このトピックでは、クラスタ管理に関するよくある質問への回答を提供します。
データディスクの暗号化を有効にするにはどうすればよいですか?データディスクの暗号化を有効にした後、どのような影響がありますか?
クラスタまたはノードグループを作成するときに、ECS リソースが不足していることを示すエラーメッセージが表示された場合はどうすればよいですか?
クラスタのスケールアウト中に「指定されたパラメータ AddNumber が無効です」というエラーメッセージが表示された場合はどうすればよいですか?
クラスタをスケールアウトするときに、ECS リソースが不足していることを示すエラーメッセージが表示された場合はどうすればよいですか?
SystemMaintenance.Redeploy という名前の ECS システムイベントが発生した場合はどうすればよいですか?
EMR クラスタの ECS インスタンスのディスクが EMR クラスタのタグを自動的に継承するようにするにはどうすればよいですか?
エラーメッセージ QuotaExceeded.PrivateIpAddress が表示された場合はどうすればよいですか?
クラスタの作成、スケールアウト、またはアップグレード時に、アカウントの残高が不足していることを示すエラーメッセージが表示された場合はどうすればよいですか?
クラスタまたはディスクのスケールアウト時に、エラーメッセージ QuotaExceed.DiskCapacity が表示された場合はどうすればよいですか?
クラスタの作成時またはスケールアウト時に、エラーメッセージ QuotaExceed.DiskCapacity が表示された場合はどうすればよいですか?
サービスに関する FAQ:
EMR Doctor に関する FAQ:
EMR クラスタをアップグレードできますか?
いいえ、E-MapReduce(EMR)クラスタとクラスタにデプロイされているサービスをアップグレードすることはできません。 EMR クラスタまたはクラスタにデプロイされているサービスをアップグレードするには、クラスタをリリースして別のクラスタを作成します。
EMR クラスタはどのサービスをサポートしていますか?
EMR クラスタでサポートされているサービスは、クラスタのバージョンとクラスタのタイプによって異なります。 詳細については、「ディストリビューション」をご参照ください。
EMR コンソールで Zeppelin サービスを追加できますか?
EMR では、EMR コンソールで Zeppelin サービスを追加することはできません。 マスターノードとして使用される Elastic Compute Service(ECS)インスタンスに Zeppelin をインストールできます。 EMR コンソールに追加できない他のサービスについては、基盤となる ECS インスタンスにインストールして O&M 操作を実行できます。 クラスタのシナリオとサポートされているサービスの詳細については、「サービスの追加」をご参照ください。
EMR クラスタは Oozie をサポートしていますか? Oozie がサポートされておらず、サービスを使用したい場合はどうすればよいですか?
EMR V5.8.0 以降のマイナーバージョンの DataLake クラスタと EMR V3.42.0 以降のマイナーバージョンは、Oozie を提供していません。 ワークフローを使用してサービスをスケジュールする場合は、EMR ワークフローを使用できます。 詳細については、「EMR ワークフローとは」をご参照ください。
高可用性 EMR クラスタにマスターノードが 3 つあるのはなぜですか?
3 つのマスターノードを持つ高可用性 EMR クラスタは、2 つのマスターノードを持つ高可用性 EMR クラスタよりも信頼性が高くなります。 2 つのマスターノードのみを持つ高可用性 EMR クラスタは、現在はサポートされていません。
高可用性クラスタの場合、EMR はマスターノードを異なる基盤となるハードウェアに分散させて、障害のリスクを軽減します。
データディスクの暗号化を有効にするにはどうすればよいですか?データディスクの暗号化を有効にした後、どのような影響がありますか?
EMR クラスタを作成するときに、[基本構成] ステップの [詳細設定] セクションで、データディスクの暗号化をオンにするかどうかを決定できます。 詳細については、「データディスクの暗号化を有効にする」をご参照ください。
データディスクの暗号化は、EMR クラスタの作成時にのみ有効にできます。 既存の EMR クラスタのデータディスクの暗号化を有効にすることはできません。
データディスクが暗号化されると、転送中のデータとディスク上の保存データが暗号化されます。 ビジネスにセキュリティコンプライアンス要件がある場合は、データディスクの暗号化機能を使用できます。 データディスクの暗号化は、ECS インスタンスのオペレーティングシステムレベルではアプリケーションに対して透過的であり、ジョブの実行には影響しません。
作成に失敗したクラスタをリリースするにはどうすればよいですか?
