このトピックでは、プロビジョニングされたGPUアクセラレーションインスタンスをリアルタイム推論シナリオで使用する方法と、プロビジョニングされたGPUアクセラレーションインスタンスを使用してレイテンシに敏感なリアルタイム推論サービスを構築する方法について説明します。
背景情報
シナリオ
リアルタイム推論シナリオのワークロードには、次の1つ以上の特徴があります。
低レイテンシ
リアルタイム推論シナリオのワークロードには、各リクエストの時間効率と応答時間に関する高い要件があります。 長いテール待ち時間は、90% の要求に対して数百ミリ秒以内でなければならない。
コアリンク
ほとんどの場合、リアルタイムの推論はコアビジネスリンクで発生し、推論の高い成功率が必要です。 長期的な再試行は避ける必要があります。 次のアイテムは例を示します。
ローンチページのコマーシャルとホームページの製品の推奨: ユーザー固有のコマーシャルと製品は、ユーザーの好みに基づいてランチページとホームページに表示できます。
ストリーミングメディアでのリアルタイム制作: インタラクティブストリーミング、ライブストリーミング、超低レイテンシ再生などのシナリオでは、オーディオストリームとビデオストリームを非常に低いエンドツーエンドのレイテンシで送信する必要があります。 リアルタイムのAIベースのビデオ超解像度やビデオ認識などのシナリオでも、パフォーマンスとユーザーエクスペリエンスを保証する必要があります。
ピーク時間とオフピーク時間
ビジネストラフィックにはピーク時間とオフピーク時間があります。 トラフィック変動傾向は、ユーザの習慣によって変化する。
低リソース使用率
ほとんどの場合、GPUリソースはトラフィックピークに基づいて計画されます。 オフピーク時には大量のリソースが浪費され、リソース利用率は一般に30% よりも低い。
メリット
Function Computeは、リアルタイム推論ワークロードに次の利点を提供します。
プロビジョニング済みGPU高速化インスタンス
Function Computeでは、オンデマンドモードとプロビジョニングモードでGPU高速化インスタンスを使用できます。 コールドスタートの影響を排除し、リアルタイム推論の低レイテンシ応答要件を満たすために、プロビジョニングされたGPUアクセラレーションインスタンスを使用できます。 プロビジョニングモードの詳細については、「プロビジョニング済みインスタンスと自動スケーリングルールの設定」をご参照ください。
プロビジョニングされたGPUアクセラレーションインスタンスの自動スケーリングポリシー (推奨)
Function Computeでは、プロビジョニングされたGPUアクセラレーションインスタンスのメトリックベースの自動スケーリングポリシーとスケジュールされた自動スケーリングポリシーを設定できます。 メトリックベースの自動スケーリングポリシーで使用されるメトリックには、同時実行、GPUストリーミングマルチプロセッサ (SM) 使用率、GPUメモリ使用率、GPUエンコーダ使用率、およびGPUデコーダ使用率が含まれます。 トラフィックトレンドのさまざまなシナリオでさまざまなオートスケーリングポリシーを使用して、GPU高速化インスタンスのコンピューティング能力要件を満たし、デプロイコストを削減できます。
サービス品質を比較的低コストで保証
プロビジョニングされたGPUアクセラレーションインスタンスの課金サイクルは、オンデマンドGPUアクセラレーションインスタンスの課金サイクルとは異なります。 プロビジョニングされたインスタンスは、インスタンスの有効期間に基づいて課金されます。 プロビジョニングされたGPUアクセラレーションインスタンスを割り当てた後、リクエストが処理されているかどうかに関係なく料金が発生します。 したがって、プロビジョニングされたGPUアクセラレーションインスタンスのコストは、オンデマンドのGPUアクセラレーションインスタンスよりも高くなります。 ただし、自作GPUクラスターと比較して、コストは50% 以上削減されます。
最適な仕様
Function Computeでは、ビジネス要件に基づいて、GPUタイプを選択し、CPU、GPUメモリ、メモリ、ディスク容量などのGPU仕様を設定できます。 GPUの最小メモリサイズは1 GB単位で設定できます。 これにより、ビジネス要件に基づいて最適なインスタンス仕様を設定できます。
Burst trafficのサポート
Function Computeは豊富なGPUリソースを提供します。 ビジネスでトラフィックバーストが発生すると、Function Computeは数秒で多数のGPUコンピューティングリソースを提供します。 これにより、GPUコンピューティングパワーの供給不足や遅延によるビジネスへの悪影響を防ぐことができます。
仕組み
GPU関数をデプロイした後、自動スケーリングポリシーを設定して、プロビジョニングされたGPUアクセラレーションインスタンスを割り当てることができます。 インスタンスは、リアルタイムの推論シナリオに必要なインフラストラクチャを提供します。 Function Computeは、設定したメトリックに基づいて、プロビジョニングされたGPUアクセラレーションインスタンスに対して水平ポッドオートスケーリング (HPA) を実行します。 リクエストは、推論のためにプロビジョニングされたGPUアクセラレーションインスタンスに優先的に送信されます。 Function Computeではコールドスタートがなくなり、サービスを低レイテンシーで実行できます。

