このトピックでは、Hologres と Flink を統合して、リアルタイムでユニークビジター (UV) 数をカウントする方法について説明します。
前提条件
Hologres インスタンスが購入され、開発ツールを使用して接続されています。この例では、HoloWeb を使用します。 HoloWeb を使用して Hologres インスタンスに接続する方法の詳細については、HoloWeb への接続とクエリの発行 を参照してください。
Flink クラスタが作成されています。 Realtime Compute for Apache Flink のフルマネージド Flink または Apache Flink を使用できます。
背景情報
Hologres は Flink と高度に互換性があります。 Hologres は、Flink からのリアルタイムの高スループットデータ書き込みと、書き込まれたデータのリアルタイムクエリをサポートしています。 Hologres では、Flink SQL ステートメントを実行することで、ソーステーブルをディメンションテーブルに結合できます。 Hologres では、データ分析に Change Data Capture (CDC) 機能を使用することもできます。 Hologres と Flink を統合して、リアルタイムで UV 数をカウントできます。次の図はワークフローを示しています。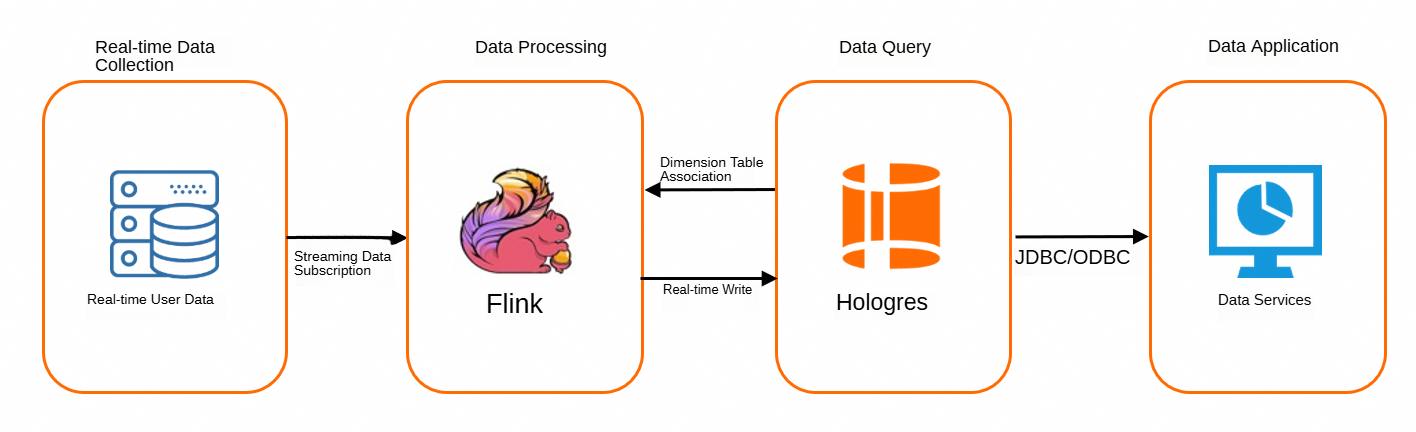
Flink は、新しく収集されたデータにリアルタイムでサブスクライブします。データは、Kafka ログなどのログから収集できます。
Flink は、サブスクライブされたデータストリームをソーステーブルに変換します。次に、Flink はソーステーブルを Hologres ディメンションテーブルに結合して、ソーステーブルのデータをリアルタイムで Hologres に書き込みます。
Hologres は、書き込まれたデータをリアルタイムで処理します。
処理されたデータは、DataService Studio や Quick BI などの上位層のデータサービスによって使用されます。
仕組み
Flink と Hologres の高度な統合、および Hologres でネイティブにサポートされている roaring bitmaps により、タグベースの重複排除に基づいてリアルタイムで UV 数をカウントできます。次の図はフローチャートを示しています。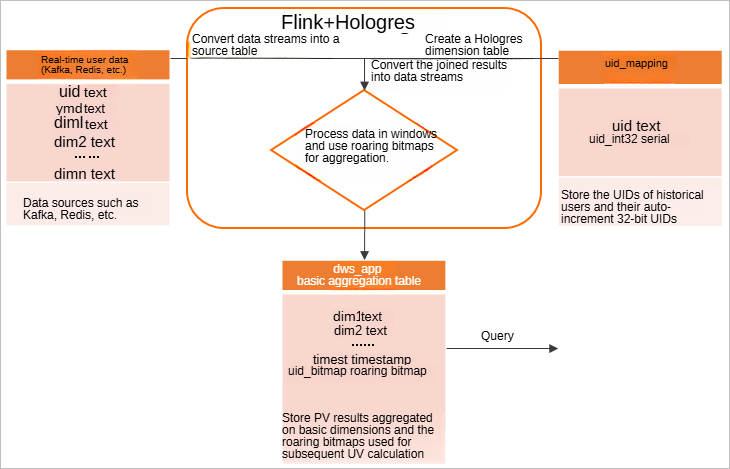
Flink で、Kafka や Redis などのデータソースからユーザーデータにサブスクライブし、DataStream プログラムを使用してデータストリームをソーステーブルに変換します。
履歴ユーザーの UID と自動インクリメント 32 ビット UID を格納するために、Hologres に一意の ID (UID) マッピングテーブルを作成します。
説明多くの場合、ビジネスまたはトラッキングポイント関連のアクティビティで収集された UID は、STRING 型または LONG 型です。このような場合は、UID マッピングテーブルを作成する必要があります。 roaring bitmaps に格納される UID は 32 ビット整数である必要があり、連続した整数が推奨されます。 UID マッピングテーブルには、自動インクリメント 32 ビット整数で構成される SERIAL 型の列が含まれています。これにより、UID マッピングが自動的に管理され、安定した状態が維持されます。
Flink で、Hologres の UID マッピングテーブルをディメンションテーブルとして使用し、Hologres ディメンションテーブルの insertIfNotExists 機能を使用して、自動インクリメント 32 ビット整数 に基づいて UID を効率的にマッピングします。ソーステーブルを Hologres ディメンションテーブルに結合し、結合された結果をデータストリームに変換します。
処理された結果を集計するために、Hologres にテーブルを作成します。 Flink は、時間ウィンドウに基づいて結合された結果を処理し、クエリディメンションに基づいて roaring bitmap 関数 を実行します。
クエリディメンションに基づいて集計結果テーブルをクエリします。 roaring bitmap フィールドで
OR演算を実行し、データエントリの数を計算します。UV 数が取得されます。
