このトピックでは、Model Studio のモデルサービスを用いたデータ分析方法について説明します。
背景情報
Model Studio は、AI 開発者およびビジネスチームが大規模言語モデル(LLM)を使用したアプリケーションを構築するためのワンストッププラットフォームです。Realtime Compute for Apache Flink のリアルタイムコンピューティング機能と深く統合されており。Model Studio の LLM 機能を迅速に呼び出し、Flink のリアルタイムデータ処理パイプラインと組み合わせることで、データインジェストからインテリジェントな意思決定までのプロセスを大幅に短縮できます。以下のセクションでは、2 つのコアモデルのユースケースについて説明します。
chat/completions モデル chat/completions モデルは、対話生成およびテキスト理解に基づく大規模言語モデルです。感情分析、インテント認識、質問応答システムなどのシナリオで広く使用されています。
感情分析:ご利用のビジネスに関するソーシャルメディア上のコメントをリアルタイムで感情分類し、ユーザーの感情を「ポジティブ」「ネガティブ」「ニュートラル」のいずれかに識別します。
インテリジェントカスタマーサービス:対話生成機能により、自然言語でのインタラクションを提供します。
コンテンツモデレーション:テキスト内のセンシティブなコンテンツやポリシー違反を自動検出し、より効率的なコンテンツセキュリティ監査を実現します。
埋め込みモデル 埋め込みモデルは、テキストを高次元ベクトル表現に変換します。一般的な用途には、セマンティック検索、レコメンデーションシステム、知識グラフの構築などがあります。
セマンティック検索:商品説明やユーザークエリをベクトル化することで、関連性に基づくセマンティック検索を実現します。
レコメンデーションシステム:テキストのベクトル化により、ユーザーの興味と商品の特徴との関連性を発見し、レコメンデーション精度を向上させます。
知識グラフ:非構造化テキストをベクトル形式に変換し、その後の知識抽出および関係モデリングを簡素化します。
前提条件
Flink ワークスペースをアクティベートしました。詳細については、「Realtime Compute for Apache Flink のアクティベート」をご参照ください。
Model Studio ワークスペースを有効化済みであり、Realtime Compute for Apache Flink の開発コンソールとのネットワーク接続を確立済みである必要があります。VPC 経由で Model Studio にアクセスする場合は、「プライベートネットワーク経由での Model Studio 内のモデルまたはアプリケーションの API アクセス」をご参照ください。
ドメイン名を使用して Model Studio にアクセスする場合は、Realtime Compute for Apache Flink の開発コンソールにそのドメイン名を登録する必要があります。詳細については、「ドメイン名の管理」をご参照ください。
制限事項
この機能は、Ververica Runtime (VVR) 11.1 以降でのみサポートされます。
ステップ 1:Model Studio モデルの登録
詳細については、「モデルの設定」をご参照ください。
Chat/completions モデル
次のサンプル SQL コードは、qwen-turbo モデルを登録する方法を示しています。
CREATE MODEL ai_analyze_sentiment
INPUT (`input` STRING)
OUTPUT (`content` STRING)
WITH (
'provider'='bailian',
'endpoint'='<base_url>/compatible-mode/v1/chat/completions', -- chat/completions モデルタスク用のエンドポイント。
'api-key' = '<YOUR KEY>',
'model'='qwen-turbo', -- Qwen-turbo モデル。
'system-prompt' = 'Classify the text below into one of the following labels: [positive, negative, neutral, mixed]. Output only the label.'
