このトピックでは、ComfyUI + SD/FLUX イメージと Function Compute の GPU 関数機能を使用して、テキストから画像への変換サービスを迅速に構築する方法について説明します。
ソリューションの概要
Alibaba Cloud Function Compute を使用して、テキストから画像への変換サービスを 2 つのステップで迅速に構築できます。
パブリックイメージを選択するか、カスタムイメージをビルドしてプッシュします。
パブリック ComfyUI + SD/FLUX イメージを使用するか、カスタムイメージをビルドして Alibaba Cloud Container Registry のイメージリポジトリにプッシュできます。
GPU 関数を作成します。
イメージに基づいて、Alibaba Cloud Function Compute で GPU 関数を作成します。関数が作成されると、システムはテキストから画像への変換サービスのエンドポイントとして機能するドメイン名を提供します。
これらのステップを完了すると、テキストから画像への変換サービスがデプロイされます。ユーザーはインターネットまたは内部ネットワークを介してサービスにアクセスできます。ブラウザから関数にアクセスするには、関数に カスタムドメイン名を設定する必要があります。
ステップ 1: Alibaba Cloud による text-to-image サービスの構築: Function Compute
イメージの構築と高速化
パブリックイメージ: 既存のパブリック ComfyUI + SD/FLUX イメージを使用して、迅速かつ簡単にセットアップできます。
カスタムイメージ: 特定のニーズに合わせてカスタムイメージを構築し、ユーザーエクスペリエンスとパフォーマンスを最適化できます。
Dockerfile を準備する
イメージをビルドする際は、ComfyUI プロジェクトの README.md ファイルのインストール手順に従ってください。 ComfyUI は Python に依存しているため、ベースイメージとして適切な Python イメージを選択してください。Docker Hub などのパブリックイメージリポジトリから Python イメージを取得できます。次のコードは、カスタムイメージのサンプルです。
# Dockerfile FROM python:3.10 # システム依存関係をインストールする RUN apt-get update && apt-get install -y \ git \ wget \ && rm -rf /var/lib/apt/lists/* WORKDIR /app # ComfyUI リポジトリのクローンを作成する RUN git clone https://github.com/comfyanonymous/ComfyUI.git WORKDIR /app/ComfyUI # Python 依存関係パッケージのダウンロードを高速化する RUN pip config set global.index-url https://mirrors.cloud.aliyuncs.com/pypi/simple RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple RUN pip config set install.trusted-host mirrors.cloud.aliyuncs.com # PyTorch をインストールする (デフォルトでは NVIDIA CUDA バージョン。