これにより、きめ細かい UV データとページビュー (PV) データを取得できます。過去 5 分間の UV などの最小統計ウィンドウを、ビジネス要件に基づいて調整できます。これは、リアルタイム監視と同様の効果があり、ビジネスインテリジェンス (BI) ツールの大きな画面にデータをより適切に表示します。このソリューションは、日、週、または月ごとの重複排除よりも、特定の営業日のデータのよりきめ細かい重複排除において、より優れたパフォーマンスを提供します。このソリューションは、重複排除結果を集計することにより、比較的長期間にわたって重複排除されたデータを提供することもできます。結果がきめ細かく集計されていても、フィルター条件または集計ディメンションが提供されていない場合、結果がクエリされるときに再度集計される可能性があります。これは計算パフォーマンスに悪影響を及ぼします。
このソリューションは使いやすく、計算のディメンションを設定できます。このソリューションはデータをビットマップに格納するため、必要なストレージ容量が大幅に削減されます。さらに、このソリューションはリアルタイムで重複排除結果を返します。これらのすべての利点が組み合わさって、豊富な機能を提供し、リアルタイムで柔軟なデータ分析をサポートする多次元データウェアハウスの構築に役立ちます。
手順
Hologres にテーブルを作成します。
UID マッピングテーブルを作成します。
次のステートメントを実行して、Hologres に uid_mapping という名前の UID マッピングテーブルを作成します。 UID マッピングテーブルは、UID とその 32 ビット整数の間のマッピングを確立するために使用されます。元の UID が 32 ビット整数の場合、この手順はスキップします。
多くの場合、ビジネスまたはトラッキングポイント関連のアクティビティで収集された UID は、STRING 型または LONG 型です。このような場合は、UID マッピングテーブルを作成する必要があります。 roaring bitmaps に格納される UID は 32 ビット整数である必要があり、連続した整数が推奨されます。 UID マッピングテーブルには、自動インクリメント 32 桁の整数で構成される SERIAL 型の列が含まれています。これにより、UID マッピングが自動的に管理され、安定した状態が維持されます。
UID に関するデータストリームはリアルタイムで収集され、行指向のソーステーブルに変換されます。これにより、Flink でソーステーブルを Hologres ディメンションテーブルに結合するときの 1 秒あたりのクエリ数 (QPS) が増加します。
最適化された実行エンジンを使用して SERIAL 型の列を含むテーブルにデータを書き込むには、Grand Unified Configuration (GUC) パラメータを指定する必要があります。詳細については、固定プランを使用して SQL ステートメントの実行を高速化する を参照してください。
-- SERIAL データ型の列を含むテーブルにデータを書き込むために固定プランの使用を許可する GUC パラメータを指定します。 alter database <dbname> set hg_experimental_enable_fixed_dispatcher_autofill_series=on; alter database <dbname> set hg_experimental_enable_fixed_dispatcher_for_multi_values=on; BEGIN; CREATE TABLE public.uid_mapping ( uid text NOT NULL, uid_int32 serial, PRIMARY KEY (uid) ); -- UID 列をクラスタリングキーおよび分散キーとして構成して、UID に対応する 32 ビット整数をすばやく見つけます。 CALL set_table_property('public.uid_mapping', 'clustering_key', 'uid'); CALL set_table_property('public.uid_mapping', 'distribution_key', 'uid'); CALL set_table_property('public.uid_mapping', 'orientation', 'row'); COMMIT;集計結果テーブルを作成します。
