このトピックでは、Function Compute で AI 推論アプリケーションをデプロイする際のモデルの一般的な保存方法について説明します。また、これらの方法の利点、欠点、および適用可能なシナリオを比較します。
背景情報
関数のストレージタイプの詳細については、「関数のストレージタイプを選択する」をご参照ください。GPU インスタンスのモデルを保存するには、次の 2 つのタイプが適しています。
GPU インスタンス関数はカスタムコンテナイメージを使用してサービスをデプロイするため、モデルファイルをコンテナイメージに直接配置することもできます。
各方法には独自のシナリオと技術的特徴があります。ストレージ方法を選択する際には、特定の要件、実行環境、およびチームのワークフローを考慮して、効率とコストのバランスを取る必要があります。
コンテナイメージを使用したモデルの配布
最も簡単な方法の 1 つは、トレーニング済みのモデルと関連するアプリケーションコードをコンテナイメージにまとめてパッケージ化することです。モデルファイルはコンテナイメージとともに配布されます。
利点と欠点
利点:
利便性: イメージを作成した後、追加の構成なしで直接推論を実行できます。
一貫性: これにより、すべての環境でモデルのバージョンが一貫していることが保証されます。これにより、環境間のバージョンの不一致によって引き起こされる問題を防ぐことができます。
欠点:
イメージサイズ: 特に大規模なモデルの場合、イメージが非常に大きくなる可能性があります。
時間のかかる更新: モデルを更新するたびにイメージを再構築して配布する必要があり、これは時間のかかるプロセスになる可能性があります。
説明
関数インスタンスのコールドスタート速度を向上させるために、プラットフォームはコンテナイメージを前処理します。イメージが大きすぎると、プラットフォームのイメージサイズ制限を超える可能性があります。また、イメージの高速化と前処理に必要な時間も増加する可能性があります。
プラットフォームのイメージサイズ制限の詳細については、「GPU イメージのサイズ制限は何ですか?」をご参照ください。
イメージの前処理と関数のステータスの詳細については、「カスタムイメージの関数のステータスと呼び出し」をご参照ください。
シナリオ
モデルサイズが比較的小さい場合、たとえば数百メガバイトなど。
モデルの変更が頻繁でない場合。この場合、モデルをコンテナイメージにパッケージ化できます。
モデルファイルが大きい、頻繁に更新される、またはコンテナイメージがプラットフォームのサイズ制限を超える原因となる場合は、モデルをイメージから分離する必要があります。
File Storage NAS へのモデルの保存
Function Compute では、NAS ファイルシステムを関数インスタンスの指定されたディレクトリにマウントできます。その後、アプリケーションは NAS マウントポイントディレクトリにアクセスしてモデルファイルをロードできます。
利点と欠点
利点:
NAS は、より完全で成熟した
POSIXファイルインターフェイスを提供するため、FUSEファイルシステムよりも優れたアプリケーション互換性を提供します。容量: NAS はペタバイト規模のストレージ容量を提供できます。
欠点:
VPC への依存: 関数が NAS マウントポイントにアクセスするには、VPC アクセスを構成する必要があります。これには、複数のクラウド製品にまたがる権限の構成が必要です。さらに、関数インスタンスがコールドスタートすると、プラットフォームがインスタンスの VPC アクセスを確立するのに数秒かかります。
限定的なコンテンツ管理: NAS ファイルシステムは使用前にマウントする必要があります。この方法では、モデルファイルを NAS インスタンスに配布するためのビジネスワークフローを確立する必要があります。
アクティブ/アクティブまたはマルチアベイラビリティゾーン (AZ) デプロイメントはサポートされていません。詳細については、「NAS のよくある質問」をご参照ください。
説明