必要に応じて変更してください) RUN pip install torch==2.5.0+cu124 torchvision==0.20.0+cu124 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu124 # プロジェクトの依存関係をインストールする RUN pip install -r requirements.txt # サービスポートを公開する EXPOSE 8188 # 起動コマンド CMD ["python", "main.py"]イメージのダウンロードを高速化する
パブリックイメージリポジトリへのアクセスが遅い場合は、Docker の registry-mirrors を設定してダウンロード速度を向上させることができます。たとえば、Linux システムでは、/etc/docker/daemon.json ファイルを編集し、次の設定を追加または変更します。
{ ...... "registry-mirrors": [ "https://docker.nju.edu.cn", "https://dockerproxy.com", "https://docker.mirrors.ustc.edu.cn", ...... ] }ファイルを再読み込みし、Docker を再起動して変更を有効にします。
systemctl daemon-reload # 設定ファイルを再読み込みします。 systemctl restart docker # Docker サービスを再起動します。
または、頻繁に使用するベースイメージを独自のイメージリポジトリに保存するか、プライベート registry-mirror をセットアップすることもできます。
Python 依存関係パッケージのダウンロードを高速化する
ComfyUI プロジェクト の README.md ファイルに従ってパッケージをインストールする際に、Python 依存関係パッケージのダウンロードが遅い場合は、pip の
index-urlを設定してプロセスを高速化できます。たとえば、Alibaba Cloud または清華大学の Python ミラーソースを使用できます。...... RUN pip config set global.index-url https://mirrors.cloud.aliyuncs.com/pypi/simple RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple RUN pip config set install.trusted-host mirrors.cloud.aliyuncs.com ......イメージをビルドする
docker build -t comfyui:latest .
イメージを Container Registry にプッシュする
Function Compute では、カスタムイメージを使用する関数を作成する場合、同じリージョンにある同じアカウント下の Alibaba Cloud Container Registry リポジトリのイメージを使用する必要があります。次のいずれかの方法でイメージを Container Registry にプッシュできます。
GPU 関数を作成する
