このトピックでは、Realtime Compute for Apache Flink の開発コンソールで Python ストリーミングデプロイメントと Python バッチデプロイメントを作成して開始する方法について説明します。
前提条件
RAM ユーザーまたは RAM ロールに必要な権限が付与されていること。Realtime Compute for Apache Flink の開発コンソールに RAM ユーザーまたは RAM ロールを使用してアクセスする場合、この前提条件を満たす必要があります。 詳細については、「権限管理」をご参照ください。
Realtime Compute for Apache Flink ワークスペースが作成されていること。 詳細については、「Realtime Compute for Apache Flink をアクティブ化する」をご参照ください。
ステップ 1:Python コードファイルを準備する
Python パッケージは Realtime Compute for Apache Flink の管理コンソール では開発できません。そのため、オンプレミス環境で Python ファイルを開発する必要があります。 デプロイメントをデバッグする方法とコネクタを使用する方法の詳細については、「Python API ドラフトを開発する」をご参照ください。
Python パッケージを開発するときに使用する Flink のバージョンは、ステップ 3:Python デプロイメントを作成する で選択したエンジンバージョンの Flink のバージョンと同じである必要があります。 Python デプロイメントでは依存関係を使用できます。 依存関係には、カスタム Python 仮想環境、サードパーティ Python パッケージ、JAR パッケージ、およびデータファイルが含まれます。 詳細については、「Python 依存関係を使用する」をご参照ください。
Realtime Compute for Apache Flink の開発コンソールで Python デプロイメントに対するさまざまな操作をすばやく実行できるように、後続の操作のためにテスト Python ファイルと入力データファイルが提供されています。 このテスト Python ファイルは、入力データファイルに単語が出現する回数を収集するために使用されます。
デプロイメントのタイプに基づいてテスト Python ファイルをダウンロードします。
ストリーミングデプロイメントのテスト Python ファイルをダウンロードします:word_count_streaming.py。
バッチデプロイメントのテスト Python ファイルをダウンロードします:word_count_batch.py。
入力データファイル Shakespeare をダウンロードします。
ステップ 2:テスト Python ファイルと入力データファイルをアップロードする
ターゲットワークスペースを見つけ、[アクション] 列の [コンソール] をクリックします。
Realtime Compute for Apache Flink 開発コンソールの左側のナビゲーションウィンドウで、[アーティファクト] をクリックします。
[アーティファクト] ページの左上隅にある [アーティファクトのアップロード] をクリックし、テスト Python ファイルとデータファイルを選択します。
このトピックでは、ステップ 1 でダウンロードしたテスト Python ファイルと入力データファイルをアップロードします。 ファイルのディレクトリの詳細については、「アーティファクトを管理する」をご参照ください。
ステップ 3:Python デプロイメントを作成する
ストリーミングデプロイメント
Realtime Compute for Apache Flink 開発コンソールの左側のナビゲーションウィンドウで、 を選択します。 [デプロイメント] ページの左上隅で、 を選択します。
[Python デプロイメントの作成] ダイアログボックスで、パラメーターを構成します。次の表にパラメーターを示します。

パラメーター
説明
例
[デプロイメントモード]
Python デプロイメントのデプロイに使用するモード。 [ストリームモード] を選択します。
ストリームモード
[デプロイメント名]
Python デプロイメントの名前。
flink-streaming-test-python
[エンジンバージョン]