);endpoint パラメーター値の <base_url> 部分は、アクセス方法に応じて置き換えてください。
インターネット経由で Model Studio にアクセスする場合、
<base_url>をhttps://dashscope-intl.aliyuncs.comに置き換えます。VPC 経由でプライベートネットワーク経由で Model Studio にアクセスする場合、
<base_url>をhttps://vpc-ap-southeast-1.dashscope.aliyuncs.comに置き換えます。説明endpointパラメーターは HTTPS プロトコルのみをサポートします。
埋め込みモデル
次のサンプル SQL コードは、text-embedding-v3 モデルを登録する方法を示しています。
CREATE MODEL embedding_model
INPUT (`input` STRING)
OUTPUT (`embeddings` ARRAY<FLOAT>)
WITH (
'provider'='bailian',
'endpoint'='https://dashscope.aliyuncs.com/compatible-mode/v1/embeddings', -- 埋め込みモデルタスク用のエンドポイント。
'api-key' = '<YOUR KEY>',
'model'='text-embedding-v3' -- text-embedding-v3 モデル。
);ステップ 2:ジョブの作成
SQL ストリーミングジョブの下書きを作成します。詳細については、「Flink SQL ジョブ」をご参照ください。
ステップ 3:LLM 分析用の SQL ジョブの記述
Chat/completions モデル
ML_PREDICT AI 関数を使用して、登録済みの ai_analyze_sentiment モデルを呼び出し、映画レビューに対して感情分析を実行します。
ML_PREDICT 文に関連付けられた Flink 演算子のスループットは、Model Studio によるレート制限の影響を受けます。Model Studio へのリクエスト上限に達すると、Flink ジョブでバックプレッシャーが発生し、ML_PREDICT 演算子がボトルネックとなります。厳しいレート制限により、関連演算子でタイムアウトエラーがトリガーされ、ジョブが再起動する可能性があります。Model Studio における各モデルのレート制限条件は確認可能です。詳細については、「QPS およびトークンの使用制限」をご参照ください。制限の解除方法については、営業担当またはプリセールス・アフターセールスのスペシャリストにお問い合わせください。
次のサンプル SQL を SQL エディターにコピーしてください。
-- 一時的な結果テーブルを作成します。
CREATE TEMPORARY TABLE print_sink(
id BIGINT,
movie_name VARCHAR,
predict_label VARCHAR,
actual_label VARCHAR
) WITH (
'connector' = 'print', -- print コネクタを使用します。
'logger' = 'true' -- 結果をコンソールに表示します。
);
-- テストデータを構築するための一時ビューを作成します。
-- | id | movie_name | comment | actual_label |
-- | 1 | Her Story | My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving. | POSITIVE |
-- | 2 | The Dumpling Queen | Unremarkable. | NEGATIVE |
CREATE TEMPORARY VIEW movie_comment(id, movie_name, user_comment, actual_label)
AS VALUES (1, 'Her Story', 'My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving.', 'positive'), (2, 'The Dumpling Queen', 'Unremarkable.', 'negative');
INSERT INTO print_sink
SELECT id, movie_name, content as predict_label, actual_label
FROM ML_PREDICT(
TABLE movie_comment,
MODEL ai_analyze_sentiment, -- 登録済みの Qwen-turbo モデル。