多くのコンテナが同時に起動してモデルをロードするシナリオでは、NAS の帯域幅のボトルネックに容易に達します。これにより、インスタンスの起動時間が長くなり、タイムアウトによる起動失敗を引き起こすことさえあります。たとえば、スケジュールされた Horizontal Pod Autoscaler (HPA) がバッチで GPU スナップショットを作成したり、トラフィックの急増によって多くの弾性 GPU インスタンスが作成されたりする場合です。
コンソールで NAS パフォーマンスモニタリング (読み取りスループット) を表示できます。
特定の NAS ファイルシステムの読み取りおよび書き込みスループットは、容量を増やすことで向上させることができます。
NAS を使用してモデルファイルを保存する場合は、パフォーマンス最適化 NAS ファイルシステムを使用することをお勧めします。これは、このタイプの NAS が約 600 MB/s の高い初期読み取り帯域幅を提供するためです。詳細については、「汎用型 NAS ファイルシステム」をご参照ください。
シナリオ
Function Compute で弾性 GPU インスタンスを使用する場合、高速な起動パフォーマンスが求められます。
Object Storage Service (OSS) へのモデルの保存
Function Compute では、OSS バケットを関数インスタンスの指定されたディレクトリにマウントできます。アプリケーションは、OSS マウントポイントから直接モデルをロードできます。
利点
帯域幅: OSS は NAS よりも帯域幅制限が高くなっています。これにより、関数インスタンス間の帯域幅の競合が発生しにくくなります。詳細については、「制限」をご参照ください。また、OSS アクセラレータを有効にして、より高いスループットを得ることもできます。
複数の管理方法:
コンソールや API などのアクセスチャネルを提供します。
さまざまなローカルで利用可能なオブジェクトストレージ管理ツールを提供します。詳細については、「開発者ツール」をご参照ください。
OSS の クロスリージョンレプリケーション機能を使用して、モデルの同期と管理を行うことができます。
シンプルな構成: NAS ファイルシステムと比較して、OSS バケットを関数インスタンスにマウントするのに VPC 接続は必要ありません。構成後すぐに使用できます。
コスト: 容量とスループットのみを比較した場合、OSS は一般的に NAS よりもコスト効率が高くなります。
説明
OSS マウントは、Filesystem in Userspace (FUSE) ユーザーモードファイルシステムメカニズムを使用します。アプリケーションが OSS マウントポイント上のファイルにアクセスすると、プラットフォームはアクセスリクエストを OSS API 呼び出しに変換してデータにアクセスします。したがって、OSS マウントには次の特徴があります。
ユーザーモードで実行され、CPU、メモリ、一時ストレージなど、関数インスタンスのリソースクォータを消費します。したがって、この方法は、大規模な仕様の GPU インスタンスに最適です。
データアクセスには OSS API を使用します。そのスループットとレイテンシは OSS API サービスによって制限されます。このため、モデルのロードシナリオで一般的な、少数の大きなファイルへのアクセスに適しています。多数の小さなファイルへのアクセスには適していません。
OSS マウントは、ランダムな読み取り/書き込みよりもシーケンシャルな読み取り/書き込みに適しています。大きなファイルをロードする場合、シーケンシャルな読み取りはファイルシステムのプリフェッチメカニズムを最大限に活用して、より良いネットワークスループットとより低いロードレイテンシを実現できます。
たとえば、safetensors ファイルでは、シーケンシャルな読み取りに最適化されたバージョンを使用すると、OSS マウントポイントからモデルファイルをロードする時間が大幅に短縮されます。詳細については、「load_file: load tensors ordered by their offsets」をご参照ください。