リアルタイム推論シナリオの基本情報
コンテナーのサポート
Function ComputeのGPU高速化インスタンスは、カスタムコンテナランタイムでのみ使用できます。 カスタムコンテナランタイムの詳細については、「概要」をご参照ください。
カスタムコンテナランタイムは、webサーバーモードと非webサーバーモードをサポートします。 オンライン推論シナリオでは、webサーバーモードのコンテナーが使用されます。 オフラインシナリオでは、非webサーバーモードのコンテナーが使用されます。
webサーバーモードでは、イベントベースの関数トリガーやHTTPベースの関数トリガーなど、さまざまなコードパスとトリガーモードの要件を満たすために、webサーバーをイメージに実装する必要があります。 Webサーバーモードは、AI学習や推論などのマルチパス要求実行シナリオに適用できます。 詳細については、「Webサーバーモード」をご参照ください。
GPU高速化インスタンスの仕様
推論シナリオでは、さまざまなGPUカードタイプを選択し、ビジネスで必要とされる計算能力に基づいてGPUアクセラレーションインスタンスの仕様を設定できます。 GPU高速化インスタンスの仕様には、GPUメモリ、メモリ、およびディスク容量が含まれます。 GPU高速化インスタンスの仕様の詳細については、「インスタンス仕様」をご参照ください。
モデル展開方法
次のいずれかの方法を使用して、Function Computeにモデルをデプロイできます。
Function Computeコンソールを使用します。 詳細については、「Function Computeコンソールを使用した関数の作成」をご参照ください。
SDKを呼び出します。 詳細については、「機能別操作一覧」をご参照ください。
Serverless Devsを使用します。 詳細については、「Serverless Devsコマンド」をご参照ください。
その他のデプロイ例については、「start-fc-gpu」をご参照ください。
プロビジョニング済みインスタンスの自動スケーリング
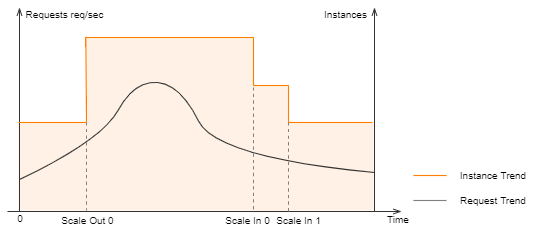
スケジュール済み自動スケーリングポリシー
Function Computeでスケジュールされた自動スケーリングポリシーを設定できます。 詳細については、「スケジュール設定の変更」をご参照ください。 リアルタイム推論シナリオでトラフィックが定期的に変化する場合、スケジュールされた自動スケーリングポリシーを設定して、プロビジョニングされたGPUアクセラレーションインスタンスを指定された時点で割り当ててリリースできます。 これにより、プロビジョニングされたGPUアクセラレーションインスタンスは、トラフィックが急増する数分前に割り当てられ、トラフィックが減少したときにリリースされます。 これにより、低コストで最適なパフォーマンスを確保できます。
メトリックベースの自動スケーリングポリシー
次の表に、Function ComputeのGPU関数で追跡できるメトリックを示します。 動的スケーリングポリシーを設定するには、ビジネス要件に基づいてメトリックを選択します。
リアルタイム推論シナリオでは、HPAメトリックとしてProvisionedConcurrencyUtilizationメトリックを使用することを推奨します。 これは、同時実行およびQPSメトリクスがビジネス指向メトリクスであり、他のGPUリソース使用率メトリクスがリソース指向メトリクスであるためです。 ビジネスメトリックの変更は、リソースメトリックに影響します。 ビジネス指向のメトリックを使用すると、プロビジョニングされたGPUアクセラレーションインスタンスのスケーリングをより効率的にトリガーできます。 これにより、サービスの品質が保証されます。
メトリック | 説明 | 有効値 |
ProvisionedConcurrencyUtilization | プロビジョニングされたインスタンスの同時使用。 このメトリックは、関数の割り当てられたプロビジョニングされた同時実行性に対する使用中のインスタンス同時実行性の比率を収集します。 | [0, 1] は、0% から100% までの利用率に対応します。 |
GPUSmUtilization | GPU SM使用率。 このメトリックは、複数のインスタンスの最大GPU SM使用率に関する統計を収集します。 | |
GPUMemoryUtilization | GPUメモリ使用率。 このメトリックは、複数のインスタンスの最大GPUメモリ使用率を収集します。 | |
GPUDecoderUtilization | GPUハードウェアデコーダ使用率。 このメトリックは、複数のインスタンスのGPUハードウェアデコーダの最大使用率を収集します。 | |
GPUEncoderUtilization | GPUハードウェアエンコーダ使用率。 このメトリックは、複数のインスタンスのGPUハードウェアエンコーダの最大使用率を収集します。 |
モデルwarmup
