ES-Hadoop は、オープンソースの Elasticsearch によって開発されたツールです。Elasticsearch を Apache Hadoop に接続し、それらの間のデータ転送を可能にします。ES-Hadoop は、Elasticsearch の高速検索機能と Hadoop のバッチ処理機能を組み合わせて、インタラクティブなデータ処理を実現します。複雑なデータ分析タスクの場合、MapReduce タスクを実行して、Hadoop Distributed File System(HDFS)に格納されている JSON ファイルからデータを読み取り、Elasticsearch クラスタに書き込む必要があります。このトピックでは、ES-Hadoop を使用してこのような MapReduce タスクを実行する方法について説明します。
手順
同じ仮想プライベートクラウド(VPC)に Alibaba Cloud Elasticsearch クラスタと E-MapReduce(EMR)クラスタを作成します。次に、Elasticsearch クラスタの自動インデックス作成機能を有効にし、テストデータと Java 環境を準備します。
手順 1:ES-Hadoop JAR パッケージを HDFS にアップロードする
ES-Hadoop パッケージをダウンロードし、EMR クラスタのマスターノードの HDFS ディレクトリにアップロードします。
Java Maven プロジェクトを作成し、POM 依存関係を設定します。
手順 3:コードをコンパイルし、MapReduce タスクを実行する
Elasticsearch クラスタにデータを書き込むために使用される Java コードをコンパイルします。コードを JAR パッケージに圧縮し、EMR クラスタにアップロードします。次に、MapReduce タスクでコードを実行してデータを書き込みます。
Elasticsearch クラスタの Kibana コンソールにログインします。次に、MapReduce タスクによって書き込まれたデータをクエリします。
準備
Alibaba Cloud Elasticsearch クラスタを作成し、クラスタの自動インデックス作成機能を有効にします。
詳細については、「Alibaba Cloud Elasticsearch クラスタを作成する」および「Elasticsearch クラスタにアクセスして設定する」をご参照ください。このトピックでは、Elasticsearch V6.7.0 クラスタが作成されます。
重要本番環境では、自動インデックス作成機能を無効にすることをお勧めします。事前にインデックスを作成し、インデックスのマッピングを設定する必要があります。このトピックで使用されている Elasticsearch クラスタはテスト用であるため、自動インデックス作成機能が有効になっています。
Elasticsearch クラスタと同じ VPC に存在する EMR クラスタを作成します。
EMR クラスタ構成:
EMR バージョン:EMR-3.29.0 を選択します。
必須サービス:HDFS(2.8.5)は必須サービスの 1 つです。他のサービスについては、デフォルト設定が保持されます。
詳細については、「EMRを使い始める」をご参照ください。
重要デフォルトでは、Elasticsearch クラスタのプライベート IP アドレスホワイトリストに 0.0.0.0/0 が指定されています。クラスタセキュリティ設定ページでホワイトリスト設定を表示できます。デフォルト設定を使用しない場合は、EMR クラスタのプライベート IP アドレスをホワイトリストに追加する必要があります。
EMR クラスタのプライベート IP アドレスを取得する方法の詳細については、「クラスタリストとクラスタの詳細を表示する」をご参照ください。
Elasticsearch クラスタのプライベート IP アドレスホワイトリストを設定する方法の詳細については、「Elasticsearch クラスタのパブリックまたはプライベート IP アドレスホワイトリストを設定する」をご参照ください。ホワイトリストに登録されている IP アドレスを使用して、VPC 経由で Elasticsearch クラスタにアクセスできます。
JSON 形式のテストデータを準備し、map.json ファイルに書き込みます。ファイルを HDFS の /tmp/hadoop-es ディレクトリにアップロードします。
このトピックでは、次のテストデータを使用します:
{"id": 1, "name": "zhangsan", "birth": "1990-01-01", "addr": "No.969, wenyixi Rd, yuhang, hangzhou"} {"id": 2, "name": "lisi", "birth": "1991-01-01", "addr": "No.556, xixi Rd, xihu, hangzhou"} {"id": 3, "name": "wangwu", "birth": "1992-01-01", "addr": "No.699 wangshang Rd, binjiang, hangzhou"}Java 環境を準備します。JDK バージョンは 1.8.0 以降である必要があります。
手順 1:ES-Hadoop JAR パッケージを HDFS にアップロードする