ほとんどの場合、EMR クラスタの作成に失敗するのは、RDS の構成が正しくないか、選択した ECS インスタンスタイプが使用できないためです。
一部の ECS インスタンスが作成され、クラスタステータスが起動失敗の場合、ECS コンソールに移動して ECS インスタンスをリリースする必要があります。 ECS インスタンスをリリースすると、システムは EMR クラスタをリリースします。
EMR クラスタのデプロイに失敗し、クラスタステータスが予期せず終了した場合、クラスタにはリソースがなく、クラスタの料金は発生しません。 [削除] 列の [削除] をクリックして、クラスタを削除できます。
クラスタを作成した後に、EMR クラスタにサービスを追加できますか?
EMR では、クラスタを作成した後に、特定のサービスを EMR クラスタに追加できます。 詳細については、「サービスの追加」をご参照ください。
サービスを追加した後、特定の既存のサービスの関連構成を変更し、既存のサービスを再起動して、構成を有効にする必要がある場合があります。 オフピーク時にサービスを追加することをお勧めします。
クラスタに追加できるサービスは、EMR のバージョンによって異なります。 クラスタに追加できる実際のサービスは、EMR コンソールに表示されます。
サービスの構成を変更した後、サービスを再起動する必要がありますか?
Spark、Hive、Hadoop 分散ファイルシステム(HDFS)などの EMR クラスタのサーバー側の構成を変更する場合は、変更を有効にするためにサービスを再起動する必要があります。 EMR クラスタのクライアント側の構成を変更する場合は、[クライアント構成のデプロイ] をクリックするだけで、変更が有効になります。 構成項目を変更または追加する方法については、「構成項目の管理」をご参照ください。
ローリング再起動とは何ですか?
ローリング再起動とは、前の ECS インスタンスが再起動され、前の ECS インスタンスにデプロイされているすべてのビッグデータサービスが復元された後にのみ、システムが ECS インスタンスを再起動するプロセスのことです。 ECS インスタンスの再起動には約 5 分かかります。
既存の EMR クラスタの ECS インスタンスにパブリック IP アドレスを関連付けるにはどうすればよいですか?
Elastic IP アドレス(EIP)を作成し、EIP を VPC ネットワークタイプでパブリック IP アドレスがない ECS インスタンスに関連付けることができます。 これにより、インターネット経由でインスタンスにアクセスできます。 詳細については、「EIP をインスタンスに関連付ける」をご参照ください。
どのようなシナリオでデプロイメントセットに追加をオンにする必要がありますか?
デプロイメントセット機能は Alibaba Cloud ECS によって提供され、ECS インスタンスの分散を制御するために使用されます。 クラスタのコアノードがローカルディスクを搭載した ECS インスタンスを使用している場合は、データセキュリティを向上させるために、デプロイメントセットに追加をオンにすることをお勧めします。 デプロイメントセットに追加をオンにすると、複数の ECS インスタンスが同じ物理マシンにデプロイされるのを防ぐことができます。 これにより、物理マシンに障害が発生した場合、他の物理マシン上の ECS インスタンスは影響を受けず、ローカル HDFS データは失われません。
デプロイメントセットには最大 20 個の ECS インスタンスを追加できます。 詳細については、「デプロイメントセットにノードを追加する」をご参照ください。
EMR クラスタをスケールアウトするときに、デプロイメントセットに追加パラメータを構成するにはどうすればよいですか?
デフォルトでは、デプロイメントセットに追加は、ローカルディスクを搭載した ECS インスタンスではオンになり、他のディスクを搭載した ECS インスタンスではオフになります。 ビジネス要件に基づいて、デプロイメントセットに追加をオンにするかどうかを指定できます。 詳細については、「デプロイメントセットにノードを追加する」をご参照ください。
EMR クラスタをスケールアウトするときに、ディスクサイズを指定するにはどうすればよいですか?
EMR クラスタをスケールアウトする場合、新しいノードのディスクサイズは、ノードグループの既存のノードのディスクサイズと同じであり、変更できません。 ビジネス要件に基づいて、ノードグループのディスクを拡張できます。 詳細については、「ディスクの拡張」をご参照ください。
EMR クラスタのディスクのサイズを変更できますか?