モデルがリリースされてから最初のリクエストに時間がかかるという問題を解決するために、Function Computeはモデルのウォームアップ機能を提供しています。 モデルのウォームアップ機能を使用すると、モデルが起動した直後に作業状態に入ることができます。
Function Computeでライフサイクルフックの初期化を設定して、モデルをウォームアップすることを推奨します。 Function Computeは、初期化のビジネスロジックを自動的に実行してモデルをウォームアップします。 詳細については、「関数インスタンスのライフサイクルフック」をご参照ください。
モデルをウォームアップするには、次の操作を実行できます。
モデルのウォームアップロジックをインスタンスの
初期化ライフサイクルフックに追加します。POSTメソッドの
/initialize呼び出しパスをビルドするHTTPサーバーに追加し、モデルのウォームアップロジックを/initializeパスの下に配置します。 モデルに単純な推論を実行させて、ウォームアップ効果を実現できます。 次のサンプルコードは、Pythonの例を示しています。def prewarm_inference(): res = model.inference() @app.route('/initialize', methods=['POST']) def initialize(): request_id = request.headers.get("x-fc-request-id", "") print("FC Initialize Start RequestId: " + request_id) # Prewarm model and perform naive inference task. prewarm_inference() print("FC Initialize End RequestId: " + request_id) return "Function is initialized, request_id: " + request_id + "\n"関数設定ページで、インスタンスライフサイクルフックを設定します。
[機能の詳細] ページの [設定] タブで、[インスタンスライフサイクルフック] セクションの [変更] をクリックします。 インスタンスライフサイクルフックパネルで、Initializerフックを設定します。

自動スケーリングポリシーの設定と検証
このトピックでは、GPUアクセラレーションインスタンスの自動スケーリングポリシーを設定する2つの方法について説明します。
自動スケーリングポリシーを設定した後、ストレステストを実行して、自動スケーリングポリシーの効果を表示できます。 詳細については、「ストレステストの実行」をご参照ください。
Serverless Devsを使用したGPU高速化インスタンスの自動スケーリングポリシーの設定
始める前に
GPUアクセラレーションインスタンスが存在するリージョンで、次の操作を実行します。
Container Registry Enterprise EditionインスタンスまたはPersonal Editionインスタンスを作成します。 Enterprise Editionインスタンスを作成することを推奨します。 詳細については、「手順1: Container Registry Enterprise Editionインスタンスの作成」をご参照ください。
名前空間とイメージリポジトリを作成します。 詳細については、「手順2: 名前空間の作成」および「手順3: イメージリポジトリの作成」をご参照ください。
手順
次のコマンドを実行して、プロジェクトを複製します。
git clone https://github.com/devsapp/start-fc-gpu.gitプロジェクトを展開します。
次のコマンドを実行して、プロジェクトディレクトリに移動します。
cd fc-http-gpu-inference-paddlehub-nlp-porn-detection-lstm/src/次のコードスニペットは、プロジェクトの構造を示しています。
. ├── hook │ └── index.js └── src ├── code │ ├── Dockerfile │ ├── app.py │ ├── hub_home │ │ ├── conf │ │ ├── modules │ │ └── tmp │ └── test │ └── client.py └── s.yaml次のコマンドを実行して、Dockerを使用してイメージをビルドし、イメージをイメージリポジトリにプッシュします。
export IMAGE_NAME="registry.cn-shanghai.aliyuncs.com/fc-gpu-demo/paddle-porn-detection:v1" # sudo docker build -f ./code/Dockerfile -t $IMAGE_NAME . # sudo docker push $IMAGE_NAME重要PaddlePaddleフレームワークは大きく、初めて画像を作成するのに長時間 (約1時間) かかります。 そのため、仮想プライベートクラウド (VPC) に存在するパブリックイメージを提供します。 パブリックイメージを使用する場合は、前述のdocker buildおよびdocker pushコマンドを実行する必要はありません。
Edit thes.yamlファイルを編集します。