集計結果を格納する dws_app という名前の集計結果テーブルを作成します。
roaring bitmap 関数 を使用する前に、roaring bitmaps の拡張機能がインストールされており、Hologres インスタンスのバージョンが V0.10 以降であることを確認してください。
CREATE EXTENSION IF NOT EXISTS roaringbitmap;オフライン結果テーブルと比較して、この集計結果テーブルにはタイムスタンプ列が追加され、Flink 時間ウィンドウのライフサイクルに基づいて収集されたデータが計算されます。次の DDL ステートメントは例を示しています。
BEGIN; CREATE TABLE dws_app( country text, prov text, city text, ymd text NOT NULL, -- 日付列。 timetz TIMESTAMPTZ, -- Flink 時間ウィンドウのライフサイクルに基づいて収集されたデータを計算するために使用されるタイムスタンプ列。 uid32_bitmap roaringbitmap, -- UV の計算に使用される roaring bitmap データ。 PRIMARY KEY (country, prov, city, ymd, timetz) -- データが繰り返し挿入されないように、クエリディメンションと時間に関する列を主キー列として構成します。 ); CALL set_table_property('public.dws_app', 'orientation', 'column'); -- 日付列をクラスタリングキーおよびイベント時間列として設定して、データをフィルタリングします。 CALL set_table_property('public.dws_app', 'clustering_key', 'ymd'); CALL set_table_property('public.dws_app', 'event_time_column', 'ymd'); -- クエリディメンションに関する列を分散キー列として設定します。 CALL set_table_property('public.dws_app', 'distribution_key', 'country,prov,city'); COMMIT;
Flink を使用してリアルタイムでデータストリームを読み取り、集計結果テーブルを更新します。
完全なサンプルコードについては、alibabacloud-hologres-connectors を参照してください。この例では、Flink で次の手順が実行されます。
データストリームを読み取り、データをソーステーブルに変換します。
Flink を使用して、ストリーミングモードでデータソースからデータを読み取ります。ビジネス要件に基づいて、CSV ファイル、Kafka データソース、または Redis データソースを選択できます。次のサンプルコードは、データをテーブルに変換する方法の例を示しています。
// この例では、データソースは CSV ファイルです。 Kafka データソースまたは Redis データソースを選択することもできます。 DataStreamSource odsStream = env.createInput(csvInput, typeInfo); // ソーステーブルをディメンションテーブルに結合する前に、proctime プロパティを記述する列をソーステーブルに追加します。 Table odsTable = tableEnv.fromDataStream( odsStream, $("uid"), $("country"), $("prov"), $("city"), $("ymd"), $("proctime").proctime()); -- カタログビューを作成します。 tableEnv.createTemporaryView("odsTable", odsTable);ソーステーブルを uid_mapping という名前の Hologres ディメンションテーブルに結合します。
Flink で Hologres ディメンションテーブルを作成するときは、