EMR クラスタのデータディスクは拡張できますが、縮小することはできません。 システムディスクのサイズを変更することはできません。
EMR クラスタのデータディスクを拡張するには、次の手順を実行します。目的のクラスタの [ノード] タブで、ノードグループを見つけ、「操作」列の [ディスクの拡張] をクリックします。詳細については、「ディスクを拡張する」をご参照ください。
EMR クラスタをスケールアウトまたはスケールインできますか?
はい、EMR クラスタをスケールアウトまたはスケールインできます。 ただし、スケールインとスケールアウトのルールは、ノードタイプによって異なります。
スケールアウト:コアノードとタスクノードのみを追加できます。 デフォルトでは、追加されたノードの構成は、ノードグループの既存のノードの構成と同じです。 スケールアウト中は、注文の支払いを完了していることを確認する必要があります。 注文の支払いを完了しないと、スケールアウトは失敗します。 詳細については、「EMR クラスタのスケールアウト」をご参照ください。
スケールイン:スケールインルールは、ノードタイプによって異なります。
タスクノードグループをスケールインする方法については、「クラスタのスケールイン」をご参照ください。
コアノードグループをスケールインする方法については、「コアノードグループのスケールイン」をご参照ください。
ノードグループの ECS インスタンスの構成を変更するにはどうすればよいですか?
サブスクリプション EMR クラスタのノードグループの仕様をアップグレードして、ノードグループの ECS インスタンスの構成を変更できます。 ノードグループの仕様をダウングレードすることはできません。
ノードグループのスペックをアップグレードするには、次の手順を実行します。目的のクラスターの [ノード] タブで、目的のノードグループを見つけ、[操作] 列の  アイコンにポインターを移動し、[構成のアップグレード] を選択します。詳細については、「ノード構成をアップグレードする」をご参照ください。
アイコンにポインターを移動し、[構成のアップグレード] を選択します。詳細については、「ノード構成をアップグレードする」をご参照ください。
クラスタのスケールアウト中に「指定されたパラメータ AddNumber が無効です」というエラーメッセージが表示された場合はどうすればよいですか?
問題の説明:クラスタのスケールアウト中に、
指定されたパラメータ AddNumber が無効です。追加インスタンス番号:xxx は deploymentSet availableAmount:xxx deploymentSetId:ds-uf6gwfou0a13kekupt14xxxx より大きいですというエラーメッセージが表示されます。原因:スケールアウトするクラスタでデプロイメントセットに追加がオンになっており、ノードグループのノード数がデプロイメントセットの上限を超えています。 デプロイメントセットの詳細については、「デプロイメントセットにノードを追加する」をご参照ください。
解決策:ECS テクニカルサポートに連絡して、現在のアカウントのデプロイメントセットに追加できるノードの最大数を増やしてください。
サービス運用ログの収集を停止するにはどうすればよいですか?
EMR にデータ収集させたくない場合は、サービス運用ログの収集を無効にできます。
サービス運用ログの収集を無効にすると、EMR クラスタのヘルスチェックとテクニカルサポートが制限されます。 クラスタの他の機能は引き続き使用できます。 慎重に行ってください。
解決策:
サービス運用ログの収集を無効にします。
クラスタを作成するときに、ソフトウェア構成ステップで [サービス運用ログの収集] をオフにします。
既存のクラスタの場合は、クラスタの [基本情報] タブの [ソフトウェア情報] セクションで、[サービス運用ログの収集ステータス] をオフにします。
サービス運用ログの収集が無効になっているかどうかを確認します。
/usr/local/ilogtail/user_log_config.json ファイルに
namenode-log情報が存在するかどうかを確認します。 namenode-log 情報が存在しない場合、サービス運用ログの収集は無効になっています。説明サービス運用ログの収集を無効にした後、構成が有効になるまで約 2 ~ 3 分かかります。
サービス運用ログにはどのような情報が収集されますか?
サービス運用ログには、クラスタ上のサービスコンポーネントの実行に関するデータのみが含まれています。 ワンクリックですべてのサービスのログ収集を有効または無効にできます。 ログ収集を無効にすると、EMR クラスタのヘルスチェックとアフターセールスのテクニカルサポートが制限されます。
クラスタを作成すると、デフォルトでサービス運用ログの収集がオンになります。 ビジネス要件に基づいて、スイッチをオフにするかどうかを決定できます。 詳細については、「サービス運用ログの収集を停止するにはどうすればよいですか?」をご参照ください。
どのタイプのクラスタが EMR Doctor(EMR コンソールのヘルス診断機能)をサポートしていますか?
