Text-to-Image ワークロードでは、ComfyUI と DeepGPU を使用して FLUX および SD モデルの推論速度を高速化できます。たとえば、GPU インスタンスで ComfyUI と DeepGPU を使用すると、標準的なセットアップと比較して、FLUX モデルの Text-to-Image パフォーマンスが約 30% 向上します。このトピックでは、DeepGPU を使用した ComfyUI のインストールと使用方法について説明します。
パフォーマンスの比較
Alibaba Cloud の DeepGPU 推論アクセラレーションコンポーネントは、FLUX.1、SD、または SDXL モデルを使用した Text-to-Image 推論で大幅なパフォーマンス向上を実現します。
ComfyUI と DeepGPU のアクセラレーションノードを使用しないセットアップと比較して、GPU インスタンス (シングルカードの gn8is インスタンスを推奨) でこれらを設定すると、flux1-dev モデルのパフォーマンスが bf16 と fp8 の両方の精度で約 30% 向上します。次の表は、一部のモデルにおける Text-to-Image の高速化パフォーマンスを比較したものです。
|
モデルの重み精度 |
画像解像度 (幅 x 高さ) |
時間 (高速化なし) |
時間 (高速化あり) |
高速化率 |
|
default(bf16) |
1024 x 1024 |
20.83s |
16.62s |
25.3% |
|
default(bf16) |
1280 x 720 |
19.02s |
15.07s |
26.2% |
|
default(bf16) |
680 x 1024 |
14.21s |
11.21s |
26.8% |
|
default(bf16) |
576 x 768 |
8.81s |
7.27s |
21.2% |
|
fp8_e4m3_fast |
1024 x 1024 |
15.16s |
11.15s |
36.0% |
|
fp8_e4m3_fast |
1280 x 720 |
13.66s |
9.97s |
37.0% |
|
fp8_e4m3_fast |
680 x 1024 |
9.93s |
7.51s |
32.2% |
|
fp8_e4m3_fast |
576 x 768 |
6.07s |
4.88s |
24.4% |
前提条件
-
以下の要件を満たす GPU インスタンスが作成されていること:
-
オペレーティングシステムは Ubuntu 20.04 または Ubuntu 22.04 である必要があります。
-
NVIDIA ドライバーと CUDA がインストールされており、バージョン要件を満たしていること。
説明GPU インスタンスを作成する際に、イメージを選択した後、[GPU ドライバーのインストール] オプションを選択することを推奨します。その後、CUDA、ドライバー、cuDNN に必要なバージョンを選択します。
-
インスタンスに固定のパブリック IP アドレスがあるか、Elastic IP アドレス (EIP) が関連付けられていること。パブリックネットワークアクセスを有効にする方法については、「パブリックネットワークアクセスの有効化」をご参照ください。
-
-
セキュリティグループルールが設定されていること。