Function Compute は、デフォルトですべての GPU 関数 に イメージの高速化 機能を提供します。この機能は、オンデマンドプルとピアツーピア (P2P) キャッシングをサポートしており、追加の設定は必要ありません。この機能を使用すると、大規模なイメージコンテナを迅速に作成し、弾力性を向上させることができます。詳細については、「GPU 関数を作成する」をご参照ください。Function Compute にはイメージサイズに制限があることに注意してください。イメージの作成時間が長くなるのを防ぐため、イメージに大きなモデルデータを含めないでください。イメージサイズの制限とクォータの増加をリクエストする方法の詳細については、「クォータと制限」をご参照ください。
次の例は、関数を作成するための起動コマンドとリスナーポートを示しています。
リスナーポート: 8188。注: リスナーポートは、ビルドされたイメージのポートと同じである必要があります。
起動コマンド: python main.py --listen 0.0.0.0

関数のカスタムドメイン名を設定する
Alibaba Cloud Function Compute が関数に提供するドメイン名は、主に API アクセスを目的としています。 ComfyUI 可視化インターフェイスを介してサービスを運用するには、関数に カスタムドメイン名を設定する必要があります。
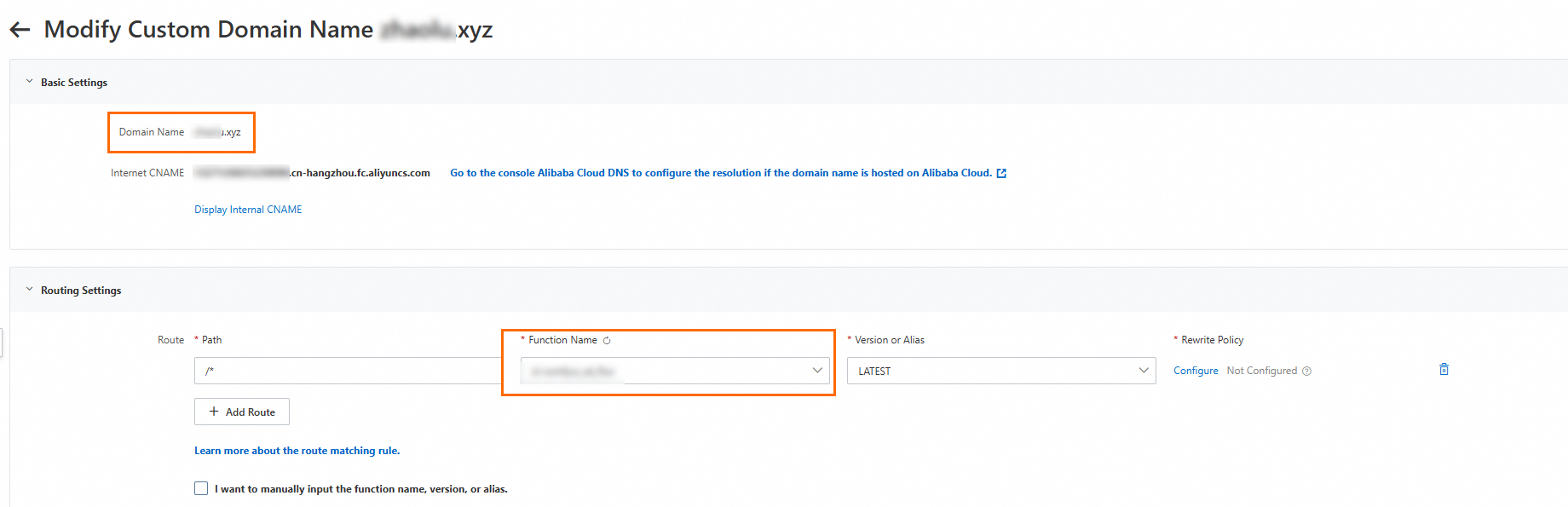
ブラウザで設定済みのカスタムドメイン名にアクセスして、ComfyUI インターフェイスを開きます。結果は次の図のようになります。
ステップ 2: モデルのダウンロードと高速化
Hugging Face、ModelScope、civitai などのコミュニティからモデルをダウンロードできます。 ModelScope コミュニティは、Black Forest Labs などの組織向けに多くのモデルとミラーを提供しています。Hugging Face へのネットワークアクセスが制限されている場合は、ModelScope ミラーソースを使用できます。
Function Compute では、モデルデータを NAS または OSS に保存することをお勧めします。Performance NAS インスタンスは、約 600 MB/s の初期帯域幅を提供します。OSS は帯域幅制限が高く、NAS よりも関数インスタンス間の帯域幅の競合が発生しにくいです。また、OSS アクセラレータを有効にして、スループットを向上させることもできます。詳細については、「AI シナリオにおける Function Compute GPU インスタンスでのモデルストレージのベストプラクティス」をご参照ください。
ModelScope のモデルライブラリで、Black Forest Labs を検索します。次の例は、FLUX.1-dev モデルをダウンロードする方法を示しています。
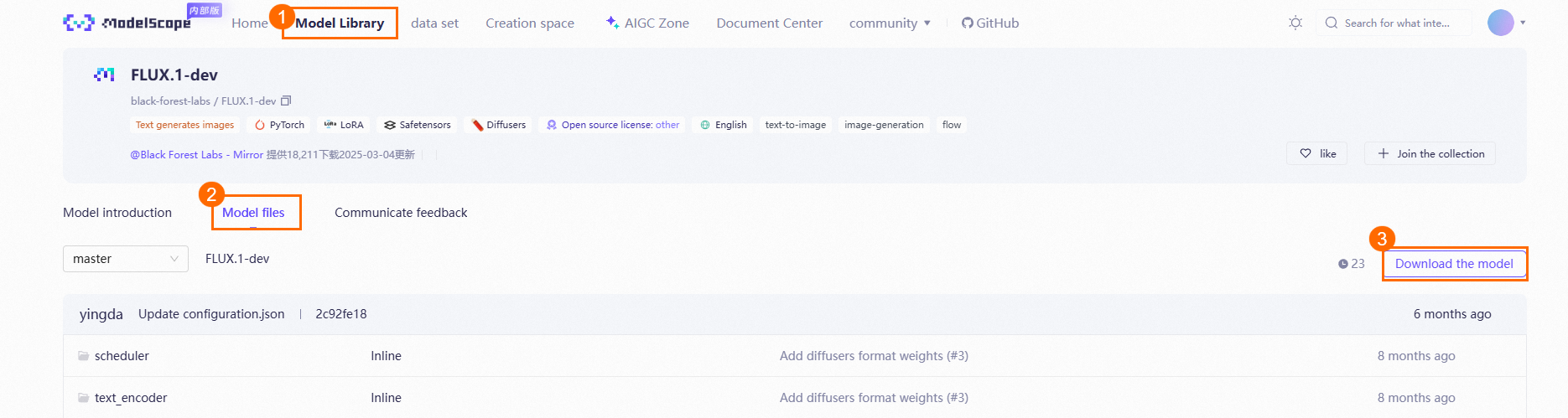
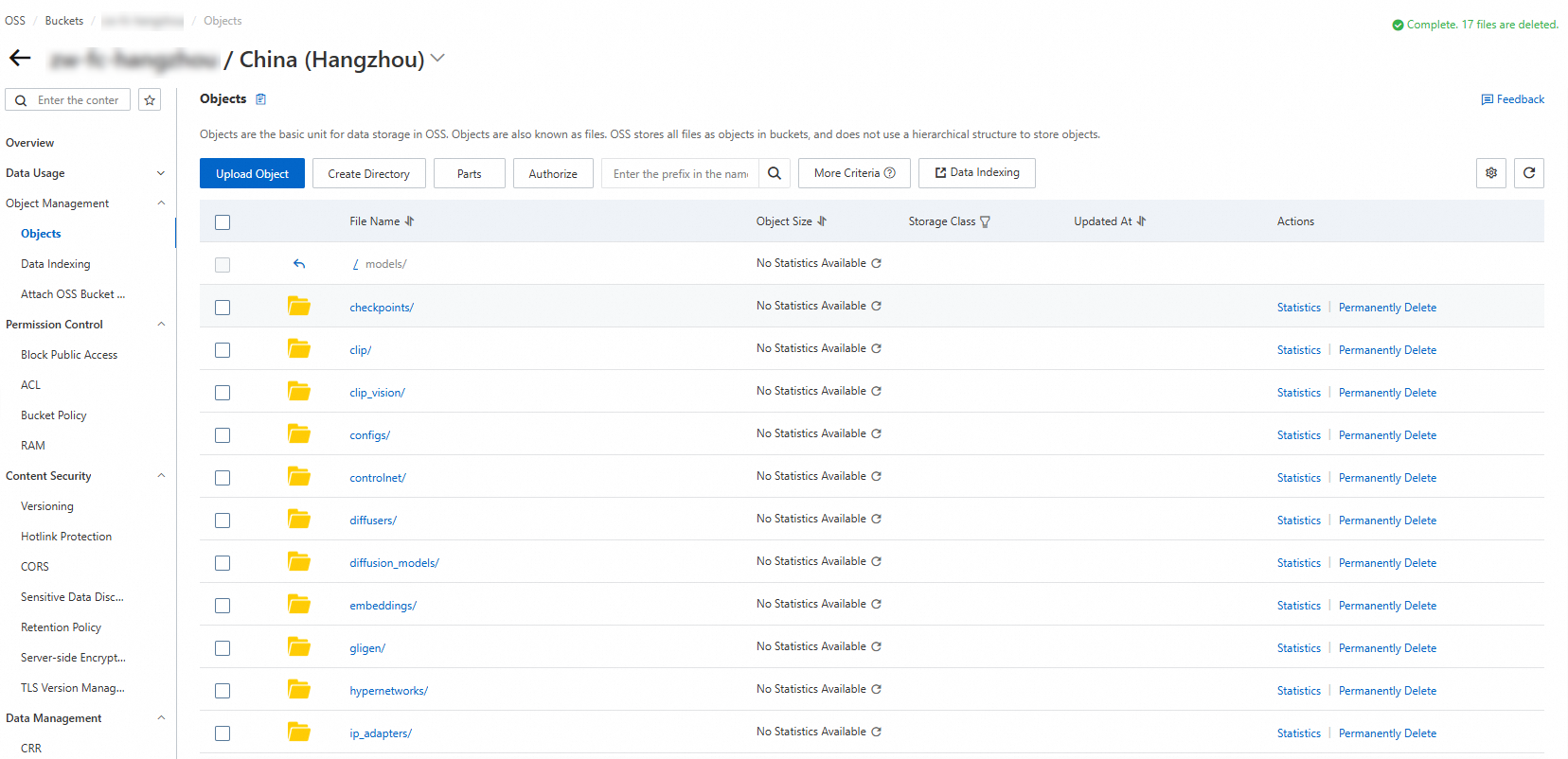
ダウンロードしたモデルを OSS にアップロードします。ダウンロードしたモデルを ComfyUI/models/ 下の指定されたフォルダに配置します。たとえば、
flux1-dev.safetensorsモデルをunetフォルダに配置します。次の例は、モデルパスを示しています。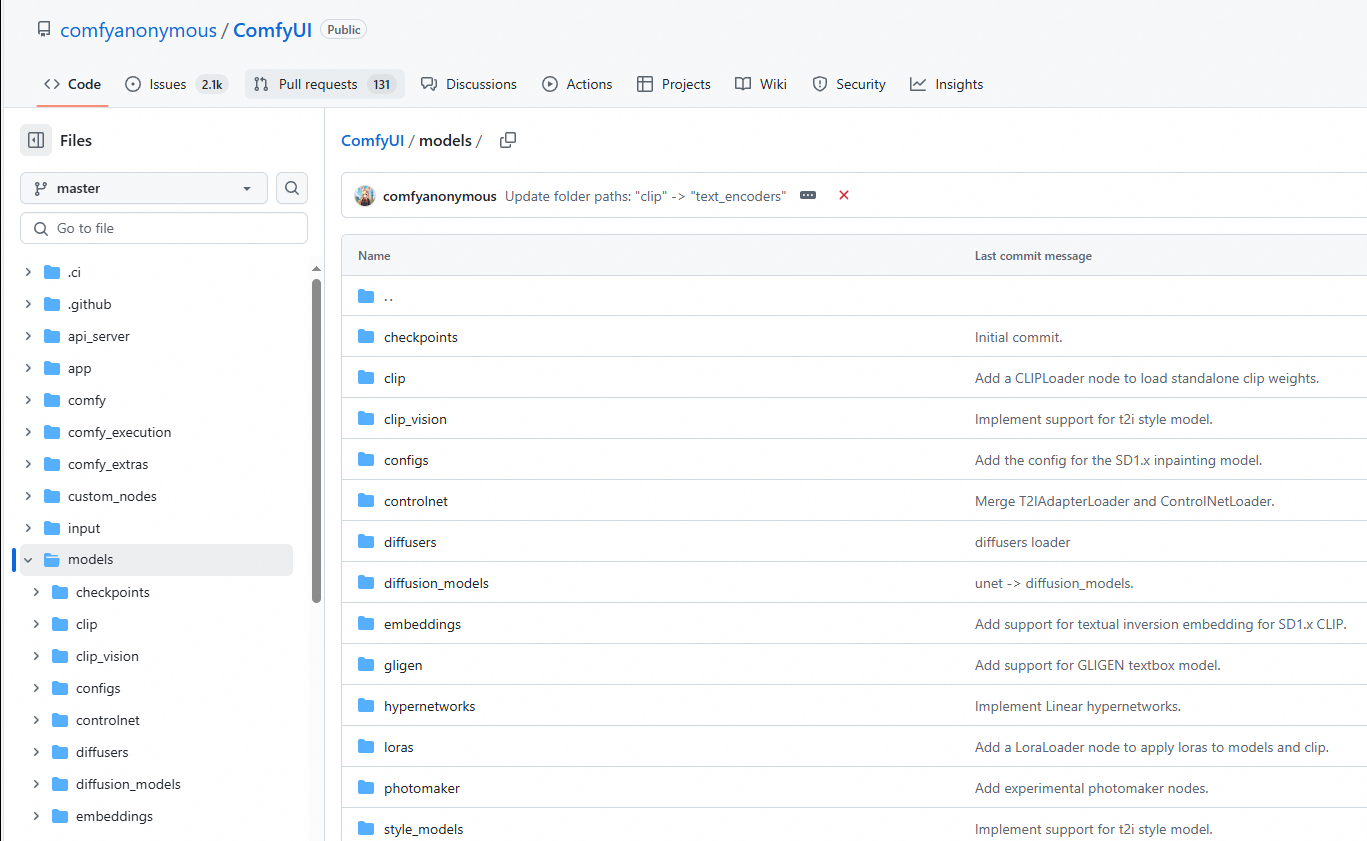
フォルダ名
ダウンロードしたモデル
