ビッグデータの時代において、ストリーム処理はリアルタイムデータ分析に不可欠です。EMR Serverless Spark は、サーバーの管理を不要にすることでリアルタイムのデータ処理を簡素化し、効率を向上させる、強力でスケーラブルなプラットフォームです。このトピックでは、EMR Serverless Spark を使用して PySpark ストリーミングジョブを送信する方法を説明し、ストリーム処理におけるプラットフォームの使いやすさとメンテナンス性を示します。
前提条件
ワークスペースが作成されていること。詳細については、「ワークスペースの作成」をご参照ください。
手順
ステップ 1: リアルタイム Dataflow クラスターを作成し、メッセージを生成する
EMR on ECS ページで、Kafka サービスを含む Dataflow クラスターを作成します。詳細については、「クラスターの作成」をご参照ください。
EMR クラスターのマスターノードにログインします。詳細については、「クラスターへのログイン」をご参照ください。
次のコマンドを実行してディレクトリを切り替えます。
cd /var/log/emr/taihao_exporter次のコマンドを実行して Topic を作成します。
# taihaometrics という名前の Topic を 10 個のパーティションと 2 のレプリケーション係数で作成します。 kafka-topics.sh --partitions 10 --replication-factor 2 --bootstrap-server core-1-1:9092 --topic taihaometrics --create次のコマンドを実行してメッセージを送信します。
# kafka-console-producer を使用して taihaometrics Topic にメッセージを送信します。 tail -f metrics.log | kafka-console-producer.sh --broker-list core-1-1:9092 --topic taihaometrics
ステップ 2: ネットワーク接続を作成する
[ネットワーク接続] ページに移動します。
EMR コンソールの左側のナビゲーションウィンドウで、 を選択します。
[Spark] ページで、ターゲットワークスペースの名前をクリックします。
[EMR Serverless Spark] ページで、左側のナビゲーションウィンドウにある [ネットワーク接続] をクリックします。
[ネットワーク接続] ページで、[ネットワーク接続の作成] をクリックします。
[ネットワーク接続の作成] ダイアログボックスで、次のパラメーターを設定し、[OK] をクリックします。
パラメーター
説明
[名前]
新しい接続の名前を入力します。例: connection_to_emr_kafka。
[Virtual Private Cloud (VPC)]
EMR クラスターと同じ VPC を選択します。
利用可能な VPC がない場合は、[VPC の作成] をクリックして VPC コンソールに移動し、VPC を作成します。詳細については、「VPC の作成と管理」をご参照ください。
[VSwitch]
EMR クラスターと同じ VPC にある vSwitch を選択します。
現在のゾーンで利用可能な vSwitch がない場合は、[VSwitch] をクリックして VPC コンソールに移動し、vSwitch を作成します。詳細については、「vSwitch の作成と管理」をご参照ください。
[ステータス] が [成功] に変わると、ネットワーク接続が作成されます。
ステップ 3: EMR クラスターにセキュリティグループルールを追加する
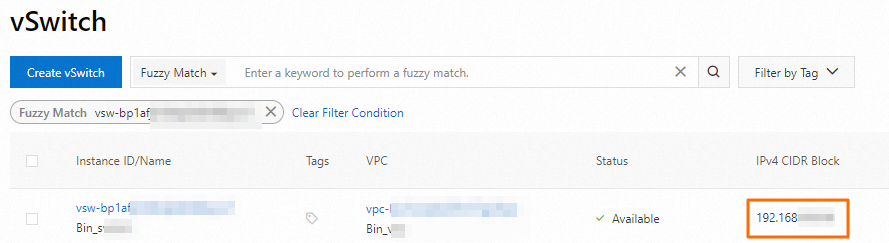
クラスターノードの vSwitch の CIDR ブロックを取得します。
[ノード管理] ページで、ノードグループ名をクリックして、関連付けられている vSwitch 情報を表示します。次に、VPC コンソールにログインし、[VSwitch] ページで vSwitch の CIDR ブロックを取得します。
セキュリティグループルールを追加します。
[クラスター管理] ページで、ターゲットクラスターの ID をクリックします。
[基本情報] ページで、[クラスターセキュリティグループ] の横にあるリンクをクリックします。
[セキュリティグループの詳細] ページの [アクセスルール] セクションで、[ルールの追加] をクリックします。次のパラメーターを設定し、[OK] をクリックします。
パラメーター
説明
[ソース]
前のステップで取得した vSwitch の CIDR ブロックを入力します。
重要外部からの攻撃によるセキュリティリスクを防ぐため、権限付与オブジェクトを 0.0.0.0/0 に設定しないでください。
[宛先 (このインスタンス)]
ポート 9092 を入力します。
ステップ 4: JAR パッケージを OSS にアップロードする
kafka.zip ファイルを解凍し、すべての JAR パッケージを Object Storage Service (OSS) にアップロードします。詳細については、「簡易アップロード」をご参照ください。
ステップ 5: リソースファイルをアップロードする
EMR Serverless Spark ページで、左側のナビゲーションウィンドウにある [ファイル管理] をクリックします。
[ファイル管理] ページで、[ファイルのアップロード] をクリックします。
[ファイルのアップロード] ダイアログボックスで、アップロードエリアをクリックし、pyspark_ss_demo.py ファイルを選択します。
ステップ 6: ストリーミングジョブを作成して開始する
EMR Serverless Spark ページで、左側のナビゲーションウィンドウにある [データ開発] をクリックします。
[開発] タブで、
 アイコンをクリックします。
アイコンをクリックします。名前を入力し、ジョブタイプとして を選択し、[OK] をクリックします。
新しい開発タブで、次のパラメーターを設定し、他のパラメーターはデフォルト値のままにして、[保存] をクリックします。
パラメーター
説明
[メイン Python リソース]
前のステップで [リソースアップロード] ページにアップロードした pyspark_ss_demo.py ファイルを選択します。
[エンジンバージョン]
Spark のバージョンです。詳細については、「エンジンバージョン」をご参照ください。
[ランタイムパラメーター]
EMR クラスターの core-1-1 ノードの内部 IP アドレスです。アドレスは、EMR クラスターの [ノード管理] ページの Core ノードグループで確認できます。
[Spark 構成]
Spark の構成情報です。次のコードに例を示します。
spark.jars oss://path/to/commons-pool2-2.11.1.jar,oss://path/to/kafka-clients-2.8.1.jar,oss://path/to/spark-sql-kafka-0-10_2.12-3.3.1.jar,oss://path/to/spark-token-provider-kafka-0-10_2.12-3.3.1.jar spark.emr.serverless.network.service.name connection_to_emr_kafka説明spark.jars: ランタイムにロードする外部 JAR パッケージのパスを指定します。パスをステップ 4 でアップロードしたすべての JAR パッケージの実際のパスに置き換えます。spark.emr.serverless.network.service.name: ネットワーク接続の名前を指定します。名前をステップ 2 で作成したネットワーク接続の名前に置き換えます。
[公開] をクリックします。
[ジョブの公開] ダイアログボックスで、[OK] をクリックします。
ストリーミングジョブを開始します。
[O&M に移動] をクリックします。
[開始] をクリックします。
ステップ 7: ログを表示する
[ログ探索] タブをクリックします。
[ログ探索] タブでは、アプリケーションの実行に関する情報と返された結果を表示できます。

参考資料
PySpark 開発プロセスの詳細については、「PySpark 開発クイックスタート」をご参照ください。