DataLake クラスタと Hadoop クラスタのみがヘルス診断機能をサポートしています。 EMR クラスタを作成した後、クラスタの [監視と診断] タブにある [ヘルス診断] サブタブをクリックして、ヘルスチェック機能を使用できます。
EMR Hadoop クラスタを作成する場合は、クラスタでヘルス診断機能を使用する前に、EMR Doctor をアクティブにする必要があります。 詳細については、「EMR Doctor のアクティブ化(Hadoop クラスタ)」をご参照ください。
EMR Doctor のインストールまたはアップグレードは、EMR クラスタのサービスとクラスタで実行されるジョブに影響を与えますか?
EMR Doctor のインストールまたはアップグレード中は、EMR クラスタのサービスは再起動されず、クラスタで実行されている既存のジョブには影響しません。 EMR Doctor がインストールされると、EMR Doctor に必要なパラメータがクラスタに自動的に構成されます。 手動で構成する必要はありません。
EMR Doctor のインストールまたはアップグレード中は、EMR は YARN、Spark、Tez、Hive などのサービスの構成をクラスタに配信します。 EMR Doctor をインストールまたはアップグレードする前に、一部のサービス構成が変更および保存されているが配信されていないかどうかを確認し、サービス構成をクラスタに配信することの影響を評価することをお勧めします。
EMR Doctor はどのようなタイプのデータを収集しますか?
EMR Doctor は実際のデータを収集したり、実際のファイルまたはファイルの内容をスキャンしたりしません。
EMR Doctor は、ジョブの開始時刻、終了時刻、メトリック、カウンターなど、必要なイベントデータのみを収集します。
EMR Doctor は課金されますか?
EMR Doctor は無料です。
ジョブデータ収集はジョブの実行にどのような影響を与えますか?
EMR Doctor のストレージメタデータ収集機能は、ユーザーリソースの量に基づいて収集されるリソースの量を動的に調整できます。 これにより、過剰なユーザーリソースが占有されるのを防ぎます。
EMR Doctor のジョブ収集機能は、Java プローブテクノロジーに基づいて動作します。 この機能は、Java プロセスの監視を個別に開始しません。 ジョブデータは非同期モードで収集されます。 ジョブのメインプロセスをブロックしません。 ジョブ収集の負荷が大きい場合、収集されたデータは自動的に破棄され、パラメータを構成することで収集頻度を調整できます。
次の表に、いくつかの TPC-DS テストのデータを示します。
SQL とエンジン | EMR Doctor を使用した場合の収集期間(10 回の計算ラウンドに基づくジョブ収集の平均期間) | EMR Doctor を使用しない場合の収集期間(10 回の計算ラウンドに基づくジョブ収集の平均期間) |
query7(Spark) | 21.0 秒 | 21.2 秒 |
query71(Tez) | 50.8 秒 | 49.8 秒 |
query19(MapReduce) | 68.6 秒 | 68.2 秒 |
この例では、TPC-DS ベンチマークに基づくテストが実行されますが、テストは TPC-DS ベンチマークテストのすべての要件を満たしていません。 その結果、テスト結果は TPC-DS ベンチマークテストの公開結果と一致しない場合があります。
収集レポートはいつ入手できますか?
EMR クラスタに EMR Doctor がインストールまたはアップグレードされると、日次クラスタレポート機能は、ユーザーが実行するジョブとストレージメタデータ収集機能が有効になっているかどうかに基づいて分析を実行します。 この場合、EMR クラスタにはジョブが含まれている必要があります。
コンピューティングジョブ:EMR クラスタのコンピューティングジョブが収集されると、ジョブの最新のレポートを翌日表示できます。 レポートの内容は、クラスタ内のジョブの実行ステータスに基づいてクラスタ全体を評価したものです。
ストレージ分析:EMR Doctor のストレージリソースに関する情報の収集機能は、デフォルトで無効になっています。 この機能は手動で有効にできます。 ストレージリソースに関する情報の収集機能を有効にすると、関連情報は当日午前 10 時に収集されます。 データが収集されると、翌日の朝にデータが分析され、分析結果に基づいてレポートが生成されます。 当日の午後にデータが収集された場合は、翌々日にレポートを表示できます。
パラメータに特定の値を指定できますか?
