JindoFS は、E-MapReduce (EMR) 向けのクラウドネイティブなファイルシステムです。Object Storage Service (OSS) をストレージバックエンドとして使用し、ローカルディスクキャッシュと専用のメタデータサービスを組み合わせています。HDFS レベルのメタデータパフォーマンスと、コンピュートクラスターから独立してスケールするエラスティックストレージが必要な場合に JindoFS を使用します。
このトピックは、EMR V3.20.0 から V3.22.0 (V3.22.0 を除く) を対象としています。EMR V3.22.0 以降については、「EMR V3.22.0 から V3.26.3 での JindoFS の使用」をご参照ください。
仕組み
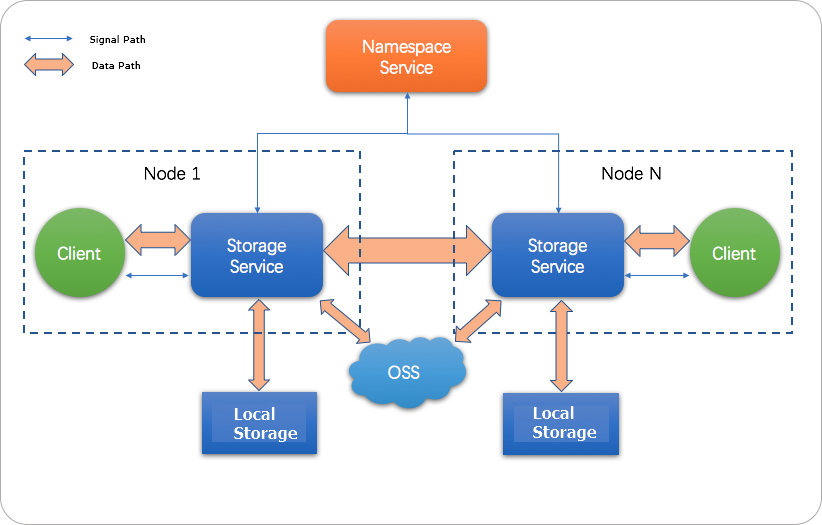
JindoFS は、2 つの内部サービスを使用してストレージとメタデータを分離します:
-
ストレージサービスは、データを OSS に書き込み、OSS に組み込まれた冗長性によって高い信頼性を確保します。頻繁にアクセスされるデータは、クラスターのローカルディスクにもキャッシュされ、読み取りを高速化します。
-
名前空間サービスは、ファイルメタデータをローカルで管理します。メタデータクエリは OSS ではなく名前空間サービスに送信されるため、JindoFS は Hadoop 分散ファイルシステム (HDFS) と同等のメタデータクエリパフォーマンスを実現します。
JindoFS は、ブロックストレージモードとキャッシュモードの 2 つのストレージモードをサポートしています。このトピックでは、ブロックストレージモードについて説明します。
ストレージシステムの選択
EMR は、OssFileSystem、HDFS、JindoFS の 3 つのストレージシステムを提供します。OssFileSystem と JindoFS はどちらも OSS をストレージバックエンドとして使用します。
| 機能 | Hadoop OSS | EMR OssFileSystem | EMR HDFS | EMR JindoFS |
|---|---|---|---|---|
| ストレージ容量 | 非常に大きい | 非常に大きい | クラスターの規模に依存 | 非常に大きい |
| 信頼性 | 高 | 高 | 高 | 高 |
| スループット要因 | サーバー | キャッシュのディスク I/O | ディスク I/O | ディスク I/O |
| メタデータクエリ効率 | 低 | 中 | 高 | 高 |
| スケールアウト | 容易 | 容易 | 容易 | 容易 |
| スケールイン | 容易 | 容易 | ノードのデコミッションが必要 | 容易 |
| データローカリティ | なし | 弱 | 強 | 中 |
