このトピックでは、リアルタイム推論シナリオと、アイドルモードの GPU アクセラレーションインスタンスを使用して、低レイテンシで費用対効果の高いリアルタイム推論サービスを構築する方法について説明します。
シナリオ
リアルタイム推論ワークロードの特性
リアルタイム推論ワークロードには、多くの場合、次の特性の 1 つ以上があります。
低レイテンシ
リアルタイム推論ワークロードでは、各リクエストの応答時間に対する要件が高くなります。ロングテールレイテンシは、リクエストの 90% で数百ミリ秒以内である必要があります。
コアリンク
ほとんどの場合、リアルタイム推論ワークロードはコアビジネスリンクで生成されるため、高い成功率が必要であり、拡張された再試行を行う余裕はありません。例として、次の項目があります。
起動ページとホームページのプロモーションコンテンツ:ユーザーの個々のプリファレンスに一致する製品広告と推奨事項は、ユーザーの起動ページとホームページに迅速かつ目立つように表示する必要があります。
リアルタイムストリーミングサービス:共同ストリーミング、ライブストリーミング、超低レイテンシ再生などのシナリオでは、オーディオおよびビデオストリームを非常に低いエンドツーエンドレイテンシで送信する必要があります。リアルタイムの AI ベースのビデオ超解像度とビデオ認識のパフォーマンスも保証する必要があります。
変動するトラフィック
ビジネストラフィックはユーザーの習慣によって変動し、ピーク時とオフピーク時が発生します。
低いリソース使用率
ほとんどの場合、GPU リソースはトラフィックのピークに基づいて計画されるため、オフピーク時には大量のリソースが休止状態になります。リソース使用率は一般的に 30% 未満です。
リアルタイム推論シナリオで Function Compute を使用するメリット
アイドルモードの GPU アクセラレーションインスタンス
Function Compute は、プロビジョニングされた GPU アクセラレーションインスタンスにアイドルモード機能を提供します。コールドスタートを軽減し、リアルタイム推論ワークロードの低レイテンシ要件を満たすには、アイドルモードを有効にしたプロビジョニングされた GPU アクセラレーションインスタンスを構成できます。詳細については、「インスタンスタイプと使用モード」をご参照ください。GPU アクセラレーションインスタンスのこのアイドルモード機能には、次のメリットがあります。
インスタンスの迅速なウェイクアップ:Function Compute は、リアルタイムワークロードに基づいて GPU アクセラレーションインスタンスをフリーズし、受信リクエストがあると自動的にフリーズ解除します。フリーズ解除プロセスには 2 ~ 3 秒かかることに注意してください。
費用対効果の高いサービス:プロビジョニングモードとオンデマンドモードのインスタンスの実行時間の測定は異なります。アイドルモードのプロビジョニングされたインスタンスは、アクティブなインスタンスよりも低い単価で課金されます。詳細については、「Function Compute でリアルタイム推論サービスを使用するための課金方法」をご参照ください。アイドルモードのプロビジョニングされた GPU アクセラレーションインスタンスを使用する全体的なコストは、オンデマンドインスタンスを使用するよりも高くなりますが、オンプレミス環境で GPU クラスタを構築するコストよりも 50% 以上低くなります。
