Data Transmission Service (DTS) を使用して、ApsaraDB RDS for MySQL データベースのデータを Alibaba Cloud Elasticsearch クラスターにリアルタイムで同期します。DTS の詳細については、「DTS」をご参照ください。DTS は、INSERT、DELETE、UPDATE 操作によって生成されるデータ変更の同期をサポートしており、本番環境の MySQL データに対して低遅延の検索または分析を必要とするユースケースに適しています。
本チュートリアルでは、ソースデータベースおよび送信先クラスターの準備、同期タスクの作成、完全同期および増分同期の結果検証までの一連の手順を説明します。
仕組み
DTS は以下の 2 つのフェーズで実行されます:
-
完全データ同期 — DTS はソースの MySQL テーブルに既存する行を読み取り、Elasticsearch 上のドキュメントとして書き込みます。
-
増分同期 — 完全同期が完了すると、DTS は変更データキャプチャ(CDC)モードに切り替わり、INSERT、UPDATE、DELETE 操作を継続的に Elasticsearch に適用します。
初期の完全同期中は、DTS がソースおよび送信先の両方でリソースを読み取り・書き込みを行うため、負荷が増加する可能性があります。CPU 利用率が両端とも 30 % 未満となるオフピーク時間帯に同期を実行してください。ピーク時間帯に開始した場合、完全同期が失敗する可能性があります。その場合はタスクを再起動してください。また、ピーク時間帯における増分同期は、遅延を引き起こす可能性があります。
DTS は DDL 操作を同期しません。同期中にテーブルスキーマを変更した場合は、「制限事項」に記載されている回復手順に従ってください。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
-
ApsaraDB RDS for MySQL インスタンス(本チュートリアルでは MySQL 8.0 を使用)
-
Alibaba Cloud Elasticsearch クラスター(本チュートリアルでは V7.10 を使用)、および 自動インデックス作成 機能が有効化されていること
-
DTS コンソールへのアクセス権限
制限事項
| 制限事項 | 詳細 |
|---|---|
| DDL 操作は同期されない | 同期中にソーステーブルに対して DDL 操作を実行した場合、以下の手順を実行する必要があります:同期タスクから該当テーブルを削除し、Elasticsearch クラスターから対応するインデックスを削除した後、再度タスクにテーブルを追加します。詳細については、「データ同期タスクからオブジェクトを削除する」および「データ同期タスクにオブジェクトを追加する」をご参照ください。 |
| 列の追加には手動操作が必要 | 列を追加するには、まず Elasticsearch のインデックスマッピングを更新して新しいフィールドを含める必要があります。その後、ソース側で ALTER TABLE を実行し、同期タスクを一時停止してから再開します。 |