JindoFS (ブロックストレージモード) の使用が推奨されるケース:
-
大量のメタデータクエリ:JindoFS は HDFS レベルのメタデータパフォーマンスを提供するため、ファイルのリスト表示、状態確認、名前変更を頻繁に行うワークロードに適しています。
-
エラスティッククラスターでの大規模データ:ストレージはクラスターから独立してスケールします。ノードのデコミッションやデータ移行を行うことなく、クラスターをスケールインまたはスケールアウトできます。
-
Write Once Read Many (WORM) ワークロード:ローカルディスクキャッシュにより、固定データセットに対する繰り返し読み取りが高速化されます。
-
データローカリティが重要:JindoFS は、データを最初に書き込んだノードにローカルバックアップを保存するため、その後の読み取り時のネットワーク I/O が削減されます。
前提条件
開始する前に、以下が準備できていることを確認してください:
-
EMR V3.20.0 から V3.22.0 (V3.22.0 を除く) を実行している EMR クラスター。クラスター作成時に [SmartData] と [Bigboot] が選択されている必要があります。手順については、「クラスターの作成」をご参照ください。
-
OSS バケット。高いパフォーマンスと安定性を確保し、AccessKey ペアを設定せずにパスワードなしのアクセスを有効にするために、バケットを EMR クラスターと同じリージョンに保存してください。
Bigboot は、分散データ管理とコンポーネント管理サービスを提供します。SmartData は Bigboot 上に構築され、JindoFS をアプリケーション層に公開します。
JindoFS の設定
2 つの設定方法があります。クラスターが既に存在する場合はクラスター作成後の設定方法を、クラスター起動時に設定を自動化したい場合はクラスター作成時の設定方法を使用します。
クラスター作成後の設定
-
EMR コンソールで、ご利用のクラスターの Bigboot 設定ページに移動します。
-
以下のパラメーターを設定します。コンソールで赤枠で囲まれたパラメーターは必須です。
説明JindoFS は複数の名前空間をサポートしています。このトピックの例では、
testという名前の名前空間を使用します。パラメーター 説明 例 oss.access.bucketJindoFS のストレージバックエンドとして使用される OSS バケットの名前。 my-emr-bucketoss.data-dirJindoFS がデータを保存するバケット内のディレクトリ。最初の書き込み時に自動的に作成されるため、事前に作成しないでください。 jindoFS-1oss.access.endpointOSS バケットが存在するリージョンのエンドポイント。 