このトピックでは、Hologres 動的テーブルのクエリ再書き込み機能、その使用方法、および制限事項について説明します。
クエリ再書き込みの概要
ビッグデータおよびデータウェアハウスのシナリオでは、明細テーブルに数億行~数十億行もの膨大なデータが含まれることがよくあります。ビジネスおよび分析クエリでは、これらの明細テーブルに対して多次元的な GROUP BY + 集計 操作が頻繁に実行されます。たとえば、日別・時間帯別・都市別の注文数や商品総額(GMV)の集計、チャネル別またはデバイス別のページビュー(PV)、ユニークビジター(UV)、コンバージョン率の測定などが該当します。
集約コストが高い:各クエリは明細テーブル全体またはその大部分をスキャンし、結果を集約します。これにより、CPU および I/O リソースを大量に消費します。
明細テーブルへの負荷が高い:これにより、同一データベース内の他のタスクに影響が出るか、頻繁なスケールアウトが必要になります。
Hologres は動的テーブルおよびクエリ再書き込みをサポートしています。動的テーブルを使用して基底テーブルに対して事前集約が行われている場合、条件が満たされれば、オプティマイザーは基底テーブルを対象とした集約クエリを自動的に動的テーブルを対象とするように再書き込みます。これにより、高コストな集約計算を回避できます。主なメリットは以下のとおりです。
明細テーブルの集約負荷を軽減:注文数、GMV、PV、UV などの頻繁に使用されるメトリックを動的テーブルから直接読み取ることができます。これにより、明細テーブルに対する繰り返しのスキャンおよび集約が不要になります。
クエリ応答速度が大幅に向上:ダッシュボード、セルフサービス分析、対話型検索などでは、動的テーブルにヒットすることで高速に応答します。集約処理が大幅に削減され、レイテンシが低下し、ワイドテーブルをクエリしているような体験になります。
上流ユーザーへの影響なし:データアナリストおよびビジネス開発者は引き続き基底テーブルモデルのみを把握していればよく、データウェアハウスまたはプラットフォームチームが動的テーブルの設計およびメンテナンスを担当します。パフォーマンス最適化は完全に透明になります。
Hologres 動的テーブルのクエリ再書き込みは、以下のシナリオをサポートしています。
リアルタイムまたはニアリアルタイムの運用ダッシュボードおよびモニタリング。
多次元 BI 分析およびダウンロード。
GMV、注文数、アクティブユーザー数などのコアメトリックの統一計算を高速化。
使用方法と制限事項
バージョン制限:Hologres 4.1 以降でのみ利用可能です。
クエリ整合性の制限:クエリ再書き込みでは、動的テーブルの最新リフレッシュ結果が使用されます。基底テーブルの最新状態と比較すると、固定されたタイムウィンドウ内での遅延が生じます。これは弱い整合性です。
基底テーブルのタイプに関する制限:
サポートされる基底テーブルのタイプ:Hologres 内部テーブル、Paimon 外部テーブル(Foreign Table を使用して作成)、MaxCompute 外部テーブル(Foreign Table を使用して作成)。
基底テーブルが Hologres のパーティションテーブルである場合、物理パーティションはサポートされません。論理パーティションは許可されます。
外部テーブルはサポートされません。
動的テーブルのタイプに関する制限:
サポート対象:非パーティション動的テーブルおよび論理パーティション動的テーブル。
非サポート対象:物理パーティション動的テーブルおよび外部動的テーブル。
動的テーブルにおけるクエリ定義の制限:
クエリは単一テーブルのみをサポートします。複数テーブルを対象としたクエリはサポートされません。
クエリは
FILTER句を使用したフィルター付き集計をサポートしません(例:sum(x) FILTER (WHERE ...))。クエリは、集計結果に依存する SELECT リスト内の追加の計算列をサポートしません(例:
sum(x)/count(x))。
クエリ再書き込みの有効化と設定
使用推奨:秒単位~分単位のレイテンシが許容可能なダッシュボード、モニタリング、分析に最適です。厳密なリアルタイム性や照合精度が重要なワークロードでは、基底テーブルを直接クエリするか、別の強い整合性を保証するソリューションをご利用ください。
クエリ再書き込みの有効化
基底テーブルクエリに対してクエリ再書き込みを有効にするには、クエリ実行時に GUC パラメーター hg_enable_query_rewrite を設定します。
データベースレベルでこの設定を有効にしないでください。パフォーマンスが低下する可能性があります。
-- クエリ再書き込みを有効化(セッションレベル)
SET hg_enable_query_rewrite = on;
-- データベースレベルで設定(非推奨)
ALTER DATABASE <db_name> SET hg_enable_query_rewrite = on;動的テーブルに対するクエリ再書き込みの有効化
動的テーブルを作成する際、allowed_to_rewrite_query プロパティを使用して、その動的テーブルがクエリ再書き込みに参加するかどうかを制御します。デフォルトでは、参加しません。
CREATE [ OR REPLACE ] DYNAMIC TABLE [ IF NOT EXISTS ] [<schema_name>.]<table_name> (
[col_name],
[col_name],
[col_name]
)
[LOGICAL PARTITION BY LIST(<partition_key>)]
WITH (
...,
allowed_to_rewrite_query = '[true | false]',
...
