このトピックでは、reindex API を使用して、マルチタイプインデックスからシングタイプインデックスにデータを移行する方法について説明します。マルチタイプインデックスは Alibaba Cloud Elasticsearch V5.X クラスタ上にあります。シングタイプインデックスは Alibaba Cloud Elasticsearch V6.X クラスタ上にあります。
制限
Alibaba Cloud Elasticsearch のネットワークアーキテクチャは、2020 年 10 月に調整されました。新しいネットワークアーキテクチャでは、クラスタ間の reindex 操作が制限されています。操作を実行する前に、PrivateLink サービスを使用して VPC 間の非公開接続を確立する必要があります。次の表に、さまざまなシナリオでのデータ移行ソリューションを示します。
2020 年 10 月より前に作成された Alibaba Cloud Elasticsearch クラスタは、元のネットワークアーキテクチャにデプロイされています。 2020 年 10 月以降に作成された Alibaba Cloud Elasticsearch クラスタは、新しいネットワークアーキテクチャにデプロイされています。
シナリオ | ネットワークアーキテクチャ | ソリューション |
Alibaba Cloud Elasticsearch クラスタ間でデータを移行する | 両方のクラスタが元のネットワークアーキテクチャにデプロイされています。 | reindex API。詳細については、「reindex API を使用して Alibaba Cloud Elasticsearch クラスタ間でデータを移行する」をご参照ください。 |
クラスタの 1 つが元のネットワークアーキテクチャにデプロイされています。 説明 もう 1 つのクラスタは、元のネットワークアーキテクチャまたは新しいネットワークアーキテクチャにデプロイできます。 |
| |
ECS インスタンスで実行されているセルフマネージド Elasticsearch クラスタから Alibaba Cloud Elasticsearch クラスタにデータを移行する | Alibaba Cloud Elasticsearch クラスタは元のネットワークアーキテクチャにデプロイされています。 | reindex API。詳細については、「reindex API を使用して、セルフマネージド Elasticsearch クラスタから Alibaba Cloud Elasticsearch クラスタにデータを移行する」をご参照ください。 |
Alibaba Cloud Elasticsearch クラスタは新しいネットワークアーキテクチャにデプロイされています。 | reindex API。詳細については、「新しいネットワークアーキテクチャにデプロイされたセルフマネージド Elasticsearch クラスタから Alibaba Cloud Elasticsearch クラスタにデータを移行する」をご参照ください。 |
手順
同じ仮想プライベートクラウド (VPC) に Elasticsearch V5.X クラスタ、Elasticsearch V6.X クラスタ、および Logstash クラスタを作成します。
Elasticsearch クラスタは、インデックスデータを格納するために使用されます。
Logstash クラスタは、パイプラインに基づいて処理済みデータを移行するために使用されます。
手順 1: マルチタイプインデックスを 1 つ以上のシングタイプインデックスに変換する
reindex API を使用して、Elasticsearch V5.X クラスタ上のマルチタイプインデックスを 1 つ以上のシングタイプインデックスに変換します。次のいずれかの方法を使用して変換を実装できます。
タイプの結合: 指定されたスクリプト条件で reindex API を呼び出して、インデックスのタイプを結合します。
インデックスの分割: reindex API を呼び出して、インデックスを複数のインデックスに分割します。これらのインデックスにはそれぞれ 1 つのタイプのみが含まれます。
Logstash クラスタを使用して、処理済みインデックスデータを Elasticsearch V6.X クラスタに移行します。
Kibana コンソールで移行されたデータを表示します。
準備を行う
Elasticsearch V5.5.3 クラスタと Elasticsearch V6.7.0 クラスタを作成します。次に、Elasticsearch V5.5.3 クラスタにマルチタイプインデックスを作成し、インデックスにデータを挿入します。
