Function Compute では、オンデマンドモードとプロビジョニング済みモードの 2 つのインスタンス使用モードを提供しています。合計インスタンス数およびインスタンスのスケーリング速度に関する制限に基づいて、自動スケーリングルールを設定できます。プロビジョニング済みモードでは、スケジュールされたスケーリングおよびメトリクスベースのスケーリングを活用して、プロビジョニング済みインスタンスの利用率を最適化できます。
インスタンスのスケーリング制限
オンデマンドインスタンスのスケーリング制限
関数呼び出しリクエストの処理において、Function Compute は、利用可能なインスタンスを優先的に使用します。現在のすべてのインスタンスが満杯の場合、Function Compute は新しいインスタンスを作成してリクエストを処理します。呼び出し数が増加すると、Function Compute は、リクエストを処理できる十分な数のインスタンスが確保されるか、設定されたインスタンス制限に達するまで、新しいインスタンスを作成し続けます。以下の制限がインスタンスのスケーリングに適用されます。
オンデマンドインスタンスの合計数:単一の Alibaba Cloud アカウント(ルートアカウント)は、デフォルトでリージョンごとに合計 100 インスタンスまでと制限されています。この合計には、オンデマンドインスタンスおよびプロビジョニング済みインスタンスの両方が含まれます。実際のクォータは、クォータセンター で指定されています。
実行中のインスタンスのスケーリング速度は、バースト可能インスタンスおよびインスタンスの増加率によって制限されます。各リージョンにおける制限については、「リージョン別のスケーリング速度制限」をご参照ください。
バースト可能インスタンス:即時に作成可能なインスタンスの数。デフォルトの制限は 100~300 です。
インスタンスの増加率:バースト可能インスタンスの制限に達した後に、1 分あたりに追加される新規インスタンスの割合。デフォルトの制限は 100~300 です。
インスタンスの合計数またはインスタンスのスケーリング速度が制限を超えると、Function Compute はスロットリングエラー(HTTP ステータス は 429)を返します。次の図は、呼び出し数が急激に増加するシナリオにおける Function Compute のスロットリング動作を示しています。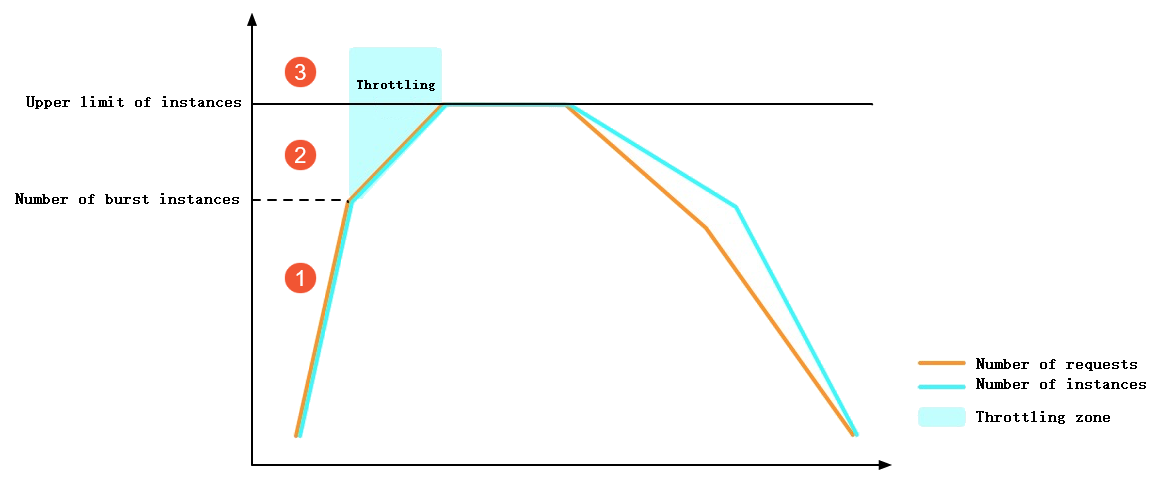
① 図中:バースト可能インスタンスの制限に達する前は、Function Compute が即時にインスタンスを作成します。このプロセスではコールドスタートが発生しますが、スロットリングエラーは発生しません。
② 図中:バースト可能インスタンスの制限に達した後は、レート制限によりインスタンスの増加が制約され、一部のリクエストでスロットリングエラーが発生します。
③ 図中:合計インスタンス数が制限を超えた後は、一部のリクエストでスロットリングエラーが発生します。
デフォルトでは、上記のスケーリング制限は、同一リージョン内の Alibaba Cloud アカウント配下のすべての関数で共有されます。特定の関数についてインスタンス数を制限するには、「関数レベルのオンデマンドインスタンス向けスケーリング制御」を設定できます。設定後、当該関数の実行中のインスタンス総数が制限を超えると、Function Compute はスロットリングエラーを返します。