推論シナリオ向けに最適化されたリクエストスケジューリングメカニズム
Function Compute は、組み込みのインテリジェントスケジューリングメカニズムを提供して、関数内の異なる GPU アクセラレーションインスタンス間の負荷分散を実現します。Function Compute のこのインテリジェントスケジューリングは、推論リクエストをバックエンドの GPU アクセラレーションインスタンスに均等に分散し、推論クラスタの全体的な使用率を向上させます。
アイドルモードの GPU アクセラレーションインスタンス
GPU 関数をデプロイした後、アイドルモードが有効になっているプロビジョニングされた GPU アクセラレーションインスタンスを使用して、リアルタイム推論シナリオのインフラストラクチャ機能を提供できます。Function Compute は、プロビジョニングされた GPU アクセラレーションインスタンスで水平ポッド自動スケーリング ( HPA ) を実行し、メトリックベースのスケーリングポリシーとワークロードに基づいてリソースを動的に調整します。推論リクエストは、処理のためにプロビジョニングされた GPU アクセラレーションインスタンスに優先的に割り当てられます。プロビジョニングされたインスタンスはコールドスタートの削減に役立ち、推論サービスが常に低レイテンシで応答できるようにします。
アイドルモードはコスト削減に役立ちます
アイドルモード機能を有効にすると、GPU アクセラレーションインスタンスの課金は、アイドル GPU とアクティブ GPU の 2 つの個別の単価によって決定されます。Function Compute は、インスタンスの状態に基づいて統計を自動的に収集し、料金を請求します。
次の図に示す例では、GPU アクセラレーションインスタンスは、作成から破棄まで 5 つのタイムウィンドウ ( T0 ~ T4 ) を通過します。インスタンスは T1 と T3 ではアクティブで、T0、T2、T4 ではアイドルです。総コストを計算するには、次の式を使用します。( T0 + T2 + T4 ) × アイドル GPU の単価 + ( T1 + T3 ) × アクティブ GPU の単価。アイドル GPU とアクティブ GPU の単価の詳細については、「課金の概要」をご参照ください。
仕組み
Function Compute は、高度な Alibaba Cloud テクノロジーに基づいて、GPU アクセラレーションインスタンスのインスタントフリーズと復元を実装しています。GPU アクセラレーションインスタンスがリクエストを処理していない場合、Function Compute は自動的にインスタンスをフリーズし、アイドル GPU 単価に基づいて課金します。このメカニズムは、リソース使用率を最適化し、コストを最小限に抑えます。新しい推論リクエストが到着すると、Function Compute はインスタンスをアクティブ化してリクエストをシームレスに実行します。この場合、アクティブ GPU 単価に基づいて課金されます。
このプロセスはユーザーにとって完全に透過的であり、ユーザーエクスペリエンスに影響を与えません。同時に、Function Compute は、インスタンスがフリーズされている場合でも、推論サービスの揺るぎない精度と信頼性を確保し、ユーザーに安定した費用対効果の高い計算能力を提供します。
アイドル状態の GPU アクセラレーションインスタンスのアクティブ化時間