edition: 1.0.0 name: container-demo access: {access} vars: region: cn-shanghai services: gpu-best-practive: component: devsapp/fc props: region: ${vars.region} service: name: gpu-best-practive-service internetAccess: true logConfig: enableRequestMetrics: true enableInstanceMetrics: true logBeginRule: DefaultRegex project: log-ca041e7c29f2a47eb8aec48f94b**** # Use the name of the Log Service project that you created. logstore: config***** # Use the name of the Logstore that you created. role: acs:ram::143199913651****:role/aliyunfcdefaultrole function: name: gpu-porn-detection description: This is the demo function deployment handler: not-used timeout: 1200 caPort: 9000 memorySize: 8192 # Set the memory size to 8 GB. cpu: 2 gpuMemorySize: 8192 # Set the GPU memory to 8 GB. diskSize: 512 instanceType: fc.gpu.tesla.1 # Deploy GPU-accelerated instances that use Tesla GPUs. instanceConcurrency: 1 runtime: custom-container environmentVariables: FCGPU_RUNTIME_SHMSIZE : '8589934592' customContainerConfig: image: registry.cn-shanghai.aliyuncs.com/serverless_devs/gpu-console-supervising:paddle-porn-detection # The public image is used as an example. Use the actual name of your image. accelerationType: Default triggers: - name: httpTrigger type: http config: authType: anonymous methods: - GET - POST次のコマンドを実行して、関数をデプロイします。
sudo s deploy --skip-push true -t s.yaml実行が完了すると、出力にURLが返されます。 URLを使用して関数をテストできます。
関数をテストし、Function Computeコンソールモニタリング結果を表示します。
curlコマンドを実行して、関数をテストします。 コマンドでは、前の手順で取得したURLを使用します。
curl https://gpu-poretection-gpu-bes-service-gexsgx****.cn-shanghai.fcapp.run/invoke -H "Content-Type: text/plain" --data "Nice to meet you"次の出力が返されると、テストに合格します。
[{"text": "Nice to meet you", "porn_detection_label": 0, "porn_detection_key": "not_porn", "porn_probs": 0.0, "not_porn_probs": 1.0}]%Function Computeコンソールで、 を選択します。 ステップ2でデプロイされたサービスと関数をクリックします。 次に、[メトリック] タブをクリックして、GPU関連のメトリックの変更を表示します。
プロビジョニングされたインスタンスの自動スケーリングポリシーを設定します。
作成します。Create theprovision.jsonテンプレートを使用します。
次のサンプルコードは、例を示しています。 このテンプレートは、インスタンスの同時実行性を追跡メトリックとして使用します。 最小インスタンス数は2、最大インスタンス数は30です。
{ "target": 2, "targetTrackingPolicies": [ { "name": "scaling-policy-demo", "startTime": "2023-01-01T16:00:00.000Z", "endTime": "2024-01-01T16:00:00.000Z", "metricType": "ProvisionedConcurrencyUtilization", "metricTarget": 0.3, "minCapacity": 2, "maxCapacity": 30 } ] }次のコマンドを実行して、スケーリングポリシーをデプロイします。