プロビジョニング済みインスタンスのスケーリング制限
大量かつ急激な呼び出しの増加は、多数のインスタンス作成時にスロットリングおよびリクエスト失敗を引き起こす可能性があります。また、これらのインスタンスのコールドスタートにより、リクエストの遅延も増加します。こうした問題を回避するため、Function Compute では、あらかじめ関数インスタンスを準備するプロビジョニング済みインスタンスを使用できます。プロビジョニング済みインスタンスの数およびスケーリング速度に関する上限は、上記のスケーリング制限とは別に設定されており、互いに影響しません。
インスタンスの合計数:デフォルトでは、単一の Alibaba Cloud アカウント(ルートアカウント)は、リージョンごとに合計 100 インスタンスまでと制限されています。この合計には、オンデマンドインスタンスおよびプロビジョニング済みインスタンスの両方が含まれます。実際の制限については、「クォータセンター」をご参照ください。
プロビジョニング済みインスタンスのスケーリング速度:デフォルトは 1 分あたり 100~300 インスタンスであり、リージョンによって制限が異なります。「各リージョンにおけるスケーリング速度制限」をご参照ください。以下の図は、上記と同じ負荷シナリオにおける、プロビジョニング済みインスタンスを用いた Function Compute のスロットリング動作を示しています。
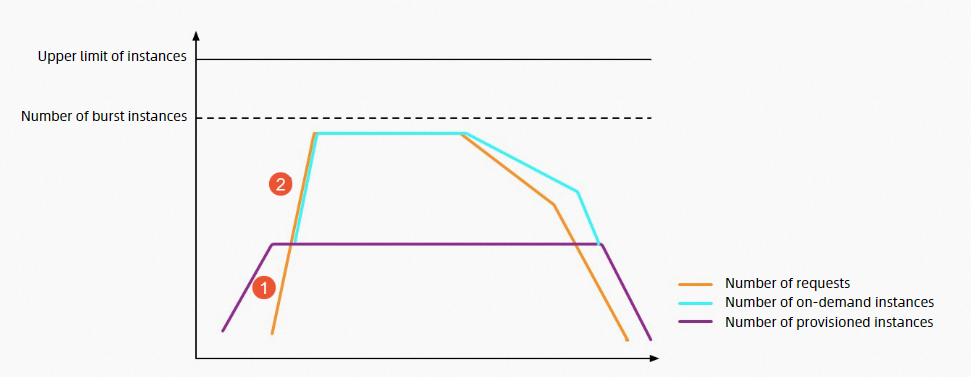
① 図中:プロビジョニング済みインスタンスが完全に活用される前は、リクエストが即時に実行されます。このプロセスではコールドスタートもスロットリングエラーも発生しません。
図の②部分:プロビジョニング済みインスタンスが完全に活用された後、かつオンデマンドインスタンスがバースト可能インスタンスの制限に達する前は、Function Compute が即時にインスタンスを作成します。このプロセスではコールドスタートが発生しますが、スロットリングエラーは発生しません。
リージョン別のスケーリング速度制限
リージョン | バースト可能インスタンス | インスタンスの増加率 |
中国 (杭州)、中国 (上海)、中国 (北京)、中国 (張家口)、中国 (深セン) | 300 | 300/分 |
その他のリージョン | 100 | 100/分 |
自動スケーリングルール
自動スケーリングルールの作成
「Function Compute コンソール」にログインします。左側のナビゲーションウィンドウで、[サービスと関数] をクリックします。
上部のナビゲーションバーでリージョンを選択します。[サービス] ページで、目的のサービスをクリックします。
- 「[関数]」ページで、変更対象の関数をクリックします。
「関数の詳細」ページで、Auto Scaling タブをクリックし、その後 ルールの作成 をクリックします。
「自動スケーリングルールの作成」ページで、関連するパラメーターを設定し、作成 をクリックします。
オンデマンドインスタンス向けのスケーリングを設定する
最小インスタンス数 を 0 に、最大インスタンス数 をオンデマンドインスタンスの最大数に設定します。最大インスタンス数 を設定しない場合、デフォルトで、現在のリージョンにおけるアカウントの最大インスタンス制限が適用されます。