アイドル状態の GPU アクセラレーションインスタンスのアクティブ化時間は、ワークロードによって異なります。次の表に、一般的な推論シナリオでの時間を示します。
推論ワークロードタイプ | アクティブ化時間 ( 秒 ) |
OCR / NLP | 0.5 ~ 1 |
Stable Diffusion | 2 |
LLM | 3 |
アクティブ化時間はモデルサイズによって異なります。実際時間は異なります。
使用上の注意
CUDA バージョン
CUDA 12.2 以前のバージョンを使用することをお勧めします。
イメージ権限
コンテナイメージはデフォルトの root ユーザーとして実行することをお勧めします。
インスタンスログイン
GPU がフリーズされているため、アイドル状態の GPU アクセラレーションインスタンスにログインすることはできません。
グレースフルインスタンスローテーション
Function Compute は、ワークロードに基づいてアイドル状態の GPU アクセラレーションインスタンスをローテーションします。サービス品質を確保するために、モデルのウォームアップと事前推論のために、関数インスタンスにライフサイクルフックを追加することをお勧めします。これにより、新しいインスタンスの起動直後に推論サービスを提供できます。詳細については、「モデルのウォームアップ」をご参照ください。
モデルのウォームアップと事前推論
アイドル状態の GPU アクセラレーションインスタンスの初期ウェイクアップのレイテンシを削減するために、コードで
initializeフックを使用して、モデルをウォームアップまたはプリロードすることをお勧めします。詳細については、「モデルのウォームアップ」をご参照ください。プロビジョニングされたインスタンス構成
[アイドルモード] スイッチをオンにすると、関数の既存のプロビジョニングされた GPU アクセラレーションインスタンスは正常にシャットダウンされます。プロビジョニングされたインスタンスは、短期間解放された後に再割り当てされます。
推論フレームワークの組み込みメトリックサーバー
アイドル GPU の互換性とパフォーマンスを向上させるために、NVIDIA Triton Inference Server や TorchServe などの推論フレームワークの組み込みメトリックサーバーを無効にすることをお勧めします。
GPU アクセラレーションインスタンスの仕様
アイドルモードをサポートするのは、フルサイズの GPU で構成された関数のみです。GPU アクセラレーションインスタンスの仕様の詳細については、「インスタンスの仕様」をご参照ください。
推論シナリオ向けに最適化されたリクエストスケジューリングメカニズム
仕組み
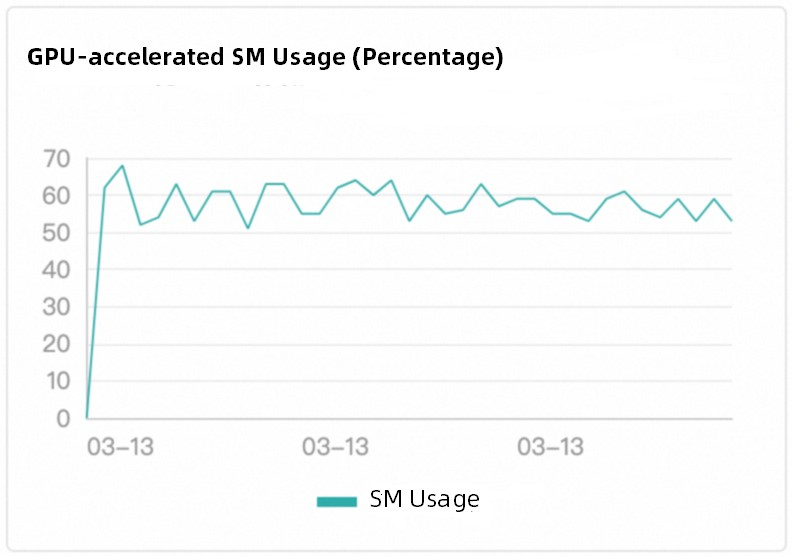
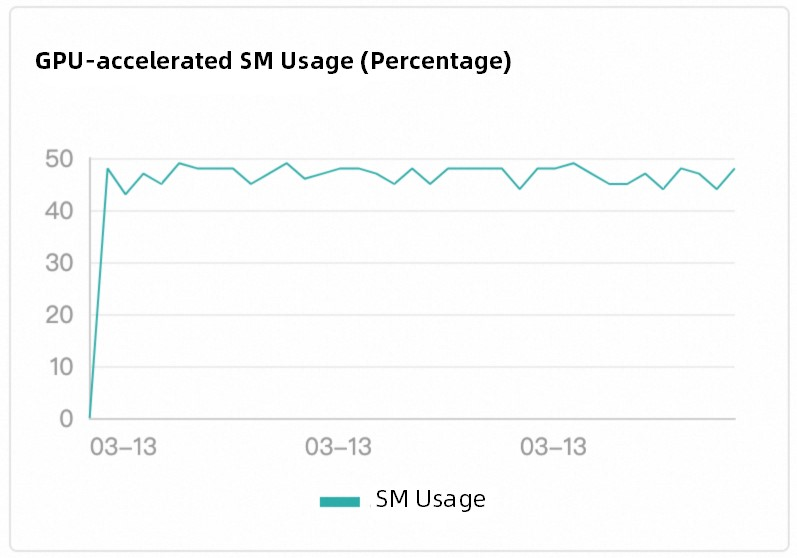
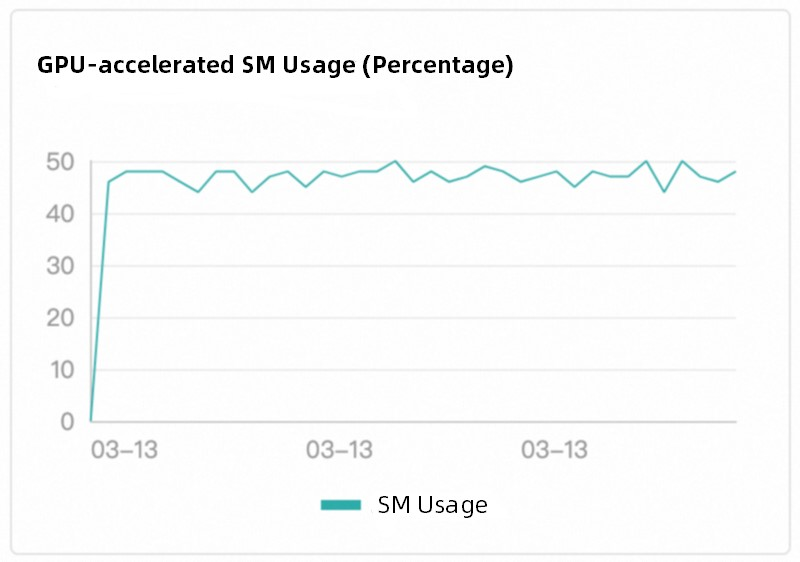
Function Compute は、ワークロードベースのインテリジェントスケジューリングを採用しています。これは、従来のラウンドロビンスケジューリングメソッドよりもはるかに優れた戦略です。プラットフォームは、GPU アクセラレーションインスタンスのタスク実行状態をリアルタイムで監視し、インスタンスがアイドル状態になると、すぐに新しいリクエストを実行中の GPU アクセラレーションインスタンスに送信します。このメカニズムにより、GPU リソースの効率的な使用が保証され、リソースの浪費とホットスポットが削減されます。また、GPU アクセラレーションインスタンスの負荷分散が GPU 計算能力の使用率と一致していることも保証されます。次の図は、Tesla T4 GPU が使用されている例を示しています。