EMR Doctor によって提供される最適化の提案は方向性です。 たとえば、特定のパラメータ値を提供せずに、メモリの量を減らし、ガベージコレクションパラメータを変更することをお勧めします。 EMR Doctor は、記録とサンプリングの方法を使用してジョブデータを収集します。 EMR Doctor は、プログラムへの影響を防ぐことを目的としています。 提案に基づいてパラメータを調整し、構成が適切かどうかを確認する必要があります。
クラスタをスケールアウトするときに、ECS リソースが不足していることを示すエラーメッセージが表示された場合はどうすればよいですか?
問題の説明:クラスタのスケールアウトに失敗し、「ECS リソースが不足しています_OutofStock」または「ECS リソースが不足しています_OperationDenied.NoStock」というエラーメッセージが表示されます。
原因:ノードグループに追加するインスタンスタイプの ECS インスタンスが不足しています。
解決策:指定したインスタンスタイプの ECS インスタンスが十分になった後、スケールアウト操作を実行します。 または、別のインスタンスタイプの ECS インスタンスを含むノードグループを作成します。 詳細については、「ノードグループの作成」をご参照ください。
クラスタまたはノードグループを作成するときに、ECS リソースが不足していることを示すエラーメッセージが表示された場合はどうすればよいですか?
問題の説明:クラスタまたはノードグループの作成に失敗し、「ECS リソースが不足しています_OutofStock」または「ECS リソースが不足しています_OperationDenied.NoStock」というエラーメッセージが表示されます。
原因:クラスタまたはノードグループの作成時に選択したインスタンスタイプの ECS インスタンスが不足しています。
解決策:クラスタまたはノードグループを作成するときに、ECS インスタンスが十分にあり、ビジネス要件を満たす別の ECS インスタンスタイプを選択します。
不要になったサービスを削除するにはどうすればよいですか?
クラスタにデプロイされている既存のサービスを削除することはできません。 サービスが開始されると、コンソールまたは API 操作の呼び出しによってサービスを削除することはできません。
クラスタのノードにログオンするにはどうすればよいですか?
EMR クラスタが作成された後、クラスタの作成時に指定したパスワードを使用して、クラスタのマスターノードにログオンできます。 クラスタの他のノードにログオンする方法については、「クラスタの他のノードにログオンする」をご参照ください。
ノードが関連付けられている vSwitch を表示するにはどうすればよいですか?
ECS 上の Alibaba Cloud EMR では、vSwitch はノードグループのノードに関連付けられています。 [基本情報] タブで関連付けを表示することはできません。 ノードが関連付けられている vSwitch を表示するには、次の手順を実行します。クラスタの [ノード] タブに移動し、ノードが属するノードグループを見つけて、ノードグループ名をクリックします。 [ノードグループ属性] パネルで、vSwitch パラメータの設定を表示します。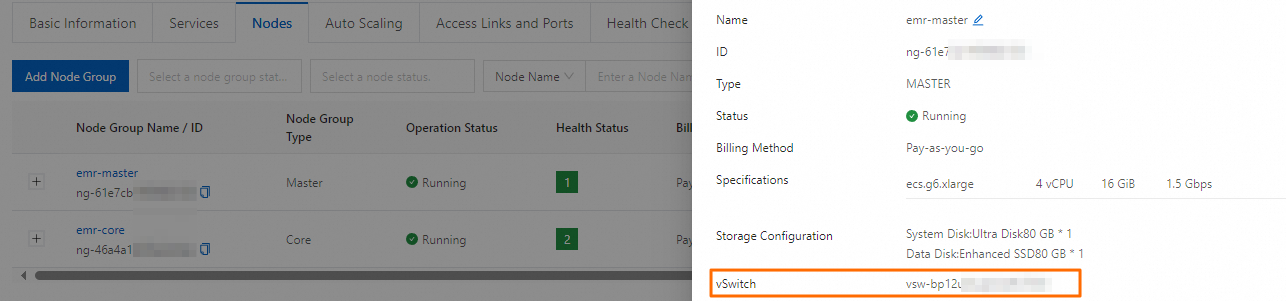
クラスタでパケット損失が頻繁に発生する場合はどうすればよいですか?