sudo s provision put --config ./provision.json --qualifier LATEST -t s.yaml -a {access}sudo s provision listコマンドを実行して確認します。 次の出力が表示されます。targetとcurrentの値が等しく、プロビジョニングされたインスタンスが正しくプルアップされ、自動スケーリングポリシーが期待どおりにデプロイされていることを示します。[2023-05-10 14:49:03] [INFO] [FC] - Getting list provision: gpu-best-practive-service gpu-best-practive: - serviceName: gpu-best-practive-service qualifier: LATEST functionName: gpu-porn-detection resource: 143199913651****#gpu-best-practive-service#LATEST#gpu-porn-detection target: 2 current: 2 scheduledActions: null targetTrackingPolicies: - name: scaling-policy-demo startTime: 2023-01-01T16:00:00.000Z endTime: 2024-01-01T16:00:00.000Z metricType: ProvisionedConcurrencyUtilization metricTarget: 0.3 minCapacity: 2 maxCapacity: 30 currentError: alwaysAllocateCPU: trueプロビジョニングされたインスタンスが割り当てられた後、モデルは正常にデプロイされ、サービスの準備が整います。
関数のプロビジョニング済みインスタンスをリリースします。
次のコマンドを実行して自動スケーリングポリシーを無効にし、プロビジョニングされたインスタンスの数を0に設定します。
sudo s provision put --target 0 --qualifier LATEST -t s.yaml -a {access}次のコマンドを実行して、自動スケーリングポリシーが無効になっているかどうかを確認します。
s provision list -a {access}次の出力が返された場合、自動スケーリングポリシーは無効になります。
[2023-05-10 14:54:46] [INFO] [FC] - Getting list provision: gpu-best-practive-service End of method: provision
Function ComputeコンソールでGPU高速化インスタンスの自動スケーリングポリシーを設定する
前提条件
function ComputeでサービスとGPU関数が作成されます。 詳細については、「サービスの作成」および「カスタムコンテナ関数の作成」をご参照ください。
手順
Function Computeコンソールにログインします。 左側のナビゲーションウィンドウで、[サービスと機能] をクリックします。
サービスのインスタンスレベルのメトリックを有効にします。 詳細については、「インスタンスレベルのメトリックの収集の有効化」をご参照ください。
インスタンスレベルのメトリックを有効にすると、function Computeコンソールの関数モニタリングページで、関数呼び出しによって消費されたGPU関連のリソースを表示できます。
管理する関数をクリックします。 表示されるページで、[トリガー管理 (URL)] タブをクリックして、後続の関数テスト用のHTTPトリガーのURLを取得します。

関数をテストし、Function Computeコンソールモニタリング結果を表示します。
curlコマンドを実行して、関数をテストします。 コマンドでは、前の手順で取得したURLを使用します。
curl https://gpu-poretection-gpu-bes-service-gexsgx****.cn-shanghai.fcapp.run/invoke -H "Content-Type: text/plain" --data "Nice to meet you"次の出力が返されると、テストに合格します。
[{"text": "Nice to meet you", "porn_detection_label": 0, "porn_detection_key": "not_porn", "porn_probs": 0.0, "not_porn_probs": 1.0}]%Function Computeコンソールで、 を選択します。 ステップ2でデプロイされたサービスと関数をクリックします。 次に、[メトリック] タブをクリックして、GPU関連のメトリックの変更を表示します。
関数の詳細ページで、自動スケーリングタブをクリックし、ルールの作成.
自動スケーリングルールを作成するページで、ビジネス要件に基づいて次のパラメーターを設定し、作成.