スケジューリング効果
Function Compute の組み込みスケジューリングロジックは、異なる GPU アクセラレーションインスタンス間の負荷分散を実装します。スケジューリングはユーザーには認識できません。
インスタンス 1 | インスタンス 2 | インスタンス 3 |
|
|
|
コンテナのサポート
Function Compute の GPU アクセラレーションインスタンスは、カスタムコンテナランタイムでのみ使用できます。カスタムコンテナランタイムの詳細については、「カスタムコンテナの概要」をご参照ください。
カスタムコンテナ関数は、異なるコードパスを実行し、イベントまたは HTTP リクエストを介して関数をトリガーするために、イメージ内に搭載された Web サーバーを必要とします。Web サーバーモードは、AI 学習や推論などのマルチパスリクエスト実行シナリオに適しています。
デプロイ方法
次のいずれかの方法を使用して、Function Compute にモデルをデプロイできます。
Function Compute コンソールを使用します。詳細については、「Function Compute コンソールで関数の作成」をご参照ください。
SDK を呼び出します。詳細については、「関数別の操作リスト」をご参照ください。
Serverless Devs を使用します。詳細については、「Serverless Devs の一般的なコマンド」をご参照ください。
デプロイの例については、「start-fc-gpu」をご参照ください。
モデルのウォームアップ
モデルの起動後の初期リクエストの処理時間が長いという問題に対処するために、Function Compute はモデルウォームアップ機能を提供します。この機能により、モデルは起動直後に動作状態に入ることができます。
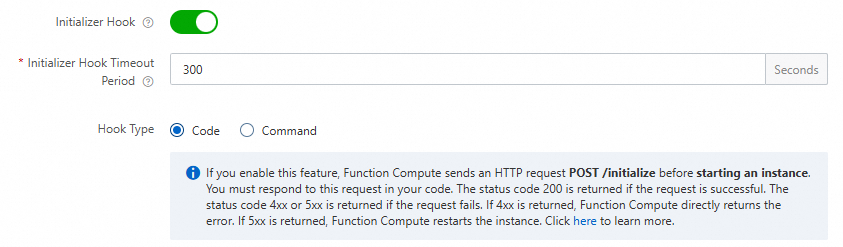
Function Compute で initialize ライフサイクルフックを構成することをお勧めします。Function Compute は、フック内のビジネスロジックを自動的に実行して、モデルをウォームアップします。 詳細については、「関数インスタンスのライフサイクルフック」をご参照ください。
構築する HTTP サーバーに POST メソッドの
/initialize呼び出しパスを追加し、/initializeパスの下にモデルウォームアップロジックを配置します。モデルに簡単な推論を実行させて、ウォームアップ効果を得ることができます。次のサンプルコードは、Python の例を示しています。
def prewarm_inference(): res = model.inference() @app.route('/initialize', methods=['POST']) def initialize(): request_id = request.headers.get("x-fc-request-id", "") print("FC Initialize Start RequestId: " + request_id) # Prewarm model and perform naive inference task. prewarm_inference() print("FC Initialize End RequestId: " + request_id) return "Function is initialized, request_id: " + request_id + "\n"[関数の詳細] ページで、 を選択し、[変更] をクリックしてライフサイクルフックを構成します。
