JindoFS は、Object Storage Service (OSS) とローカルストレージを組み合わせたクラウドネイティブなファイルシステムであり、E-MapReduce (EMR) の次世代ストレージシステムとして機能します。OSS を耐久性のあるストレージバックエンドとして使用し、ローカルに冗長コピーを保持することで読み取りを高速化します。メタデータはローカルの Namespace Service によって管理され、そのパフォーマンスは Hadoop 分散ファイルシステム (HDFS) に匹敵します。このトピックでは、EMR 3.22.0 以降で JindoFS をセットアップ、設定、使用する方法について説明します。
EMR 3.20.0 以降は JindoFS をサポートしています。JindoFS を使用するには、クラスター作成時に JindoFS サービスを選択する必要があります。EMR 3.20.0 から 3.22.0 (3.22.0 を除く) については、「EMR 3.20.0 から 3.22.0 での SmartData の使用」をご参照ください。
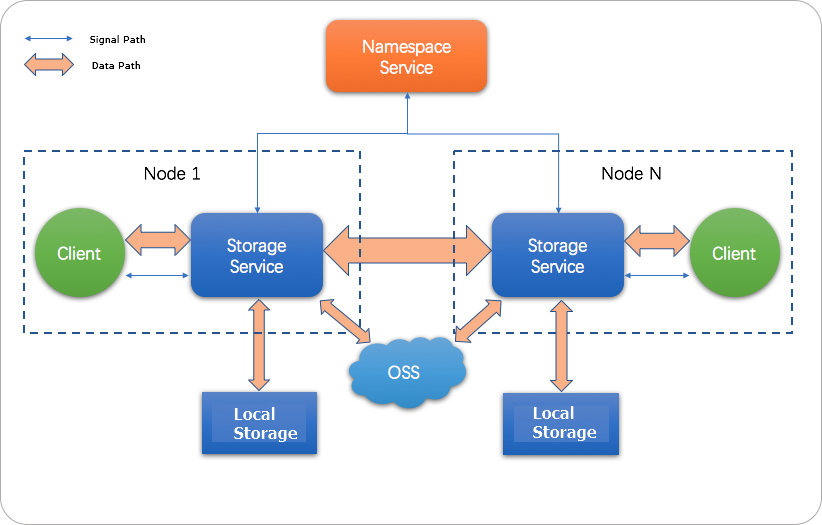
JindoFS の仕組み
JindoFS は、異種混合のマルチバックアップメカニズムを使用します。OSS は耐久性のあるストレージを提供し、ローカルディスクは読み取り高速化のために冗長コピーを保持します。ローカルの Namespace Service がメタデータを管理します。
JindoFS は 2 つのストレージモードをサポートしています:
| モード | 仕組み | 最適な用途 |
|---|---|---|
| ブロック | データはブロックに分割され、OSS に保存され、ローカルにキャッシュされます。 | ほとんどのビッグデータワークロード |
| キャッシュ | OSS がプライマリストアであり、ローカルディスクは透過的なキャッシュレイヤーとして機能します。 | OSS が信頼できる唯一の情報源であるワークロード |
すべての JindoFS パスは jfs:// プレフィックスを使用します。JindoFS を使用するには、コマンドとジョブ設定で hdfs:// プレフィックスを jfs:// に置き換えます。
すべてのパラメーター名は jfs.namespaces.<name>.<param> のパターンに従います。ここで、<name> はご利用の名前空間名です。複数の名前空間を定義し、それぞれを個別に設定できます。
前提条件
開始する前に、以下を確認してください:
バージョン 3.22.0 以降を実行している EMR クラスター。作成時に SmartData サービスが選択されていること
ご利用の EMR クラスターと同じリージョンにある OSS バケット (パスワードレスアクセスを推奨)
JindoFS のセットアップ
ステップ 1:SmartData を使用した EMR クラスターの作成
クラスターを作成する際、EMR バージョン 3.22.0 以降を選択し、[オプションサービス] で SmartData を有効にします。
クラスターの作成手順については、「クラスターの作成」をご参照ください。
ステップ 2:JindoFS の設定
すべての JindoFS 設定は Bigboot コンポーネントに保存されます。2 つのメソッドが利用可能です:
クラスター作成後 (既存のクラスターに推奨):EMR コンソールで Bigboot パラメーターを変更し、SmartData を再起動します。
クラスター作成時:カスタムソフトウェア設定で設定を JSON 配列として渡します。
以下の例では、test という名前の名前空間を設定します。
クラスター作成後の設定
EMR コンソールで、[サービス設定] に移動し、[bigboot] タブをクリックします。
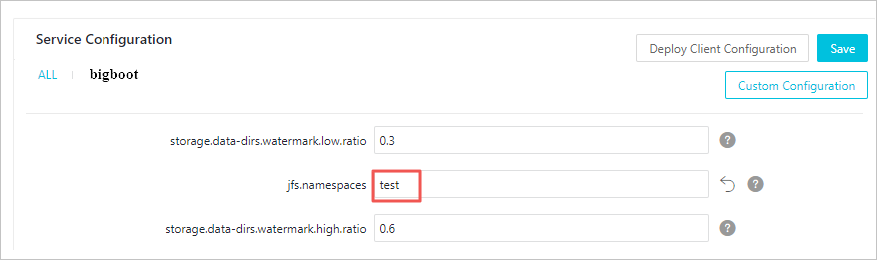
カスタム設定をクリックします。
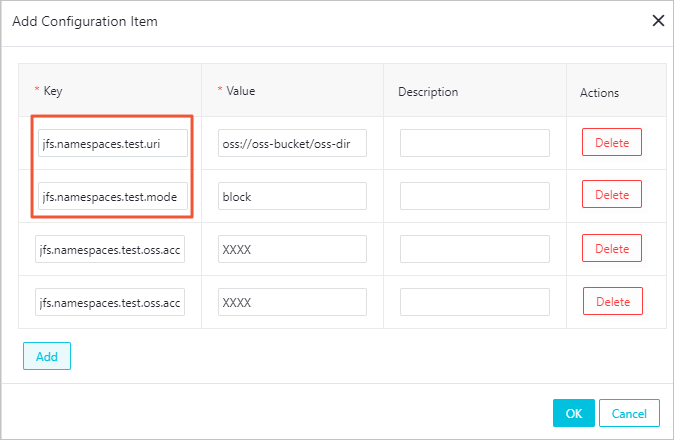
必須パラメーターを追加します。以下の表にすべての設定項目をリストします。必須とマークされた項目は設定する必要があります。