DESCRIPTOR(user_comment)); 埋め込みモデル
ML_PREDICT AI 関数を使用して、登録済みの embedding_model モデルを呼び出し、映画レビューの埋め込みベクトルを生成した後、結果を Milvus (パブリックプレビュー) に書き込みます。
ML_PREDICT 文に関連付けられた Flink 演算子のスループットは、Model Studio によるレート制限の影響を受けます。Model Studio へのリクエスト上限に達すると、Flink ジョブでバックプレッシャーが発生し、ML_PREDICT 演算子がボトルネックとなります。厳しいレート制限により、関連演算子でタイムアウトエラーがトリガーされ、ジョブが再起動する可能性があります。Model Studio における各モデルのレート制限条件は確認可能です。詳細については、「QPS およびトークンの使用制限」をご参照ください。制限の解除方法については、営業担当またはプリセールス・アフターセールスのスペシャリストにお問い合わせください。
次のサンプル SQL を SQL エディターにコピーしてください。
-- milvus_sink という名前の一時的な結果テーブルを作成します。
CREATE TEMPORARY TABLE milvus_sink
(
id STRING,
movie_name STRING,
user_comment STRING,
embeddings ARRAY<FLOAT>,
PRIMARY KEY (id) NOT ENFORCED
)
WITH (
'connector' = 'milvus',
'endpoint' = '<YOUR-ENDPOINT>',
'port' = '<YOUR-PORT>',
'userName' = '<YOUR-USERNAME>',
'password' = '<YOUR-PASSWORD>',
'databaseName' = 'default',
'collectionName' = 'movie-comment-embeddings'
);
-- テストデータを構築するための一時ビューを作成します。
-- | id | movie_name | comment |
-- | 1 | Her Story |My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving.|
-- | 2 | The Dumpling Queen | Unremarkable. |
CREATE TEMPORARY VIEW movie_comment(id, movie_name, user_comment)
AS VALUES ('1', 'Her Story', 'My favorite part was when the kid guessed the sounds. It is one of the most romantic narratives I have seen in movies. Very gentle and loving.'), ('2', 'The Dumpling Queen', 'Unremarkable.');
INSERT INTO
milvus_sink
SELECT
id,
movie_name,
user_comment,
embeddings
FROM
ML_PREDICT (
TABLE movie_comment,
MODEL embedding_model, -- 登録済みの text-embedding-v3 モデル。
DESCRIPTOR (user_comment)
);ステップ 4:ジョブのデプロイと開始
ジョブをデプロイして開始します。詳細については、「Flink SQL ジョブ」をご参照ください。
ステップ 5:分析結果の確認
Chat/completions モデル
ジョブのステータスが FINISHED であることを確認します。
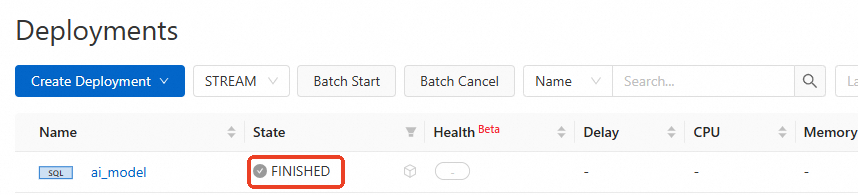
コンソールで、Deployments ページに移動し、対象ジョブの名前をクリックします。
Logs タブで、Task Managers サブタブをクリックし、current TaskManager を選択します。
Log をクリックし、PrintSinkOutputWriter に関連するログを検索します。
モデルが予測したラベル
predict_labelは、実際のラベルactual_labelと一致します。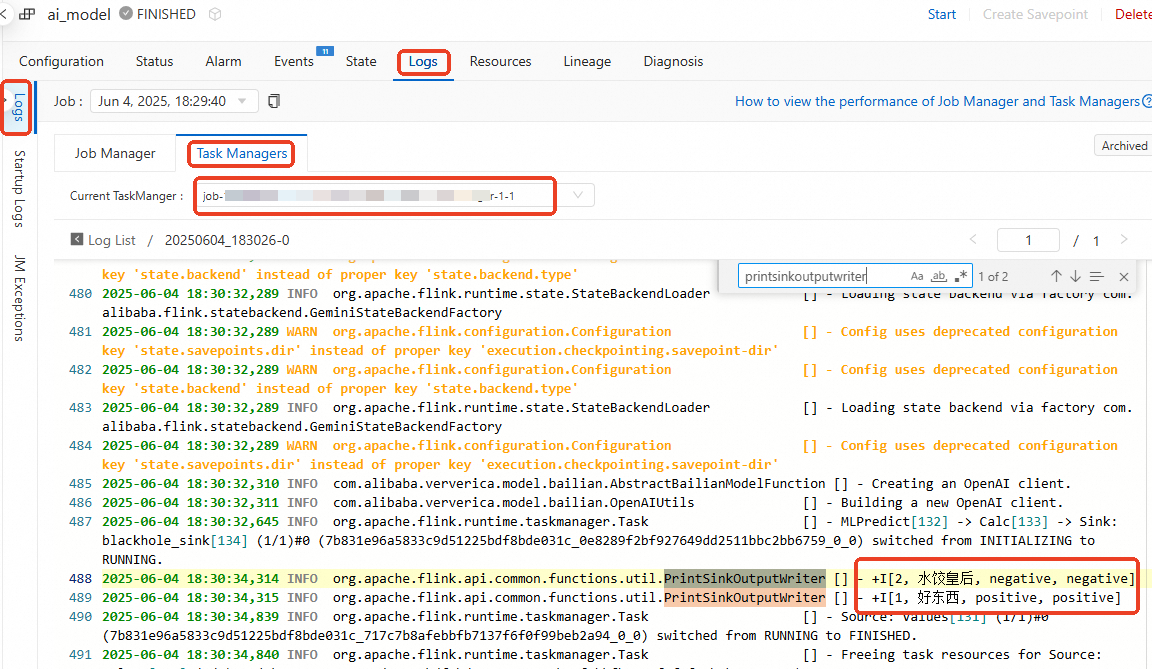
関連ドキュメント
AI モデルのデータ定義言語(DDL)文:「モデルの設定」
AI 関数:「ML_PREDICT」
ベクトル検索サービス:「Milvus (パブリックプレビュー)」