この Topic では、Function Compute を使用して AI 推論アプリケーションをデプロイする際のモデルの一般的な保存方法について説明します。また、各方法の長所、短所、および適用可能なシナリオを比較します。
背景情報
関数のストレージタイプの詳細については、「関数のストレージタイプを選択する」をご参照ください。以下の 2 つのストレージタイプは、GPU インスタンスにモデルを保存するのに適しています。
さらに、GPU 関数はカスタムコンテナイメージを使用してサービスをデプロイします。したがって、モデルファイルをコンテナイメージに直接パッケージ化することもできます。
各方法には、独自のアプリケーションシナリオと技術的な特徴があります。モデルのストレージ方法を選択する際には、特定のニーズ、実行環境、チームのワークフローを考慮して、効率とコストのバランスを取る必要があります。
コンテナイメージでモデルを配布する
トレーニング済みのモデルと関連するアプリケーションコードをコンテナイメージにまとめてパッケージ化することは、モデルファイルを配布するための最も直接的な方法の 1 つです。
長所と短所
長所:
利便性: イメージを作成した後、追加の構成なしで直接実行して推論を行うことができます。
一貫性: すべての環境でモデルのバージョンが一貫していることを保証します。これにより、バージョンの不一致による問題が減少します。
短所:
イメージサイズ: イメージは、特に大規模なモデルの場合、非常に大きくなる可能性があります。
時間のかかる更新: モデルが更新されるたびにイメージを再構築して再配布する必要があり、これは時間のかかるプロセスです。
注意事項
プラットフォームは、関数インスタンスのコールドスタート速度を向上させるためにコンテナイメージを前処理します。ただし、イメージが大きすぎると、プラットフォームのイメージサイズ制限を超え、イメージアクセラレーションの前処理に必要な時間が増加する可能性があります。プラットフォームのイメージサイズ制限の詳細については、「GPU イメージのサイズ制限は何ですか?」をご参照ください。
シナリオ
モデルサイズが比較的小さい場合、たとえば数百メガバイトなど。
モデルの変更が頻繁でない場合は、コンテナイメージにパッケージ化できます。
モデルファイルが大きい場合、頻繁に更新される場合、またはイメージと共に公開されるときにプラットフォームのイメージサイズ制限を超える場合は、モデルをイメージから分離する必要があります。
File Storage NAS にモデルを保存する
Function Compute プラットフォームでは、NAS ファイルシステムを関数インスタンスの指定されたディレクトリにマウントできます。モデルを NAS ファイルシステムに保存した後、アプリケーションは NAS マウントポイントディレクトリにアクセスしてモデルファイルを読み込むことができます。
長所と短所
長所:
互換性: Filesystem in Userspace (FUSE) ベースのファイルシステムと比較して、NAS が提供する
POSIXファイルインターフェイスはより完全で成熟しています。これにより、アプリケーションの互換性が向上します。容量: NAS はペタバイト級のストレージ容量を提供できます。
短所:
VPC ネットワークへの依存: 関数が NAS マウントポイントにアクセスするには、VPC アクセスチャネルを構成する必要があります。これには、さまざまなクラウドプロダクトに対する多数の権限が含まれます。さらに、関数インスタンスのコールドスタート中、プラットフォームがインスタンスの VPC アクセスチャネルを確立するのに数秒かかります。
限定されたコンテンツ管理: NAS ファイルシステムは使用前にマウントする必要があります。また、モデルファイルを NAS インスタンスに配布するためのビジネスプロセスを確立する必要もあります。
アクティブ/アクティブまたはマルチ AZ デプロイメントをサポートしていません。詳細については、「NAS よくある質問」をご参照ください。