Elasticsearch クラスタの作成方法の詳細については、「Alibaba Cloud Elasticsearch クラスタを作成する」をご参照ください。
Elasticsearch クラスタが存在する VPC に Logstash クラスタを作成します。
詳細については、「手順 1: Logstash クラスタを作成する」をご参照ください。
手順 1: マルチタイプインデックスを 1 つ以上のシングタイプインデックスに変換する
次の手順では、インデックスのタイプを結合して、インデックスを 1 つのシングタイプインデックスに変換します。
Elasticsearch V5.5.3 クラスタの自動インデックス作成機能を有効にします。
Elasticsearch コンソール にログインします。
左側のナビゲーションウィンドウで、[elasticsearch クラスタ] をクリックします。
上部のナビゲーションバーで、リソースグループとリージョンを選択します。
[elasticsearch クラスタ] ページで、Elasticsearch V5.5.3 クラスタを見つけて、その ID をクリックします。
表示されるページの左側のナビゲーションウィンドウで、[クラスタ構成] をクリックします。
[構成の変更][YML ファイル構成] の右側にある をクリックします。
[YML ファイル構成] パネルで、[自動インデックス作成] を [有効] に設定します。
 警告
警告この操作によりクラスタが再起動されます。そのため、[自動インデックス作成] の値を変更する前に、再起動がサービスに影響を与えないことを確認してください。
[この操作によりクラスタが再起動されます。続行しますか?] を選択し、[OK] をクリックします。
Elasticsearch クラスタの Kibana コンソールにログインします。
詳細については、「Kibana コンソールにログインする」をご参照ください。
左側のナビゲーションウィンドウで、[dev Tools] をクリックします。
表示されるページの [コンソール] タブで、次のコマンドを実行してインデックスのタイプを結合します。
POST _reindex { "source": { "index": "twitter" }, "dest": { "index": "new1" }, "script": { "inline": """ ctx._id = ctx._type + "-" + ctx._id; ctx._source.type = ctx._type; ctx._type = "doc"; """, "lang": "painless" } }この例では、new1 インデックスにカスタムタイプフィールドが追加されます。ctx._source.type はカスタム type フィールドを指定し、このフィールドは元の _type パラメータの値に設定されます。さらに、new1 インデックスの _id には _type-_id が含まれています。これにより、異なるタイプのドキュメントが同じ ID を持つことを防ぎます。
GET new1/_mappingコマンドを実行して、結合後のマッピングを表示します。次のコマンドを実行して、タイプが結合された新しいインデックスのデータを表示します。
GET new1/_search { "query":{ "match_all":{ } } }
次の手順では、マルチタイプインデックスが複数のシングタイプインデックスに分割されます。
[コンソール] タブで、次のコマンドを実行して、マルチタイプインデックスを複数のシングタイプインデックスに分割します。
POST _reindex { "source": { "index": "twitter", "type": "tweet", "size": 10000 }, "dest": { "index": "twitter_tweet" } } POST _reindex { "source": { "index": "twitter", "type": "user", "size": 10000 }, "dest": { "index": "twitter_user" } }この例では、twitter インデックスは、タイプに基づいて twitter_tweet インデックスと twitter_user インデックスに分割されます。
次のコマンドを実行して、新しいインデックスのデータを表示します。
GET twitter_tweet/_search { "query":{ "match_all":{ } } }GET twitter_user/_search { "query":{ "match_all":{ } } }
手順 2: Logstash を使用してデータを移行する
目的のクラスタに移動します。
上部のナビゲーションバーで、クラスタが存在するリージョンを選択します。