Elasticsearch クラスタのバージョンと互換性のある ES-Hadoop パッケージ をダウンロードします。
この例では、elasticsearch-hadoop-6.7.0.zip パッケージを使用します。
EMR コンソール にログインし、EMR クラスタのマスターノードの IP アドレスを取得します。次に、SSH を使用して、IP アドレスで示される Elastic Compute Service(ECS)インスタンスにログインします。
詳細については、「クラスターにログオンする」をご参照ください。
elasticsearch-hadoop-6.7.0.zip パッケージを EMR クラスタのマスターノードにアップロードします。パッケージを解凍して、elasticsearch-hadoop-6.7.0.jar ファイルを取得します。
HDFS ディレクトリを作成し、elasticsearch-hadoop-6.7.0.jar ファイルをディレクトリにアップロードします。
hadoop fs -mkdir /tmp/hadoop-es hadoop fs -put elasticsearch-hadoop-6.7.0/dist/elasticsearch-hadoop-6.7.0.jar /tmp/hadoop-es
手順 2:POM 依存関係を設定する
Java Maven プロジェクトを作成し、プロジェクトの pom.xml ファイルに次の POM 依存関係を追加します。
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-shade-plugin</artifactId>
<version>2.4.1</version>
<executions>
<execution>
<phase>package</phase>
<goals>
<goal>shade</goal>
</goals>
<configuration>
<transformers>
<transformer
implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer">
<mainClass>WriteToEsWithMR</mainClass> // メインクラスを指定
</transformer>
</transformers>
</configuration>
</execution>
</executions>
</plugin>
</plugins>
</build>
<dependencies>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-jobclient</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-auth</artifactId>
<version>2.8.5</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch-hadoop-mr</artifactId>
<version>6.7.0</version>
</dependency>
<dependency>
<groupId>commons-httpclient</groupId>
<artifactId>commons-httpclient</artifactId>
<version>3.1</version>
</dependency>
</dependencies>POM 依存関係のバージョンが、関連する Alibaba Cloud サービスのバージョンと一致していることを確認してください。たとえば、elasticsearch-hadoop-mr のバージョンは Alibaba Cloud Elasticsearch のバージョンと一致し、hadoop-hdfs のバージョンは HDFS のバージョンと一致しています。
手順 3:コードをコンパイルし、MapReduce タスクを実行する
コードをコンパイルします。
次のコードは、HDFS の /tmp/hadoop-es ディレクトリにある JSON ファイルからデータを読み取ります。また、これらの JSON ファイルの各行のデータをドキュメントとして Elasticsearch クラスタに書き込みます。データの書き込みは、マップステージの EsOutputFormat によって完了します。
import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.conf.Configured; import org.apache.hadoop.fs.Path; import org.apache.hadoop.io.NullWritable; import org.apache.hadoop.io.Text; import org.apache.hadoop.mapreduce.Job; import org.apache.hadoop.mapreduce.Mapper; import org.apache.hadoop.mapreduce.lib.input.FileInputFormat; import org.apache.hadoop.mapreduce.lib.input.TextInputFormat; import org.apache.hadoop.util.GenericOptionsParser; import