)
AS
<query>;パラメーターの説明:
allowed_to_rewrite_query:この動的テーブルがクエリ再書き込みの候補として使用可能かどうかを示します。'true':クエリ再書き込みでの使用を許可します。'false':デフォルト値。クエリ再書き込みに参加しません。
使用上の推奨事項:
集約クエリの高速化を目的として構築された動的テーブルには、
'true'を設定してください。現在のルールでは活用できない複雑な動的テーブルには、
'false'を設定してください。これにより、オプティマイザーによる無駄な探索を削減できます。
動的テーブルのクエリ再書き込み設定の変更
ALTER DYNAMIC TABLE ... SET を使用して、動的テーブルがクエリ再書き込みに参加するかどうかを変更できます。
ALTER DYNAMIC TABLE [IF EXISTS] [<schema_name>.]<table_name>
SET (allowed_to_rewrite_query = '[true | false]');再書き込み先の動的テーブルの指定
複数の動的テーブルが存在する場合、ヒントワードを使用して候補セットを指定できます。これにより、オプティマイザーの探索範囲を狭め、優先順位を制御できます。ヒントワードの完全な構文については、「HINT」をご参照ください。
SELECT /*+HINT query_rewrite_candidates(<schema.dt_name1> <schema.dt_name2> ...) */
...
FROM ...;GUC 使用上の注意点:
複数の動的テーブル名はスペースで区切ります。
スキーマ名を含めることも可能です。
例:
-- dt_sales のみをクエリ再書き込みで使用可能に設定
SELECT /*+HINT query_rewrite_candidates(dt_sales) */
day, hour, min(amount), max(amount)
FROM base_sales_table
GROUP BY day, hour;サポートされる機能
現行バージョンでは、単一テーブル集約に対するクエリ再書き込みをサポートしています。以下の 3 つのパターンが含まれます。
集約ディメンションが完全に一致する場合の透過的な再書き込み。
集約ロールアップ(GROUP BY ディメンションのロールアップ)。
条件補償付き集約ロールアップ(WHERE フィルター付きロールアップ)。
集約ディメンションの完全一致
条件:
クエリの
GROUP BYディメンションが、動的テーブル定義のGROUP BYディメンションと完全に一致すること。クエリの集計関数が、動的テーブル内に既存の集計結果列に直接マッピングされること。
DISTINCT を含むすべての集計関数タイプがサポートされますが、動的テーブルにすでに対応する結果列が含まれている必要があります。
例:
-- 基底テーブルの作成
CREATE TABLE base_sales_table(
day text not null,
hour int,
amount int
);
-- データの挿入
INSERT INTO base_sales_table
VALUES ('20250529', 12, 1),
('20250529', 12, 2),
('20250529', 12, 2),
('20250529', 13, 3),
('20250530', 13, 4),
('20250530', 14, 5),
('20250531', 14, 6);
-- 動的テーブル
CREATE DYNAMIC TABLE dt_sales
WITH (
freshness = '1 minutes',
auto_refresh_mode='incremental',
auto_refresh_enable='false',
allowed_to_rewrite_query='true'
)
AS
SELECT
day,
hour,
min(amount),
max(amount),
sum(amount),
count(amount),
count(*) as rows,
count(1) as rows1,
count(distinct amount) as cd
FROM base_sales_table
GROUP BY day, hour;
REFRESH TABLE dt_sales;クエリ例:ディメンションが一致する場合、実行計画に、基底テーブルクエリが動的テーブルのスキャンに再書き込みされたことが表示されます。
-- ディメンションが一致するクエリ
EXPLAIN SELECT day, hour, min(amount), max(amount) FROM base_sales_table GROUP BY day, hour;
集約ロールアップ
条件:
動的テーブルの
GROUP BYディメンションが、クエリのGROUP BYディメンションの上位集合であること。言い換えると、動的テーブルはクエリよりも多くのディメンションでグループ化されていること。クエリの集計関数が、動的テーブル内の既存列を再集約することで計算可能であること。