[logstash クラスタ] ページで、クラスタを見つけて、その ID をクリックします。
表示されるページの左側のナビゲーションウィンドウで、[パイプライン] をクリックします。
パイプラインページで、[パイプラインの作成] をクリックします。
[作成] ウィザードで、パイプライン ID を入力し、パイプラインを構成します。
この例では、パイプラインに次の構成が使用されます。
input { elasticsearch { hosts => ["http://es-cn-0pp1f1y5g000h****.elasticsearch.aliyuncs.com:9200"] user => "elastic" index => "*" password => "your_password" docinfo => true } } filter { } output { elasticsearch { hosts => ["http://es-cn-mp91cbxsm000c****.elasticsearch.aliyuncs.com:9200"] user => "elastic" password => "your_password" index => "test" } }詳細については、「Logstash 構成ファイル」をご参照ください。
[次へ] をクリックして、パイプラインパラメータを構成します。
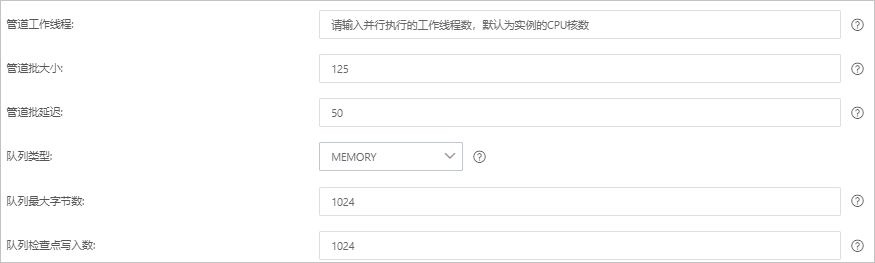
パラメータ
説明
[パイプラインワーカー]
パイプラインのフィルタと出力プラグインを並列で実行するワーカースレッドの数。イベントのバックログが存在する場合、または一部の CPU リソースが使用されていない場合は、スレッド数を増やして CPU 使用率を最大化することをお勧めします。このパラメータのデフォルト値は vCPU の数です。
[パイプラインバッチサイズ]
単一のワーカースレッドがフィルタと出力プラグインの実行を試みる前に、入力プラグインから収集できるイベントの最大数。このパラメータを大きな値に設定すると、単一のワーカースレッドはより多くのイベントを収集できますが、より多くのメモリを消費します。ワーカースレッドがより多くのイベントを収集するのに十分なメモリを確保するには、LS_HEAP_SIZE 変数を指定して Java 仮想マシン (JVM) ヒープサイズを増やします。デフォルト値: 125。
[パイプラインバッチ遅延]
イベントの待機時間。この時間は、小さなバッチをパイプラインワーカースレッドに割り当てる前、およびパイプラインイベントのバッチタスクを作成した後に発生します。デフォルト値: 50。単位: ミリ秒。
[キュータイプ]
イベントをバッファリングするための内部キューモデル。有効な値:
[メモリ]: 従来のメモリベースのキュー。これがデフォルト値です。
[永続化]: ディスクベースの ACKed キュー。これは永続キューです。
[キュー最大バイト数]
値はディスクの合計容量よりも小さくなければなりません。デフォルト値: 1024。単位: MB。
[キューチェックポイント書き込み]
永続キューが有効になっている場合にチェックポイントが適用される前に書き込まれるイベントの最大数。値 0 は制限がないことを示します。デフォルト値: 1024。
警告パラメータを構成した後、設定を保存してパイプラインをデプロイする必要があります。これにより、Logstash クラスタの再起動がトリガーされます。続行する前に、再起動がビジネスに影響を与えないことを確認してください。
[保存] または [保存してデプロイ] をクリックします。
[保存]: このボタンをクリックすると、システムはパイプライン設定を保存し、クラスタの変更をトリガーします。ただし、設定は有効になりません。[保存] をクリックすると、[パイプライン] ページが表示されます。[パイプライン] ページで、作成したパイプラインを見つけて、[アクション] 列の [今すぐデプロイ] をクリックします。次に、システムは Logstash クラスタを再起動して、設定を有効にします。
[保存してデプロイ]: このボタンをクリックすると、システムは Logstash クラスタを再起動して、設定を有効にします。
手順 3: データ移行結果を表示する
Elasticsearch V6.7.0 クラスタの Kibana コンソールにログインします。
詳細については、「Kibana コンソールにログインする」をご参照ください。
左側のナビゲーションウィンドウで、[dev Tools] をクリックします。
表示されるページの [コンソール] タブで、次のコマンドを実行して、移行されたデータが格納されているインデックスを表示します。
GET _cat/indices?v