パラメーター 必須 説明 例 jfs.namespacesはい 有効にする名前空間。複数の名前空間はカンマで区切ります。 testjfs.namespaces.test.uriはい この名前空間の OSS ストレージバックエンド。バケットのルートまたは特定のディレクトリに設定します。そのディレクトリが名前空間のルートになります。 oss://oss-bucket/oss-dirjfs.namespaces.test.modeはい ストレージモード: blockまたはcache。blockjfs.namespaces.test.oss.access.keyいいえ OSS バックエンドの AccessKey ID。EMR クラスターと OSS バケットが同じアカウントの同じリージョンにある場合は省略します (パスワードレスアクセスが適用されます)。 xxxxjfs.namespaces.test.oss.access.secretいいえ OSS バックエンドの AccessKey Secret。パスワードレスアクセスを使用する場合は省略します。 — 設定を保存してデプロイし、SmartData サービスのすべてのコンポーネントを再起動します。
クラスター作成時の設定
クラスター作成時に、カスタムソフトウェア設定で設定エントリの JSON 配列を渡します。次の例では、パスワードレス OSS アクセスで test 名前空間を設定します:
[
{
"ServiceName": "BIGBOOT",
"FileName": "bigboot",
"ConfigKey": "jfs.namespaces",
"ConfigValue": "test"
},
{
"ServiceName": "BIGBOOT",
"FileName": "bigboot",
"ConfigKey": "jfs.namespaces.test.uri",
"ConfigValue": "oss://oss-bucket/oss-dir"
},
{
"ServiceName": "BIGBOOT",
"FileName": "bigboot",
"ConfigKey": "jfs.namespaces.test.mode",
"ConfigValue": "block"
}
]
クラスターが作成されると、サービスはカスタムパラメーターで自動的に開始されます。
JindoFS の使用
JindoFS は HDFS ベースのツールと互換性があります。コマンドとジョブ設定で hdfs:// プレフィックスを jfs:// に置き換えます。Hadoop、Hive、Spark、Flink、Presto、Impala をサポートしています。
シェルコマンド
hadoop fs -ls jfs://your-namespace/
hadoop fs -mkdir jfs://your-namespace/test-dir
hadoop fs -put test.log jfs://your-namespace/test-dir/
hadoop fs -get jfs://your-namespace/test-dir/test.log ./MapReduce ジョブ
hadoop jar /usr/lib/hadoop-current/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar teragen \
-Dmapred.map.tasks=1000 10737418240 jfs://your-namespace/terasort/input
hadoop jar /usr/lib/hadoop-current/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.8.5.jar terasort \
-Dmapred.reduce.tasks=1000 jfs://your-namespace/terasort/input jfs://your-namespace/terasort/outputSpark SQL
CREATE EXTERNAL TABLE IF NOT EXISTS src_jfs (key INT, value STRING)
LOCATION 'jfs://your-namespace/Spark_sql_test/';ディスク領域の管理
JindoFS はデータを OSS に保存するため、総容量は実質的に無制限です。ローカルディスクはキャッシングと冗長コピーに使用されます。JindoFS は 2 つのウォーターマークパラメーターを使用して、ローカルディスクの使用量を自動的に管理します:
| パラメーター | 説明 |
|---|---|
node.data-dirs.watermark.high.ratio | ディスクごとのディスク使用率の上限 (0–1)。ディスクがこのしきい値に達すると、JindoFS はコールドデータを削除します。 |
node.data-dirs.watermark.low.ratio | ディスクごとのディスク使用率の下限 (0–1)。ディスク使用率がこのレベルに低下するまで削除が続行されます。 |
上限ウォーターマークは下限ウォーターマークよりも大きい必要があります。デフォルトでは、JindoFS はすべてのデータディスクの総容量を使用します。
ストレージポリシーの設定
JindoFS は、パフォーマンス、信頼性、コストのバランスをとるための 4 つのストレージポリシーを提供します。デフォルトのポリシーは WARM です。新しいファイルは、親ディレクトリのストレージポリシーを継承します。
| ポリシー | 説明 | 使用場面 |
|---|---|---|
| COLD | OSS に 1 つのコピー、ローカルバックアップなし。 | データへのアクセスがまれで、ローカルキャッシングが不要な場合 |
| WARM (デフォルト) | OSS に 1 つのコピー、ローカルに 1 つのバックアップ。ローカルコピーにより、後続の読み取りが高速化されます。 | 標準的なワークロード |
| HOT | OSS に 1 つのコピー、ローカルに複数のバックアップ。 | 最大の読み取りスループットが必要なデータ |
| TEMP | ローカルバックアップのみ 1 つ。一時データに対する高性能な読み取りと書き込み。データ信頼性は低下します。 | 高性能な I/O が要求される一時データ |
ストレージポリシーの設定
ディレクトリにストレージポリシーを設定します。
jindo dfsadmin -R -setStoragePolicy <path> <policy>| 引数 | 説明 |
|---|---|
<path> | ポリシーを適用するディレクトリパス |
<policy> | ポリシー名:COLD、WARM、HOT、または TEMP |
-R | (オプション) <path> |
ストレージポリシーの取得
ディレクトリの現在のストレージポリシーを取得します。
jindo dfsadmin -getStoragePolicy <path>| 引数 | 説明 |
|---|---|
<path> | クエリ対象のディレクトリパス |
管理ツール
jindo dfsadmin ツールは、JindoFS の管理コマンドを提供します。jindo dfsadmin --help を実行して、利用可能なすべてのオプションを確認してください。
コールドデータのアーカイブ
ローカルデータブロックを明示的に削除し、OSS コピーのみを保持します。これを使用して、データへのアクセス頻度が低くなったディレクトリのローカルディスク領域を解放します。
jindo dfsadmin -archive <path>| 引数 | 説明 |
|---|---|
<path> | ローカルデータブロックを削除するディレクトリ |
例:Hive がデータを日単位でパーティション分割し、1 週間以上前のパーティションがアクティブでなくなった場合、それらのパーティションディレクトリで archive を実行してローカルディスク領域を解放し、データは OSS でアクセス可能な状態を維持します。
メタデータの差異の表示 (キャッシュモード)
ローカルのキャッシュデータと OSS バックエンドとの間の差異を表示します。デフォルトでは、<path> の直下のサブディレクトリのみを比較します。
jindo dfsadmin -R -diff <path>| 引数 | 説明 |
|---|---|
<path> | 比較するパス |
-R | (オプション) <path> |
メタデータの同期 (キャッシュモード)
ローカル記憶域と OSS バックエンド間のメタデータを同期します。デフォルトでは、<path> の直下のサブディレクトリのみを同期します。
jindo dfsadmin -R -sync <path>| 引数 | 説明 |
|---|---|
<path> | 同期対象のパス |
-R | (任意)<path> |