現在のデプロイメントで使用されるエンジンバージョン。
[推奨] または [安定] ラベルが付いたエンジンバージョンを使用することをお勧めします。 ラベル付きバージョンは、より高い信頼性とパフォーマンスを提供します。 詳細については、「リリースノート」および「エンジンバージョン」をご参照ください。
vvr-8.0.9-flink-1.17
[Python URI]
Python ファイル。 テスト Python ファイル word_count_streaming.py をダウンロードし、[Python URI] フィールドの右側にある
 アイコンをクリックして、テスト Python ファイルを選択してアップロードします。
アイコンをクリックして、テスト Python ファイルを選択してアップロードします。アーティファクト 内の Python ファイルを選択することもできます。
-
[エントリモジュール]
Python プログラムのエントリポイントクラス。
アップロードするファイルが .py ファイルの場合、このパラメーターを構成する必要はありません。
アップロードするファイルが .zip ファイルの場合、このパラメーターを構成する必要があります。 たとえば、[エントリモジュール] パラメーターを word_count に設定できます。
不要
[エントリポイントのメイン引数]
main メソッドで呼び出すパラメーター。
この例では、入力データファイル Shakespeare が格納されているディレクトリを入力します。
--input oss://<関連付けられている OSS バケット名>/artifacts/namespaces/<ワークスペース名>/Shakespeare[アーティファクト] ページに移動し、入力データファイル Shakespeare の名前をクリックして、完全なディレクトリをコピーできます。
[デプロイメントターゲット]
デプロイメントがデプロイされる宛先。 ドロップダウンリストから使用する [キュー] または [セッションクラスター] を選択します。 本番環境ではセッションクラスターを使用しないことをお勧めします。 詳細については、「キューを管理する」および「ステップ 1:セッションクラスターを作成する」をご参照ください。
重要セッションクラスターにデプロイされたデプロイメントのモニタリングメトリックは表示できません。 セッションクラスターは、モニタリングおよびアラート機能と Autopilot 機能をサポートしていません。 セッションクラスターは、開発環境とテスト環境に適しています。 本番環境ではセッションクラスターを使用しないことをお勧めします。 詳細については、「デプロイメントをデバッグする」をご参照ください。
default-queue
その他のデプロイメントパラメーターの詳細については、「デプロイメントを作成する」をご参照ください。
[デプロイ] をクリックします。
バッチデプロイメント
Realtime Compute for Apache Flink 開発コンソールの左側のナビゲーションウィンドウで、 を選択します。 [デプロイメント] ページの左上隅で、[デプロイメントの作成] > [Python デプロイメント] を選択します。
[Python デプロイメントの作成] ダイアログボックスで、パラメーターを構成します。次の表にパラメーターを示します。
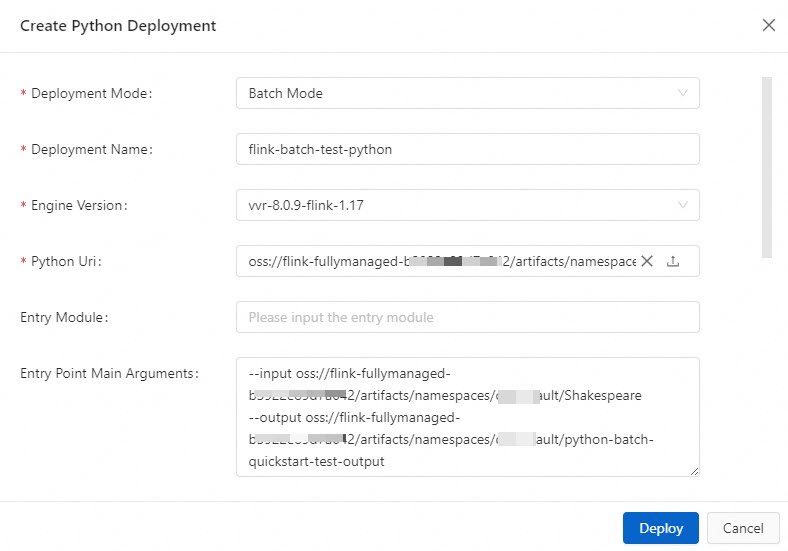
パラメーター
説明
例
[デプロイメントモード]
Python デプロイメントのデプロイに使用するモード。 [バッチモード] を選択します。
バッチモード
[デプロイメント名]
デプロイメントの名前。
flink-batch-test-python
[エンジンバージョン]
現在のデプロイメントで使用されるエンジンバージョン。
[推奨] または [安定] ラベルが付いたエンジンバージョンを使用することをお勧めします。 ラベル付きバージョンは、より高い信頼性とパフォーマンスを提供します。 詳細については、「リリースノート」および「エンジンバージョン」をご参照ください。
vvr-8.0.9-flink-1.17
[Python URI]
Python ファイル。 テスト Python ファイル word_count_batch.py をダウンロードし、[Python URI] フィールドの右側にある