リモート接続に必要なポート 22 は、セキュリティグループを作成する際にデフォルトで開いています。ComfyUI サーバーは、Web UI にアクセスするために 7860 などの特定のポートを必要とします。ポート 22 と 7860 のインバウンドルールがセキュリティグループに追加されていることを確認してください。開いていない場合は、手動でセキュリティグループルールを設定してください。
ComfyUI と DeepGPU のインストール
ComfyUI はオープンソースプロジェクトです。DeepGPU 推論アクセラレーションコンポーネントをインストールする前に、ComfyUI をインストールする必要があります。ComfyUI における DeepGPU ノードとワークフローについては、「ノードとワークフローの概要」をご参照ください。
-
ComfyUI をセットアップします。
説明ComfyUI の関連ノードとワークフローの概要については、「ノードとワークフローの概要」をご参照ください。
ComfyUI でネイティブの LoRA モデルをロードし (LoraLoaderModelOnly ノードを使用)、deepgpu-torch で高速化する場合は、ComfyUI のソースコードを 1 行修正する必要があります。
-
ComfyUI/comfy/sd.py ファイルで、次のコード行にパラメーター
weight_inplace_update=Trueを追加します。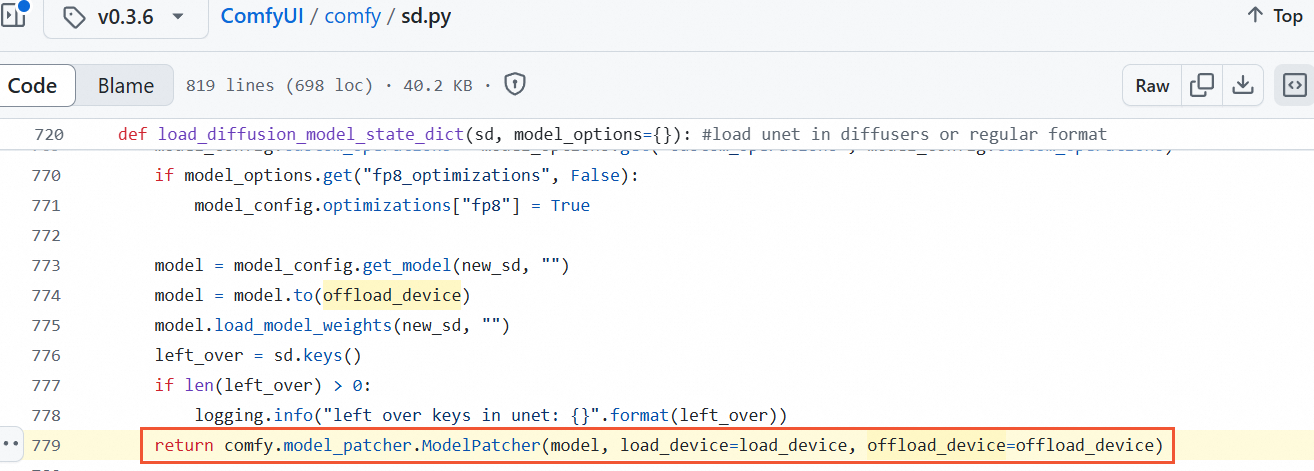
修正後のコードは次のようになります:
return comfy.model_patcher.ModelPatcher(model, load_device=load_device, offload_device=offload_device, weight_inplace_update=True) -
ComfyUI/comfy/sd.py ファイルで、次のコード行にパラメーター
weight_inplace_update=Trueを追加します。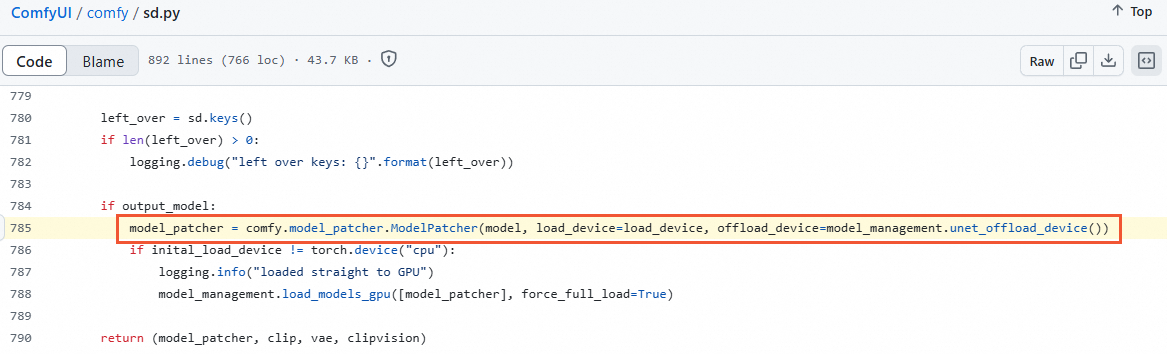
修正後のコードは次のようになります:
model_patcher = comfy.model_patcher.ModelPatcher(model, load_device=load_device, offload_device=model_management.unet_offload_device(), weight_inplace_update=True)
-
-
DeepGPU 推論アクセラレーションコンポーネントをインストールします。
-
Python のバージョンを確認し、deepgpu-torch アクセラレーションコンポーネントの依存関係要件を満たしていることを確認します。
deepgpu-torch アクセラレーションコンポーネントには Python 3.10 が必要です。
Ubuntu 22.04
python3 -Vを実行して Python のバージョンを確認します。次の図に示すように、Ubuntu 22.04 にはデフォルトで Python 3.10.12 が付属しており、依存関係の要件を満たしています。
Ubuntu 20.04
python3 -Vを実行して Python のバージョンを確認します。次の図に示すように、Ubuntu 20.04 にはデフォルトで Python 3.8.10 が付属しており、依存関係の要件を満たしていません。
Miniconda をインストールして独立した Python 3.10 環境を作成するか、別の方法を使用できます。
-
次のコマンドを実行して、Miniconda のインストールスクリプトをダウンロードします。