oss-cn-hangzhou-internal.aliyuncs.comoss.access.keyOSS アクセス用の AccessKey ID。バケットがクラスターと同じリージョンにある場合 (パスワードなしのアクセス) は省略します。 — oss.access.secretOSS アクセス用の AccessKey Secret。バケットがクラスターと同じリージョンにある場合 (パスワードなしのアクセス) は省略します。 — 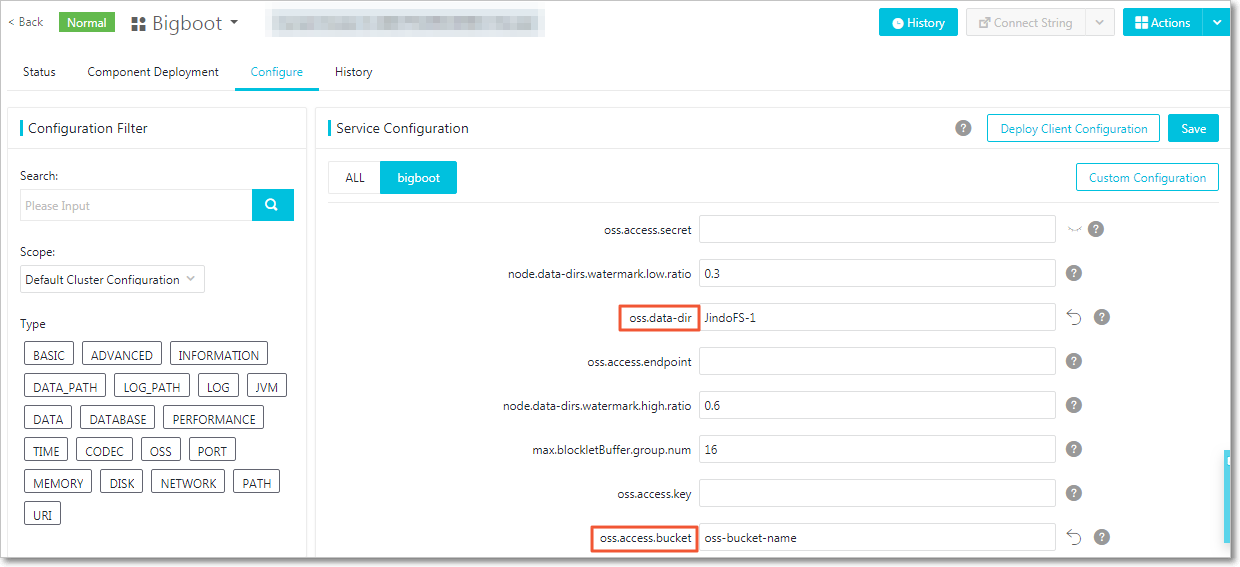
-
設定を保存してデプロイします。
-
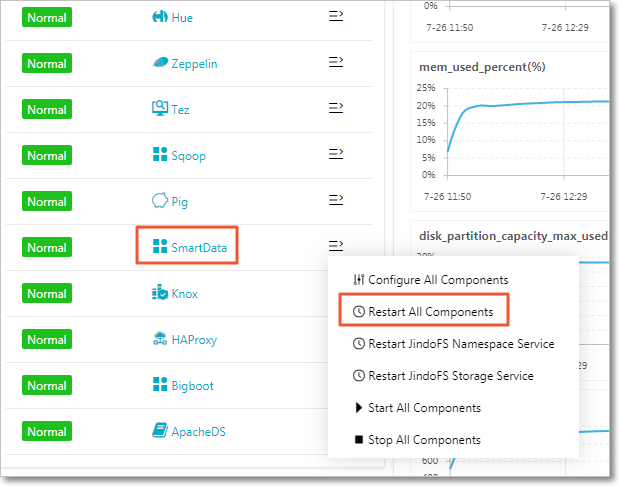
変更を有効にするには、すべての SmartData コンポーネントを再起動します。


クラスター作成時の設定
クラスター作成時に、Bigboot パラメーターをカスタム設定として渡します。クラスターは起動後に自動的に設定を適用します。
-
クラスター作成ページで、[カスタムソフトウェア設定] を有効にします。
-
[詳細設定] セクションで、次の JSON を追加します。値をご利用の OSS バケット名とデータディレクトリに置き換えてください。
[ { "ServiceName": "BIGBOOT", "FileName": "bigboot", "ConfigKey": "oss.data-dir", "ConfigValue": "jindoFS-1" }, { "ServiceName": "BIGBOOT", "FileName": "bigboot", "ConfigKey": "oss.access.bucket", "ConfigValue": "oss-bucket-name" } ]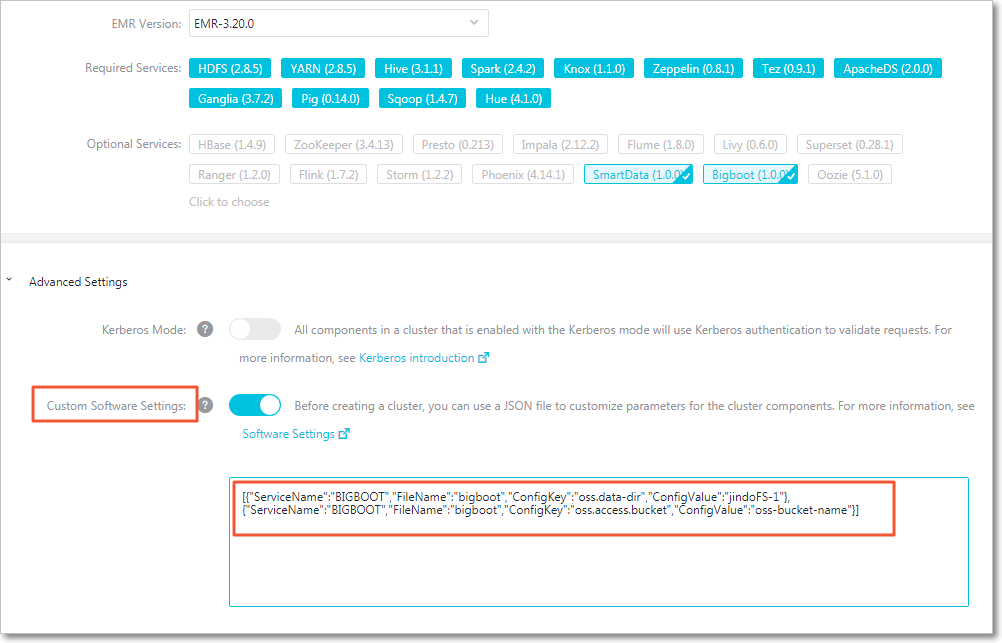
-
クラスターの作成を完了します。SmartData は自動的に再起動し、設定を適用します。

JindoFS の使用方法
JindoFS は jfs:// という URI プレフィックスを使用し、コマンド構文は HDFS と同じです。
ディレクトリのリスト表示:
hadoop fs -ls jfs:///ディレクトリの作成:
hadoop fs -mkdir jfs:///test-dirファイルのアップロード:
hadoop fs -put test.log jfs:///test-dir/JindoFS からデータを読み取れるのは、EMR クラスターで Hadoop、Hive、Spark のジョブが実行されている場合のみです。
ディスク領域の管理
JindoFS はローカルディスクにデータをキャッシュして読み取りを高速化します。ローカルディスクの容量は有限であるため、JindoFS は高ウォーターマーク/低ウォーターマークメカニズムを使用して、コールドデータを自動的に削除します。