リアルタイム推論シナリオでの自動スケーリングの構成
Serverless Devs の使用
前提条件
GPU アクセラレーションインスタンスが存在するリージョンで、次の操作が完了していることを確認します。
Container Registry Enterprise Edition インスタンスまたは Personal Edition インスタンスが作成されます。Container Registry Enterprise Edition インスタンスを作成することをお勧めします。詳細については、「Container Registry Enterprise Edition インスタンスへのイメージのプッシュとインスタンスからのイメージのプル」をご参照ください。
名前空間とイメージリポジトリが作成されます。詳細については、「Container Registry Enterprise Edition インスタンスへのイメージのプッシュとインスタンスからのイメージのプル」および「Container Registry Enterprise Edition インスタンスを使用したイメージの構築」をご参照ください。
Serverless Devs がインストールされています。詳細については、「クイックスタート」をご参照ください。
Serverless Devs が構成されています。詳細については、「Serverless Devs の構成」をご参照ください。
1. 関数のデプロイ
次のコマンドを実行して、プロジェクトをクローンします。
git clone https://github.com/devsapp/start-fc-gpu.git次のコマンドを実行して、プロジェクトのディレクトリに移動します。
cd /root/start-fc-gpu/fc-http-gpu-inference-paddlehub-nlp-porn-detection-lstm/src/次のコードスニペットは、プロジェクトの構造を示しています。
. ├── hook │ └── index.js └── src ├── code │ ├── Dockerfile │ ├── app.py │ ├── hub_home │ │ ├── conf │ │ ├── modules │ │ └── tmp │ └── test │ └── client.py └── s.yaml次のコマンドを実行して、Docker を使用してイメージを構築し、イメージをイメージリポジトリにプッシュします。
export IMAGE_NAME="registry.cn-shanghai.aliyuncs.com/fc-gpu-demo/paddle-porn-detection:v1" # sudo docker build -f ./code/Dockerfile -t $IMAGE_NAME . # sudo docker push $IMAGE_NAME重要PaddlePaddle フレームワークのサイズは大きく、初めてイメージを構築するには約 1 時間かかります。Function Compute は、直接使用できる VPC ベースのパブリックイメージを提供します。パブリックイメージを使用する場合は、上記の docker build コマンドまたは docker push コマンドを実行する必要はありません。