wget https://repo.anaconda.com/miniconda/Miniconda3-py310_24.1.2-0-Linux-x86_64.sh -
次のコマンドを実行して Miniconda をインストールし、環境をアクティベートします。
bash ./Miniconda3-py310_24.1.2-0-Linux-x86_64.sh -b -p /workspace/miniconda source /workspace/miniconda/bin/activate -
再度
python3 -Vを実行して Python のバージョンを確認します。 説明
説明ログインするたびに
source /workspace/miniconda/bin/activateを実行して、仮想 Python 3.10 環境をアクティベートしてください。
-
-
次のコマンドを実行して torch をインストールします。
deepgpu-torch アクセラレーションコンポーネントには torch 2.5.x+cu124 が必要です。この例では torch 2.5.0 をインストールします。別のバージョンをインストールする場合は、バージョン番号を適宜置き換えてください。
pip install torch==2.5.0python3 -c "import torch; print(torch.__version__)"を実行して、torch 2.5.0+cu124 がインストールされていることを確認します。
-
次のコマンドを実行して deepgpu-torch をインストールします。
apt-get install which curl iputils-ping -y pip install deepgpu-torch==0.0.15+torch2.5.0cu124 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/deepytorch/index.htmlpip list | grep deepgpu-torchを実行して、インストールされている deepgpu-torch のバージョンを確認します。
-
次のコマンドを実行して、DeepGPU 推論アクセラレーションコンポーネント用の ComfyUI プラグインをダウンロードしてインストールします。
DeepGPU 推論アクセラレーションコンポーネントのプラグインをダウンロードし、
ComfyUI/custom_nodes/ディレクトリに展開します。cd ComfyUI/custom_nodes/ wget https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/flux/20250102/ComfyUI-deepgpu.tar.gz tar zxf ComfyUI-deepgpu.tar.gz cd ../.. pip install deepgpu-comfyui==1.0.8 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/index.htmlpip list | grep deepgpu-comfyuiを実行して、DeepGPU 推論アクセラレーションコンポーネントのプラグインがインストールされていることを確認します。
Text-to-Image 推論の高速化
この例では、ComfyUI と DeepGPU を使用して、FLUX モデルの Text-to-Image 推論の高速化をテストする方法を示します。セットアップには、DeepGPU がインストールされた Ubuntu 22.04 を実行する gn8is インスタンスを使用します。