insertIfNotExistsパラメータを true に設定します。これにより、データがクエリされない場合に、ディメンションテーブルに手動でデータを挿入できます。 uid_int32 フィールドは、自動インクリメント 32 ビット整数を含む SERIAL 型の列です。次のサンプルコードは、テーブルを結合する方法の例を示しています。-- Hologres ディメンションテーブルを作成します。 insertIfNotExists パラメータは、データをクエリできない場合にディメンションテーブルに手動でデータを挿入するかどうかを指定します。 String createUidMappingTable = String.format( "create table uid_mapping_dim(" + " uid string," + " uid_int32 INT" + ") with (" + " 'connector'='hologres'," + " 'dbname' = '%s'," // Hologres ディメンションテーブルが存在する Hologres データベース。 + " 'tablename' = '%s'," // Hologres ディメンションテーブルの名前。 + " 'username' = '%s'," // Alibaba Cloud アカウントの AccessKey ID。 + " 'password' = '%s'," // Alibaba Cloud アカウントの AccessKey シークレット。 + " 'endpoint' = '%s'," //Hologres エンドポイント + " 'insertifnotexists'='true'" + ")", database, dimTableName, username, password, endpoint); tableEnv.executeSql(createUidMappingTable); -- ソーステーブルを Hologres ディメンションテーブルに結合します。 String odsJoinDim = "SELECT ods.country, ods.prov, ods.city, ods.ymd, dim.uid_int32" + " FROM odsTable AS ods JOIN uid_mapping_dim FOR SYSTEM_TIME AS OF ods.proctime AS dim" + " ON ods.uid = dim.uid"; Table joinRes = tableEnv.sqlQuery(odsJoinDim);結合された結果をデータストリームに変換します。
Flink 時間ウィンドウを使用してデータストリームを処理し、roaring bitmap 関数を実行してデータを重複排除します。次のサンプルコードは例を示しています。
DataStream<Tuple6<String, String, String, String, Timestamp, byte[]>> processedSource = source -- データがクエリされるディメンション。この例では、ディメンションは country、prov、city、および ymd 列です。 .keyBy(0, 1, 2, 3) -- Flink タンブリングウィンドウ。この例では、データソースは CSV ファイルであるため、データストリームは処理時間に基づいてウィンドウに割り当てられます。実際のシナリオでは、ビジネス要件に基づいて、処理時間またはイベント時間のいずれかに基づいてデータストリームを割り当てることができます。 .window(TumblingProcessingTimeWindows.of(Time.minutes(5))) -- トリガー。ウィンドウが削除される前に、集計結果を取得できます。 .trigger(ContinuousProcessingTimeTrigger.of(Time.minutes(1))) .aggregate( -- 集計関数。指定されたクエリディメンションに基づいて結果を集計するために使用されます。 new AggregateFunction< Tuple5<String, String, String, String, Integer>, RoaringBitmap, RoaringBitmap>() { @Override public RoaringBitmap createAccumulator() { return new RoaringBitmap(); } @Override public RoaringBitmap add( Tuple5<String, String, String, String, Integer> in, RoaringBitmap acc) { -- 32 桁の UID に対して roaring bitmap 関数を実行して、重複する UID を削除します。 