいて、時系列テーブルを設計する方法について説明します。
時系列データのサンプル
モデリングは時系列データにとって重要です。適切なデータテーブルを作成するには、クエリシナリオとデータソースの特性を分析する必要があります。このようにして、最適なストレージとクエリパフォーマンスを得ることができます。次の図は例を示しています。この例では、大気質モニタリング(AQM)データが使用されています。
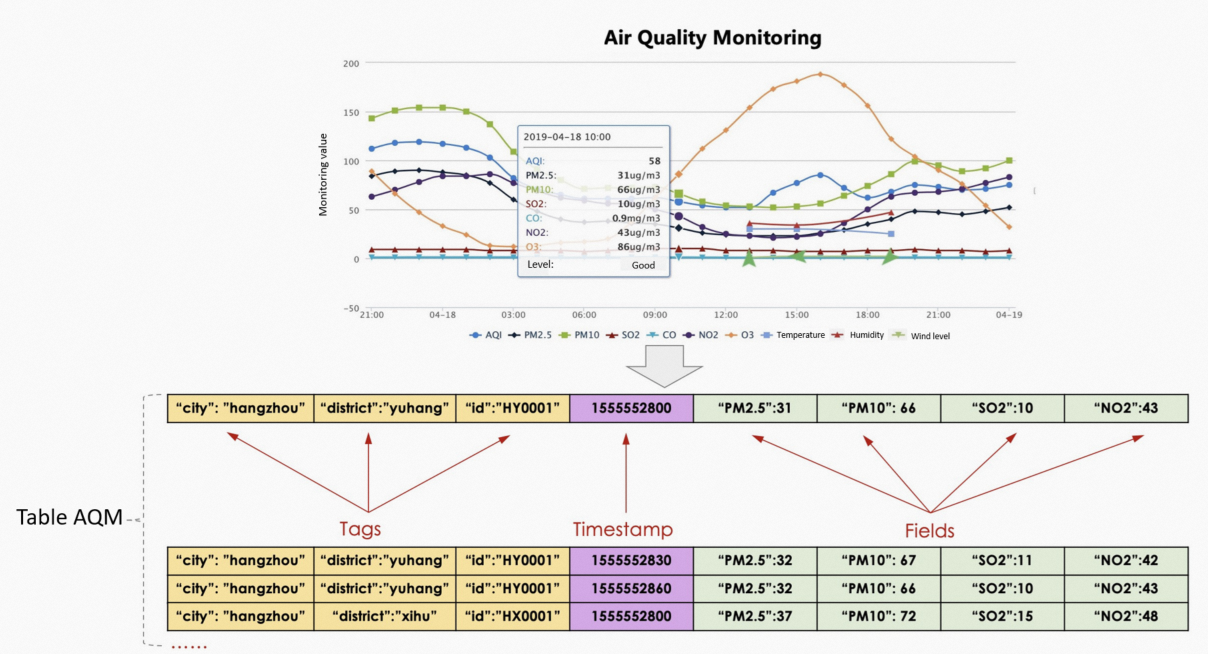
各時点で生成されるデータレコードは、次の部分に分割できます。
テーブル:同じタイプの時系列データのコレクションを示します。
タグ:メトリックが監視されるオブジェクトの属性を示します。タグは、タグキーとタグ値で構成されます。デフォルトでは、LindormTSDB は、各タグのキーと値のペアに対して、タグを時系列にマッピングするインデックスを作成します。特定のシナリオでは、タグはラベルまたはディメンションと呼ばれる場合があります。
タイムスタンプ:データレコードが生成された時刻を示します。
フィールド:メトリックの側面を示します。データレコードには、複数のフィールドの値を含めることができます。 LindormTSDB は、フィールドのインデックスを作成しません。
時系列テーブルを設計するためのベストプラクティス
上記のデータモデルに基づいて、同じタイプの時系列データの測定値をテーブル名として使用し、[CREATE TABLE] SQL ステートメントを実行してテーブルを設計できます。たとえば、前の図に示されている測定値 AQM をテーブル名として使用できます。
次のサンプルコードは、テーブルを定義する方法の例を示しています。この例では、上記の AQM 時系列モデルが使用されています。
CREATE TABLE aqm (
city VARCHAR TAG,
district VARCHAR TAG,
id VARCHAR TAG,
time TIMESTAMP,
pm2_5 DOUBLE,
pm10 DOUBLE,
so2 DOUBLE,
no2 DOUBLE,
PRIMARY KEY(id) // 単一ノードの Lindorm インスタンスはプライマリキーをサポートしていません。Lindorm インスタンスが単一ノードの Lindorm インスタンスの場合は、この行を削除してください。
);テーブルを定義した後、INSERT ステートメントを実行してテーブルにデータを書き込みます。
INSERT INTO aqm (city, district, id, time, pm2_5, pm10, so2, no2)
VALUES ('hangzhou', 'yuhang', 'HY00001', '2019-04-18 10:00:00', 31.0, 66.0, 10.0, 43.0);
INSERT INTO aqm (city, district, id, time, pm2_5, pm10, so2, no2)
VALUES ('hangzhou', 'yuhang', 'HY00001', '2019-04-18 10:01:00', 31.2, 66.0, 10.5, 43.1);また、次の INSERT ステートメントを実行して、一度に複数のレコードをテーブルに書き込むこともできます。
INSERT INTO aqm (city, district, id, time, pm2_5, pm10, so2, no2)
VALUES ('hangzhou', 'yuhang', 'HY00001', '2019-04-18 10:02:00', 31.3, 66.0, 10.0, 42.9),