checkpoints
dreamshaperXL_lightningDPMSDE.safetensors
clip
clip_l.safetensors
t5xxl_fp8_e4m3fn.safetensors
clip_vision
clip_vision_g.safetensors
clip_vision_l.safetensors
controlnet
flux-canny-controlnet-v3.safetensors
loras
FLUX1_wukong_lora.safetensors
araminta_k_flux_koda.safetensors
unet
flux1-dev.safetensors
vae
ae.safetensors
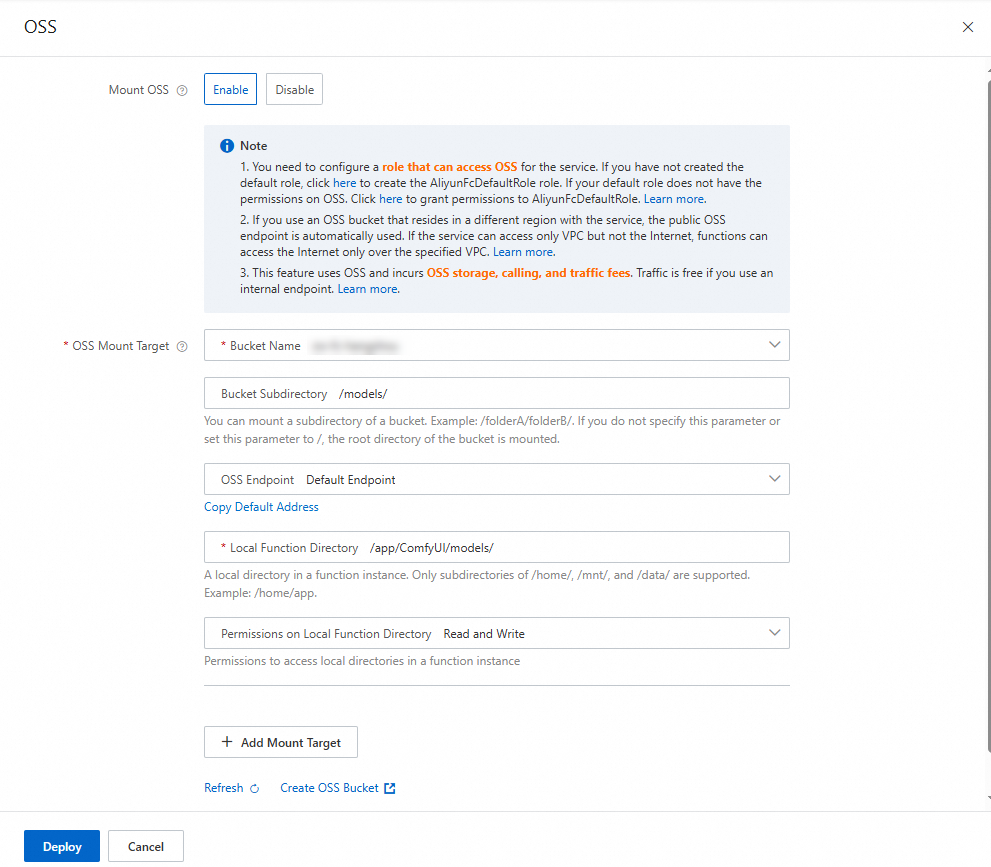
関数の詳細ページで、[構成] タブをクリックします。左側のナビゲーションウィンドウで、[権限] タブをクリックし、関数に OSS へのアクセス権限を持つロールを設定します。次に、[ストレージ] タブをクリックします。[Object Storage Service (OSS)] セクションで、[編集] をクリックします。表示されるパネルでパラメータを設定し、[デプロイ] をクリックします。
デプロイメントが完了したら、関数インスタンスにログインし、モデルが関数のローカルディレクトリに正常にマウントされていることを確認します。

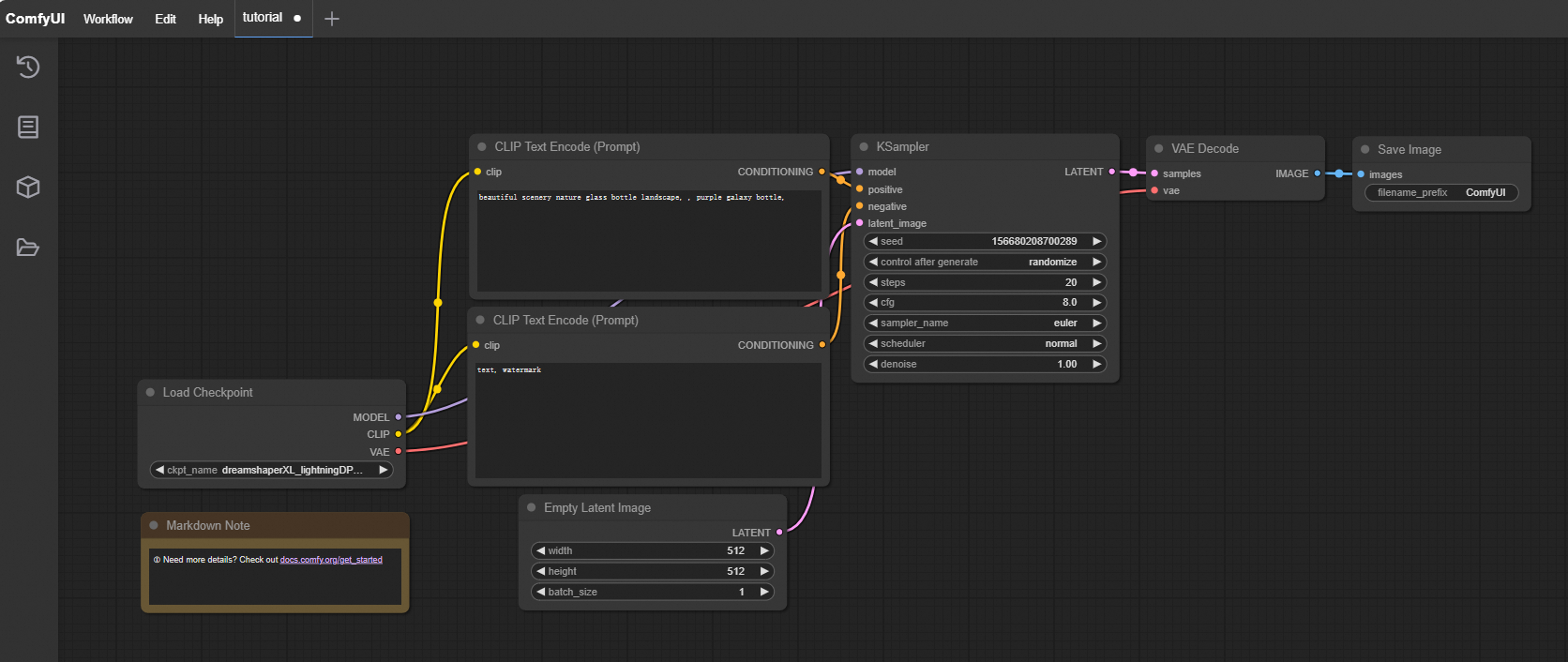
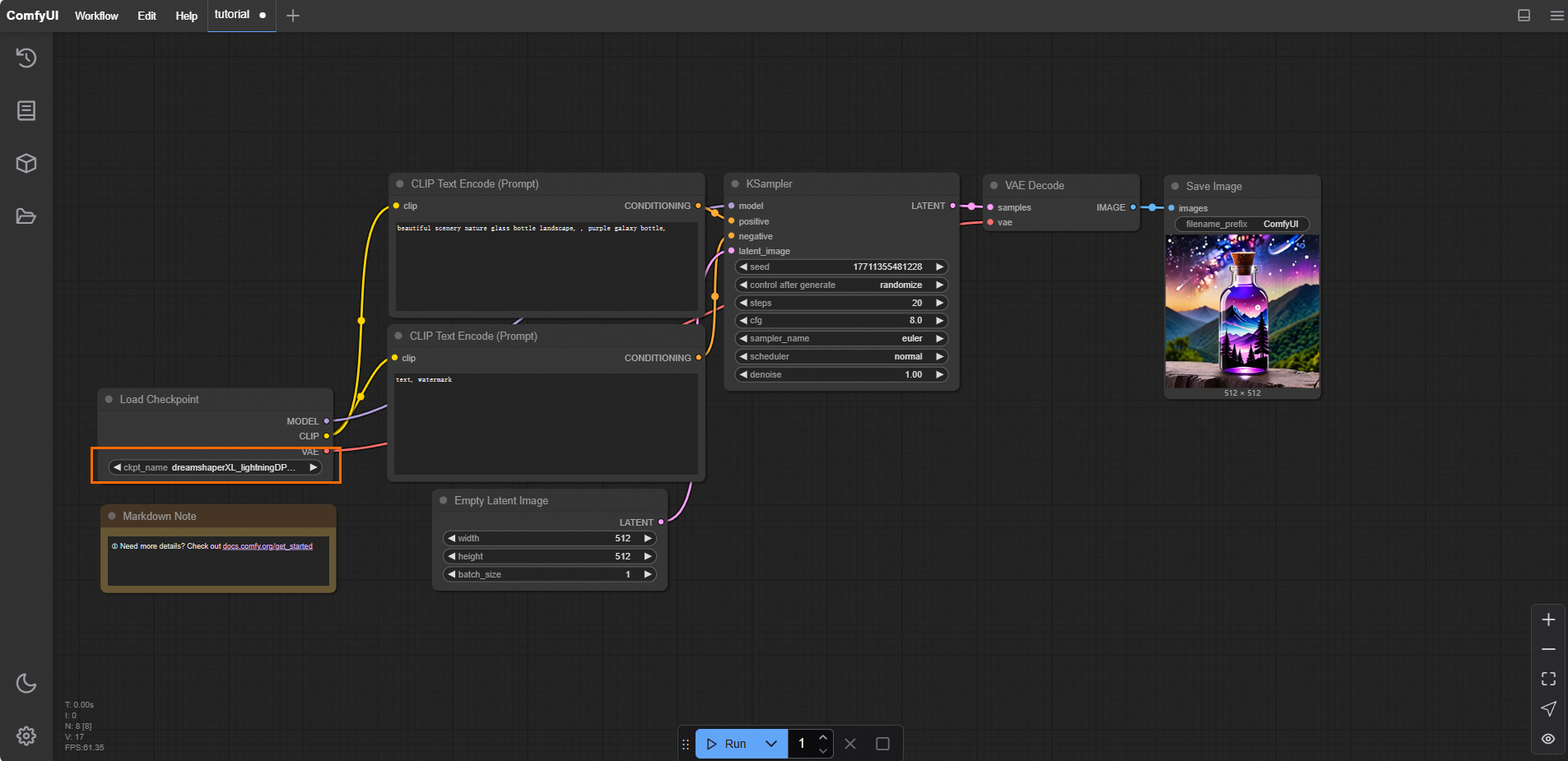
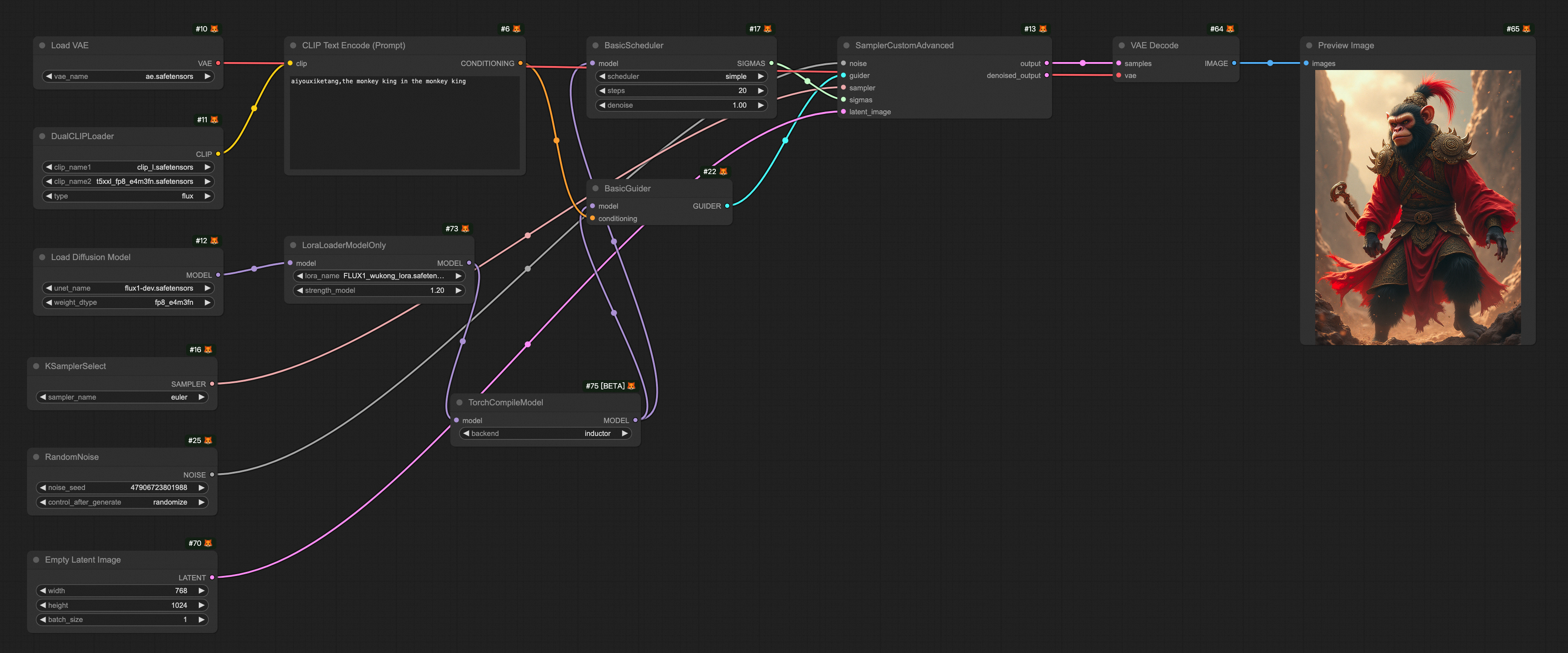
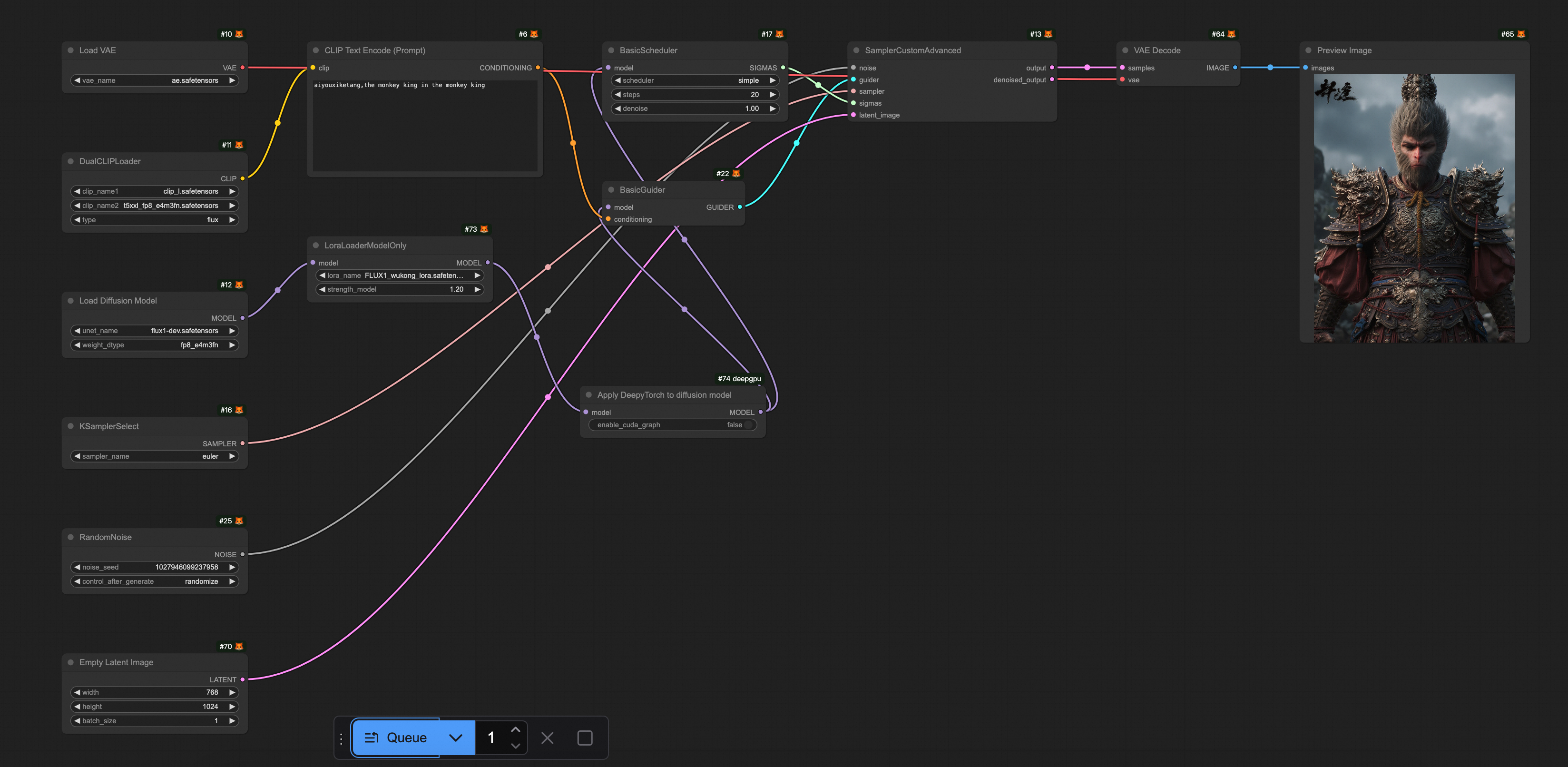
(オプション) ComfyUI を開きます。デフォルトのワークフローには、Checkpoint ローダーモデルが必要です。
dreamshaperXL_lightningDPMSDE.safetensorsなどの Checkpoint モデルも OSS の Checkpoint ファイルディレクトリにアップロードする必要があります。インスタンスにログインした後に表示されるパスは、次の図のようになります。

[実行] をクリックして、出力イメージを表示します。
事前に設定されたワークフローファイル FLUX-base.json をダウンロードします。ComfyUI を開き、 を選択し、ダウンロードした FLUX-base.json ファイルをインポートします。このワークフローは、
t5xxl_fp8_e4m3fn.safetensors、ae.safetensors、flux1-dev.safetensorsモデルを使用します。[実行] をクリックします。結果は次の図のようになります。
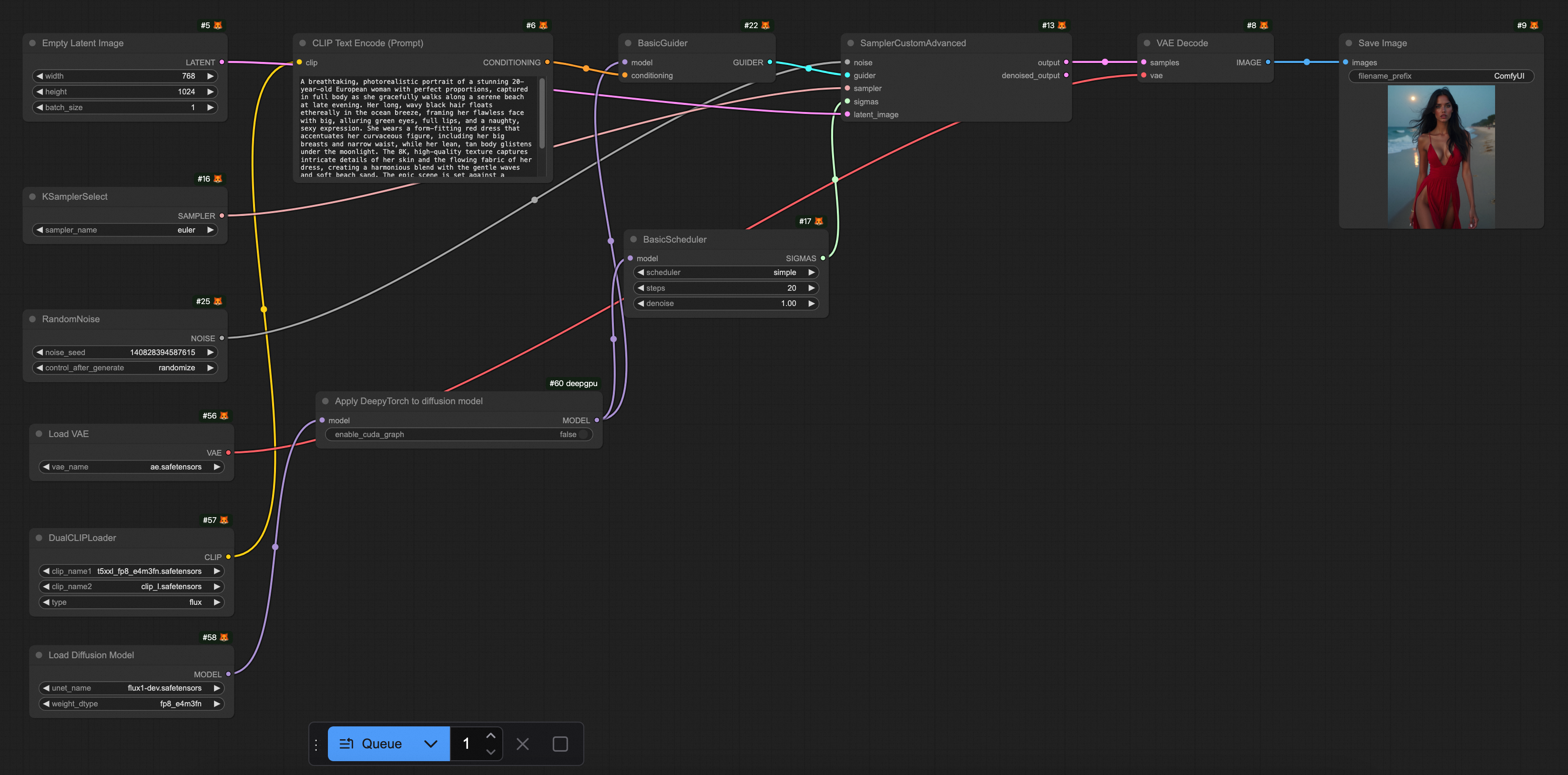
ステップ 3: 推論の高速化
テキストから画像への変換サービスの推論には、通常、数秒から数十秒かかります。推論の高速化は、応答時間を短縮し、ユーザーエクスペリエンスを向上させるだけでなく、リソースコストも削減します。次のセクションでは、2 つの推論高速化ソリューションについて説明します。
Alibaba Cloud DeepGPU Toolkit (DeepGPU)