注意事項
多くのコンテナーが同時に起動してモデルを読み込むと、NAS の帯域幅のボトルネックに容易に達します。これにより、インスタンスの起動時間が増加し、タイムアウトによる障害が発生する可能性があります。たとえば、これは、スケジュールされた HPA が予約済みの GPU インスタンスをバッチで起動する場合や、トラフィックのバーストが多くのオンデマンド GPU インスタンスの作成をトリガーする場合に発生する可能性があります。
コンソールから NAS パフォーマンスモニタリングを表示 (読み取りスループット) できます。
NAS のデータ量を増やすことで、読み取りおよび書き込みスループットを向上させることができます。
NAS を使用してモデルファイルを保存する場合は、汎用型 NAS ファイルシステムのパフォーマンスタイプを選択します。これは、この NAS タイプが約 600 MB/s の高い初期読み取り帯域幅を提供するためです。詳細については、「汎用型 NAS ファイルシステム」をご参照ください。
シナリオ
非常に高速な起動パフォーマンスを必要とするオンデマンド GPU シナリオ。
Object Storage Service (OSS) にモデルを保存する
Function Compute プラットフォームでは、OSS バケットを関数インスタンスの指定されたディレクトリにマウントできます。その後、アプリケーションは OSS マウントポイントから直接モデルを読み込むことができます。
長所
帯域幅: OSS には高い帯域幅制限があります。NAS と比較して、関数インスタンス間の帯域幅の競合は起こりにくいです。詳細については、「OSS の制限とパフォーマンスメトリック」をご参照ください。また、OSS アクセラレータを有効にして、より高いスループットを得ることもできます。
複数の管理方法:
OSS は、コンソールやオープン API などのアクセスチャネルを提供します。
OSS は、ローカルで利用可能なさまざまな管理ツールを提供します。詳細については、「OSS 開発者ツール」をご参照ください。
OSS の クロスリージョンレプリケーション機能を使用して、モデルの同期と管理を行うことができます。
簡単な構成: NAS ファイルシステムと比較して、OSS バケットを関数インスタンスにマウントする場合、VPC アクセスは不要で、構成後すぐに使用できます。
コスト: 一般的に、OSS は NAS よりもコスト効率が高いです。
注意事項
原則として、OSS マウントは Filesystem in Userspace (FUSE) メカニズムを使用して実装されます。アプリケーションが OSS マウントポイント上のファイルにアクセスすると、プラットフォームはそのアクセスリクエストを OSS API 呼び出しに変換します。したがって、OSS マウントには次の特徴があります。
ユーザーモードで実行され、CPU、メモリ、一時ストレージなど、関数インスタンスのリソースクォータを消費します。したがって、より大きな仕様の GPU インスタンスで使用する必要があります。
データは OSS API を使用してアクセスされます。スループットと待機時間は、最終的に OSS API サービスによって制限されます。したがって、この方法は、モデルの読み込みシナリオなど、少数の大きなファイルへのアクセスに適しており、多数の小さなファイルへのアクセスには適していません。
現在の実装では、システムのページキャッシュは有効になっていません。NAS ファイルシステムとは異なり、これは、単一インスタンス内のアプリケーションが同じモデルファイルに複数回アクセスする必要がある場合に、ページキャッシュアクセラレーションの恩恵を受けることができないことを意味します。
シナリオ
多くのインスタンスがモデルを並行して読み込み、インスタンス間の帯域幅不足を避けるために、より高いストレージスループットが必要な場合。
ローカル冗長ストレージまたはマルチリージョンデプロイメントを必要とするシナリオ。