-
torch、ComfyUI の依存関係、DeepGPU アクセラレーションコンポーネントを含む基本環境をインストールします。
-
python3 -Vコマンドを実行して、Python のバージョンが 3.10 であることを確認します。Ubuntu 22.04 にはデフォルトで Python 3.10.12 が付属しており、deepgpu-torch アクセラレーションコンポーネントの依存関係要件を満たしています。Ubuntu 20.04 の GPU インスタンスを使用している場合は、独立した Python 3.10 環境を作成する必要があります。詳細については、「Ubuntu 20.04」をご参照ください。
-
次のコマンドを実行して torch をインストールします。
# この例では torch 2.5.0 をインストールします。別のバージョンをインストールする場合は、バージョン番号を適宜置き換えてください。 pip install torch==2.5.0 torchvision==0.20.0 torchaudio==2.5.0python3 -c "import torch; print(torch.__version__)"を実行して、インストールされている torch のバージョンを確認します。
-
次のコマンドを実行して ComfyUI の依存関係をインストールします。
pip install PyYAML safetensors numpy Pillow einops psutil transformers scipy torchsde aiohttp comfyui-frontend-package==1.11.8 kornia spandrel av -
次のコマンドを実行して DeepGPU アクセラレーションコンポーネントをインストールします。
apt-get install which curl iputils-ping -y pip install deepgpu-torch==0.0.15+torch2.5.0cu124 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/deepytorch/index.html pip install deepgpu-comfyui==1.0.8 -f https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/index.htmlpip list | grep deepgpu-torchまたはpip list | grep deepgpu-comfyuiを実行して、インストールされている DeepGPU アクセラレーションコンポーネントのバージョンを確認します。
-
次のコマンドを実行して ComfyUI のソースコードをダウンロードします。
この例では、公式の ComfyUI ソースコードを使用します。独自のカスタマイズされたバージョンの ComfyUI コードを使用することもできます。
Ubuntu 22.04
git clone -b v0.3.26 https://github.com/comfyanonymous/ComfyUI sed -i "s|comfy.model_patcher.ModelPatcher(model, load_device=load_device, offload_device=model_management.unet_offload_device())|comfy.model_patcher.ModelPatcher(model, load_device=load_device, offload_device=model_management.unet_offload_device(), weight_inplace_update=True)|g" ComfyUI/comfy/sd.pyUbuntu 20.04