説明[アイドルモード]、定期的な設定変更、および メトリックベースの設定変更 は、プロビジョニング済みモードでのみ有効です。
プロビジョニング済みインスタンス向けのスケーリングを設定する
パラメーター
説明
基本設定
バージョンまたはエイリアス
プロビジョニング済みインスタンスを作成するバージョンまたはエイリアスを選択します。
説明プロビジョニング済みインスタンスは、LATEST バージョンに対してのみ作成できます。
最小インスタンス数
プロビジョニング済みインスタンスの数を入力します。[最小インスタンス数] = プロビジョニング済みインスタンス数。
説明関数レベルのインスタンス数の最小値を制限することで、呼び出しに対する迅速な応答を確保し、コールドスタートを削減し、遅延の影響を受けやすいオンラインビジネスをよりよくサポートできます。
アイドルモード
アイドルモードを有効または無効にするかどうかを選択します。デフォルトでは無効です。各オプションの説明は以下のとおりです。
この機能を有効にすると、プロビジョニング済みインスタンスはリクエストを処理している間のみ vCPU を割り当てられます。それ以外の時間は、インスタンスの CPU がフリーズします。
アイドルモードが有効な場合、Function Compute は、関数のインスタンス同時実行数に基づき、リクエストを同じインスタンスに優先的にルーティングします。ただし、そのインスタンスが満杯になるまではこの処理を行います。たとえば、ある関数のインスタンス同時実行数が 50 であり、10 個のアイドル状態のプロビジョニング済みインスタンスがあると仮定します。Function Compute が同時に 40 個のリクエストを受信した場合、すべてのリクエストが単一のインスタンスにルーティングされ、そのインスタンスはアイドル状態からアクティブ状態に遷移します。
この機能を無効にすると、プロビジョニング済みインスタンスはリクエストを処理しているかどうかに関わらず、常に vCPU を割り当てられます。
最大インスタンス数
最大インスタンス数を入力します。[最大インスタンス数] = プロビジョニング済みインスタンス数 + オンデマンドインスタンスの最大数。
説明関数レベルのインスタンス数の最大値を制限することで、過剰な呼び出しにより単一の関数が過度に多くのインスタンスを占有することを防ぎ、バックエンドリソースを保護し、予期しないコスト発生を回避できます。
このパラメーターを空欄のままにした場合、デフォルトで、現在のリージョンにおけるアカウントの最大インスタンス制限が適用されます。
(任意)定期的な設定変更:スケジュールされたスケーリングルールを作成することで、プロビジョニング済みインスタンスをより柔軟に構成できます。これにより、指定された時刻にプロビジョニング済みインスタンスの数を所定の値に設定でき、ビジネスの同時実行数ニーズにより適合させることができます。動作方法および設定例については、「スケジュールされたスケーリング」をご参照ください。
ポリシー名
カスタムポリシー名を入力します。
最小インスタンス数
必要に応じて、プロビジョニング済みインスタンスの数を設定します。
[スケジュール式 (UTC)]