('hangzhou', 'yuhang', 'HY00001', '2019-04-18 10:03:00', 31.2, 66.4, 10.3, 43.0);TAG キーワードは、SQL の構文拡張です。このキーワードは、テーブルの列をタグとして指定するために使用されます。時系列テーブルを作成する場合は、次のルールに基づいて列をタグとして定義することをお勧めします。
タグとして定義されている列が、データソースの属性を一意に識別できることを確認します。
値が頻繁に変更される属性をタグとして使用しないことをお勧めします。たとえば、プロセス ID や時間関連の属性をタグとして使用しないことをお勧めします。これらの属性のデータ型が STRING であっても、これらの属性をフィールドとして定義することをお勧めします。これらの属性がタグとして使用される場合、時系列の数が増加します。その結果、時系列インデックスのサイズが増加します。これはデータクエリに悪影響を及ぼします。
プライマリキーを設計するためのベストプラクティス
データベースは、プライマリキーに基づいてストレージシャーディングとクエリ最適化を実行します。クエリにプライマリキーが指定されている場合、クエリ効率が向上します。テーブルを作成するときは、プライマリキーを指定することをお勧めします。
単一ノードの Lindorm インスタンスはプライマリキーをサポートしていません。
ほとんどの場合、実際のシナリオに基づいて、データソースの一意の識別子をプライマリキーとして使用することをお勧めします。
IoT および産業用 IoT(IIoT)のシナリオでは、デバイス ID をプライマリキーとして使用できます。
コネクテッドカー(IoV)のシナリオでは、車両の一意の識別子をプライマリキーとして使用できます。
監視シナリオでは、アプリ ID や host:port などの識別子をプライマリキーとして使用できます。
前の例で示した時系列テーブル aqm では、ID に基づいて多数のクエリが実行される場合、ID をプライマリキーとして使用することで、最適なクエリパフォーマンスを得ることができます。
CREATE TABLE aqm (
city VARCHAR TAG,
district VARCHAR TAG,
id VARCHAR TAG,
time TIMESTAMP,
pm2_5 DOUBLE,
pm10 DOUBLE,
so2 DOUBLE,
no2 DOUBLE,
PRIMARY KEY (id) // 単一ノードの Lindorm インスタンスはプライマリキーをサポートしていません。Lindorm インスタンスが単一ノードの Lindorm インスタンスの場合は、この行を削除してください。
);時系列テーブルは、従来のリレーショナルデータベースのテーブルとは異なります。時系列テーブルでは、プライマリキー列の値が一意である必要はありません。列をプライマリキー列として指定する場合は、その列にタグのラベルが付いていることを確認してください。
データ型を選択するためのベストプラクティス
LindormTSDB でサポートされているデータ型の詳細については、「[データ型]」をご参照ください。時系列テーブルを作成する場合は、次のルールに基づいてデータ型を選択することをお勧めします。
タグ列
タグとして宣言された列の値は、VARCHAR データ型である必要があります。これらの列のデータ型は変更できません。
タイムスタンプ列
LindormTSDB は、タイムスタンプを UNIX 時間形式の BIGINT 値として LindormDFS に保存します。これにより、タイムスタンプの圧縮パフォーマンスが向上します。テーブルを作成するときは、タイムスタンプの計算要件に基づいて、BIGINT 型または TIMESTAMP 型を指定できます。
フィールド列
フィールド列はすべてのデータ型をサポートしています。優れたデータ圧縮と最適なクエリパフォーマンスを確保するために、フィールド列の値のデータ型として VARCHAR を使用しないことをお勧めします。