apt install git git clone -b v0.3.26 https://github.com/comfyanonymous/ComfyUI sed -i "s|comfy.model_patcher.ModelPatcher(model, load_device=load_device, offload_device=model_management.unet_offload_device())|comfy.model_patcher.ModelPatcher(model, load_device=load_device, offload_device=model_management.unet_offload_device(), weight_inplace_update=True)|g" ComfyUI/comfy/sd.py -
次のコマンドを実行して、DeepGPU 推論アクセラレーションコンポーネントのプラグインをダウンロードします。
cd ComfyUI/custom_nodes/ wget https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/flux/20250102/ComfyUI-deepgpu.tar.gz tar zxf ComfyUI-deepgpu.tar.gz ls cd ../.. -
次のコマンドを実行して FLUX モデルをダウンロードします。
この例では、公式の FLUX モデルを使用します。独自にトレーニングしたモデルを使用することもできます。
cd ComfyUI wget -P models/unet https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/flux/models/flux1-dev.safetensors wget -P models/clip https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/flux/models/t5xxl_fp16.safetensors wget -P models/clip https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/flux/models/clip_l.safetensors wget -P models/vae https://aiacc-inference-public-v2.oss-cn-hangzhou.aliyuncs.com/deepgpu/comfyui/flux/models/ae.safetensors説明モデルのダウンロードには時間がかかる場合があります。
-
次のコマンドを実行して ComfyUI サービスを開始します。
python3 main.py --listen 0.0.0.0 --port 7860 -
http://IP:7860にアクセスして ComfyUI サービスにアクセスします。IPをご利用の GPU インスタンスのパブリック IP アドレスに置き換えてください。 -
ComfyUI インターフェイスで、 を選択し、サンプルワークフローで提供されている JSON ファイルを選択してから、[プロンプトをキューに追加] をクリックします。