スケジュール情報です。例:cron(0 0 20 * * *)。詳細については、「パラメーターの説明」をご参照ください。
[有効期間 (UTC)]
スケジュールされた自動スケーリングルールが有効となる期間です。
(任意)メトリックベースの設定変更:各種インスタンスメトリクスまたはプロビジョニング済みインスタンスの同時実行数利用率の利用率に基づき、1 分ごとにプロビジョニング済みリソースをスケーリングします。動作方法および設定例については、「メトリクスベースのスケーリング」をご参照ください。
ポリシー名
カスタムポリシー名を入力します。
[インスタンス数の最小範囲]
当該ポリシーで調整されるプロビジョニング済みインスタンス数の許容範囲(最小値および最大値)を設定します。
利用タイプ
このパラメーターは、関数のインスタンスタイプが GPU インスタンスの場合にのみ有効です。利用率ベースの自動スケーリングポリシーで使用するメトリクスタイプを選択します。GPU インスタンス向けの自動スケーリングポリシーの詳細については、「プロビジョニング済み GPU モード向けの自動スケーリングポリシー」をご参照ください。
同時実行使用率のしきい値
目標利用率しきい値を設定します。利用率がこのしきい値を下回るとスケールインが発生し、超えるとスケールアウトが発生します。
有効時間(UTC)
メトリクスベースの自動スケーリングルールが有効となる期間です。
作成後、対象関数のプロビジョニング済みモードインスタンス構成をルール一覧で確認できます。
自動スケーリングルールの変更または削除
「Auto Scaling」ページで、作成済みのルール一覧を表示できます。一覧から対象のルールを見つけ、変更 または 削除 を、操作 列からクリックします。
プロビジョニング済みインスタンスを削除するには、最小インスタンス数 を 0 に設定します。
プロビジョニング済みモード向けの自動スケーリング手法
固定数のプロビジョニング済みインスタンスによる低利用率を回避するため、スケジュールされたスケーリングおよびメトリクスベースのスケーリングを活用できます。
スケジュールされたスケーリング
定義:スケジュールされたスケーリングでは、指定された時刻にプロビジョニング済みインスタンスの数を特定の値に設定することで、予測可能な同時実行数ニーズに容量を合わせます。
適用範囲:この手法は、明確な周期性や予測可能なトラフィックピークを持つ関数に適しています。関数呼び出しの同時実行数がスケジュールされたプロビジョニング済み値を超える場合、超過分の負荷は オンデマンドモード インスタンスによって処理されます。
設定例:次の図は、2 つのスケジュールされたアクションを含む設定を示しています。関数呼び出しトラフィックが到着する前に、最初のスケジュールされた設定によりプロビジョニング済みインスタンスが大規模にスケールアウトされます。トラフィックが減少した後、2 番目のスケジュールされた設定によりプロビジョニング済みインスタンスが小規模にスケールインされます。
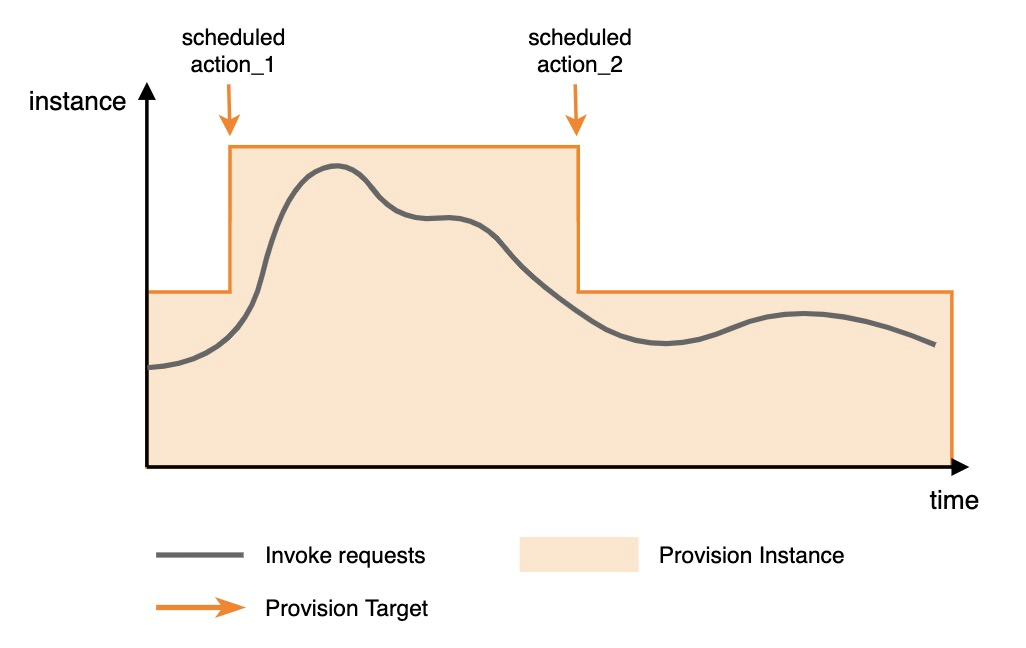