インスタンスのバージョンと最小数を指定し、他のパラメーターのデフォルト値を保持します。
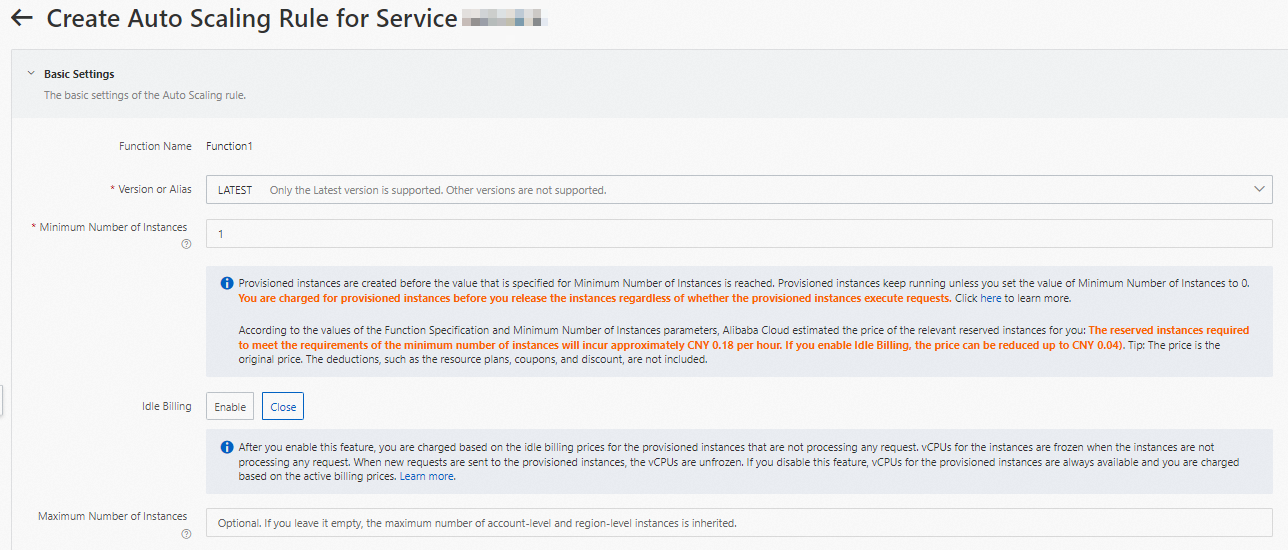
メトリックベースの設定の変更セクションで、をクリック+ 設定の追加ポリシーを設定します。
次の図に例を示します。

設定が完了したら、 を選択して、[関数プロビジョニング済みインスタンス (カウント)] メトリックの変更を表示できます。
プロビジョニングされたGPUアクセラレーションインスタンスが不要になった場合は、できるだけ早い機会にプロビジョニングされたGPUアクセラレーションインスタンスを削除してください。
ストレステストを実行する
Apache Benchなどの一般的なストレステストツールを使用して、HTTP関数のストレステストを実行できます。
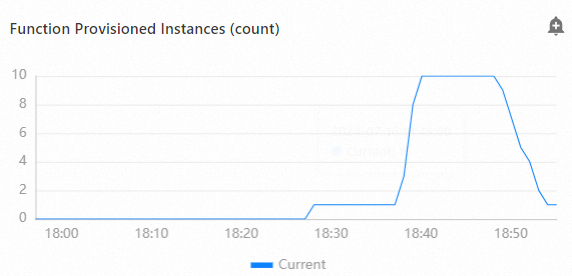
ストレステストが完了したら、Function Computeコンソールにログインし、管理する関数をクリックします。 関数の詳細ページで、 を選択してテスト結果を表示します。 メトリックの詳細は、プロビジョニングされた関数のインスタンスがストレステスト中に自動的にスケールアウトされ、ストレステスト後にスケールインされることを示しています。 以下の図は一例です。
よくある質問
Function Computeでリアルタイム推論サービスを使用するにはどれくらいの費用がかかりますか?
Function Computeの課金については、「課金の概要」をご参照ください。 プロビジョニングされたインスタンスの課金方法は、オンデマンドインスタンスの課金方法とは異なります。 請求書の詳細をメモしてください。
自動スケーリングポリシーを設定した後もレイテンシが発生するのはなぜですか。
トラフィックの急増に先立ってインスタンスを割り当てるように、より積極的な自動スケーリングポリシーを設定して、リクエストのバーストによる待ち時間を防ぐことができます。
追跡メトリックがしきい値に達したときにインスタンス数が増加しないのはなぜですか。
Function Computeのメトリクスは分単位で収集されます。 スケールアウト機構は、メトリック値が一定期間閾値に達した後にのみトリガされる。