DeepGPU Toolkit (DeepGPU) は、ComfyUI + SD/FLUX の推論高速化も提供します。DeepGPU Toolkit は、GPU コンピューティングサービスを強化する無料のツールセットです。迅速なビジネス展開、GPU 分分割、AI トレーニングと推論の最適化、人気のある AI モデル専用の高速化のためのツールが含まれています。現在、DeepGPU Toolkit の推論コンポーネントは、Alibaba Cloud Function Compute で無料で使用できます。これにより、ユーザーは Function Compute の GPU リソースをより便利かつ効率的に使用できます。
1. DeepGPU のインストール
DeepGPU を使用して ComfyUI + SD/FLUX の推論を高速化する前に、必要な依存関係パッケージをインストールする必要があります。
torch 2.5 をインストールする
RUN pip install torch==2.5.0deepgpu-torch をインストールする
DeepGPU torch モデル高速化パッケージは、FLUX.1 や VAE などのモデルを高速化します。
# ubuntu RUN apt-get update RUN apt-get install which curl iputils-ping -y # centos # RUN yum install which curl iputils -y # まず、torch をインストールします。deepgpu-torch は python3.10 と torch2.5.x+cu124 に依存しています (他のバージョンが必要な場合は、お問い合わせください)。 RUN pip install deepgpu-torch==0.0.15+torch2.5.0cu124 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/deepytorch/index.htmlダウンロードしたプラグインを custom_nodes/ ディレクトリに抽出します。
RUN wget https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/flux/20250102/ComfyUI-deepgpu.tar.gz RUN tar zxf ComfyUI-deepgpu.tar.gz -C /app/ComfyUI/custom_nodes RUN pip install deepgpu-comfyui==1.0.8 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/index.html
2. ComfyUI ソースコードの変更 (重要)
依存関係のバージョン
x-flux-comfyui を GitHub の最新バージョンに更新します。
ネイティブ LoRA のサポート
LoraLoaderModelOnly を使用してネイティブ ComfyUI LoRA モデルを読み込み、deepgpu-torch を使用して高速化する場合、ComfyUI ソースコードの 1 行を変更する必要があります。
ComfyUI のバージョンが v0.3.6 より前の場合
コードパス:
https://github.com/comfyanonymous/ComfyUI/blob/v0.3.6/comfy/sd.py#L779

この行にパラメータ