問題の説明:クラスタでパケット損失が頻繁に発生し、システムログに
neighbor:arp_cache:neighbor テーブルオーバーフロー!などのエラーメッセージが表示される場合があります。 これは、アドレス解決プロトコル(ARP)キャッシュテーブルが上限に達し、メディアアクセス制御(MAC)アドレスを IP アドレスに効果的にマッピングできないことを示しています。 その結果、ネットワークパフォーマンスが低下します。問題分析:大規模分散システム、特に EMR クラスタが EMR V5.18.0 または V3.52.0 より前のマイナーバージョンであり、1,000 台を超えるサーバーがある場合、ネットワークが不安定になり、パケット損失が発生する可能性があります。 システムパラメータを構成して、ARP キャッシュの管理を最適化できます。
ARP キャッシュテーブルには、MAC アドレスと IP アドレスのペアが格納されます。 関連パラメータ:
net.ipv4.neigh.default.gc_thresh1:ARP キャッシュテーブルのエントリ数がこのパラメータの値より少ない場合、ガベージコレクタはエントリを収集しません。 デフォルト値:128。net.ipv4.neigh.default.gc_thresh2:ARP キャッシュテーブルのエントリ数がこのパラメータの値より大きい場合、ガベージコレクタは 5 秒以内にエントリを収集します。 デフォルト値:512。net.ipv4.neigh.default.gc_thresh3:ARP キャッシュテーブルに保持するエントリの最大数。 デフォルト値:1024。
説明パラメータのデフォルト値は小さくなっています。 その結果、クラスタに 1,000 台を超えるサーバーがある場合、パケット損失とネットワークの不安定が発生します。 この場合、ビジネス要件に基づいてデフォルト値を変更する必要があります。
解決策:
次のコードを
/etc/sysctl.confファイルに追加して、上記のパラメータの値とサーバーへの接続の最大許容数を増やします。net.ipv4.neigh.default.gc_thresh1 = 512 net.ipv4.neigh.default.gc_thresh2 = 2048 net.ipv4.neigh.default.gc_thresh3 = 10240 net.nf_conntrack_max = 524288sudo sysctl -pコマンドを実行して、変更を有効にします。説明エラーメッセージ
sysctl: cannot stat /proc/sys/net/nf_conntrack_max: No such file or directoryがsysctl -pコマンドの実行時に表示される場合は、sudo modprobe nf_conntrackコマンドを実行して nf_conntrack モジュールを読み込んだ後、sysctl -pコマンドを再実行できます。
SystemMaintenance.Redeploy という名前の ECS システムイベントが発生した場合はどうすればよいですか?
SystemMaintenance.Redeploy イベントは、Alibaba Cloud がクラスタの ECS インスタンスの基盤となるホストでソフトウェアとハードウェアの障害の潜在的なリスクを検出したことを示します。 これにより、ECS インスタンスが再デプロイされる可能性があります。 この場合、データ損失を防ぐために、ECS コンソールで [再デプロイ] をクリックしないでください。
解決策:
イベントの詳細に基づいて、イベントが発生したノードを特定します。
障害のあるノードが属するノードグループにノードを追加します。 詳細については、「EMR クラスタのスケールアウト」をご参照ください。
障害のあるノードを削除します。
クラスタのコアノードグループまたはサブスクリプションタスクノードグループをスケールインする方法については、「コアノードグループのスケールイン」に記載されている手順に従ってください。
説明ECS は、サブスクリプション ECS インスタンスのサブスクリプションを解除するときに、払い戻し額を計算して表示します。 ご質問がある場合は、チケットを送信してください。 チケットを送信するときは、[elastic Compute Service(ecs)] を選択します。
従量課金インスタンスを含むタスクノードグループをスケールインする方法については、「クラスタのスケールイン」をご参照ください。
EMR クラスタの ECS インスタンスのディスクが EMR クラスタのタグを自動的に継承するようにするにはどうすればよいですか?