| データ型の違い | ApsaraDB RDS for MySQL と Elasticsearch では異なる型システムが採用されています。初期のスキーマ同期時に、DTS はサポートされている Elasticsearch タイプに基づいて、ソースフィールドを送信先フィールドにマッピングします。完全なマッピングテーブルについては、「スキーマ同期におけるデータ型のマッピング」をご参照ください。 |
| プライマリキーのないテーブル | プライマリキーのないテーブルを使用すると、DTS がより多くの読み取り/書き込みリソースを消費する可能性があります。これにより、ソースおよび送信先の負荷が増大し、いずれかのエンドポイントが利用不可になるおそれがあります。 |
ステップ 1:ソースデータベースおよび送信先クラスターの準備
ソースデータベースのセットアップ
-
アカウントとデータベースの作成 という名前の
test_mysql。 -
test_mysqlデータベースで、テーブルを作成してサンプルデータを挿入します。-- テーブルの作成 CREATE TABLE `es_test` ( `id` bigint(32) NOT NULL, `name` varchar(32) NULL, `age` bigint(32) NULL, `hobby` varchar(32) NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARACTER SET=utf8; -- サンプル行の挿入 INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (1,'user1',22,'music'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (2,'user2',23,'sport'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (3,'user3',43,'game'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (4,'user4',24,'run'); INSERT INTO `es_test` (`id`,`name`,`age`,`hobby`) VALUES (5,'user5',42,'basketball');
送信先 Elasticsearch クラスターのセットアップ
-
自動インデックス作成 機能を有効化します。クラスターのYML ファイル構成を開き、自動インデックス作成をオンにします。
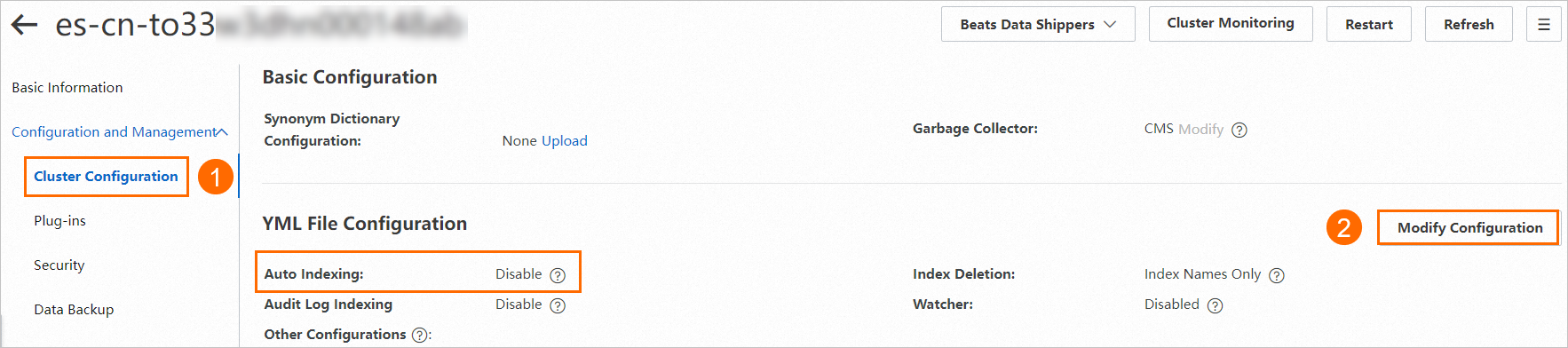
ステップ 2:同期タスクの作成
-
DTS コンソールのデータ同期ページに移動します。
-
タスクの作成 をクリックします。
-
画面の指示に従ってタスクを構成します。
各パラメーターの詳細については、「ApsaraDB RDS for MySQL インスタンスから Elasticsearch クラスターへのデータ同期」をご参照ください。
-
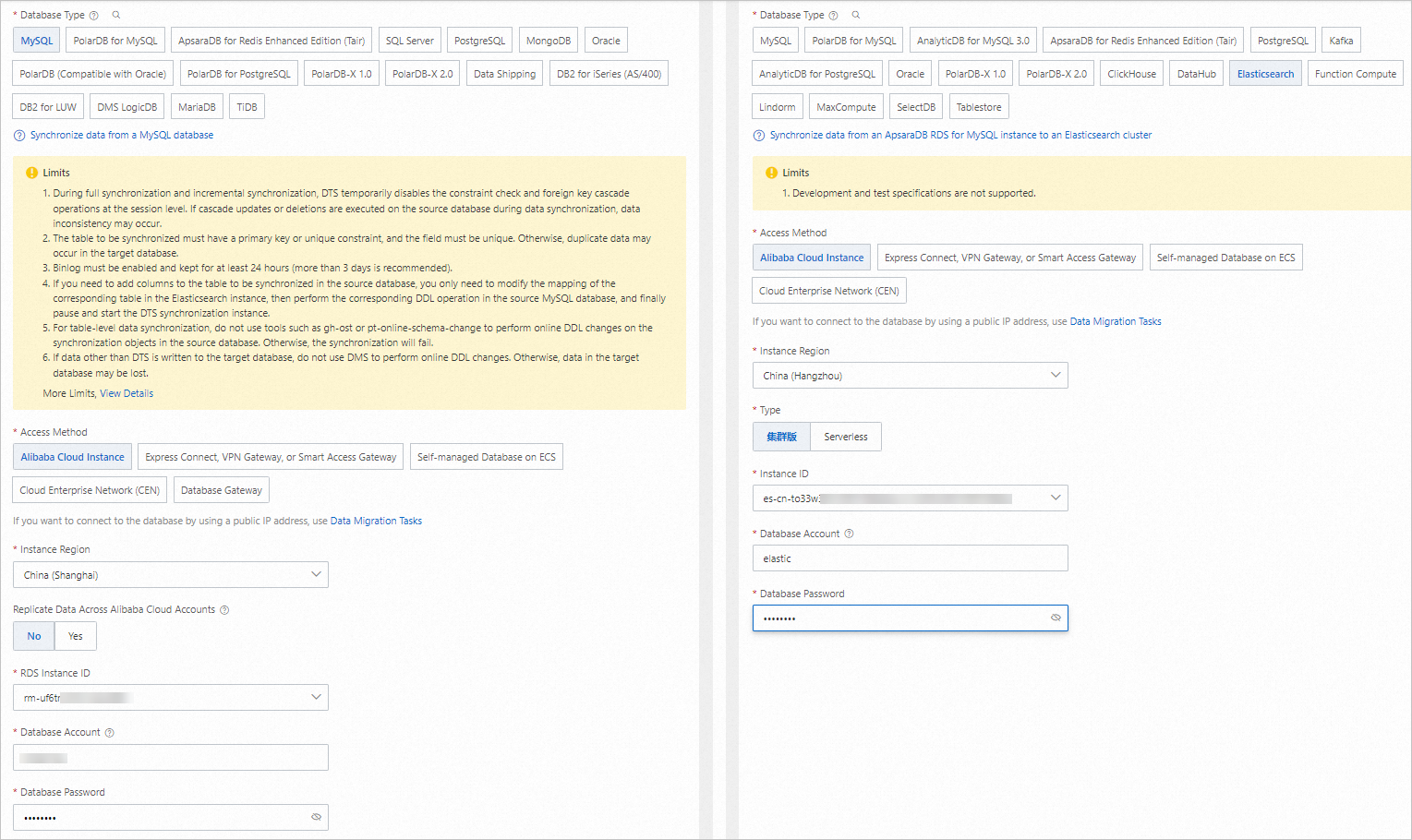
ソース(ApsaraDB RDS for MySQL)および送信先(Elasticsearch クラスター)を構成します。接続性のテストと続行 をクリックします。