アイコンをクリックして、テスト Python ファイルを選択してアップロードします。-
[エントリモジュール]
Python プログラムのエントリポイントクラス。
アップロードするファイルが .py ファイルの場合、このパラメーターを構成する必要はありません。
アップロードするファイルが .zip ファイルの場合、このパラメーターを構成する必要があります。 たとえば、[エントリモジュール] パラメーターを word_count に設定できます。
不要
[エントリポイントのメイン引数]
main メソッドで呼び出すパラメーター。
この例では、入力データファイル Shakespeare と出力データファイル batch-quickstart-test-output が格納されているディレクトリを入力します。
説明出力データファイルのディレクトリのみを指定する必要があります。 指定したディレクトリにあらかじめ出力データファイルを作成する必要はありません。 出力データファイルの親ディレクトリは、入力データファイルのディレクトリと同じです。
--input oss://<関連付けられた OSS バケットの名前>/artifacts/namespaces/<ワークスペースの名前>/Shakespeare--output oss://<関連付けられた OSS バケットの名前>/artifacts/namespaces/<ワークスペースの名前>/python-batch-quickstart-test-output[成果物] ページに移動し、入力データファイル Shakespeare の名前をクリックして、完全なディレクトリをコピーできます。
[デプロイメント ターゲット]
デプロイメントがデプロイされる宛先です。 ドロップダウンリストから、使用する [キュー] または [セッション クラスター] を選択します。 本番環境ではセッション クラスターを使用しないことをお勧めします。 詳細については、「キューを管理する」および「手順 1:セッション クラスターを作成する」をご参照ください。
重要セッション クラスターにデプロイされたデプロイメントのモニタリング メトリクスは表示できません。 セッション クラスターは、モニタリングおよびアラート機能と、Autopilot 機能をサポートしていません。 セッション クラスターは、開発環境およびテスト環境に適しています。 本番環境ではセッション クラスターを使用しないことをお勧めします。 詳細については、「デプロイメントをデバッグする」をご参照ください。
デフォルトキュー
詳細については、「デプロイメントを作成する」をご参照ください。
[デプロイ] をクリックします。
ステップ 4:デプロイメントを開始し、計算結果を表示する
ストリーミングデプロイメント
Realtime Compute for Apache Flink の開発コンソールの左側のナビゲーションウィンドウで、 を選択します。[デプロイメント] ページで、目的のデプロイメントを見つけ、[開始] 列の [アクション] をクリックします。

[ジョブの開始] パネルで、[初期モード] を選択し、[開始] をクリックします。デプロイメントの開始方法の詳細については、「デプロイメントを開始する」をご参照ください。
[開始] をクリックすると、デプロイメントは [実行中] または [完了] 状態になります。これは、デプロイメントが想定どおりに実行されていることを示します。テスト用の Python ファイルをアップロードしてデプロイメントを作成した場合、デプロイメントは [完了] 状態になります。
デプロイメントが [実行中] 状態になったら、ストリーミングデプロイメントの計算結果を表示します。
重要テスト用の Python ファイルをアップロードしてデプロイメントを作成した場合、ストリーミングデプロイメントが [完了] 状態になると、ストリーミングデプロイメントの計算結果は削除されます。ストリーミングデプロイメントの計算結果は、ストリーミングデプロイメントが [実行中] 状態の場合にのみ表示できます。
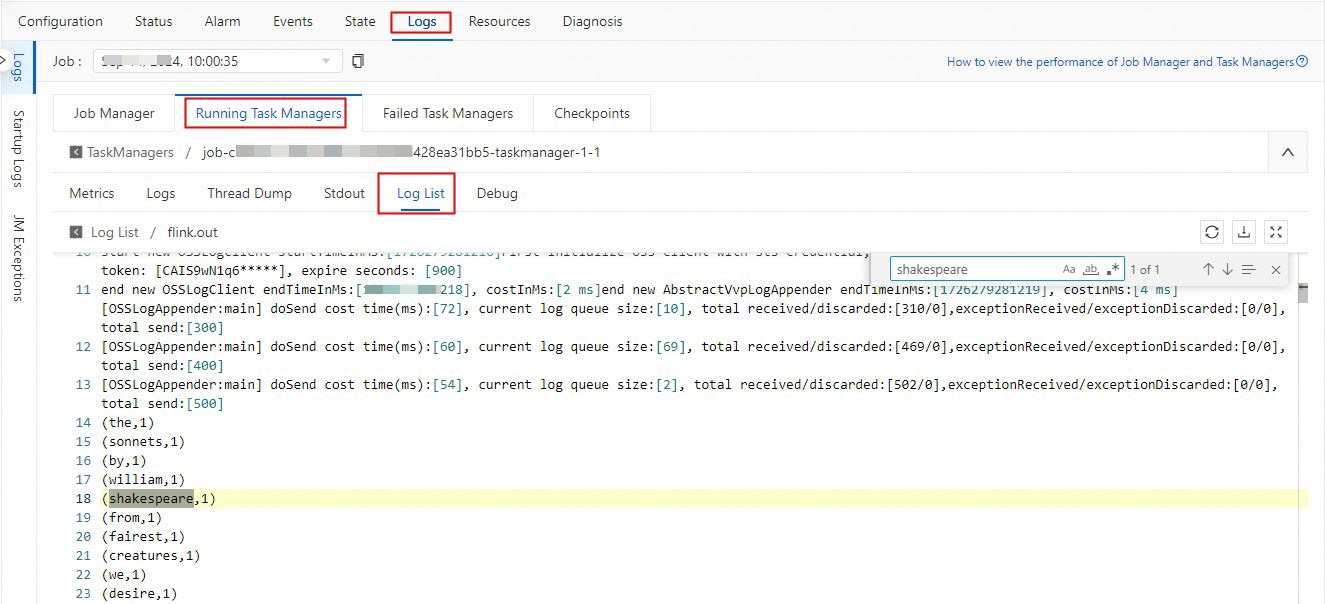
[デプロイメント] ページで、目的のデプロイメントを見つけ、デプロイメントの名前をクリックします。表示されるページで、[ログ] をクリックします。[実行中のタスクマネージャー] タブで、[パス、ID] 列の値をクリックします。表示されるページで、[ログリスト] タブをクリックします。[ログ名] 列で、名前が .out で終わるログファイルを見つけ、ログファイルの名前をクリックします。次に、ログファイルで shakespeare キーワードを検索して、計算結果を表示します。