weight_inplace_update=Trueを追加します。return comfy.model_patcher.ModelPatcher(model, load_device=load_device, off load_device=offload_device, weight_inplace_update=True)ComfyUI のバージョンが v0.3.7 以後の場合
コードパス:https://github.com/comfyanonymous/ComfyUI/blob/v0.3.7/comfy/sd.py#L785
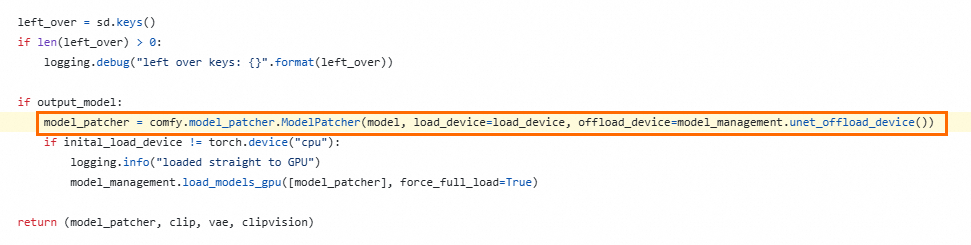
この行にパラメータ
weight_inplace_update=Trueを追加します。model_patcher = comfy.model_patcher.ModelPatcher(model, load_device=load_de vice, offload_device=model_management.unet_offload_device(), weight_inplace _update=True)
次のコードは、DeepGPU をインストールするためのサンプルイメージです。
# Dockerfile FROM python:3.10 # システム依存関係をインストールする RUN apt-get update && apt-get install -y \ git \ wget \ && rm -rf /var/lib/apt/lists/* WORKDIR /app # ComfyUI リポジトリのクローンを作成する RUN git clone https://github.com/comfyanonymous/ComfyUI.git WORKDIR /app/ComfyUI # Python 依存関係パッケージのダウンロードを高速化する RUN pip config set global.index-url https://mirrors.cloud.aliyuncs.com/pypi/simple RUN pip config set global.index-url https://pypi.tuna.tsinghua.edu.cn/simple RUN pip config set install.trusted-host mirrors.cloud.aliyuncs.com # PyTorch をインストールする (デフォルトでは NVIDIA CUDA バージョン。必要に応じて変更してください) RUN pip install torch==2.5.0+cu124 torchvision==0.20.0+cu124 torchaudio==2.5.0 --index-url https://download.pytorch.org/whl/cu124 # プロジェクトの依存関係をインストールする RUN pip install -r requirements.txt # ubuntu RUN apt-get update RUN apt-get install which curl iputils-ping -y # centos # RUN yum install which curl iputils -y # まず、torch をインストールします。deepgpu-torch は python3.10 と torch2.5.x+cu124 に依存しています (他のバージョンが必要な場合は、DeepGPU チームにお問い合わせください)。 