EMR クラスタの ECS インスタンスのディスクが EMR クラスタのタグを自動的に継承するようにするには、リソース管理によって提供される関連リソースタギング機能を使用できます。 これにより、クラウドディスクを ECS インスタンスに接続すると、クラウドディスクは ECS インスタンスの既存のタグを自動的に継承し、後で ECS インスタンスに加えられたタグの変更も継承します。
手順:
リソース管理コンソール にログオンします。
左側のナビゲーションウィンドウで、 を選択します。
[関連リソースのタグ設定] ページで、機能の説明を読み、サービスロールを作成するためのチェックボックスをオンにします。
関連リソースタギング機能を有効にすると、システムは AliyunServiceRoleForTag サービスロールを作成します。 このロールは、関連リソースでタグ関連の操作を実行するために使用されます。 詳細については、「タグのサービスロール」をご参照ください。
[有効化とルールの構成] をクリックします。
[関連リソースのタグ設定] ページの右上隅にある [編集] をクリックし、関連リソースタギングルールを構成します。
さまざまなタイプの関連リソースのタグ継承スコープを [すべてのタグキー] または [特定のタグキー] に設定できます。
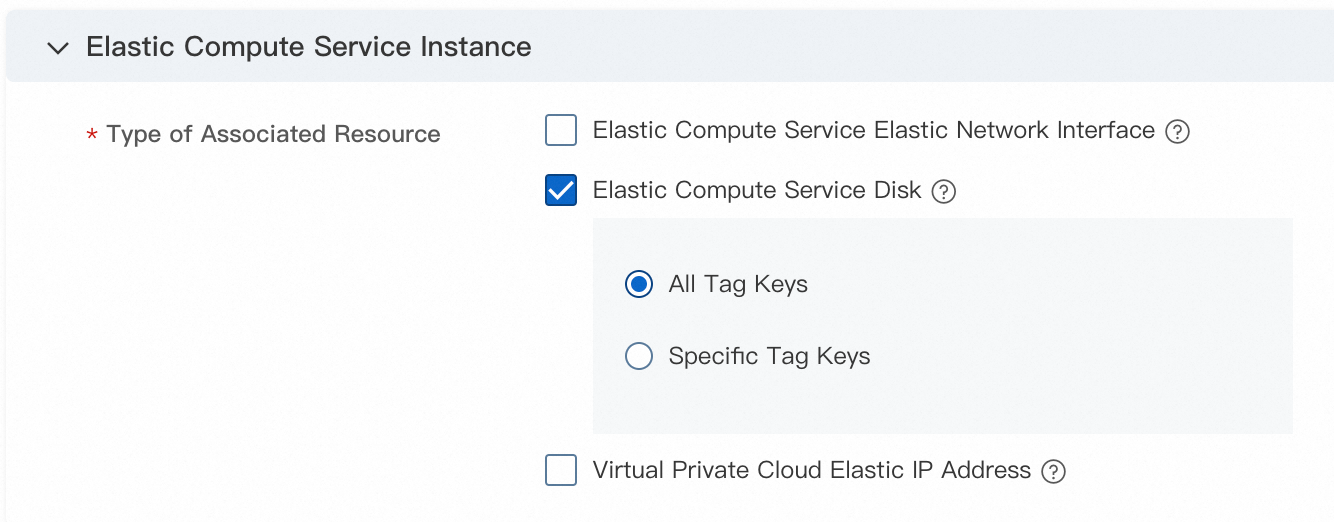
[OK] をクリックします。
関連リソースタギング機能の詳細については、「関連リソースタギング機能を使用する」をご参照ください。
エラーメッセージ IdempotentParameterMismatch が表示された場合はどうすればよいですか?
問題の説明:クラスタをリリースしたり、クラスタ構成をアップグレードしたりすると、次のエラーメッセージが表示される場合があります。
原因:複数のリクエストで同じクライアントトークンが使用されています。
リクエストは以前のリクエストと同じクライアントトークンを使用していますが、同一ではありません。 リクエストが同一でない限り、異なるリクエストでクライアントトークンを再利用しないでください。解決策:クラスタをリリースしているか、クラスタ構成をアップグレードしているかを確認します。 クラスタをリリースしているか、クラスタ構成をアップグレードしている場合は、操作を再実行する必要はありません。 クラスタをリリースしていないか、クラスタ構成をアップグレードしていない場合は、コンソールページを更新します。 その後、EMR コンソールで新しいクライアントトークンが自動的に生成されます。
エラーメッセージ QuotaExceeded.PrivateIpAddress が表示された場合はどうすればよいですか?
問題の説明:クラスタを作成またはスケールアウトすると、次のエラーメッセージが表示される場合があります。
[QuotaExceeded.PrivateIpAddress] 指定された vSwitch「vsw-xxxx」に十分な IP アドレスがありません。原因:選択した vSwitch の使用可能な IP アドレスの数が、クラスタの作成またはスケールアウトに不十分です。
解決策:ノードグループを作成し、十分な IP アドレスを持つ vSwitch を選択します。
LostProxy エラーメッセージが表示された場合はどうすればよいですか?