重要DeepGPU アクセラレーションを使用するワークフローと使用しないワークフローを切り替える際には、ComfyUI サービスを再起動する必要があります。
-
DeepGPU アクセラレーションなし:基本の flux-dev JSON ファイル (workflow_flux.json) を選択します。次の図は、ワークフローの実行を示しています。
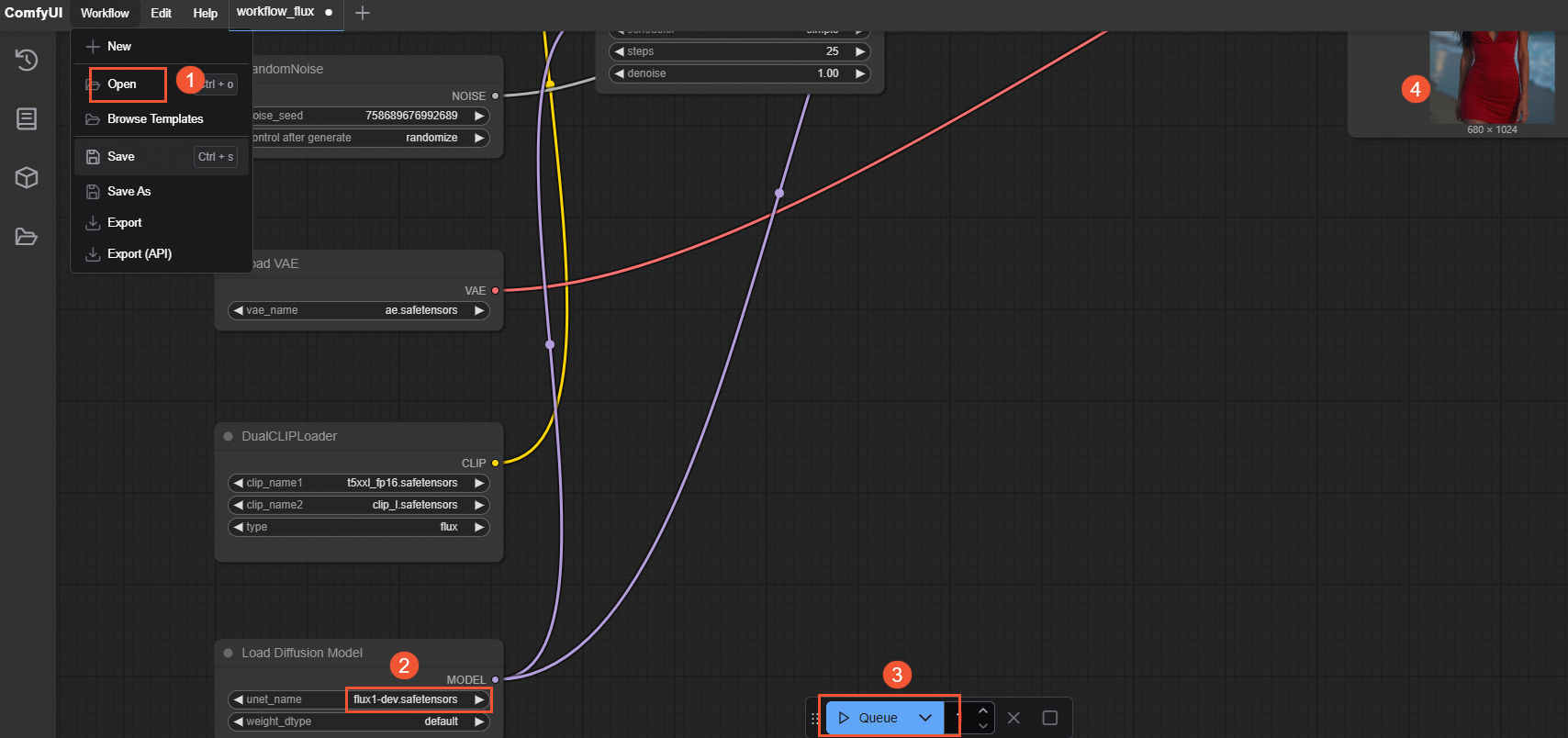
-
DeepGPU アクセラレーションあり:高速化された flux-dev DeepyTorch JSON ファイル (workflow_flux_deepytorch.json) を選択します。次の図は、ワークフローの実行を示しています。
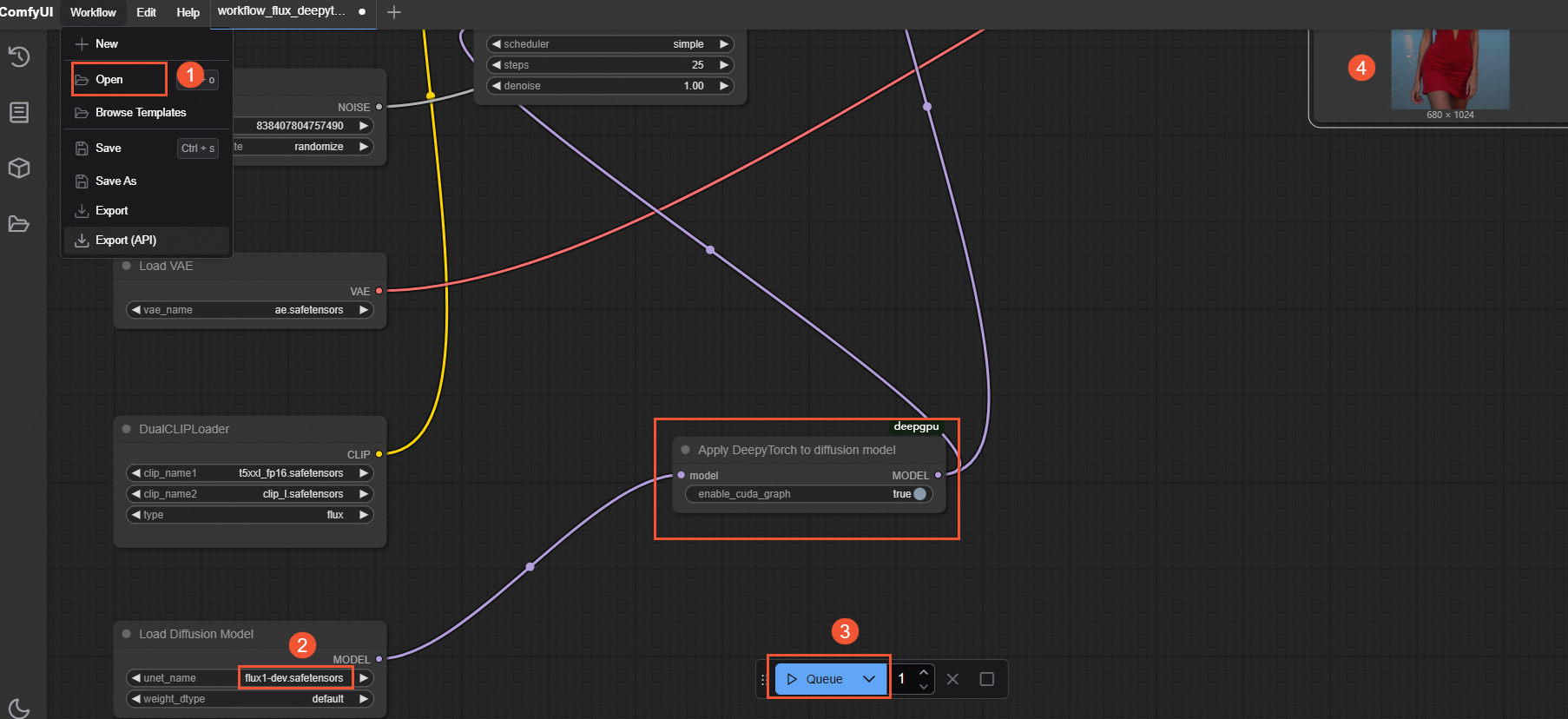
プロセスが完了したら、ComfyUI を開始したターミナルで Text-to-Image の実行時間を確認します。これは、次の図に示すように、
Prompt executed inの後に表示される時間です。ComfyUI と DeepGPU の構成を使用した場合、実行時間は標準のセットアップと比較して大幅に短縮されます。パフォーマンスの詳細については、「パフォーマンスの比較」をご参照ください。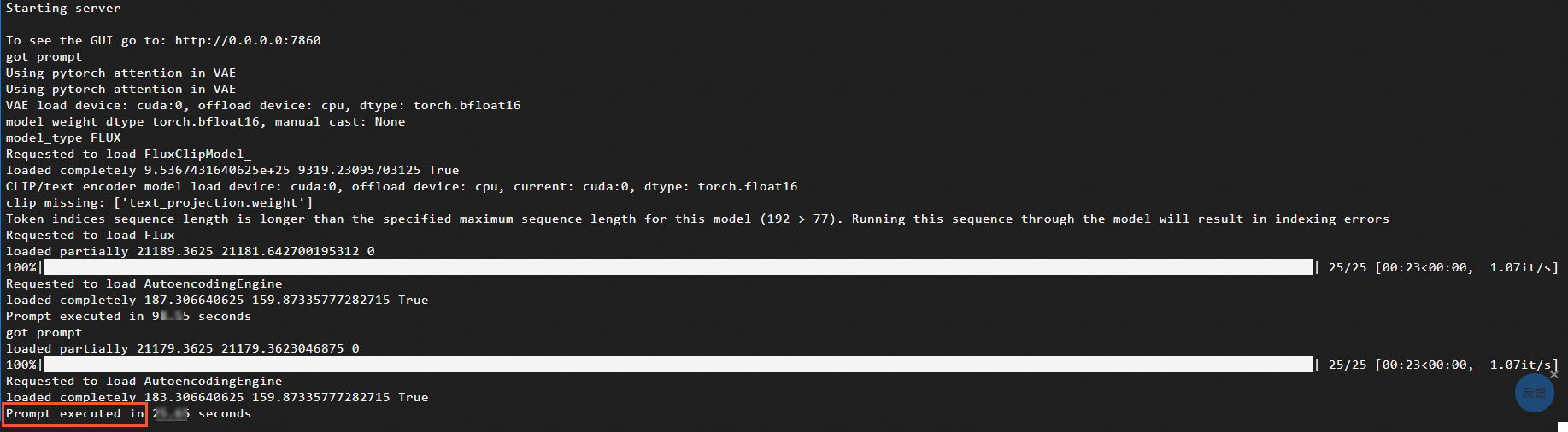
-
ノードとワークフローの概要
DeepGPU ノードの種類
DeepGPU 推論アクセラレーションコンポーネントのプラグインには、いくつかの DeepGPU 固有のノードが含まれています。ComfyUI インターフェイスで、空白の領域を右クリックし、 を選択すると、利用可能な DeepGPU ノードの種類が表示されます。
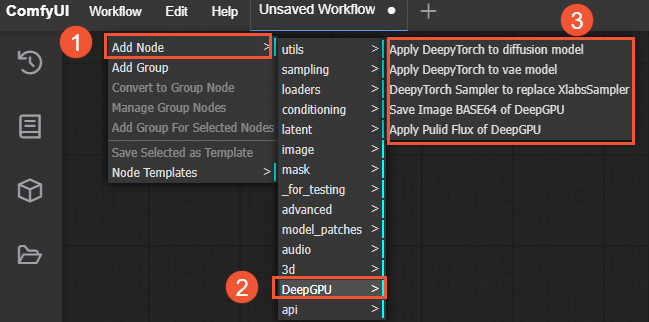
ComfyUI/custom_nodes/ComfyUI-deepgpu ディレクトリに移動し、__init__.py ファイルを開くと、対応するノードの種類が表示されます。
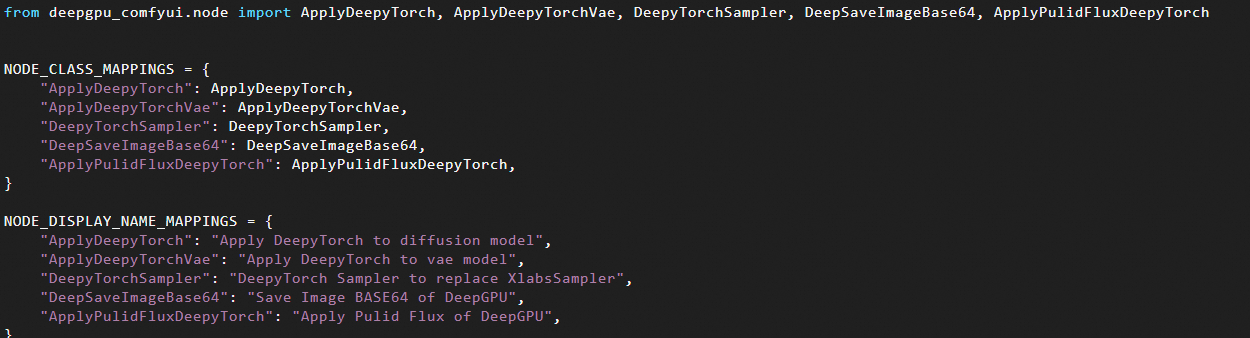
主なノードの種類は以下のとおりです:
-
ApplyDeepyTorch ノード:FLUX モデルの場合、ApplyDeepyTorch ノードは他のノードに依存します。Load Diffusion Model、Load Flux LoRA、または Apply Flux IPAdapter ノードの後に挿入する必要があります。他のモデルの場合、このノードは Load Checkpoint または LoraLoaderModelOnly ノードの後に挿入する必要があります。
-
DeepyTorchSampler ノード:FLUX モデルの場合、このノードは新しいサンプラーであり、XLabsSampler ノード (x-flux-comfyui より) よりも優れたパフォーマンスを提供します。このノードを使用する場合、ApplyDeepyTorch ノードを追加する必要はありません。
-
ApplyPulidFluxDeepyTorch ノード:FLUX モデルの場合、このノードは ApplyPulidFlux ノード (ComfyUI-PuLID-Flux-Enhanced より) よりもパフォーマンスが優れており、それを置き換えます。このノードを使用する場合、ApplyDeepyTorch ノードを追加する必要はありません。
ワークフローの例