-
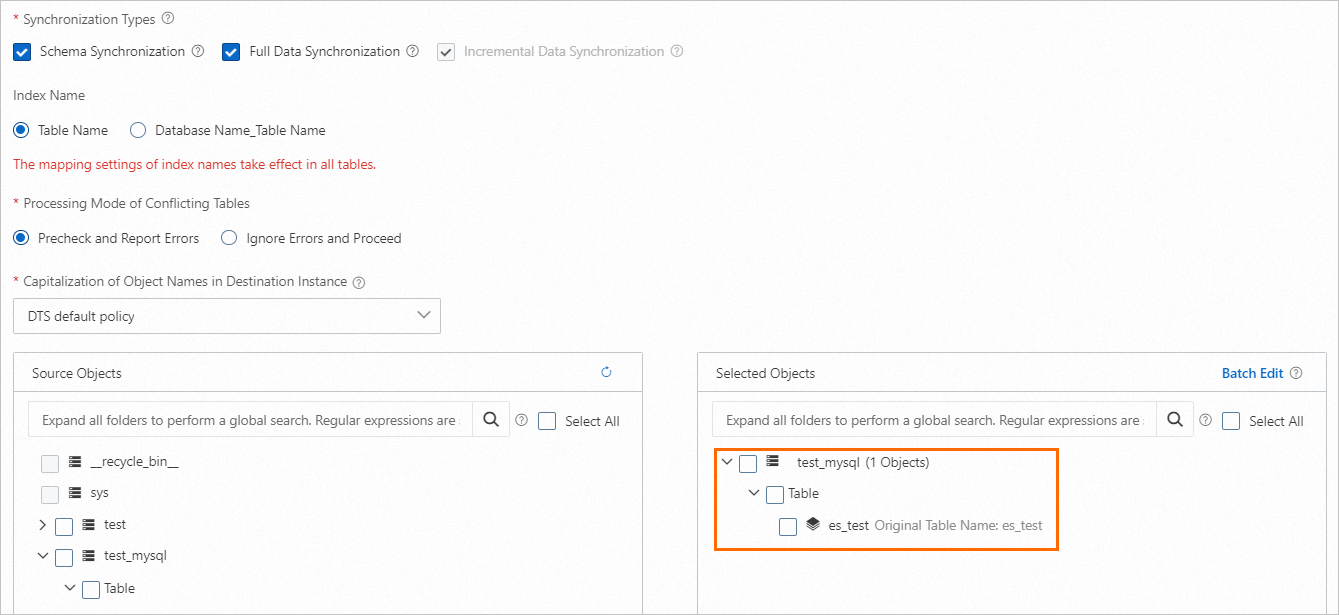
同期対象のオブジェクトを選択します。
-
高度な設定を構成します。本チュートリアルではデフォルト設定を使用します。
-
データ検証 のサブステップで、すべてのテーブルに _routing ポリシーを適用しない を選択します。
この設定は、送信先クラスターが Elasticsearch V7.X を実行している場合に必須です。
-
-
タスクを保存し、事前チェックを実行した後、DTS インスタンスを購入して同期を開始します。DTS インスタンスの購入が完了すると、タスクは自動的に開始されます。データ同期ページで進行状況を監視できます。完全同期が完了すると、Elasticsearch 上で初期の 5 行のデータが利用可能になります。

ステップ 3:(任意)同期結果の検証
Alibaba Cloud Elasticsearch クラスターのKibana コンソールにログインする。左上隅の  > 管理 > Dev Tools を選択し、コンソール タブをクリックします。
> 管理 > Dev Tools を選択し、コンソール タブをクリックします。
完全データ同期の検証
以下のクエリを実行します:
GET /es_test/_search応答により、5 行すべてが同期されたことが確認できます:
{
"took" : 10,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "es_test",
"_type" : "es_test",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"id" : 3,
"name" : "user3",
"age" : 43,
"hobby" : "game"
}
},
{
"_index" : "es_test",
"_type" : "es_test",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"id" : 5,
"name" : "user5",
"age" : 42,
"hobby" : "basketball"
}
},
{
"_index" : "es_test",
"_type" : "es_test",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"id" : 4,
"name" : "user4",
"age" : 24,
"hobby" : "run"
}
},
{
"_index" : "es_test",
"_type" : "es_test",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"id" : 2,
"name" : "user2",
"age" : 23,
"hobby" : "sport"
}
},
{
"_index" : "es_test",
"_type" : "es_test",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"id" : 1,