問題の説明:クラスタの作成、クラスタのスケールアウト、またはサービス構成の更新時に、「taihao-proxy 切断」というエラーメッセージが表示されます。
原因:クラスタノードの EMR プロキシが切断されています。
解決策:
クラスタステータスを確認し、ノードの問題を修正します。
ノードのバッチが切断されている場合は、CPU 使用率とメモリ使用量を確認します。
CPU 使用率またはメモリ使用率が高い場合、クラスタは過負荷になっています。 クラスタ構成をアップグレードするか、クラスタをスケールアウトできます。
CPU 使用率またはメモリ使用率が低い場合は、ネットワークセキュリティグループの構成を確認して、ネットワーク通信が正常であることを確認します。
特定のノードのみが切断されている場合は、ノードの CPU 使用率またはメモリ使用率が 100% に達しているかどうかを確認します。 ノードが過負荷になっている場合は、異常なプロセスがリソースを占有しているかどうかを確認します。 異常なプロセスが存在する場合は、プロセスを終了し、ノードステータスが正常になるかどうかを確認します。 異常なプロセスが存在しない場合は、次の操作を実行します。
マスターノードが切断されている場合は、CPU 使用率の高いプロセスを確認します。 マスターノードの仕様をアップグレードするか、マスター拡張ノードを追加してワークロードを共有できます。
マスター以外のノードがワークロードが高いために切断されているか、応答しない場合は、ノードをアンデプロイするか、新しいノードを追加できます。
ノードにログオンし、次のコマンドを実行してサービスを再起動します。
service taihao-proxy restart
上記の操作が完了したら、クラスタの作成、クラスタのスケールアウト、またはサービス構成の更新を再実行します。
クラスタの作成、スケールアウト、または構成のアップグレード時に、アカウントの残高が不足していることを示すエラーメッセージが表示された場合はどうすればよいですか?
問題の説明:クラスタの作成、スケールアウト、または構成のアップグレード時に、次のエラーメッセージが表示されます。
nvalidAccountStatus.NotEnoughBalance メッセージ:アカウントの残高が不足しているため、後払いプロダクトを注文できません。原因:アカウントの残高が不足しています。
解決策:アカウントの残高を確認し、アカウントの残高が必要なリソースのコストよりも大きいことを確認します。 アカウントの残高が十分であることを確認したら、関連操作を再実行します。
クラスタまたはディスクのスケールアウト時に、エラーメッセージ QuotaExceed.DiskCapacity が表示された場合はどうすればよいですか?
問題の説明:クラスタまたはディスクのスケールアウト時に、次のエラーメッセージが表示される場合があります。
[QuotaExceed.DiskCapacity] ディスクタイプの使用容量がゾーンのクォータを超えました。クォータチェックに失敗しました。原因:インスタンスのディスククォータが上限に達しました。
解決策:特定のディスクタイプの占有容量がゾーンのクォータ制限を超えています。 クォータセンターに移動して、クォータを表示および増やすことができます。
クラスタの作成時またはスケールアウト時に、エラーメッセージ QuotaExceed.DiskCapacity が表示された場合はどうすればよいですか?
問題の説明:クラスタの作成時またはスケールアウト時に、次のエラーメッセージが表示される場合があります。
QuotaExceed.ElasticQuota メッセージ:指定された ECS インスタンスの数が、指定されたインスタンスタイプのクォータを超えました。原因:ECS インスタンスのクォータが上限に達しました。
解決策:別のインスタンスタイプを選択するか、作成するインスタンスの数を減らします。 また、ECS コンソールまたはクォータセンターに移動して、クォータの増加をリクエストすることもできます。
ブートスクリプトが実行に失敗した場合はどうすればよいですか?
操作履歴の詳細ページで、実行に失敗したブートスクリプトの実行ログを表示します。
ログに特定のエラーメッセージが含まれている場合は、エラーメッセージに基づいてブートスクリプトを変更し、スクリプトを再実行します。
ログに特定のエラーメッセージなしで
exitCodeキーワードが含まれている場合は、デバッグを改善するためにブートスクリプトにさらにログ記録ステートメントを追加し、スクリプトを再実行します。ログにタスクがタイムアウトしたことが示されているか、出力が含まれていない場合は、次の項目を確認します。
ブートスクリプトが格納されている OSS バケットに対する読み取りおよび書き込み権限があるかどうかを確認します。
ECS インスタンスが内部 OSS エンドポイントにアクセスできるかどうかを確認します。 その後、スクリプトを再実行します。