バッチデプロイメント
Realtime Compute for Apache Flink の開発コンソールの左側のナビゲーションウィンドウで、 を選択します。[デプロイメント] ページで、目的のデプロイメントを見つけ、[アクション] 列の [開始] をクリックします。

[ジョブの開始] パネルで、[開始] をクリックします。デプロイメントの開始方法の詳細については、「デプロイメントを開始する」をご参照ください。
デプロイメントが [完了] 状態になったら、バッチデプロイメントの計算結果を表示します。
OSS コンソール にログインし、oss://<関連付けられた OSS バケット名>/artifacts/namespaces/<ワークスペース名>/batch-quickstart-test-output ディレクトリで計算結果を表示します。デプロイメントの開始日時を名前とするフォルダをクリックし、管理するファイルをクリックします。表示されるパネルで、[ダウンロード] をクリックします。

バッチデプロイメントの計算結果は .ext ファイルです。出力データファイルをダウンロードした後、メモ帳または Microsoft Office Word を使用してファイルを開くことができます。次の図は、計算結果を示しています。

ステップ 5:(オプション)デプロイメントのキャンセル
2 つの状況で、デプロイメントをキャンセルする必要がある場合があります。デプロイメントのドラフト(SQL コード、WITH 句のコネクタオプション、エンジンバージョンなど)を変更した後、更新されたドラフトをデプロイし、実行中のデプロイメントをキャンセルしてから、変更を有効にするためにデプロイメントを再起動する必要があります。デプロイメントが失敗し、状態データを再利用して回復できない場合、または動的に有効にならないパラメーター設定を更新する場合、デプロイメントをキャンセルしてから開始する必要があります。詳細については、「デプロイメントのキャンセル」をご参照ください。
参照資料
デプロイメントを開始する前に、デプロイメントのリソースを構成できます。 また、デプロイメントのドラフトを公開した後に、デプロイメントのリソース構成を変更することもできます。 Realtime Compute for Apache Flink は、基本モード(粗粒度)とエキスパートモード(細粒度)という 2 つのリソース構成モードを提供します。 詳細については、「デプロイメントのリソースを構成する」をご参照ください。
Realtime Compute for Apache Flink デプロイメントのパラメーター構成を動的に更新できます。 これにより、パラメーター構成がより迅速に有効になり、デプロイメントの起動とキャンセルによって発生するサービス中断時間が短縮されます。 詳細については、「動的スケーリングのパラメーター構成を動的に更新する」をご参照ください。
パラメーターを構成して、デプロイメントのログを外部ストレージにエクスポートし、エクスポートするログのレベルを指定できます。 詳細については、「デプロイメントのログをエクスポートするためのパラメーターを構成する」をご参照ください。
Realtime Compute for Apache Flink の SQL デプロイメントを作成する方法の詳細については、「SQL デプロイメントの概要」をご参照ください。
Realtime Compute for Apache Flink と Hologres を使用して、リアルタイム データ ウェアハウスを構築できます。 詳細については、「Realtime Compute for Apache Flink と Hologres を使用してリアルタイム データ ウェアハウスを構築する」をご参照ください。
Realtime Compute for Apache Flink を使用して、OpenLake ベースのストリーミング データ レイクハウスを構築できます。 詳細については、「Realtime Compute for Apache Flink を使用して OpenLake ベースのストリーミング データ レイクハウスを構築する」をご参照ください。