s.yaml ファイルを編集します。
edition: 3.0.0 name: container-demo access: default vars: region: cn-shanghai resources: gpu-best-practive: component: fc3 props: region: ${vars.region} description: これはデモ関数のデプロイです handler: not-used timeout: 1200 memorySize: 8192 cpu: 2 gpuMemorySize: 8192 diskSize: 512 instanceConcurrency: 1 runtime: custom-container environmentVariables: FCGPU_RUNTIME_SHMSIZE: '8589934592' customContainerConfig: image: >- registry.cn-shanghai.aliyuncs.com/serverless_devs/gpu-console-supervising:paddle-porn-detection port: 9000 internetAccess: true logConfig: enableRequestMetrics: true enableInstanceMetrics: true logBeginRule: DefaultRegex project: z**** logstore: log**** functionName: gpu-porn-detection gpuConfig: gpuMemorySize: 8192 gpuType: fc.gpu.tesla.1 triggers: - triggerName: httpTrigger triggerType: http triggerConfig: authType: anonymous methods: - GET - POST次のコマンドを実行して、関数をデプロイします。
sudo s deploy --skip-push true -t s.yaml実行後、出力に URL が返されます。後続のテストのために、この URL をコピーします。URL の例:
https://gpu-poretection-****.cn-shanghai.fcapp.run。
2. 関数のテストと監視データの表示
curl コマンドを実行して関数を呼び出します。次のコードスニペットは例を示しています。前の手順で取得した URL がこのコマンドで使用されます。
curl https://gpu-poretection-gpu-****.cn-shanghai.fcapp.run/invoke -H "Content-Type: text/plain" --data "Nice to meet you"次の出力が返された場合、テストは成功です。