acc.add(in.f4); return acc; } @Override public RoaringBitmap getResult(RoaringBitmap acc) { return acc; } @Override public RoaringBitmap merge( RoaringBitmap acc1, RoaringBitmap acc2) { return RoaringBitmap.or(acc1, acc2); } }, -- ウィンドウ関数。集計結果を生成するために使用されます。 new WindowFunction< RoaringBitmap, Tuple6<String, String, String, String, Timestamp, byte[]>, Tuple, TimeWindow>() { @Override public void apply( Tuple keys, TimeWindow timeWindow, Iterable<RoaringBitmap> iterable, Collector< Tuple6<String, String, String, String, Timestamp, byte[]>> out) throws Exception { RoaringBitmap result = iterable.iterator().next(); // roaring bitmap 関数の結果を最適化します。 result.runOptimize(); // roaring bitmap 関数の結果をバイト配列に変換し、Hologres に格納します。 byte[] byteArray = new byte[result.serializedSizeInBytes()]; result.serialize(ByteBuffer.wrap(byteArray)); // Tuple6 パラメータは、データストリームがウィンドウのライフサイクルに基づいて処理されることを指定します。パラメータの値は秒単位で測定されます。 out.collect( new Tuple6<>( keys.getField(0), keys.getField(1), keys.getField(2), keys.getField(3), new Timestamp( timeWindow.getEnd() / 1000 * 1000), byteArray)); } });重複を除去したデータを Hologres 集計結果テーブルに書き込みます。
重複を除去したデータを dws_app という名前の Hologres 集計結果テーブルに書き込みます。 roaring bitmap 関数の結果は、Flink にバイト配列として格納されます。次のサンプルコードは例を示しています。
-- 処理された結果をテーブルに変換します。 Table resTable = tableEnv.fromDataStream( processedSource, $("country"), $("prov"), $("city"), $("ymd"), $("timest"), $("uid32_bitmap")); -- Hologres に集計結果テーブルを作成します。 roaring bitmap 関数の結果をバイト配列としてテーブルに格納します。 String createHologresTable = String.format( "create table sink(" + " country string," + " prov string," + " city string," + " ymd string," + " timetz timestamp," + " uid32_bitmap BYTES" + ") with (" + " 'connector'='hologres'," + " 'dbname' = '%s'," + " 'tablename' = '%s'," + " 'username' = '%s'," + " 'password' = '%s'," + " 'endpoint' = '%s'," + " 'connectionSize' = '%s'," + " 'mutatetype' = 'insertOrReplace'" + ")", database, dwsTableName, username, password, endpoint, connectionSize); tableEnv.executeSql(createHologresTable); -- 結果を dws_app という名前のテーブルに書き込みます。 tableEnv.executeSql("insert into sink select * from " + resTable);