"name" : "user1",
"age" : 22,
"hobby" : "music"
}
}
]
}
}増分データ同期の検証
-
ソーステーブルに新しい行を挿入します:
INSERT INTO `test_mysql`.`es_test` (`id`,`name`,`age`,`hobby`) VALUES (6,'user6',30,'dance'); -
行がレプリケートされた後、再度
GET /es_test/_searchを実行します。応答には、新規レコードを含む合計 6 件のヒットが表示されます:{ "took" : 541, "timed_out" : false, "_shards" : { "total" : 5, "successful" : 5, "skipped" : 0, "failed" : 0 }, "hits" : { "total" : { "value" : 6, "relation" : "eq" }, "max_score" : 1.0, "hits" : [ { "_index" : "es_test", "_type" : "es_test", "_id" : "3", "_score" : 1.0, "_source" : { "id" : 3, "name" : "user3", "age" : 43, "hobby" : "game" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "5", "_score" : 1.0, "_source" : { "id" : 5, "name" : "user5", "age" : 42, "hobby" : "basketball" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "4", "_score" : 1.0, "_source" : { "id" : 4, "name" : "user4", "age" : 24, "hobby" : "run" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "2", "_score" : 1.0, "_source" : { "id" : 2, "name" : "user2", "age" : 23, "hobby" : "sport" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "6", "_score" : 1.0, "_source" : { "name" : "user6", "id" : 6, "age" : 30, "hobby" : "dance" } }, { "_index" : "es_test", "_type" : "es_test", "_id" : "1", "_score" : 1.0, "_source" : { "id" : 1, "name" : "user1", "age" : 22, "hobby" : "music" } } ] } }
次のステップ
-
データ同期シナリオの概要 — サポートされるソースおよび送信先の組み合わせ