以下はパラメーターの例です。service_1 の function_1 に対してスケジュールされたスケーリングを設定します。この設定は 2022 年 11 月 1 日 10 時 00 分 00 秒から 2022 年 11 月 30 日 10 時 00 分 00 秒まで有効です。毎日 20 時にプロビジョニング済みインスタンスの数が 50 にスケールアウトされ、22 時に 10 にスケールインされます。スケジュールされたスケーリングを PutProvisionConfig API を使用して設定する場合のリクエストパラメーターの参考情報として、以下の情報をご活用ください。
{
"ServiceName": "service_1",
"FunctionName": "function_1",
"Qualifier": "alias_1",
"ScheduledActions": [
{
"Name": "action_1",
"StartTime": "2022-11-01T10:00:00Z",
"EndTime": "2022-11-30T10:00:00Z",
"TargetValue": 50,
"ScheduleExpression": "cron(0 0 20 * * *)"
},
{
"Name": "action_2",
"StartTime": "2022-11-01T10:00:00Z",
"EndTime": "2022-11-30T10:00:00Z",
"TargetValue": 10,
"ScheduleExpression": "cron(0 0 22 * * *)"
}
]
}各パラメーターの説明は以下のとおりです。
パラメーター | 説明 |
Name | スケジュールタスクの名前です。 |
StartTime | 設定が有効になる時刻(UTC 形式)です。 |
EndTime | 設定が有効期限切れとなる時刻(UTC 形式)です。 |
TargetValue | プロビジョニング済みインスタンスの目標数です。 |
ScheduleExpression | スケジュール情報です。2 種類の形式がサポートされています。
|
cron 式のフィールドは、秒、分、時、月の日、月、週の日に相当します。それぞれの説明は以下のとおりです。
表 1. フィールドの説明
フィールド | 許容される値 | 許容される特殊文字 |
秒 | 0~59 | なし |
会議録 | 0~59 | , - * / |
時 | 0~23 | , - * / |
月の日 | 1~31 | , - * ? / |
月 | 1~12 または JAN~DEC | , - * / |
週の日 | 1~7 または MON~SUN | , - * ? |
表 2. 特殊文字の説明
文字 | 定義 | 例 |
* | 任意またはすべてを意味します。 | 「 |
, | 値のリストを意味します。 |
|
- | 範囲を意味します。 |
|
? | 不確定な値を意味します。 | 他の指定された値と併用されます。たとえば、特定の日付を指定するが、その曜日は問わない場合、 |
/ | 値の増分を意味します。n/m は、n から始まる m の増分を意味します。 |
|
メトリクスベースのスケーリング
定義:監視メトリクスを追跡することで、プロビジョニング済みモードの関数インスタンスを動的にスケーリングします。
適用範囲:Function Compute システムは、定期的にプロビジョニング済みインスタンスの同時実行数またはリソース利用率に関するメトリクスを収集します。システムはこれらのメトリクスおよび設定されたスケールアウトおよびスケールインのトリガー値を用いて、プロビジョニング済みモードの関数インスタンスのスケーリングを制御します。このプロセスにより、プロビジョニング済みインスタンスの数が実際のリソース使用量に密接に一致するようになります。