データをクエリします。
dws_app テーブルのデータに基づいて UV を計算します。クエリディメンションに基づいて集計演算を実行し、ビットマップのビット数をクエリします。これにより、GROUP BY 句で指定された条件下で UV を計算できます。
例 1: 特定の日の各都市の UV 数をクエリする
-- データをクエリするには、次の RB_AGG 演算を実行します。パフォーマンスを向上させるために、3 段階集計機能を無効にすることができます。この機能は、要件に基づいて有効または無効にすることができます。デフォルトでは、この機能は無効になっています。 set hg_experimental_enable_force_three_stage_agg=off; SELECT country ,prov ,city ,RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv FROM dws_app WHERE ymd = '20210329' GROUP BY country ,prov ,city ;例 2: 特定の期間内の各州の UV と PV をクエリする
-- データをクエリするには、次の RB_AGG 演算を実行します。パフォーマンスを向上させるために、3 段階集計機能を無効にすることができます。この機能は、要件に基づいて有効または無効にすることができます。デフォルトでは、この機能は無効になっています。 set hg_experimental_enable_force_three_stage_agg=off; SELECT country ,prov ,RB_CARDINALITY(RB_OR_AGG(uid32_bitmap)) AS uv ,SUM(pv) AS pv FROM dws_app WHERE time > '2021-04-19 18:00:00+08' and time < '2021-04-19 19:00:00+08' GROUP BY country ,prov ;
データを視覚的に表示します。
ほとんどの場合、ビジネスインテリジェンス (BI) ツールを使用して、計算された UV と PV を視覚的に表示する必要があります。計算プロセスでは、RB_CARDINALITY 関数と RB_OR_AGG 関数を使用してデータが集計されます。したがって、BI ツールはカスタム集計関数をサポートする必要があります。 Apache Superset や Tableau などの一般的な BI ツールを使用できます。
Apache Superset
Apache Superset を Hologres に接続します。詳細については、Apache Superset を参照してください。
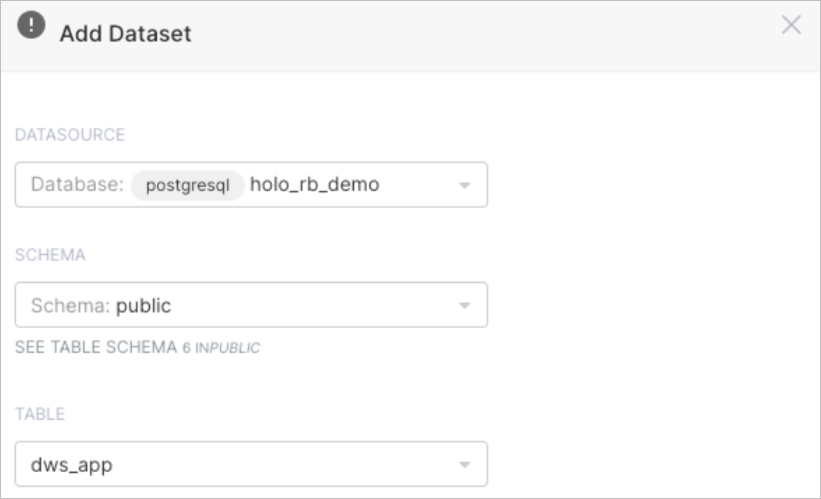
dws_app テーブルをデータセットとして設定します。
次の図に示す式を使用して、データセットに UV という名前のメトリックを作成します。
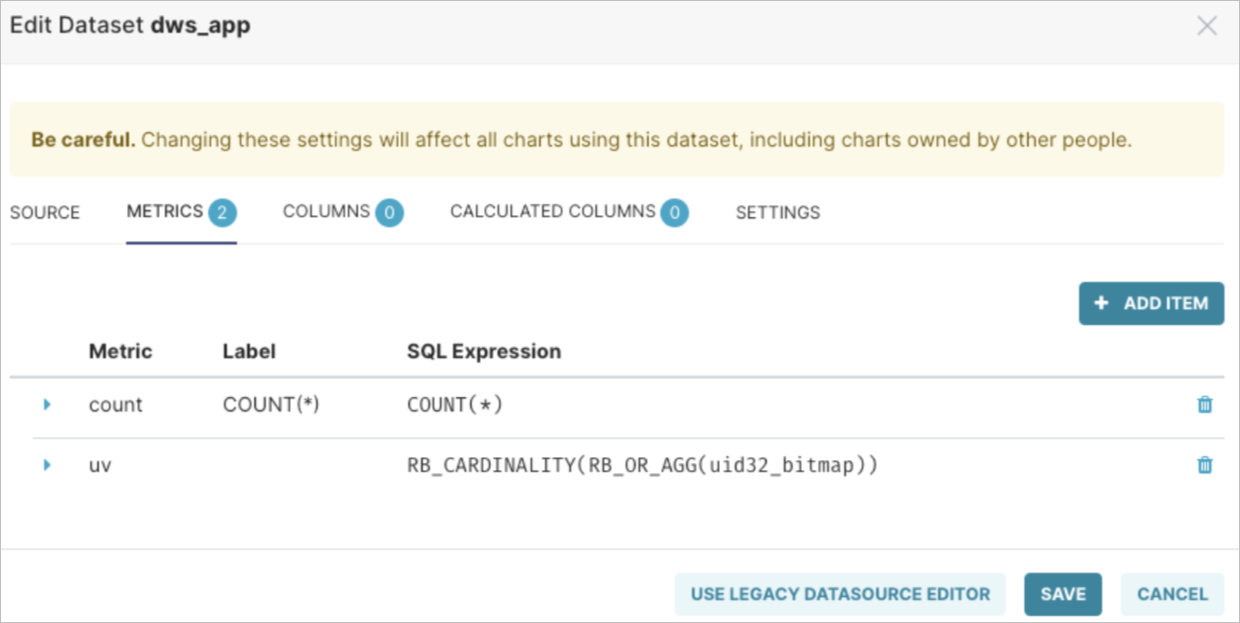
RB_CARDINALITY(RB_OR_AGG(uid32_bitmap))これで、データの探索を開始できます。
オプション。ダッシュボードを作成します。
ダッシュボードの作成方法の詳細については、最初のダッシュボードの作成 を参照してください。
Tableau
Tableau を Hologres に接続します。詳細については、Tableau を参照してください。
Tableau のパススルー関数を使用して関数をカスタマイズできます。詳細については、パススルー関数 (RAWSQL) を参照してください。
次の図に示す式を使用して、計算フィールドを作成します。

RAWSQLAGG_INT("RB_CARDINALITY(RB_OR_AGG(%1))", [Uid32 Bitmap])これで、データの探索を開始できます。
オプション。ダッシュボードを作成します。
ダッシュボードの作成方法の詳細については、ダッシュボードの作成 を参照してください。