サポートされる集計関数:
min、max、count、sum、およびavg。DISTINCT を使用したロールアップはサポートされません(完全一致の場合を除く。この場合は、動的テーブルにすでに DISTINCT の結果が格納されています)。
集計関数のマッピング:
元の基底テーブルクエリの集計関数 | 動的テーブルに必要な集計列 | 再書き込み後の集計関数 |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
例:
-- 基底テーブルの作成
CREATE TABLE base_sales_table(
day text not null,
hour int,
amount int
);
-- データの挿入
INSERT INTO base_sales_table
VALUES ('20250529', 12, 1),
('20250529', 12, 2),
('20250529', 12, 2),
('20250529', 13, 3),
('20250530', 13, 4),
('20250530', 14, 5),
('20250531', 14, 6);
-- 動的テーブル:自動更新を無効にしてクエリ再書き込みを検証
CREATE DYNAMIC TABLE dt_sales
WITH (
freshness = '1 minutes',
auto_refresh_mode='incremental',
auto_refresh_enable='false',
allowed_to_rewrite_query='true'
)
AS
SELECT
day,
hour,
min(amount),
max(amount),
sum(amount),
count(amount),
count(*) as rows,
count(1) as rows1,
count(distinct amount) as cd
FROM base_sales_table
GROUP BY day, hour;
-- 動的テーブルを手動でリフレッシュ
REFRESH TABLE dt_sales;クエリ例 1:日付のみで集約(ロールアップ)。基底テーブルクエリの GROUP BY 列が動的テーブルで定義された列のサブセットであるため、再書き込みが適用されます。
-- 元のクエリ
EXPLAIN SELECT day, min(amount), max(amount)
FROM base_sales_table
GROUP BY day;
クエリ例 2:sum + count + avg を使用したロールアップ。基底テーブルクエリで avg を使用しており、動的テーブルに sum および count が提供されているため、avg を導出できます。再書き込みが適用されます。
-- 元のクエリ
EXPLAIN SELECT day, sum(amount), count(amount), avg(amount)
FROM base_sales_table
GROUP BY day;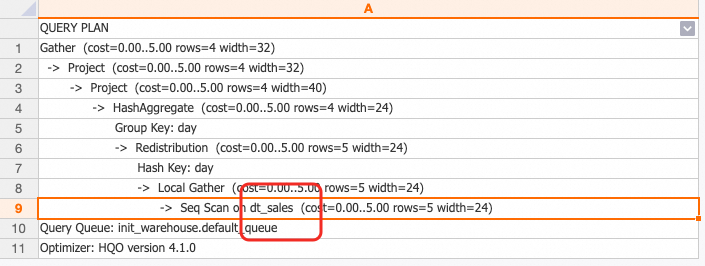
条件補償付き集約ロールアップ(フィルターあり)
条件:
基底テーブルクエリに WHERE フィルターが含まれているが、動的テーブルの定義には
WHEREフィルターが含まれていないこと。WHERE 句で使用されるすべてのフィールドが、動的テーブルの
GROUP BYディメンションに含まれていること。サポートされる集計関数:
min、max、count、sum、およびavg。DISTINCT はサポートされません。
例:
-- 基底テーブルの作成
CREATE TABLE base_sales_table(
day text not null,
hour int,
amount int
);
-- データの挿入
INSERT INTO base_sales_table
VALUES ('20250529', 12, 1),
('20250529', 12, 2),
('20250529', 12, 2),
('20250529', 13, 3),
('20250530', 13, 4),
('20250530', 14, 5),
('20250531', 14, 6);
-- 動的テーブル:自動更新を無効にしてクエリ再書き込みを検証
CREATE DYNAMIC TABLE dt_sales
WITH (
freshness = '1 minutes',
auto_refresh_mode='incremental',
auto_refresh_enable='false',
allowed_to_rewrite_query='true'
)
AS
SELECT
day,
hour,
min(amount),
max(amount),
sum(amount),
count(amount),
count(*) as rows,