アプリケーションの I/O パターンを調整できない場合は、ロードする前にファイルを一度シーケンシャルに読み取ることができます。これにより、コンテンツがシステムの PageCache にプリフェッチされます。その後、アプリケーションは PageCache からファイルをロードします。
シナリオ
多くのインスタンスが並行してモデルをロードします。これには、インスタンス間の帯域幅の競合を避けるために、より高いストレージスループットが必要です。
ローカル冗長ストレージまたはマルチリージョンデプロイメントが必要です。
モデルのロードシナリオで一般的な、シーケンシャルな読み取り I/O パターンで少数の大きなファイルにアクセスする場合。
比較のまとめ
比較項目 | イメージで配布 | NAS のマウント | OSS のマウント |
モデルサイズ |
| なし | なし |
スループット | 高速 |
|
|
互換性 | 良好 | 良好 |
|
I/O パターン適応性 | 良好 | 良好 | シーケンシャルな読み取り/書き込みシナリオに適しています。ランダムな読み取りは、より良いスループットを得るために PageCache アクセスに変換する必要があります。 |
管理方法 | コンテナイメージ | VPC 内でマウントしてから使用します。 |
|
マルチ AZ | サポートされています | サポートされていません | サポートされています |
コスト | 追加料金なし | NAS は一般的に OSS よりもわずかに高価です。各製品の現在の課金ルールをご参照ください。
| |
この比較に基づき、さまざまな使用パターン、同時コンテナ起動ボリューム、およびモデル管理のニーズを考慮して、Function Compute (FC) GPU インスタンスにモデルを保存するための推奨プラクティスを以下に示します。
ファイルシステム API との高い互換性が必要な場合、またはアプリケーションがランダム読み取りを使用し、メモリ PageCache にアクセスするように変更できない場合は、パフォーマンス最適化 NAS ファイルシステムを使用します。
多くの GPU コンテナが同時に起動するシナリオでは、OSS アクセラレータを使用して、NAS の単一ポイントの帯域幅ボトルネックを回避します。
マルチリージョンデプロイメントシナリオでは、OSS と OSS アクセラレータを使用して、モデル管理とクロスリージョン同期の複雑さを軽減します。
テストデータ
以下の 2 つのテストでは、さまざまなシナリオでファイルをロードするのにかかる時間を比較することで、さまざまなストレージメディア間のパフォーマンスの違いを分析します。ロード時間が短いほど、ストレージのパフォーマンスが優れていることを示します。
方法 1: 異なるモデルのファイルロード時間
このテストでは、さまざまなストレージメディアから GPU メモリに `safetensors` モデルの重みファイルをロードするのにかかる時間を測定します。この結果を使用して、さまざまなモデルに対するさまざまなストレージ方法のパフォーマンスを比較します。
テスト環境
インスタンスタイプ: Ada カードタイプ、8 コア、64 GB メモリ
OSS アクセラレータ容量: 10 TB、最大スループット 3,000 MB/s
NAS 仕様: パフォーマンス最適化 NAS ファイルシステム、最大スループット 600 MB/s に対応する容量
safetensors バージョン
0.5.3次の表に、このテストで使用されたモデルとそのサイズを示します。
モデル
サイズ (GB)
Anything-v4.5-pruned-mergedVae.safetensors
3.97
Anything-v5.0-PRT-RE.safetensors
1.99
CounterfeitV30_v30.safetensors
3.95
Deliberate_v2.safetensors
1.99
DreamShaper_6_NoVae.safetensors
5.55
cetusMix_Coda2.safetensors
3.59
chilloutmix_NiPrunedFp32Fix.safetensors
3.97
flux1-dev.safetensors
22.2