このセクションでは、FLUX および SD モデルの推論を高速化するためのワークフローの例を示します。
FLUX.1 モデル
-
基本の
flux-devモデルの場合ComfyUI インターフェイスで、次の図に示すように、
Load Diffusion Modelノードの後にApplyDeepyTorchノードを挿入します: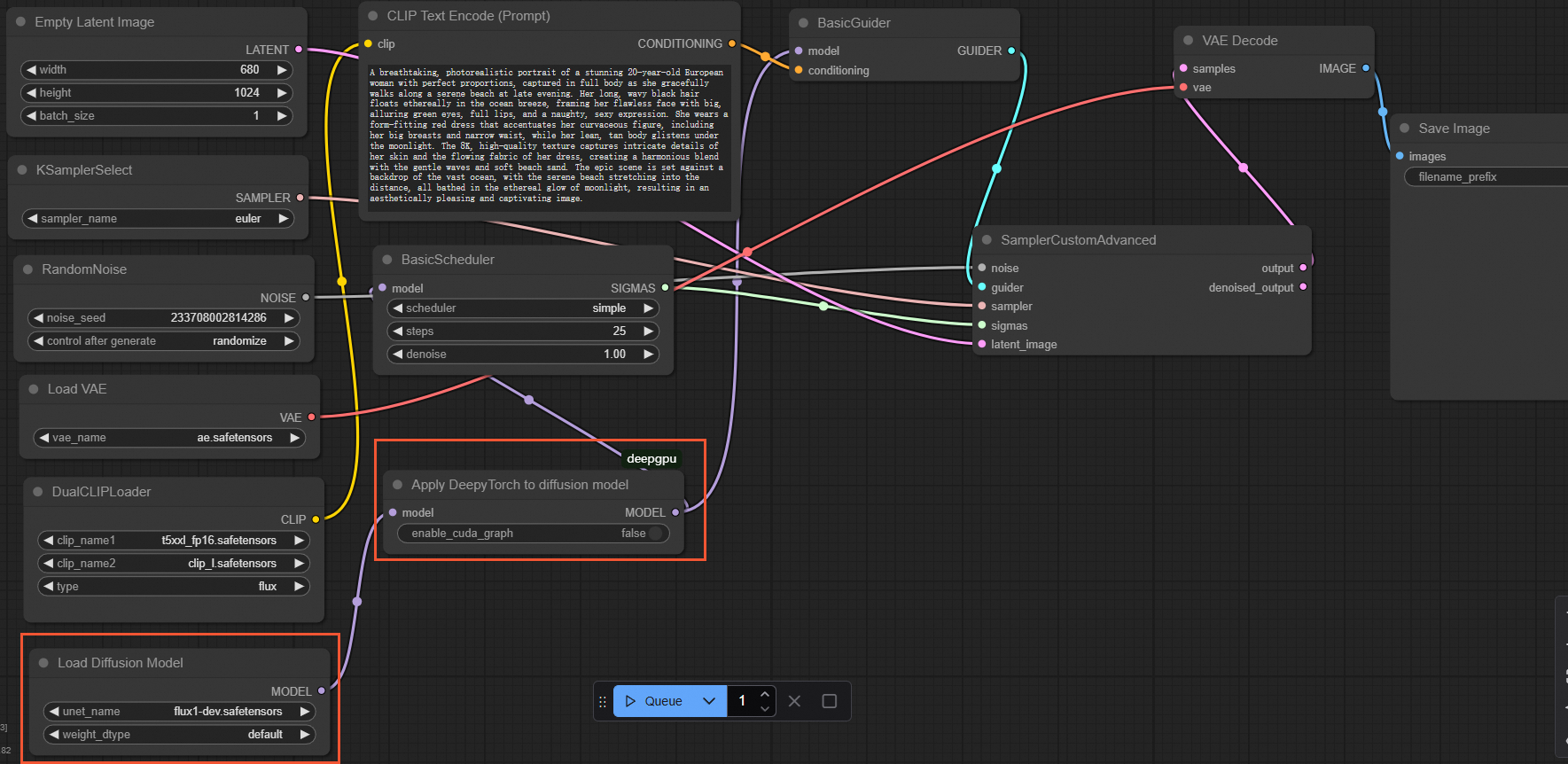
ワークフローファイルの例:
-
基本の flux-dev バージョン:workflow_flux.json
-
高速化された flux-dev DeepyTorch バージョン:workflow_flux_deepytorch.json
-
-
ネイティブの ComfyUI LoRA モデルの場合
説明DeepGPU は、FLUX.1-dev モデルに対して XLabs とネイティブの ComfyUI LoRA の両方の実装をサポートしています。
ComfyUI インターフェイスで、次の図に示すように、最後の
LoraLoaderModelOnlyノードの後にApplyDeepyTorchノードを挿入します: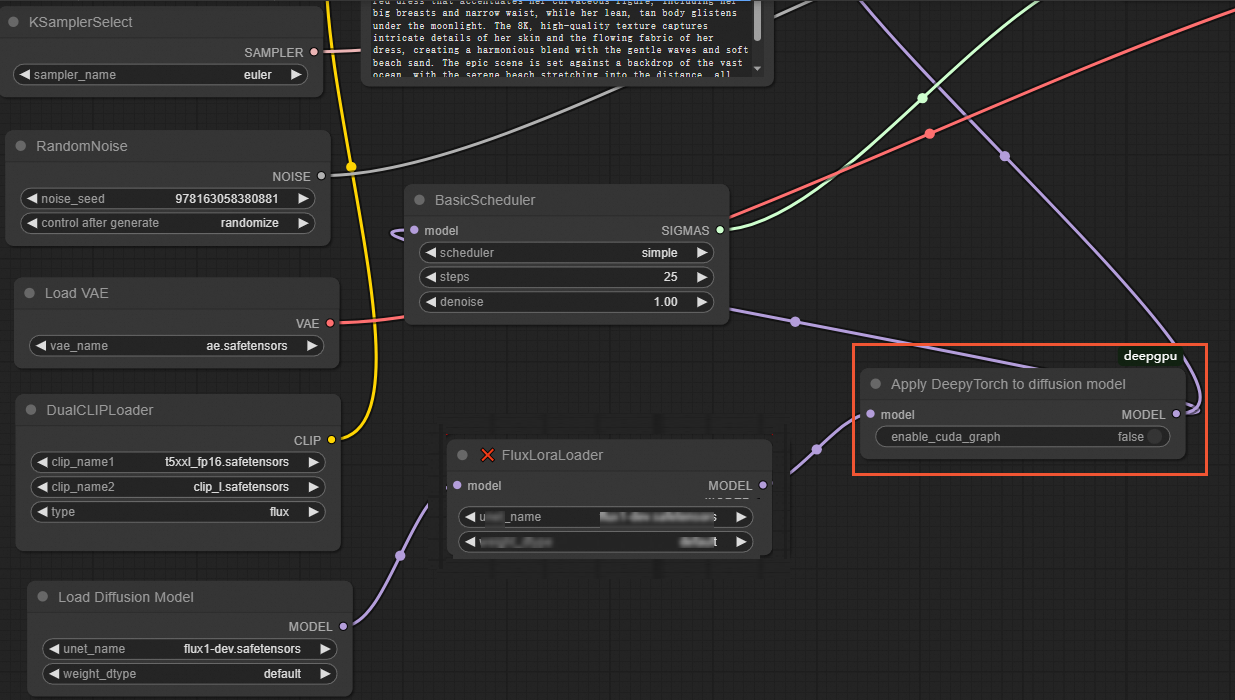
ワークフローファイルの例:
-
オリジナルの flux-dev+lora バージョン:workflow_flux_lora_wukong.json
-
高速化された flux-dev+lora DeepyTorch バージョン:workflow_flux_lora_deepytorch_wukong.json
-
-
Pulid プラグインを使用した FLUX モデルの場合
説明Pulid プラグインは ComfyUI-PuLID-Flux-Enhanced からのものです。
ComfyUI インターフェイスで、
Apply Pulid FluxノードをApplyPulidFluxDeepyTorchノードに置き換えます。ApplyDeepyTorchノードは必要ありません。ワークフローは次の図のようになります: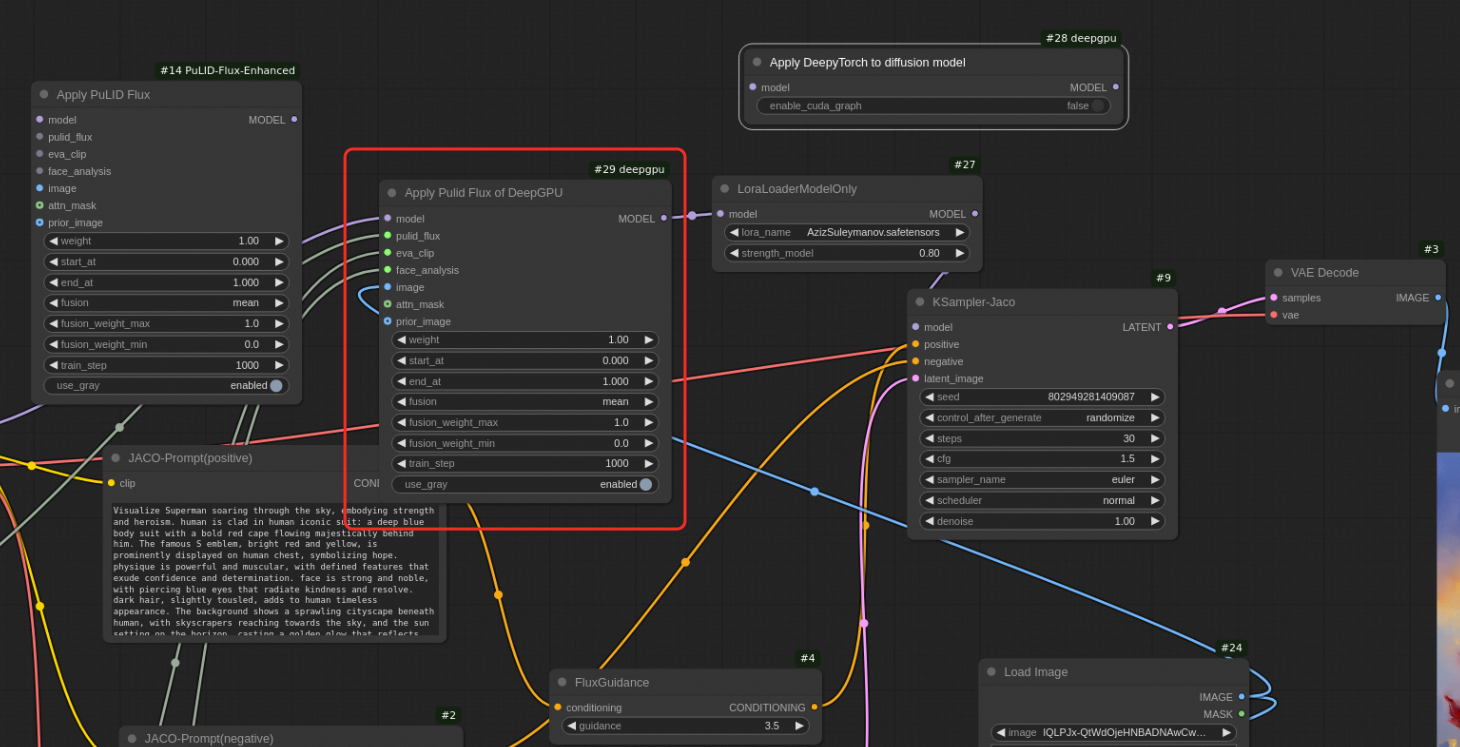
-
カスタム FLUX LoRA モデルの場合
ComfyUI サービスを開始する前に、ComfyUI インターフェイスでワークフローを実行するために、次の環境変数を設定する必要があります。
export DEEPGPU_ENABLE_FLUX_LORA=trueComfyUI インターフェイスで、次の図に示すように、最後の
Load Flux LoRAノードの後にApplyDeepyTorchノードを挿入します: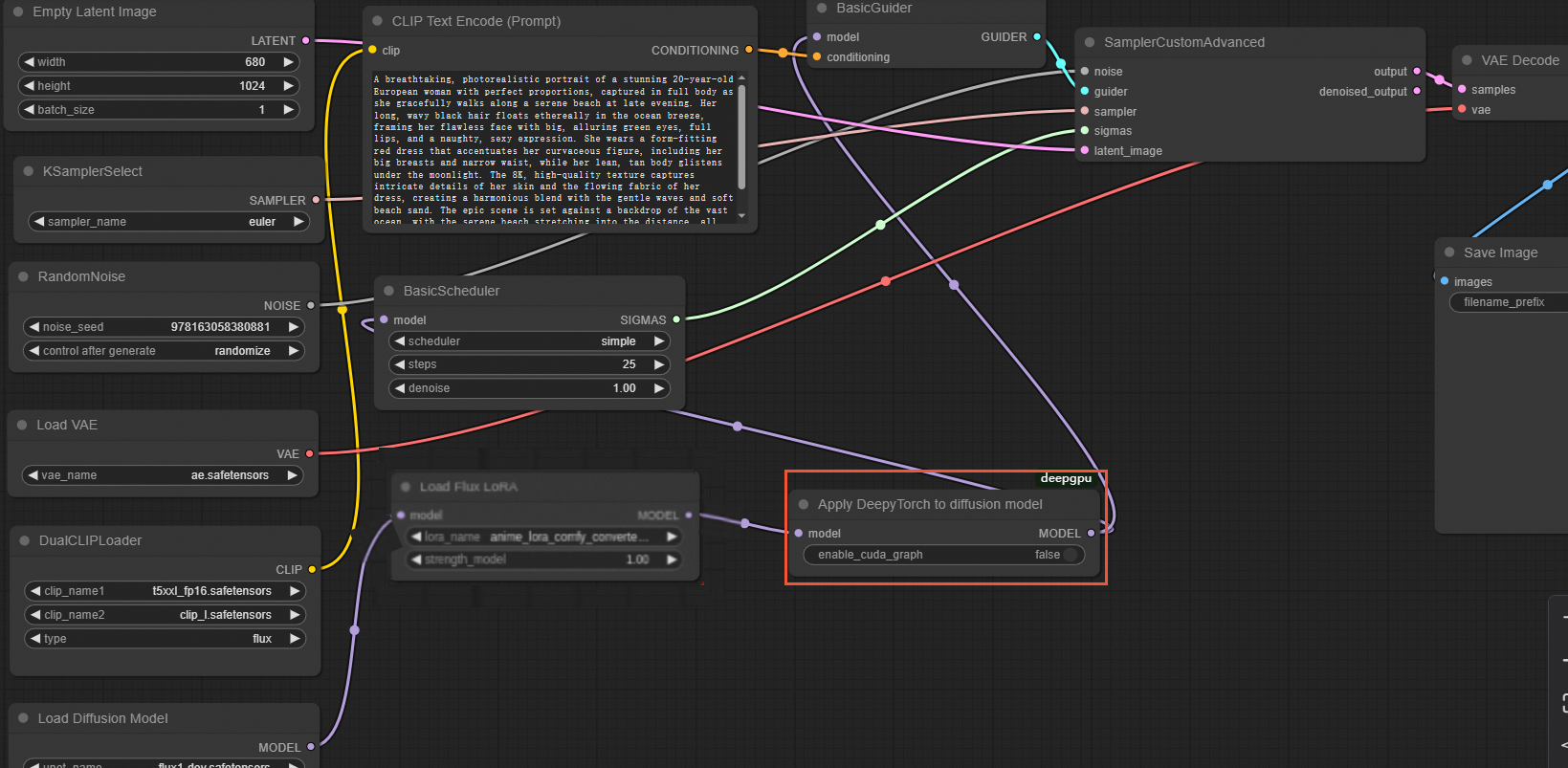
ワークフローファイルの例:
-
オリジナルの flux-dev+lora バージョン:workflow_flux_lora.json
-
高速化された flux-dev+lora DeepyTorch バージョン:workflow_flux_lora_deepytorch.json
-
-
カスタム FLUX IP-Adapter の場合
ComfyUI サービスを開始する前に、ComfyUI インターフェイスでワークフローを実行するために、次の環境変数を設定する必要があります。
export DEEPGPU_ENABLE_FLUX_LORA=trueComfyUI インターフェイスで、
Apply Flux IPAdapterノードの後にApplyDeepyTorchノードを挿入し、XLabsSamplerノードをDeepyTorch Samplerノードに置き換えます。次の図のようになります:説明このシナリオの入力として使用されるテスト画像は XLabs-AI の画像です。