[{"text": "Nice to meet you", "porn_detection_label": 0, "porn_detection_key": "not_porn", "porn_probs": 0.0, "not_porn_probs": 1.0}]%Function Compute コンソール にログインします。左側のナビゲーションウィンドウで、[関数] をクリックします。リージョンを選択します。管理する関数を見つけて、関数名をクリックします。[関数の詳細] ページで、 を選択して、GPU 関連のメトリックの変更を表示します。
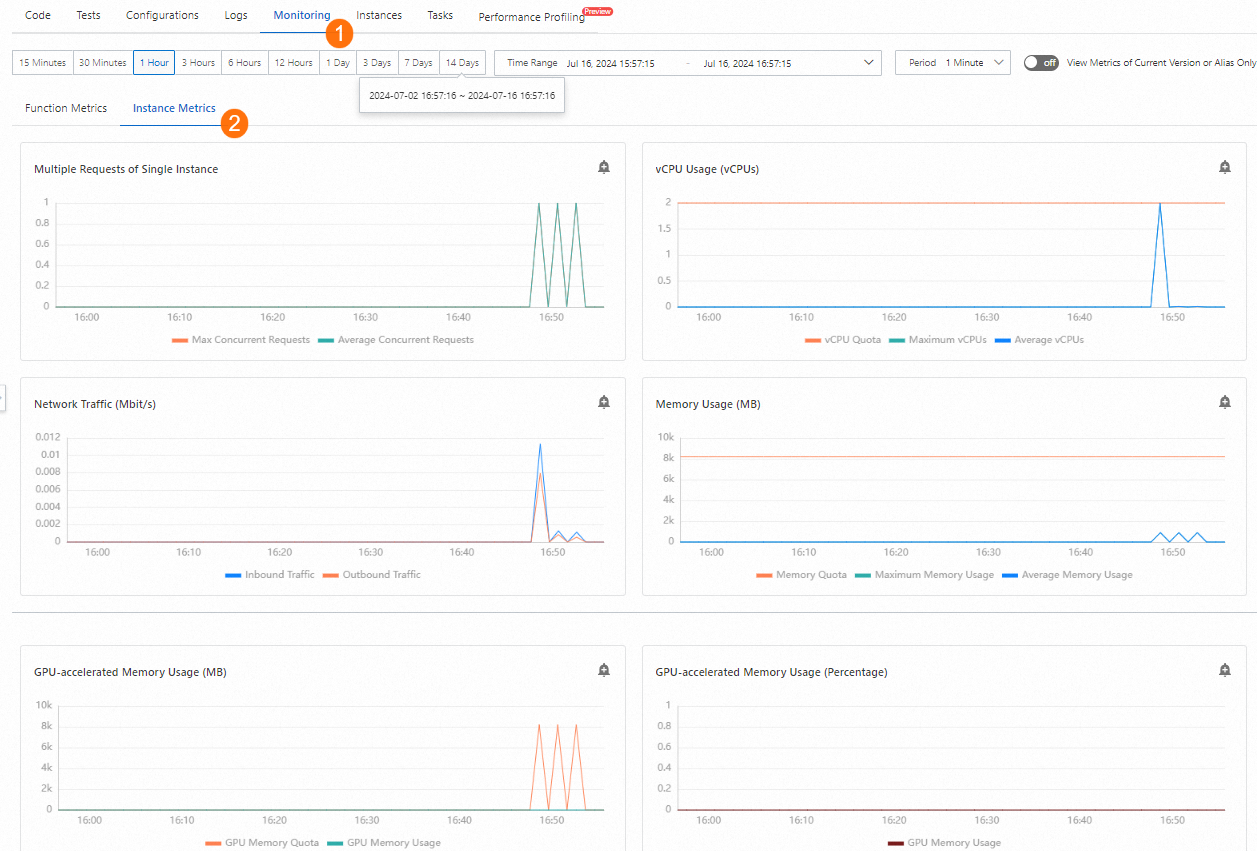
3. 自動スケーリングポリシーの構成
s.yaml ファイルがあるディレクトリに、provision.json テンプレートを作成します。
次のサンプルコードは、テンプレートの例を示しています。このテンプレートは、追跡メトリックとしてインスタンスの同時実行性を使用します。インスタンスの最小数は 2 で、インスタンスの最大数は 30 です。
{ "targetTrackingPolicies": [ { "name": "scaling-policy-demo", "startTime": "2024-07-01T16:00:00.000Z", "endTime": "2024-07-30T16:00:00.000Z", "metricType": "ProvisionedConcurrencyUtilization", "metricTarget": 0.3, "minCapacity": 2, "maxCapacity": 30 } ] }次のコマンドを実行して、スケーリングポリシーをデプロイします。
sudo s provision put --target 1 --targetTrackingPolicies ./provision.json --qualifier LATEST -t s.yaml -a {access}検証のために
sudo s provision listコマンドを実行します。出力では、targetとcurrentの値が同じです。これは、プロビジョニングされたインスタンスが期待どおりに割り当てられ、自動スケーリングポリシーが正しくデプロイされていることを意味します。[2023-05-10 14:49:03] [INFO] [FC] - Getting list provision: gpu-best-practive-service gpu-best-practive: - serviceName: gpu-best-practive-service qualifier: LATEST functionName: gpu-porn-detection resource: 143199913651****#gpu-best-practive-service#LATEST#gpu-porn-detection target: 1 current: 1 scheduledActions: null targetTrackingPolicies: - name: scaling-policy-demo startTime: 2024-07-01T16:00:00.000Z endTime: 2024-07-30T16:00:00.000Z metricType: ProvisionedConcurrencyUtilization metricTarget: 0.3 minCapacity: 2 maxCapacity: 30 currentError: alwaysAllocateCPU: trueプロビジョニングされたインスタンスが作成されると、モデルは正常にデプロイされ、使用できる状態になります。