org.elasticsearch.hadoop.mr.EsOutputFormat; import org.apache.hadoop.util.Tool; import org.apache.hadoop.util.ToolRunner; public class WriteToEsWithMR extends Configured implements Tool { public static class EsMapper extends Mapper<Object, Text, NullWritable, Text> { private Text doc = new Text(); @Override protected void map(Object key, Text value, Context context) throws IOException, InterruptedException { // value が空でない場合にのみ処理を実行 if (value.getLength() > 0) { doc.set(value); System.out.println(value); // 値を出力 context.write(NullWritable.get(), doc); // Elasticsearch に書き込むデータ } } } public int run(String[] args) throws Exception { Configuration conf = new Configuration(); String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs(); conf.setBoolean("mapreduce.map.speculative", false); conf.setBoolean("mapreduce.reduce.speculative", false); conf.set("es.nodes", "es-cn-4591jumei000u****.elasticsearch.aliyuncs.com"); // Elasticsearch クラスタのエンドポイント conf.set("es.port","9200"); // Elasticsearch クラスタのポート番号 conf.set("es.net.http.auth.user", "elastic"); // Elasticsearch クラスタにアクセスするためのユーザー名 conf.set("es.net.http.auth.pass", "xxxxxx"); // Elasticsearch クラスタにアクセスするためのパスワード conf.set("es.nodes.wan.only", "true"); // WAN 経由でのみノードに接続 conf.set("es.nodes.discovery","false"); // ノード検出を無効化 conf.set("es.input.use.sliced.partitions","false"); // スライスパーティションを使用しない conf.set("es.resource", "maptest/_doc"); // インデックス名とタイプ conf.set("es.input.json", "true"); // 入力データが JSON 形式であることを指定 Job job = Job.getInstance(conf); job.setInputFormatClass(TextInputFormat.class); job.setOutputFormatClass(EsOutputFormat.class); job.setMapOutputKeyClass(NullWritable.class); job.setMapOutputValueClass(Text.class); job.setJarByClass(WriteToEsWithMR.class); job.setMapperClass(EsMapper.class); FileInputFormat.setInputPaths(job, new Path(otherArgs[0])); // 入力パス return job.waitForCompletion(true) ? 0 : 1; } public static void main(String[] args) throws Exception { int ret = ToolRunner.run(new WriteToEsWithMR(), args); System.exit(ret); } }表 1. ES-Hadoop パラメータ
パラメーター
デフォルト値
説明
es.nodes
localhost
Elasticsearch クラスタにアクセスするために使用されるエンドポイント。内部エンドポイントを使用することをお勧めします。内部エンドポイントは、Elasticsearch クラスタの [基本情報] ページで取得できます。詳細については、「クラスタの基本情報を表示する」をご参照ください。
es.port
9200
Elasticsearch クラスタにアクセスするために使用されるポート番号。
es.net.http.auth.user
elastic
Elasticsearch クラスタにアクセスするために使用されるユーザー名。