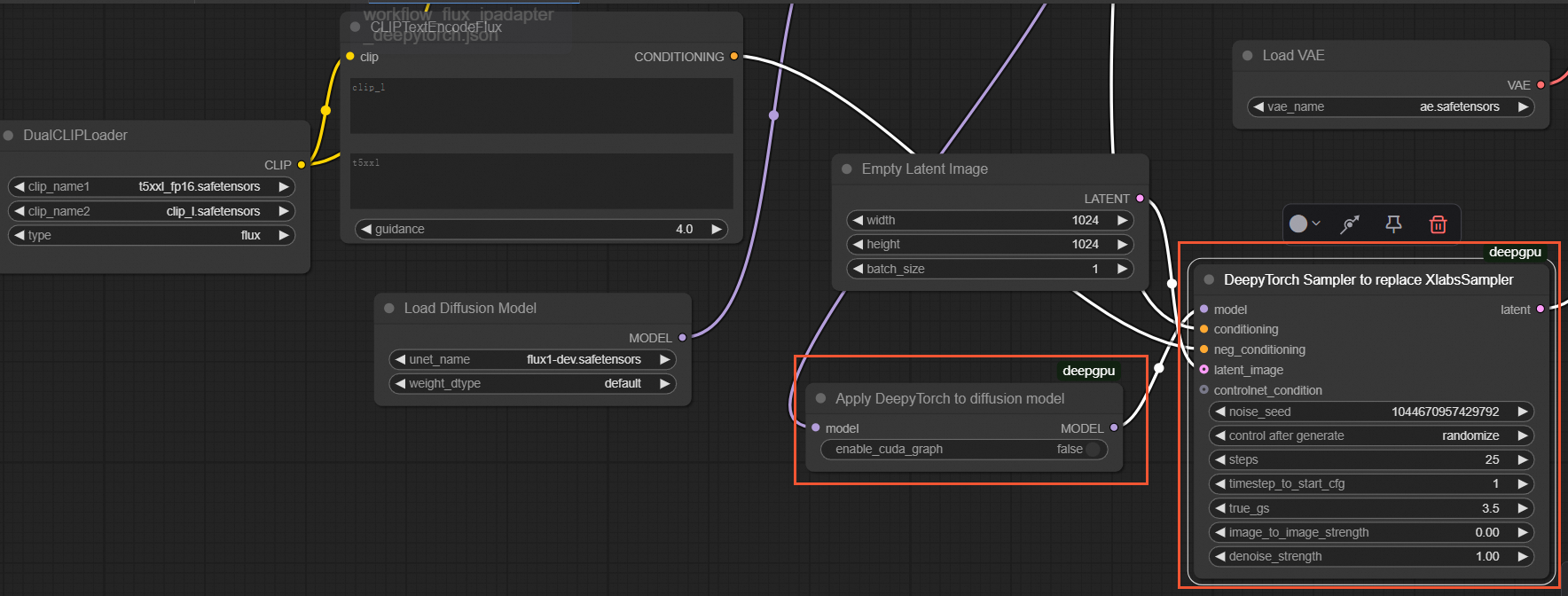
ワークフローファイルの例:
-
オリジナルの flux-dev+ip-adapter バージョン:workflow_flux_ipadapter.json
-
高速化された flux-dev+ip-adapter DeepyTorch バージョン:workflow_flux_ipadapter_deepytorch.json
-
-
カスタム FLUX ControlNet の場合
ComfyUI インターフェイスで、次の図に示すように、
XLabsSamplerノードをDeepyTorch Samplerノードに置き換えます:説明このシナリオの入力として使用されるテスト画像は XLabs-AI の画像です。
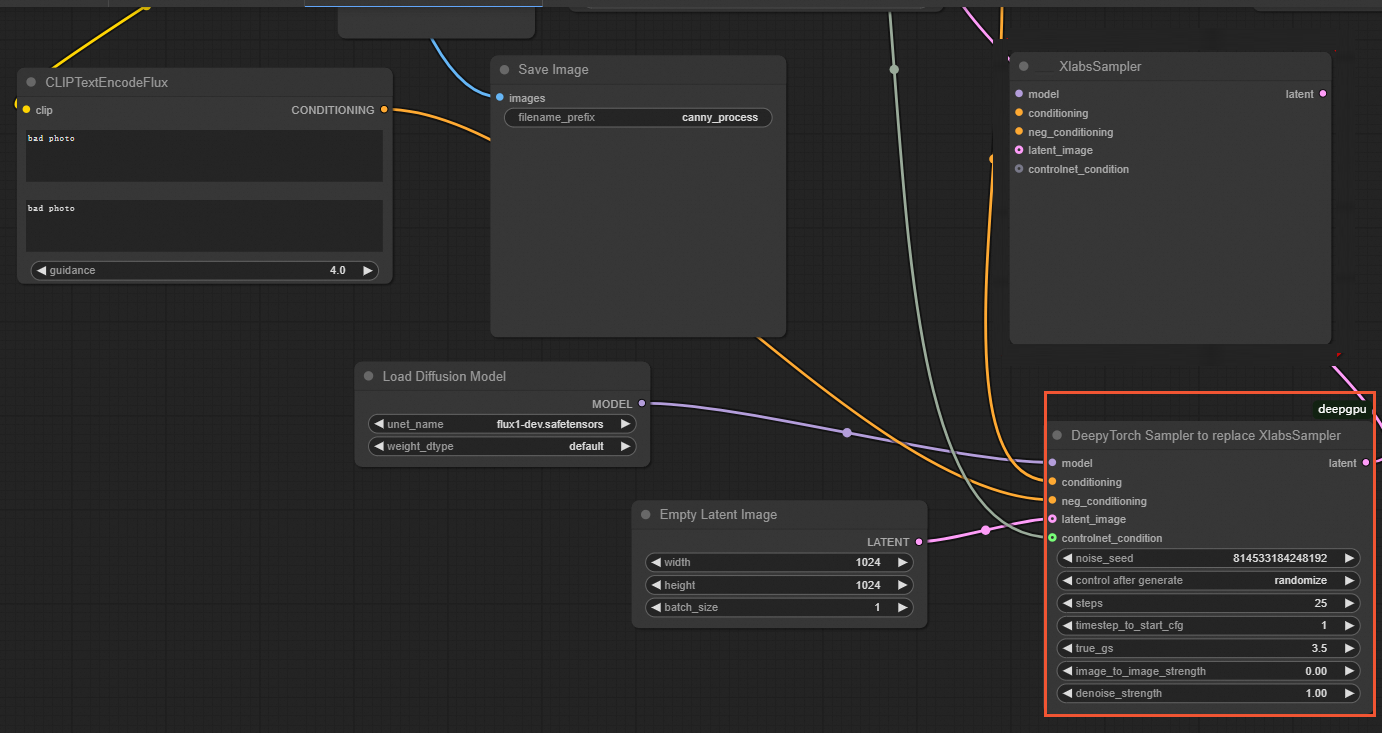
ワークフローファイルの例:
-
オリジナルの flux-dev+controlnet バージョン:workflow_flux_controlnet.json
-
高速化された flux-dev+controlnet DeepyTorch バージョン:workflow_flux_controlnet_deepytorch.json
-
SD 1.5 モデル
-
ネイティブの ComfyUI LoRA モデルの場合
説明DeepGPU は、FLUX.1-dev モデルに対して XLabs とネイティブの ComfyUI LoRA の両方の実装をサポートしています。
ComfyUI インターフェイスで、次の図に示すように、最後の
LoraLoaderModelOnlyノードの後にApplyDeepyTorchノードを挿入します:ワークフローファイルの例:
-
オリジナルの flux-dev+lora バージョン:workflow_flux_lora_wukong.json
-
高速化された flux-dev+lora DeepyTorch バージョン:workflow_flux_lora_deepytorch_wukong.json
-
-
カスタム SD ControlNet の場合
ComfyUI インターフェイスで、次の図に示すように、
Load Checkpointノードの後にApplyDeepyTorchノードを挿入します: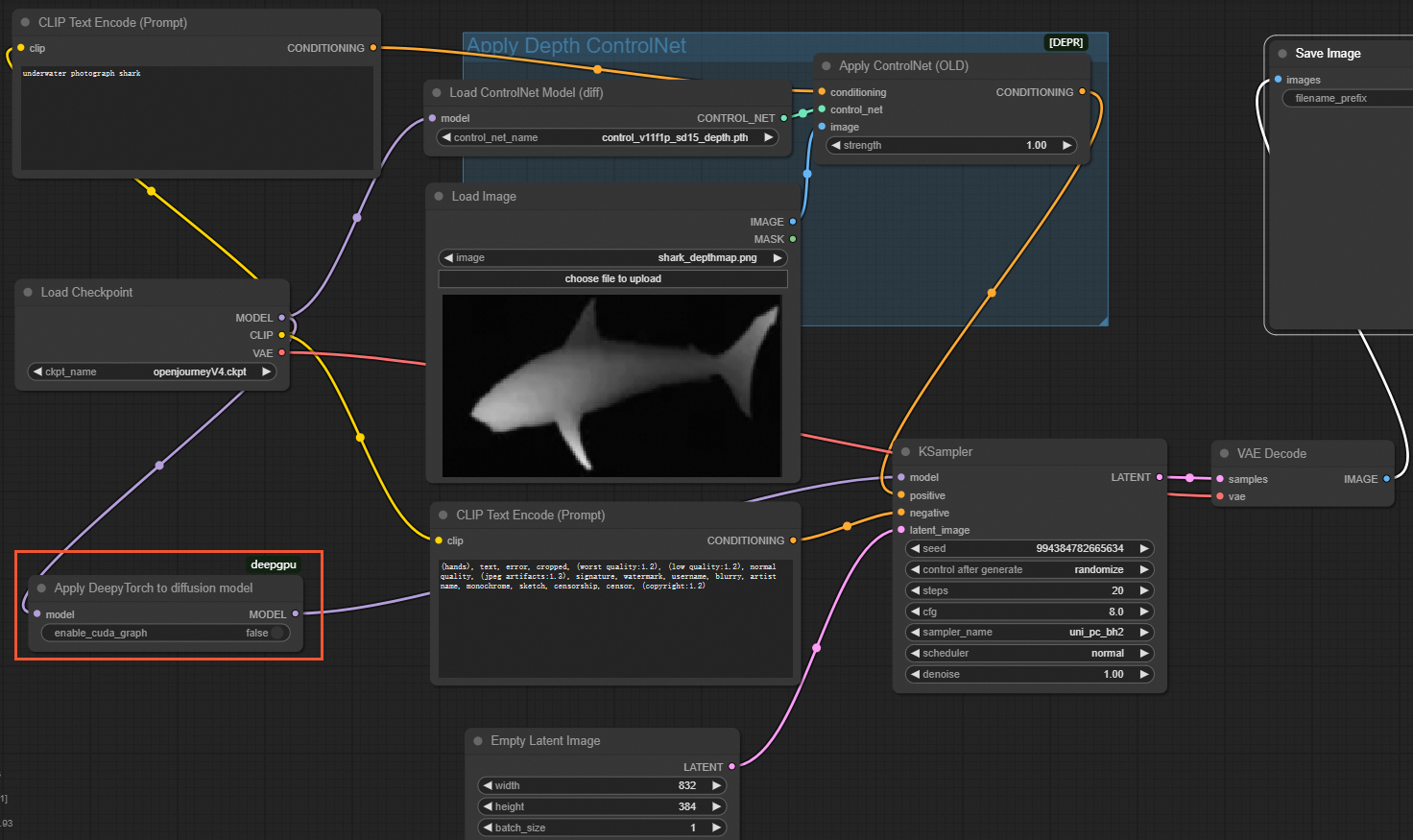
ワークフローファイルの例:
-
オリジナルの sd1.5+controlnet バージョン:workflow_sd1.5_controlnet.json
-
高速化された sd1.5+controlnet DeepyTorch バージョン:workflow_sd1.5_controlnet_deepytorch.json
-
SDXL モデル
SDXL モデルを高速化するには、次の図に示すように、BASE と REFINER の両方の Load Checkpoint ノードの後に ApplyDeepyTorch ノードを挿入します:
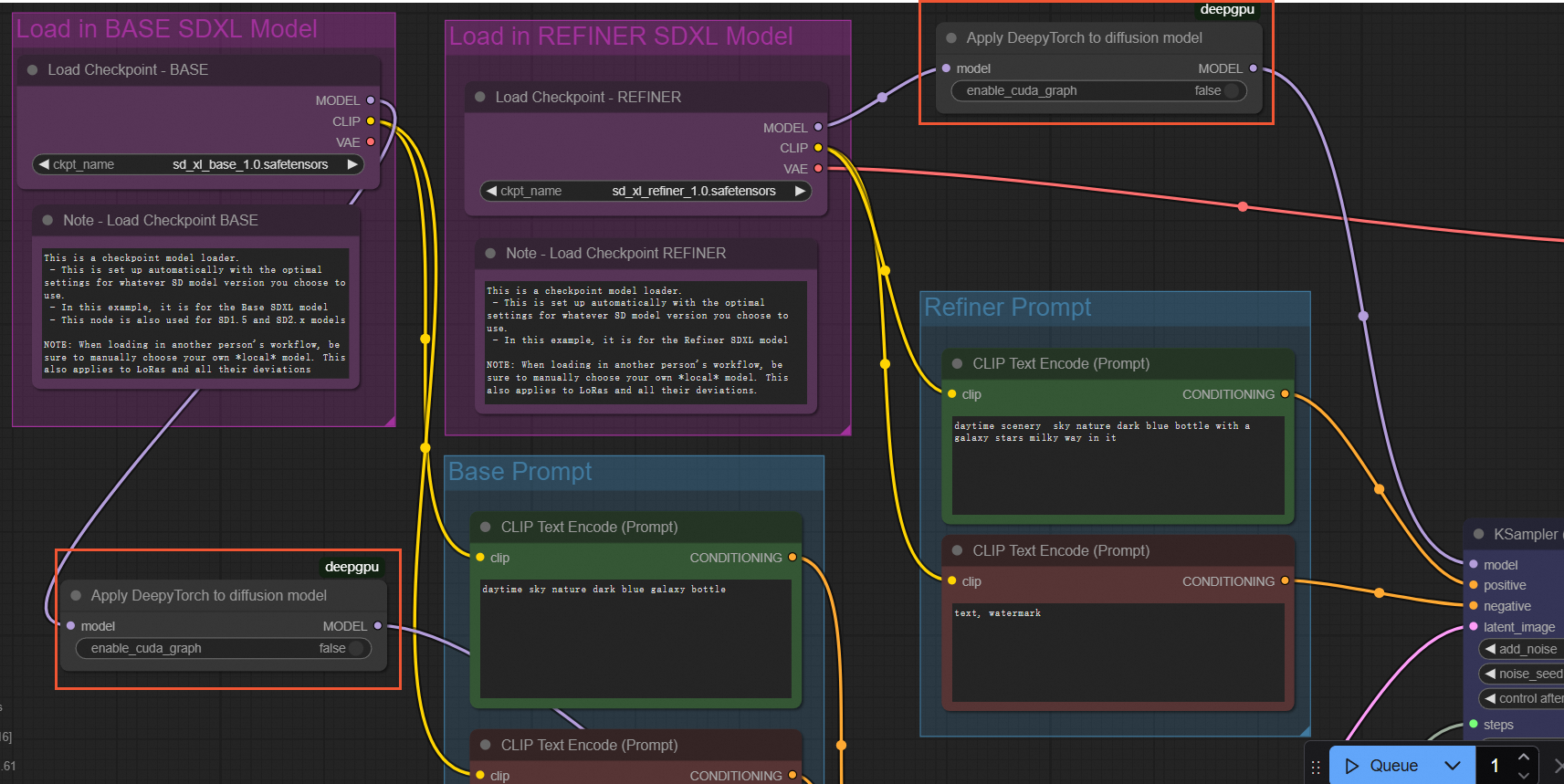
ワークフローファイルの例:
-
オリジナルの sdxl バージョン:workflow_sdxl_base_refiner.json
-
高速化された sdxl DeepyTorch バージョン:workflow_sdxl_base_refiner_deepytorch.json