RUN pip install deepgpu-torch==0.0.15+torch2.5.0cu124 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/deepytorch/index.html # プラグインをダウンロードした後、custom_nodes/ ディレクトリに抽出します。 RUN wget https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/flux/20250102/ComfyUI-deepgpu.tar.gz RUN tar zxf ComfyUI-deepgpu.tar.gz -C /app/ComfyUI/custom_nodes RUN pip install deepgpu-comfyui==1.0.8 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/index.html # サービスポートを公開する EXPOSE 8188 # 起動コマンド CMD ["python", "main.py"]
3. 環境変数の設定
Alibaba Cloud Function Compute で DeepGPU を使用する場合、DEEPGPU_PUB_LS=true および DEEPGPU_ENABLE_FLUX_LORA=true 環境変数を設定する必要があります。

4. (オプション) GPU アイドルモードを設定する
プロビジョニングされたインスタンスを設定することで、インスタンスのコールドスタートによるリクエストのレイテンシを削減できます。また、スケジュールされたスケーリングやメトリックベースのスケーリングなど、プロビジョニングされたインスタンスのスケーリングルールを設定して、インスタンスの利用率を向上させ、リソースの浪費を防ぐこともできます。
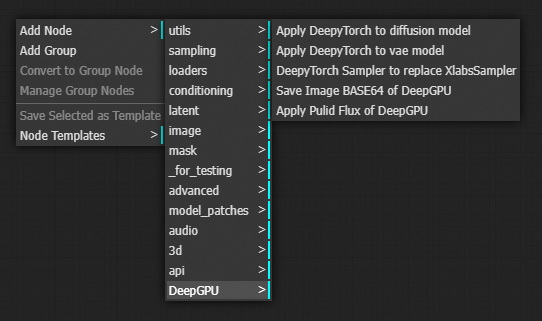
5. DeepGPU ComfyUI プラグインの使用方法
プラグインには、4 種類の DeepGPUノードが含まれています。ComfyUI インターフェイスの検索ボックスに DeepyTorch と入力することで見つけることができます。
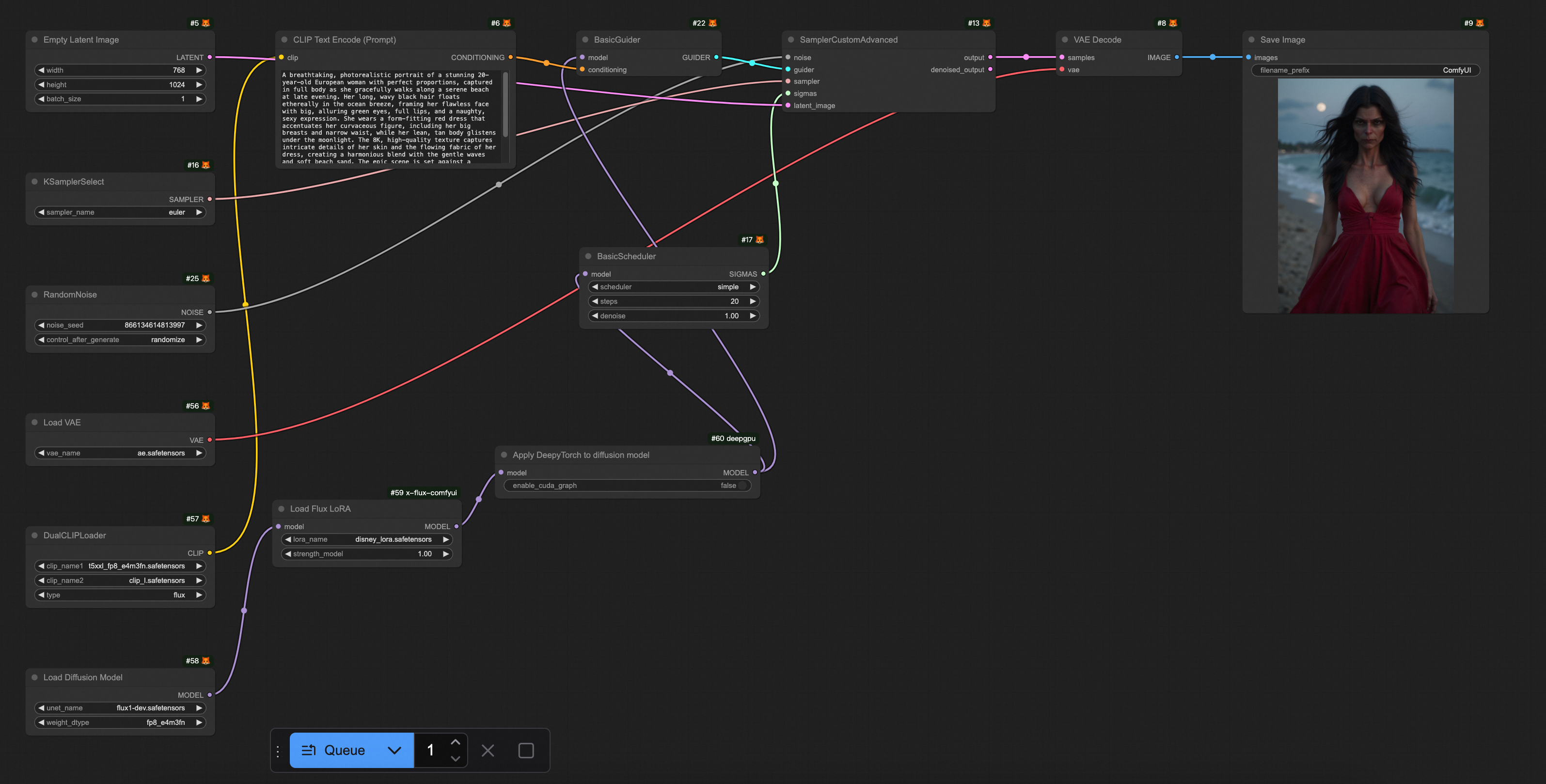
拡散モデルに DeepyTorch を適用する
vae モデルに DeepyTorch を適用する
DeepTorch Sampler を使用して XlabsSampler を置き換える
使用ガイド
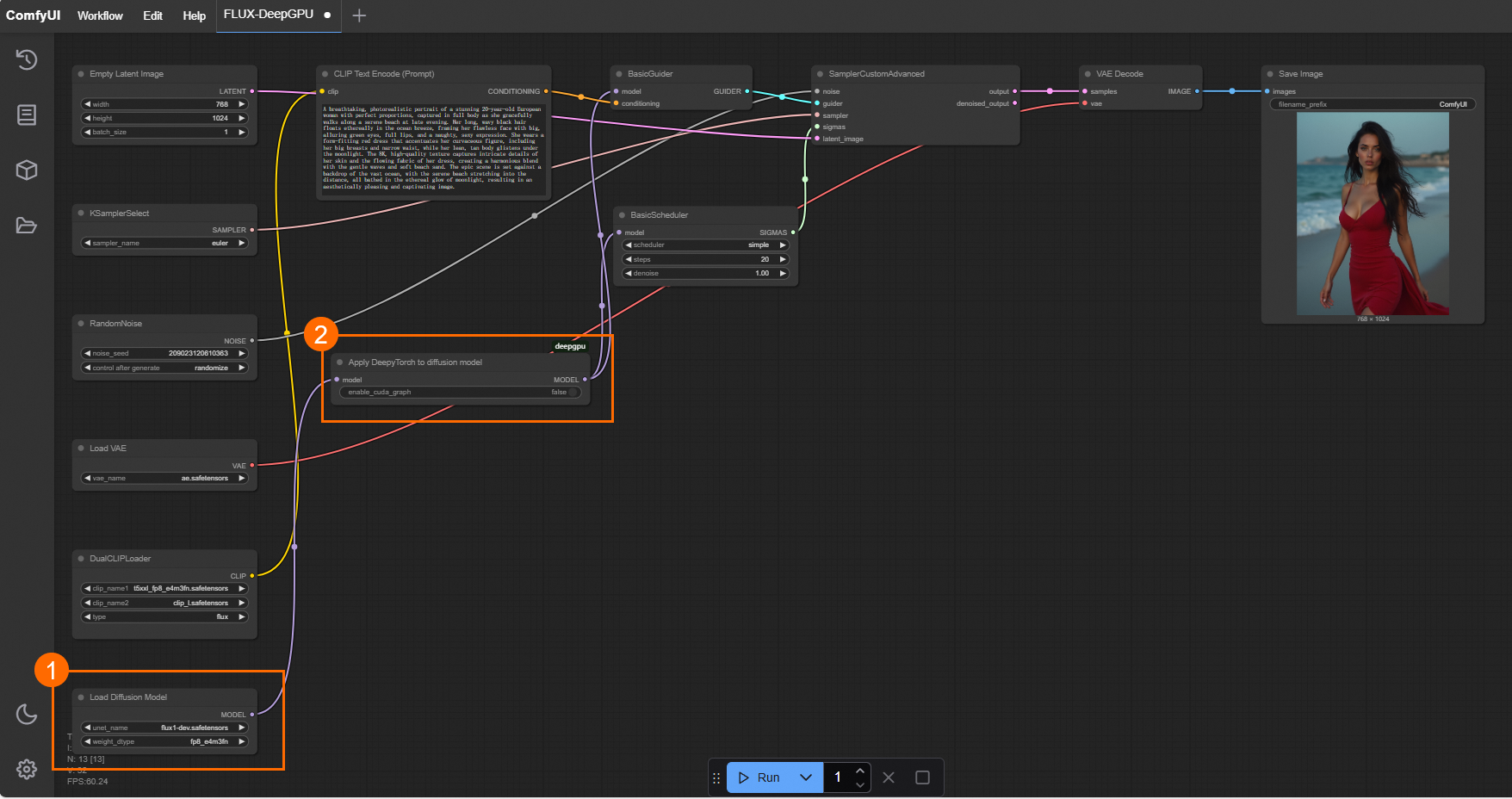
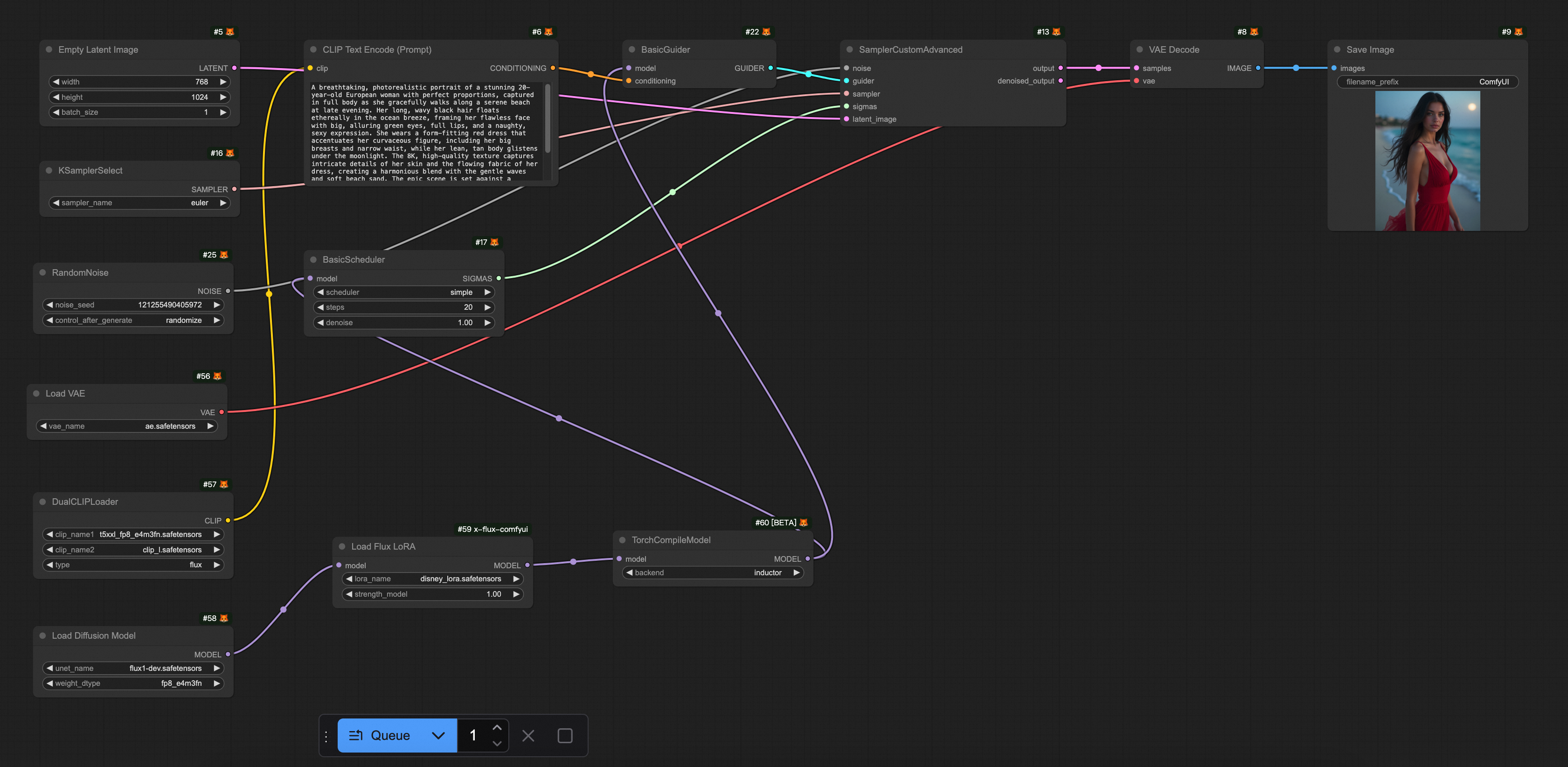
挿入ポイント: Flux の場合、Load Diffusion Model、Load Flux LoRA、または Apply Flux IPAdapter ノードの後に Apply DeepyTorch to diffusion model ノードを挿入します。他のモデルの場合は、Load Checkpoint または LoraLoaderModelOnly ノードの後に挿入します。次の図は、インポートの例を示しています。