Bigboot でウォーターマークパラメーターを設定します:
| パラメーター | 説明 |
|---|---|
node.data-dirs.watermark.high.ratio |
データディスクごとのディスク領域使用量の上限 (0~1)。使用量がこの比率に達すると、JindoFS は最も最近アクセスされていないローカルブロックの削除を開始します。 |
node.data-dirs.watermark.low.ratio |
データディスクごとのディスク領域使用量の下限 (0~1)。使用量がこの比率に低下するまで削除が続行されます。 |
デフォルトでは、JindoFS はすべてのデータディスクの合計容量を使用します。高比率は低比率よりも高く設定してください。値が逆になると設定エラーが発生します。
ストレージポリシーの設定
JindoFS は、ファイルのコピーを OSS とローカルディスクにいくつ保持するかを制御する 4 つのストレージポリシーを提供します。デフォルトポリシーは WARM です。
| ポリシー | OSS バックアップ | ローカルバックアップ | 最適な用途 |
|---|---|---|---|
| COLD | はい | なし | ほとんどアクセスされないアーカイブデータ |
| WARM | はい | 1 | 汎用ワークロード (デフォルト) |
| HOT | はい | 複数 | 頻繁に読み取られるホットデータ |
| TEMP | なし | 1 | 一時データ。I/O は高速ですが、信頼性は低くなります |
新しいファイルは、親ディレクトリのストレージポリシーを継承します。
ストレージポリシーの設定:
jindo dfsadmin -R -setStoragePolicy <path> <policy>-
<path>:ターゲットディレクトリ。 -
<policy>:COLD、WARM、HOT、またはTEMPのいずれか。 -
-R:ポリシーをすべてのサブディレクトリに再帰的に適用します。
現在のストレージポリシーの取得:
jindo dfsadmin -getStoragePolicy <path>コールドデータのアーカイブ (ローカルブロックの削除):
archive コマンドを使用すると、OSS のコピーを保持したまま、ローカルブロックを明示的に削除できます。これは、古いパーティションが頻繁にアクセスされなくなったパーティションテーブルに便利です。
jindo dfsadmin -archive <path>たとえば、Hive がテーブルを日単位でパーティション分割している場合、7 日より古いディレクトリに対して毎週 archive を実行すると、OSS からデータを削除せずにローカルディスク領域を解放できます。