説明elastic アカウントを使用して Elasticsearch クラスタにアクセスし、アカウントのパスワードをリセットする場合、新しいパスワードが有効になるまでに時間がかかる場合があります。この期間中は、elastic アカウントを使用してクラスタにアクセスできません。そのため、Elasticsearch クラスタへのアクセスに elastic アカウントを使用しないことをお勧めします。Kibana コンソールにログインし、必要なロールを持つユーザーを作成して、Elasticsearch クラスタにアクセスできます。詳細については、「Elasticsearch X-Pack が提供する RBAC メカニズムを使用してアクセス制御を実装する」をご参照ください。
es.net.http.auth.pass
/
Elasticsearch クラスタにアクセスするために使用されるパスワード。
es.nodes.wan.only
false
Elasticsearch クラスタが接続に仮想 IP アドレスを使用する場合に、ノードスニッフィングを有効にするかどうかを指定します。有効な値:
true:ノードスニッフィングが有効になっていることを示します。
false:ノードスニッフィングが無効になっていることを示します。
es.nodes.discovery
true
ノード検出メカニズムを禁止するかどうかを指定します。有効な値:
true:ノード検出メカニズムが禁止されていることを示します。
false:ノード検出メカニズムが禁止されていないことを示します。
重要Alibaba Cloud Elasticsearch を使用する場合は、このパラメータを false に設定する必要があります。
es.input.use.sliced.partitions
true
パーティションを使用するかどうかを指定します。有効な値:
true:パーティションを使用します。この場合、インデックスの先読みフェーズにより多くの時間がかかる場合があります。このフェーズに必要な時間は、データクエリに必要な時間よりも長くなる場合があります。クエリ効率を向上させるには、このパラメータを false に設定することをお勧めします。
false:パーティションを使用しません。
es.index.auto.create
true
ES-Hadoop を使用してクラスタにデータを書き込むときに、システムが Elasticsearch クラスタにインデックスを作成するかどうかを指定します。有効な値:
true:システムが Elasticsearch クラスタにインデックスを作成することを示します。
false:システムが Elasticsearch クラスタにインデックスを作成しないことを示します。
es.resource
/
データの読み取りまたは書き込み操作が実行されるインデックスの名前とタイプ。
es.input.json
false
入力データが JSON 形式であるかどうかを指定します。
es.mapping.names
/
テーブルのフィールド名と Elasticsearch クラスタのインデックスのフィールド名の間のマッピング。
es.read.metadata
false
_id などのドキュメントメタデータを結果に含めるかどうかを指定します。ドキュメントメタデータを含めるには、値を true に設定します。
ES-Hadoop の設定項目の詳細については、オープンソースの ES-Hadoop 設定 をご参照ください。
コードを JAR パッケージに圧縮し、EMR クラスタのマスターノード、またはこの EMR クラスタに関連付けられているゲートウェイクラスタなど、EMR クライアントにアップロードします。
EMR クライアントで、次のコマンドを実行して MapReduce タスクを実行します。
hadoop jar es-mapreduce-1.0-SNAPSHOT.jar /tmp/hadoop-es/map.json説明es-mapreduce-1.0-SNAPSHOT.jar を、アップロードした JAR ファイルの名前に置き換えます。
手順 4:結果を確認する
Elasticsearch クラスタの Kibana コンソールにログインします。
詳細については、「Kibana コンソールにログインする」をご参照ください。
左側のナビゲーションペインで、[dev Tools] をクリックします。
表示されるページの [console] タブで、次のコマンドを実行して、MapReduce タスクによって書き込まれたデータをクエリします。
GET maptest/_search { "query": { "match_all": {} // 全てのドキュメントにマッチするクエリ } }コマンドが正常に実行されると、次の図に示す結果が返されます。
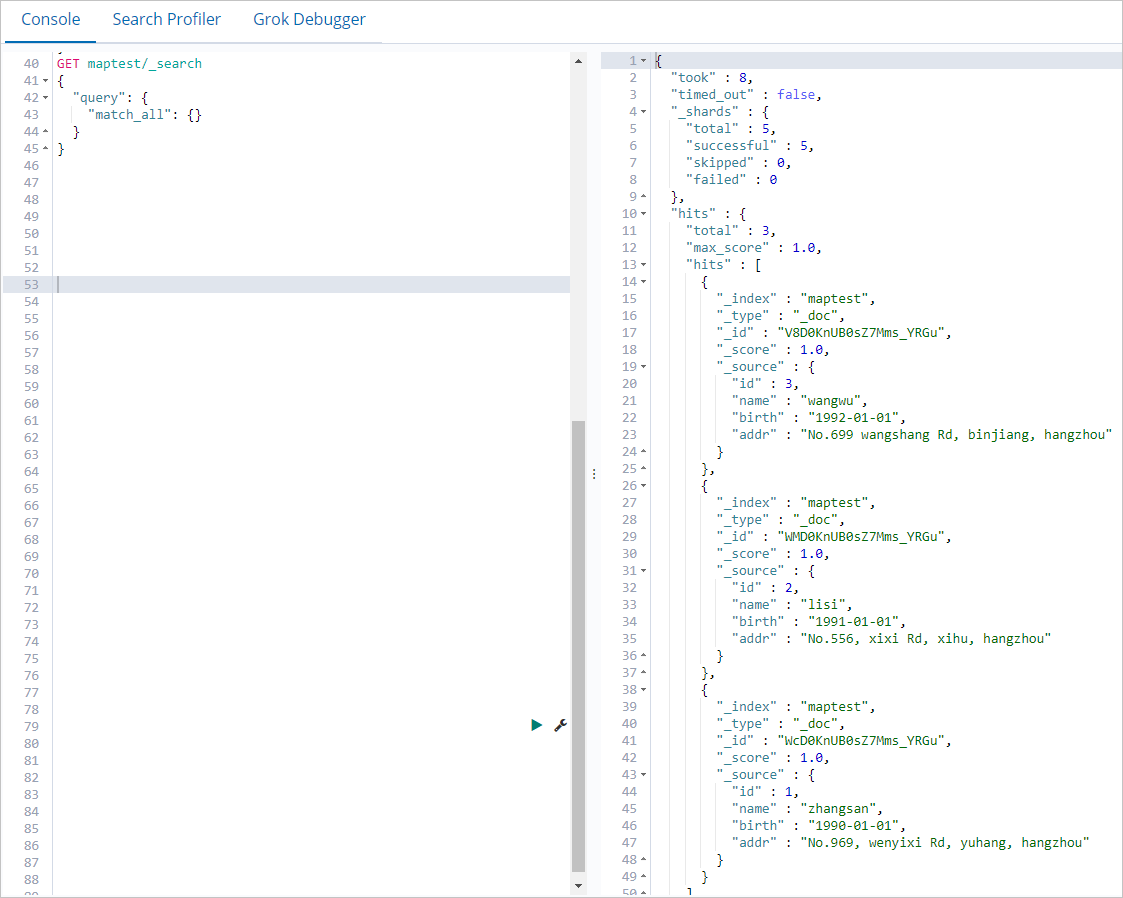
まとめ
このトピックでは、EMR クラスタで MapReduce タスクを実行することにより、ES-Hadoop を使用して Elasticsearch にデータを書き込む方法について説明しました。MapReduce タスクを実行して、Elasticsearch からデータを読み取ることもできます。データ読み取り操作の設定は、データ書き込み操作の設定と似ています。詳細については、オープンソースの Elasticsearch ドキュメントの「Elasticsearch からデータを読み取る」をご参照ください。