動作方法:メトリクスベースの追跡自動スケーリングは、メトリクス条件に基づき、1 分ごとにプロビジョニング済みリソースを調整します。
メトリクスがスケールアウトしきい値を超えると、積極的なポリシーが開始され、プロビジョニング済みインスタンスの数を素早く目標値まで拡大します。
メトリクスがスケールインしきい値を下回ると、慎重なポリシーが開始され、プロビジョニング済みインスタンスの数を徐々にスケールイン目標に近づけます。
システムで最大および最小スケーリング値を設定した場合、プロビジョニング済み関数インスタンスの数はこれらの値の間でスケーリングされます。最大値に達するとスケールアウトが停止し、最小値に達するとスケールインが停止します。
設定例:次の図は、プロビジョニング済みインスタンス利用率メトリクスに基づくスケーリングの例を示しています。
トラフィックが増加すると、スケールアウトしきい値がトリガーされ、プロビジョニング済み関数インスタンスがスケールアウトを開始します。設定された最大値に達すると、スケールアウトが停止し、超過分のリクエストはオンデマンド関数インスタンスに割り当てられます。
トラフィックが減少すると、スケールインしきい値がトリガーされ、プロビジョニング済み関数インスタンスがスケールインを開始します。
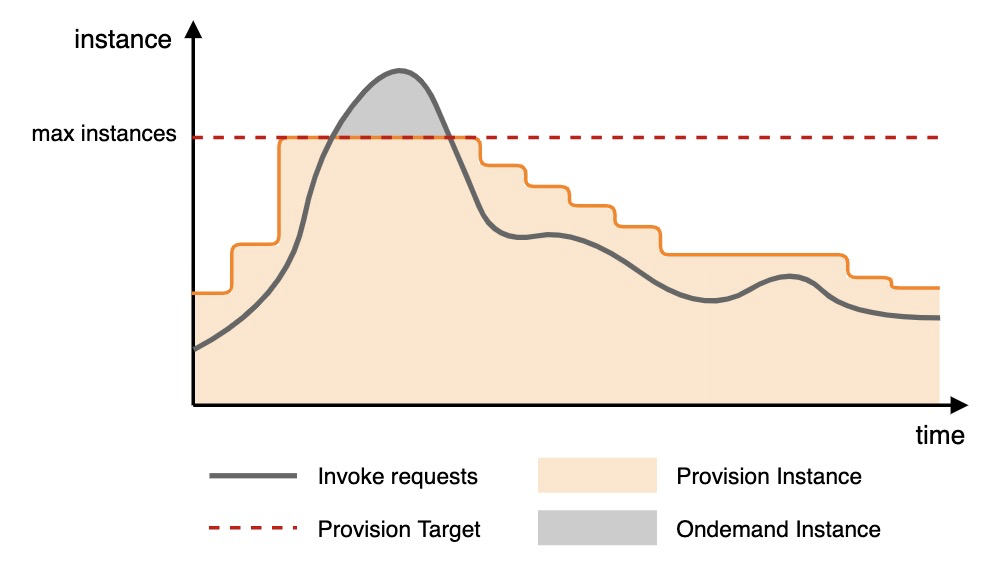
プロビジョニング済み関数インスタンスの同時実行数利用率は、プロビジョニング済みインスタンスの同時実行数のみに基づき、オンデマンドモードのデータは含みません。
メトリクス計算:プロビジョニング済み関数インスタンスが処理中の同時実行リクエスト数を、すべてのプロビジョニング済み関数インスタンスが処理可能な最大同時実行リクエスト数で割った比率です。値の範囲は 0~1 です。
異なるインスタンス同時実行数設定における、プロビジョニング済みインスタンスの最大同時実行リクエスト容量の計算ロジックは以下のとおりです。「インスタンス同時実行数の設定」をご参照ください。
インスタンスあたり 1 リクエスト:最大同時実行リクエスト数 = プロビジョニング済みインスタンス数
インスタンスあたり複数リクエスト:最大同時実行リクエスト数 = プロビジョニング済みインスタンス数 × インスタンス同時実行数
スケールアウトおよびスケールインの目標値
目標値は、現在のメトリクス値、メトリクス追跡値、現在のプロビジョニング済み関数インスタンス数、およびスケールイン係数によって決定されます。
スケーリング計算の原則:スケールイン時は、比較的慎重なスケールインプロセスを実現するためにスケールイン係数が使用されます。スケールイン係数の範囲は 0(排他)~1(包括)です。スケールイン係数は、スケールイン速度を遅くして過剰な速さを防ぐために使用されるシステムパラメーターであり、ユーザーが設定する必要はありません。最終的なスケーリング目標値は、計算結果を切り上げることで得られます。計算ロジックは以下のとおりです。
スケールアウト目標 = 現在のプロビジョニング済み関数インスタンス数 × (現在のメトリクス値 / メトリクス追跡値)