revAnimated_v122.safetensors
5.13
sd_xl_base_1.0.safetensors
6.46
結果
次の図では、縦軸はロード時間を表し、横軸はさまざまなモデルと 3 つのストレージ方法 (`ossfs,accel`、`ossfs`、`nas`) を表します。
バーの色 | ストレージ方法 | 技術的特徴 |
青 | ossfs,accel | OSS アクセラレータエンドポイント |
オレンジ | ossfs | 標準 OSS エンドポイント |
グレー | nas | NAS ファイルシステムマウントポイント |
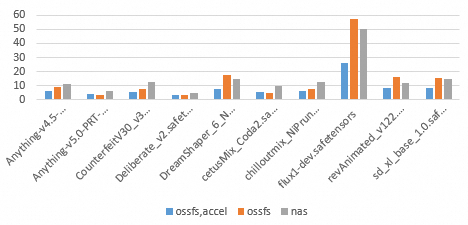
テストの結論
スループット: NAS に対する OSS の主な利点は、スループット性能です。テストデータによると、標準 OSS エンドポイントの読み取りスループットは、多くの場合 600 MB/s 以上に達することがあります。
ランダム読み取りの影響: 比較的大規模な flux1-dev.safetensors や小規模な revAnimated_v122.safetensors などの一部のファイルでは、標準 OSS のロード時間は OSS アクセラレータや NAS よりも大幅に長くなります。これは、プラットフォームが OSS アクセラレータのランダム読み取りを最適化しており、NAS がランダム読み取りシナリオで標準 OSS よりも予測可能なパフォーマンスを発揮するためです。
方法 2: 異なる同時実行レベルでのファイルロード時間
このテストでは、大規模な 22.2 GB モデル flux1-dev.safetensors を使用して、4、8、16 の同時実行レベルでファイルを GPU メモリにロードするときのレイテンシ分布をテストします。
テスト環境
インスタンスタイプ: Ada.3、8 コア、64 GB メモリ
OSS アクセラレータ容量: 80 TB、最大スループット 24,000 MB/s
NAS 仕様: パフォーマンス最適化 NAS ファイルシステム、最大スループット 600 MB/s に対応する容量
safetensors バージョン
0.5.3
結果
図 1 は、異なる同時実行レベルにおける、`ossfs,accel,N`、`ossfs,N`、`nas,N` などのさまざまなストレージ方法の最大、平均、および中央値のロード時間を示しています。N はインスタンスの最小数を示します。
ストレージ方法 | 技術的特徴 |
ossfs,accel,N | OSS アクセラレータエンドポイント |
ossfs,N | 標準 OSS エンドポイント |
nas,N | NAS ファイルシステムマウントポイント |
バーの色 | 表す値 |
青 | 平均時間 |
オレンジ | 中央値時間 |
グレー | 最大時間 |
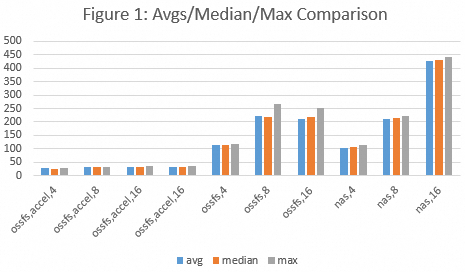
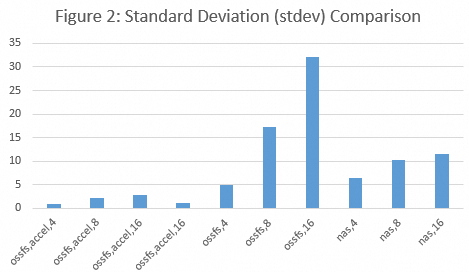
図 2 は、異なる同時実行レベルにおける、`ossfs,accel,N`、`ossfs,N`、`nas,N` などのさまざまなストレージ方法の標準偏差を示しています。N はインスタンスの最小数を示します。
テストの結論
スループット: NAS に対する OSS の主な利点はスループット性能であり、OSS アクセラレータの利点はさらに顕著です。標準 OSS のスループットは多くの場合 600 MB/s を超えることができ、OSS アクセラレータのスループットは期待値に達することができます (図 1 を参照)。
安定性: 高い同時実行シナリオでは、標準 OSS は NAS よりも平均ロードレイテンシが低いですが、標準偏差が高いことからわかるように、そのパフォーマンスの一貫性は低くなります。この場合、NAS のスループットは標準 OSS よりも予測可能です (図 2 を参照)。
注: 異なる safetensors ファイルをロードする際に生成されるランダム I/O はさまざまです。これは、NAS マウントポイントよりも標準 OSS マウントポイントからのモデルロード時間に大きな影響を与えます。