関数のプロビジョニングされたインスタンスを解放します。
次のコマンドを実行して、自動スケーリングポリシーを無効にし、プロビジョニングされたインスタンスの数を 0 に設定します。
sudo s provision put --target 0 --qualifier LATEST -t s.yaml -a {access}次のコマンドを実行して、自動スケーリングポリシーが無効になっているかどうかを確認します。
s provision list -a {access}次の出力が返された場合、自動スケーリングポリシーは無効になっています。
[2023-05-10 14:54:46] [INFO] [FC] - Getting list provision: gpu-best-practive-service End of method: provision
Function Compute コンソールの使用
前提条件
GPU 関数が作成されます。詳細については、「カスタムコンテナ関数の作成」をご参照ください。
手順
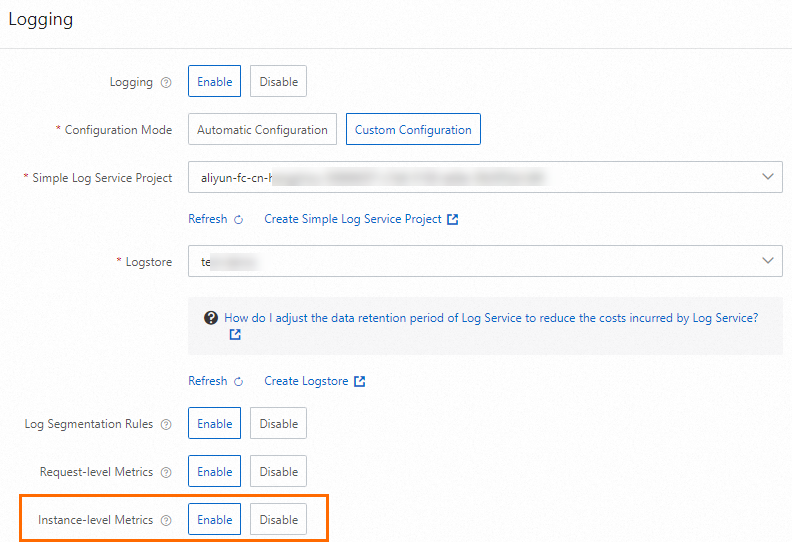
Function Compute コンソール にログインします。左側のナビゲーションウィンドウで、[関数] をクリックします。上部のナビゲーションバーで、リージョンを選択します。表示されるページで、管理する関数を見つけます。関数の構成で、関数のインスタンスレベルメトリックを有効にします。
[関数の詳細] ページで、 を選択して、後続のテストのために HTTP トリガーの URL を取得します。
curl コマンドを実行して関数をテストします。[関数の詳細] ページで、 を選択して、GPU 関連のメトリックの変更を表示します。
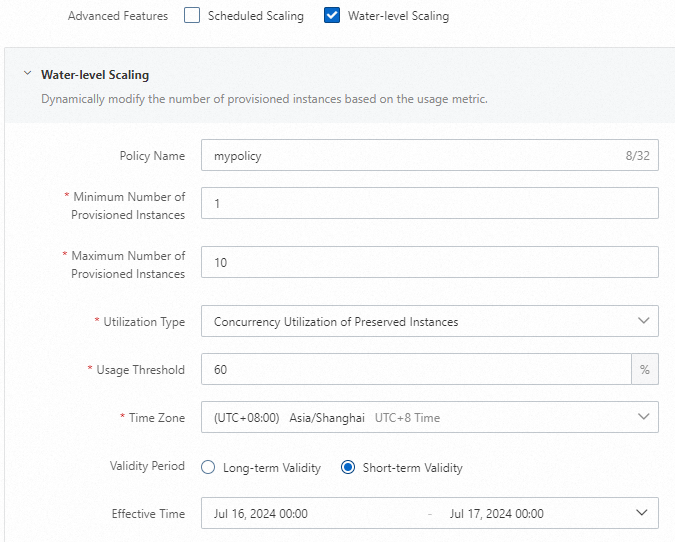
curl https://gpu-poretection****.cn-shanghai.fcapp.run/invoke -H "Content-Type: text/plain" --data "Nice to meet you"[関数の詳細] ページで、 を選択します。次に、[プロビジョニングされたインスタンスポリシーの作成] をクリックして、自動スケーリングポリシーを構成します。
構成が完了したら、[関数の詳細] ページで を選択して、プロビジョニングされたインスタンスの変更を表示できます。
プロビジョニングされた GPU アクセラレーションインスタンスが不要になった場合は、できるだけ早く削除してください。
よくある質問
Function Compute でリアルタイム推論サービスを使用するための課金方法
Function Compute の課金については、「課金の概要」をご参照ください。プロビジョニングされたインスタンスの課金方法は、オンデマンドインスタンスの課金方法とは異なります。請求の詳細にご注意ください。
自動スケーリングポリシーを構成した後もレイテンシが発生するのはなぜですか?
より積極的な自動スケーリングポリシーを使用してノードを事前にプロビジョニングすることで、リクエストの急激なバーストによるパフォーマンスの低下を防ぐことができます。
追跡メトリックがしきい値に達してもインスタンス数が増加しないのはなぜですか?
Function Compute のメトリックは分単位で収集されます。スケールアウトメカニズムは、メトリック値が一定期間しきい値を超えた場合にのみトリガーされます。