サンプラーの置き換え: Flux の場合、DeepTorch Sampler to replace XlabsSampler ノードを使用して XLabsSampler ノードを置き換えます。
ComfyUI TorchCompile* ノード
現在、いくつかのオープンソースの推論高速化ノードが利用可能です。例:
TorchCompileModel
TorchCompileVAE
TorchCompileControlNet
TorchCompileModelFluxAdvanced
これらのノードは、PyTorch の Just-In-Time (JIT) コンパイル機能を使用して、モデルの実行を最適化および高速化します。また、動的計算グラフを効率的な静的コードに変換することで、リソースの利用率も向上させます。
現在、これらのノードのほとんどはベータ版または実験段階にあります。
TorchCompile* ノードと DeepGPU の使用状況とパフォーマンスの比較
推論高速化のために、ComfyUI の組み込み TorchCompile ノードと DeepGPU ノードのパフォーマンスを比較しました。使用方法、高速化効果、および適用可能なシナリオを分析して、参考資料を提供しました。
モデルリスト
フォルダ名 | ダウンロードしたモデル |
clip | clip_l.safetensors |
t5xxl_fp8_e4m3fn.safetensors | |
clip_vision_l.safetensors | |
loras | FLUX1_wukong_lora.safetensors |
unet | flux1-dev.safetensors |
vae | ae.safetensors |
構成パラメータ
サンプラー
steps: 20
空の潜在画像
幅: 768
高さ: 1024
テストプラットフォーム
Alibaba Cloud Function Compute fc.gpu.ada.1 インスタンス。
推論高速化フレームワークのシナリオサポートマトリックスと推論高速化効果
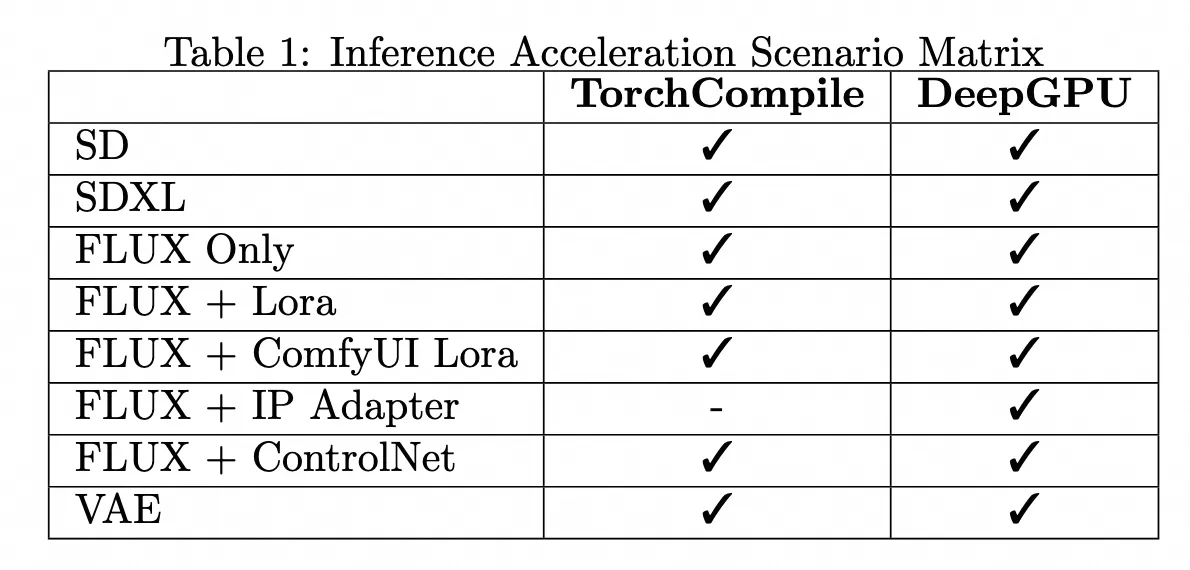
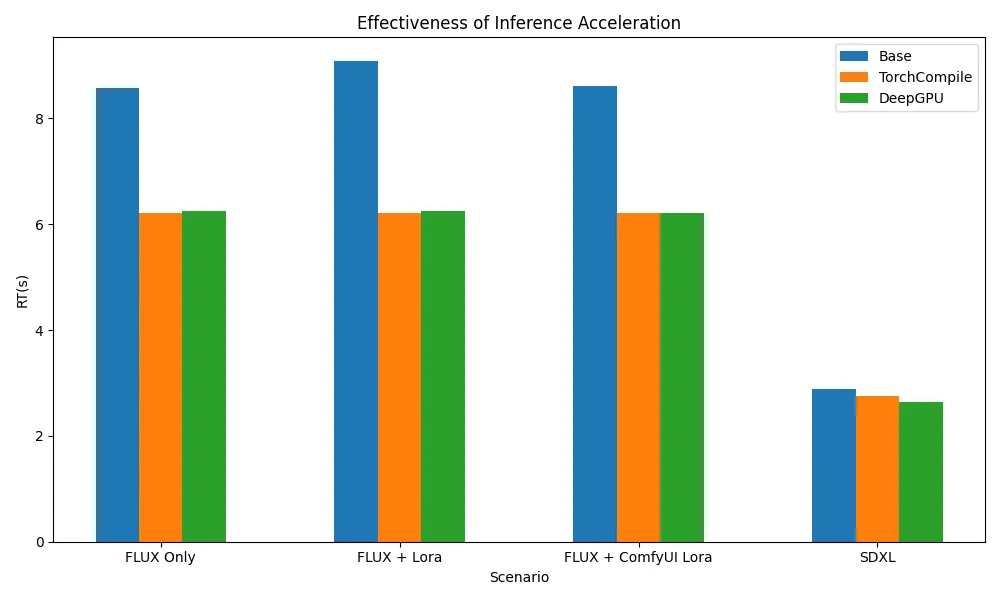
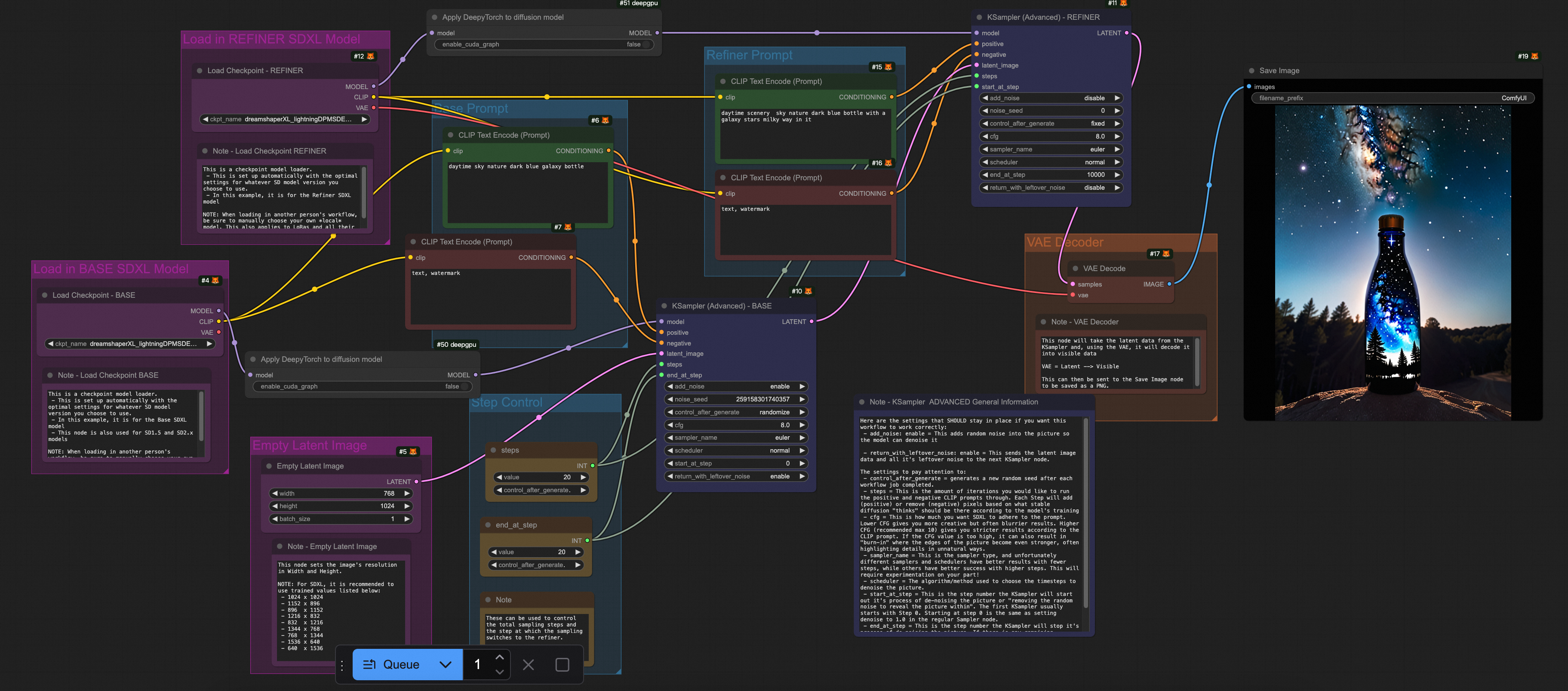
テスト結果によると、TorchCompile シリーズノードと DeepGPU の両方が ComfyUI + SD/FLUX シナリオのほとんどをカバーし、Flux 関連のシナリオで約 20% から 30% の推論高速化を実現しています。
テストワークフロー
次の表に、さまざまなモデルで使用される推論高速化の Workflows.json ファイルを示します。
シナリオ | ワークフロー |
FLUX のみ |
|
FLUX + Lora |
|
FLUX + ComfyUI Lora |
|
SDXL |
|
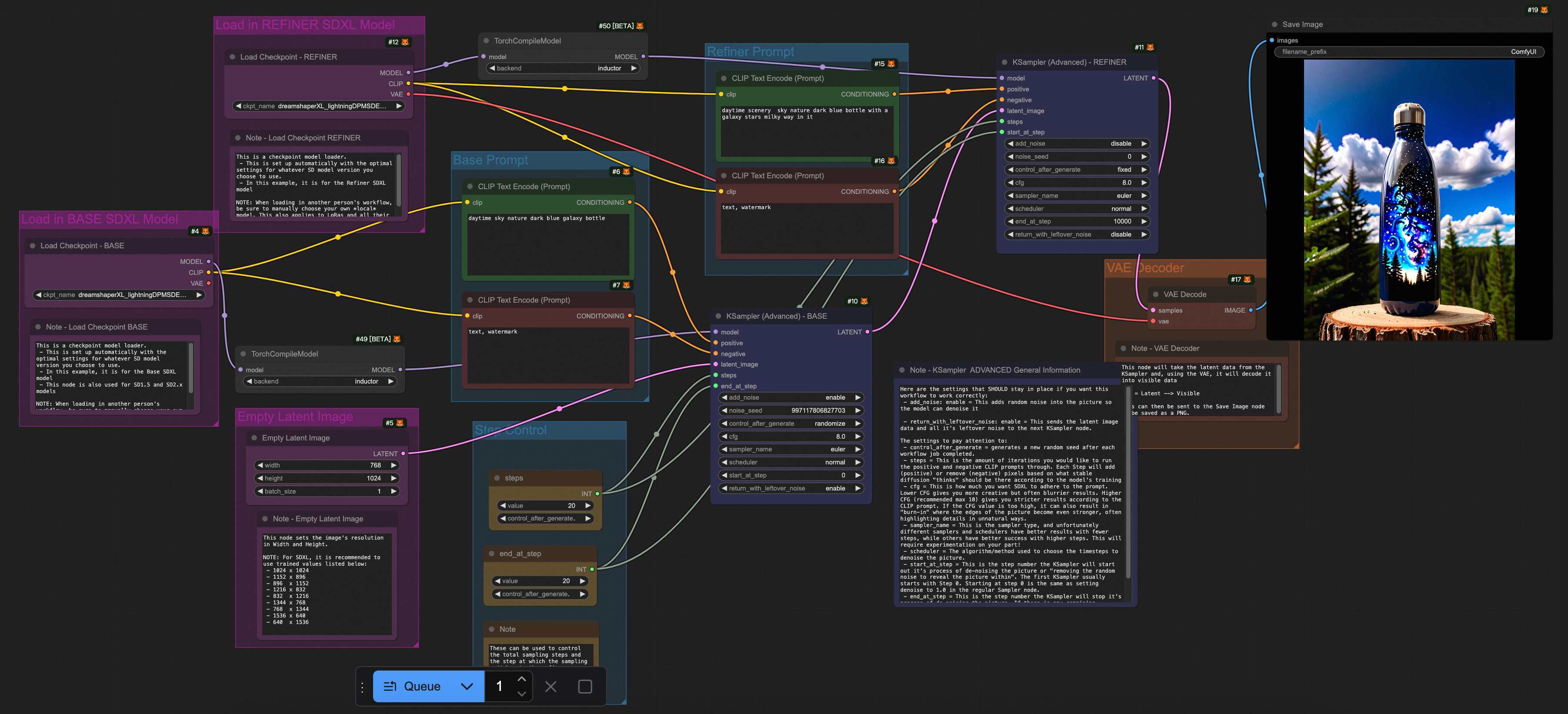
参考資料
長時間実行される GPU インスタンスは失敗する可能性があります。Function Compute は、デフォルトでリクエストベースのヘルスチェックメカニズムを提供し、カスタムインスタンスヘルスチェック ロジックを設定できます。
Function Compute は、関数とインスタンスの監視レポートをデフォルトで提供しており、追加の設定なしで表示できます。トラブルシューティングのために関数ログを収集するには、ログ収集を設定することができます。