モデルの読み込みシナリオなど、少数の大きなファイルにアクセスする場合。
比較のまとめ
項目 | イメージで配布 | NAS のマウント | OSS のマウント |
モデルサイズ |
| なし | なし |
スループット | 比較的速い |
|
|
互換性 | 良好 | 良好 |
|
管理方法 | コンテナイメージ | VPC 内でのマウントと使用 |
|
マルチ AZ | サポート | 非サポート | サポート |
ページキャッシュ有効 | はい | はい。 | いいえ |
コスト | 追加コストなし | 一般的に、NAS は OSS よりもわずかに高価です。実際のコストは、各プロダクトの現在の課金ルールに従います。
| |
比較に基づき、さまざまな使用パターン、同時コンテナ起動数、およびモデル管理のニーズを考慮した、FC GPU インスタンスでのモデルホスティングのベストプラクティスは次のとおりです。
非常に高速な起動パフォーマンスを必要とするオンデマンド GPU シナリオでは、パフォーマンスタイプの汎用型 NAS ファイルシステムを使用します。
コンテナの起動時間が重要でないプロビジョニング済み GPU シナリオでは、OSS を使用します。
多くの GPU コンテナが同時に起動するシナリオでは、OSS アクセラレータを使用して、NAS の単一点帯域幅ボトルネックを回避します。
マルチリージョンのユニット化されたデプロイメントシナリオでは、OSS と OSS アクセラレータを使用して、モデル管理の複雑さとクロスリージョン同期の困難さを軽減します。
テストデータ
このセクションでは、Stable Diffusion モデルの切り替えにかかる時間を測定することで、モデルストレージ方法間のパフォーマンスの違いを比較します。このテストで使用されたモデルとそのサイズを次の表に示します。
モデル | サイズ (GB) |
Anything-v4.5-pruned-mergedVae.safetensors | 3.97 |
Anything-v5.0-PRT-RE.safetensors | 1.99 |
CounterfeitV30_v30.safetensors | 3.95 |
Deliberate_v2.safetensors | 1.99 |
DreamShaper_6_NoVae.safetensors | 5.55 |
cetusMix_Coda2.safetensors | 3.59 |
chilloutmix_NiPrunedFp32Fix.safetensors | 3.97 |
pastelmix-fp32.ckpt | 3.97 |
revAnimated_v122.safetensors | 5.13 |
sd_xl_base_1.0.safetensors | 6.46 |
モデル切り替え時間 (初回) (秒) | モデル切り替え時間 (2 回目) (秒) |
|
|
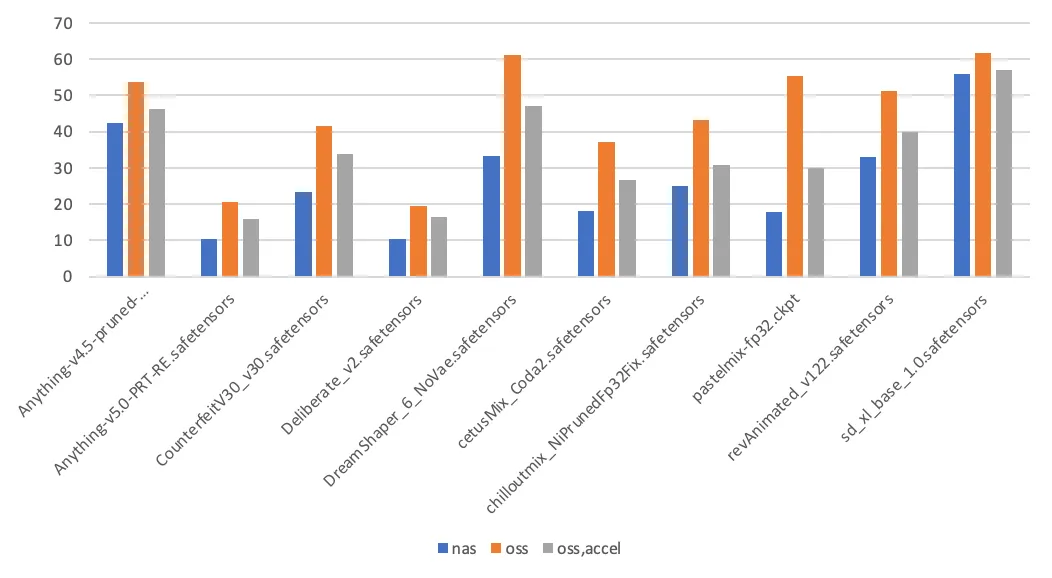
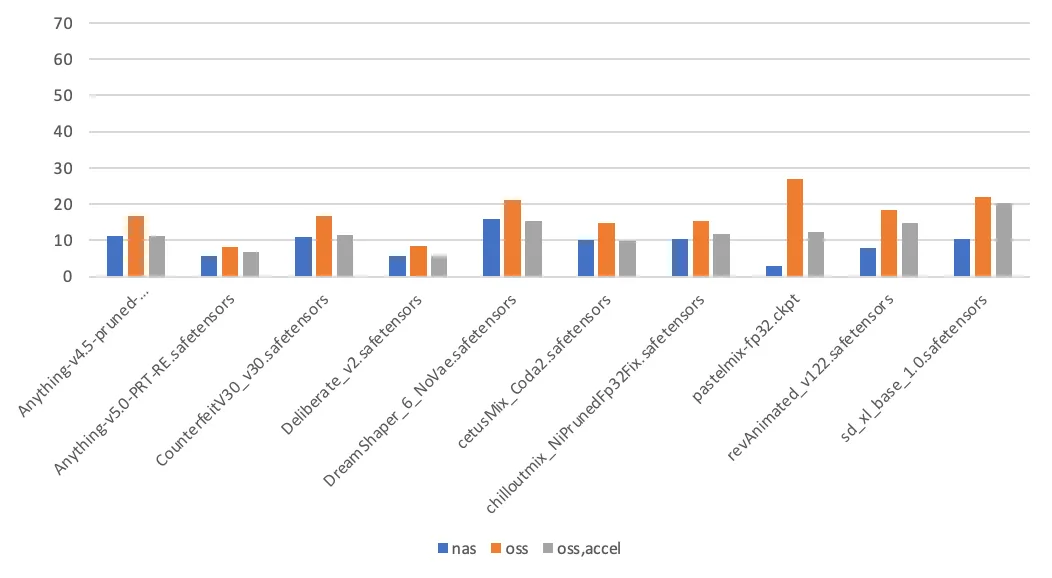
テストの結論は次のとおりです。
ページキャッシュ有効: Stable Diffusion が初めてモデルを読み込むとき、モデルファイルを 2 回読み取ります。1 回目はモデルファイルのハッシュ値を計算するため、2 回目は実際の読み込みのためです。その後のモデルの読み込みでは、モデルファイルは 1 回だけ読み取られます。NAS マウントポイント上のファイルに初めてアクセスすると、カーネルはページキャッシュを埋め、2 回目のアクセスを高速化します。対照的に、OSS マウントポイントへのアクセスではページキャッシュは使用されません。
読み込み時間に影響を与えるその他の要因: 記憶媒体に加えて、モデルの読み込みにかかる時間は、アプリケーションの実装の詳細にも関連しています。これらの詳細には、アプリケーションのスループット容量や、モデルファイルの読み取りに使用される I/O モード (シーケンシャルリードまたはランダムリード) が含まれます。