count(1) as rows1,
count(distinct amount) as cd
FROM base_sales_table
GROUP BY day, hour;
-- 動的テーブルを手動でリフレッシュ
REFRESH TABLE dt_sales;以下の例では、基底テーブルクエリに WHERE 条件が含まれており、フィルターで使用されるすべてのフィールドが GROUP BY リストに含まれているため、再書き込みが適用されます。
EXPLAIN SELECT day, sum(amount), count(amount), avg(amount)
FROM base_sales_table
WHERE day > '20250528' AND day <= '20250531'
GROUP BY day;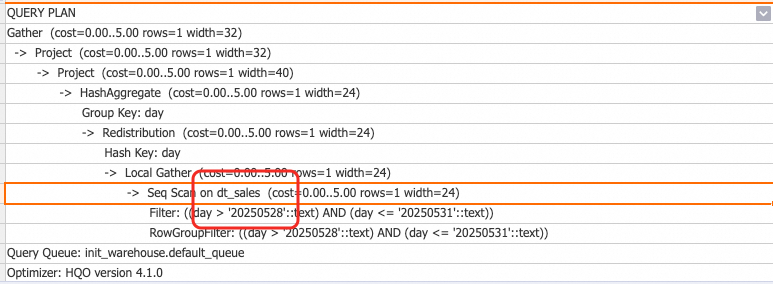
クエリ再書き込みステータスの確認
クエリ再書き込みを有効化した後、以下のいずれかの方法でクエリが動的テーブルにヒットしているかどうかを確認できます。
実行計画の確認:EXPLAIN の結果で、Scan オペレーターがスキャンするテーブル名を確認し、動的テーブルがヒットしているかどうかを判断します。
スロークエリログの確認:
hologres.hg_query_logテーブルのextended_infoフィールドに、選択された動的テーブルが記録されます。再書き込みが失敗した場合、その原因もここに表示されます。
select extended_info::json->>'rewrite_query_info' from hologres.hg_query_log where query_id = 'xxxxx';
?column?
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
{"rewrite_failed_dt": [[\"public.dt3\", {\"rewrite_failed_cause\": \"Doesn't include all query required output columns\"}]], \"rewrite_succeeded_and_selected_dt\": [\"public.dt2\"], \"rewrite_succeeded_but_not_selected_dt\": [\"public.dt1\"]}
(1 row)使用例
Hologres 内部テーブルを基底テーブルとするクエリ再書き込みの例
基底テーブルは TPC-H lineitem データセット(100 GB)から取得します。テーブル作成およびインポート手順については、「公開データセットのワンクリックインポート」をご参照ください。この例では、動的テーブルは増分更新を使用し、非パーティション構成です。
CREATE DYNAMIC TABLE dt_lineitem_100g_incremental
WITH (
freshness = '10 minutes',
auto_refresh_mode='incremental',
auto_refresh_enable='false',
allowed_to_rewrite_query='true')
AS
select
l_returnflag,
l_linestatus,
l_shipdate,
sum(l_quantity) as sum_qty,
count(*) as count_order
from
hologres_dataset_tpch_100g.lineitem
group by
l_returnflag,
l_linestatus,
l_shipdate
-- 手動でリフレッシュ
REFRESH DYNAMIC TABLE dt_lineitem_100g_incremental;基底テーブルをクエリします:
set hg_enable_query_rewrite = on;
explain
select
l_returnflag,
l_linestatus,
l_shipdate,
sum(l_quantity) as sum_qty,
count(*) as count_order
from
hologres_dataset_tpch_100g.lineitem
where l_shipdate = '1998-12-01'
group by
l_returnflag,
l_linestatus,
l_shipdate実行計画に、クエリが動的テーブルのスキャンに再書き込みされたことが表示されます:

基底テーブルをクエリした結果:
l_returnflag | l_linestatus | l_shipdate | sum_qty | count_order
--------------+--------------+------------+----------+-------------
N | O | 1998-12-01 | 52841.00 | 2070