削除するインスタンス数 = 現在のプロビジョニング済み関数インスタンス数 × スケールイン係数 × (1 - 現在のメトリクス値 / メトリクス追跡値)
スケールアウト目標の計算例:現在のメトリクス値が 80 %、メトリクス目標値が 40 %、現在のプロビジョニング済み関数インスタンス数が 100 の場合、計算は 100 × (80 % / 40 %) = 200 となります。スケール後のメトリクス目標値が約 40 % に保たれるよう、プロビジョニング済み関数インスタンス数を 200 にスケールアウトします。
以下はパラメーターの例です。service_1 の function_1 に対してメトリクスベースの追跡自動スケーリングを設定します。この設定は 2022 年 11 月 1 日 10 時 00 分 00 秒から 2022 年 11 月 30 日 10 時 00 分 00 秒まで有効です。プロビジョニング済み関数インスタンスの ProvisionedConcurrencyUtilization メトリクスを追跡します。同時実行数利用率の追跡値は 60 % です。利用率が 60 % を超えるとスケールアウトイベントが発生し、最大容量は 100 です。利用率が 60 % を下回るとスケールインイベントが発生し、最小容量は 10 です。メトリクスベースのスケーリングを PutProvisionConfig API を使用して設定する場合のリクエストパラメーターの参考情報として、以下の情報をご活用ください。
{
"ServiceName": "service_1",
"FunctionName": "function_1",
"Qualifier": "alias_1",
"TargetTrackingPolicies": [
{
"Name": "action_1",
"StartTime": "2022-11-01T10:00:00Z",
"EndTime": "2022-11-30T10:00:00Z",
"MetricType": "ProvisionedConcurrencyUtilization",
"MetricTarget": 0.6,
"MinCapacity": 10,
"MaxCapacity": 100,
}
]
}各パラメーターの説明は以下のとおりです。
パラメーター | 説明 |
Name | メトリクスベースのタスクの名前です。 |
StartTime | 設定が有効になる時刻(UTC 形式)です。 |
EndTime | 設定が有効期限切れとなる時刻(UTC 形式)です。 |
MetricType | 追跡対象のメトリクスです。有効な値:ProvisionedConcurrencyUtilization。 |
MetricTarget | メトリクスの目標値です。 |
MinCapacity | スケーリング対象の最小インスタンス数です。 |
MaxCapacity | スケーリング対象の最大インスタンス数です。 |
関連ドキュメント
オンデマンドモードおよびプロビジョニング済みモードの基本概念および課金方法については、「インスタンスタイプおよび使用モード」をご参照ください。
自動スケーリングを設定した後に使用中のプロビジョニング済みインスタンス数を確認するには、「FunctionProvisionedCurrentInstance」メトリクスを確認します:「関数レベルのメトリクス」をご参照ください。