(1 row)動的テーブルを直接クエリします(ここでは自動更新が無効になっており、手動リフレッシュが 1 回のみ実行されています)。結果は最新のリフレッシュ内容と一致します:
select
l_returnflag,
l_linestatus,
l_shipdate,
sum_qty,
count_order
from
dt_lineitem_100g_incremental
where l_shipdate = '1998-12-01' ;
l_returnflag | l_linestatus | l_shipdate | sum_qty | count_order
--------------+--------------+------------+----------+-------------
N | O | 1998-12-01 | 52841.00 | 2070
(1 row)Paimon 外部テーブルを基底テーブルとするクエリ再書き込みの例
基底テーブルが Paimon 外部テーブルの場合にも、クエリ再書き込みは機能します。手順は以下のとおりです。
Paimon テーブルの準備:TPC-H customer 100 GB テーブルを Paimon にインポートします。詳細については、「Paimon テーブル」をご参照ください。
Hologres に Paimon 外部テーブルを作成:Foreign Table 方式を使用します。「DLF を使用した Paimon カタログへのアクセス」をご参照ください。
-- 外部サーバーの作成
CREATE SERVER IF NOT EXISTS paimon_server FOREIGN DATA WRAPPER dlf_fdw OPTIONS (
catalog_type 'paimon',
metastore_type 'dlf-rest',
dlf_catalog '<dlf_catalog_name>'
);
-- Paimon スキーマを外部テーブルとしてインポート
IMPORT FOREIGN SCHEMA <schema_name>
limit to (customer)
FROM SERVER paimon_server into public
options (if_table_exist 'update');
-- データのクエリ
SELECT * FROM customerPaimon 外部テーブルから増分更新を行う動的テーブルの作成:Hologres に、Paimon 外部テーブルから増分更新を行う動的テーブルを構築します。ここでは検証を簡略化するため、自動更新を無効にしています。
-- 動的テーブルの作成
CREATE DYNAMIC TABLE dt_paimon_customer
WITH (
freshness = '10 minutes',
auto_refresh_mode='incremental',
auto_refresh_enable='false',
allowed_to_rewrite_query='true')
AS
SELECT
c_custkey,
avg(c_acctbal) ,
sum(c_acctbal) ,
count(c_acctbal)
FROM customer
group by c_custkey;
-- 動的テーブルを手動でリフレッシュ
REFRESH DYNAMIC TABLE dt_paimon_customer;クエリ再書き込みを有効にして Paimon 外部テーブルをクエリします。
set hg_enable_query_rewrite = on;
SELECT
c_custkey,
avg(c_acctbal) ,
sum(c_acctbal) ,
count(c_acctbal)
FROM
customer
group by c_custkey ORDER BY 3 DESC LIMIT 3;
c_custkey | avg |sum |count
----------|-------------|---------|-----
3605586 |9999.990000 | 9999.99 |1
10705496 |9999.990000 |9999.99 |1
14959900 |9999.990000 |9999.99 |1動的テーブルのクエリ:結果は最新のリフレッシュ内容を反映しています。
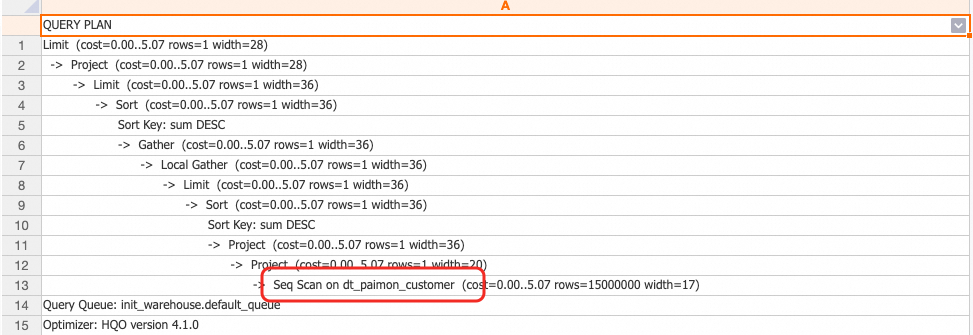
SELECT * FROM dt_paimon_customer ORDER BY 3 DESC LIMIT 3;
c_custkey | avg |sum |count
----------|-------------|---------|-----
3605586 |9999.990000 | 9999.99 |1
10705496 |9999.990000 |9999.99 |1
14959900 |9999.990000 |9999.99 |1実行計画による確認:計画に、クエリが動的テーブルへのアクセスに再書き込みされたことが表示されます。