このトピックでは、DTS RAGFlow を使用して AnalyticDB for PostgreSQL 向けの GraphRAG を構築する方法について説明します。このソリューションは、ナレッジベースから知識グラフを構築し、従来のベクターベースの検索の限界を超え、複雑な関係クエリに対する深い理解と正確な取得を可能にします。
この機能は現在、招待プレビュー段階です。アクセスが必要な場合は、チケットを送信してお問い合わせください。有効化いたします。
ビジネスシナリオ
金融のリスク管理レポート、複数プロダクトの技術マニュアル、企業の組織図など、複雑なエンティティ関係や深い論理構造を含むナレッジベースを扱う場合、ベクターの類似性のみに基づく従来の検索拡張生成 (RAG) ソリューションでは、「シナリオ C におけるプロダクト A とプロダクト B の長所と短所を比較せよ」や「プロジェクト X に関連するすべてのチームメンバーと彼らが担当するモジュールをリストアップせよ」といった、多段階の推論や関係性の発見を必要とするクエリに答えることが困難な場合があります。これらの質問は、表面的なテキストの類似性だけでなく、エンティティ間の内在的な接続を理解する必要があります。
GraphRAG は、知識グラフを導入することで、従来のベクター検索を強化します。非構造化テキストから隠れたエンティティと関係を明示的に抽出し、構造化します。これにより、システムはグラフ検索を通じて関連するサブグラフを特定し、大規模言語モデル (LLM) に、より豊富で論理的に一貫性のあるコンテキストを提供できます。これにより、複雑なマルチホップクエリに対する応答の品質が大幅に向上します。
ソリューションアーキテクチャ
このソリューションは、DTS RAGFlow のデータ処理能力と AnalyticDB for PostgreSQL のグラフ分析エンジンを組み合わせ、ドキュメントの取り込みから知識グラフの構築、インテリジェントな Q&A まで、エンドツーエンドのパイプラインを構築します。
ワークフロー:
データの取り込みと処理:非構造化ドキュメントを DTS RAGFlow ナレッジベースにアップロードします。
知識の抽出と保存:
RAGFlow はドキュメントを自動的に解析、チャンク化、埋め込みを行います。
GraphRAG が有効になっている場合、RAGFlow は知識抽出オペレーターを呼び出し、テキストから主語-述語-目的語 (S-P-O) のトライアドを抽出します。
埋め込まれたテキストチャンクと抽出された知識グラフデータ (エンティティとエッジ) の両方が、指定された AnalyticDB for PostgreSQL インスタンスに書き込まれ、一元的に保存されます。
ハイブリッド検索:
検索テストまたは API ベースのクエリ中に、システムはハイブリッド検索を実行します。
クエリはまずベクター検索を実行し、関連するテキストチャンクを見つけます。
同時に、クエリは AnalyticDB for PostgreSQL のグラフ分析エンジンでグラフ検索を実行し、関連するエンティティとその関連サブグラフを特定します。
コンテキストの拡充と生成:システムは、ベクター検索で取得したテキストチャンクとグラフ検索で取得したサブグラフの両方をコンテキストとして LLM に送信し、LLM はこの拡充された情報を使用して最終的な回答を生成します。
実装手順
ステップ 1:環境の準備
AnalyticDB for PostgreSQL インスタンスを作成します。
Milvus のバージョンは 7.3 以降である必要があります。
ステップ 2:ナレッジベースの設定と GraphRAG の有効化
このステップでは、DTS RAGFlow ナレッジベースを AnalyticDB for PostgreSQL インスタンスに関連付けます。
ターゲットリージョンの RAGFlow ナレッジベースのリストページに移動します。
左側のナビゲーションウィンドウで、データの準備 をクリックします。
ページの左上隅で、データ準備インスタンスが存在するリージョンを選択します。
[RAGFlow ナレッジベース] タブをクリックします。
RAGFlow にログインします。
対象の RAGFlow ナレッジベースの 操作 列で、[管理] をクリックします。
説明操作 列の [ナレッジベースにログイン] をクリックし、内部ネットワークまたはパブリックネットワーク経由でのログインを選択することもできます。
[エンドポイント] セクションで、[パブリックエンドポイントでログイン] または [内部エンドポイントでログイン] をクリックします。
説明パブリックネットワーク経由で RAGFlow ナレッジベースにアクセスするには、インスタンスのパブリックエンドポイントを有効にする必要があります。
ログインページで、アカウントのメールアドレスとパスワードを入力し、[ログイン] をクリックします。
RAGFlow ページで、ナレッジベースの管理やその他の操作を実行できます。
説明操作の詳細については、「公式 RAGFlow ドキュメント」をご参照ください。
[ナレッジベースの作成] をクリックします。作成ページで名前を入力し、[GraphRAG を有効にする] スイッチを切り替えます。
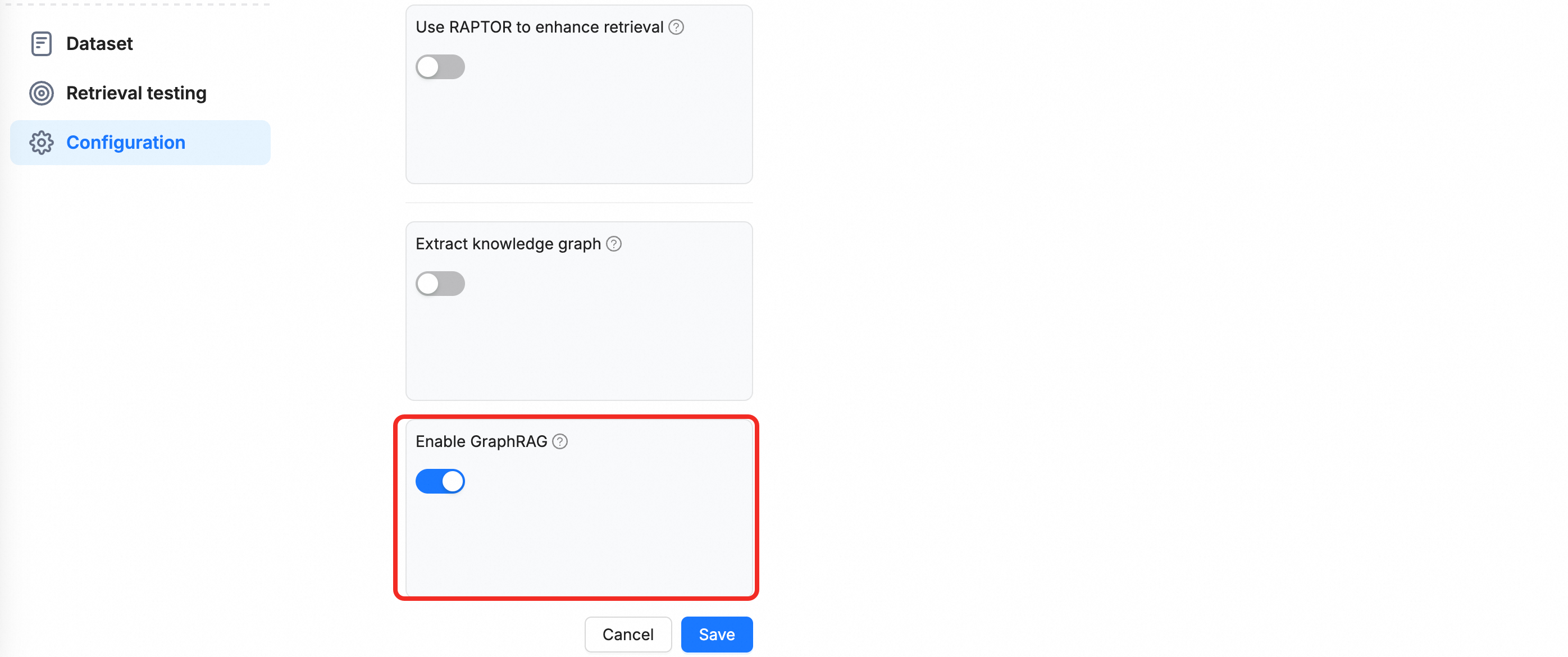 説明
説明ナレッジベースを作成する前に、[モデルプロバイダー] で埋め込みモデルと LLM を追加し、 で設定します。
DTS RAGFlow ナレッジベースで外部モデルと LLM を使用する場合は、ナレッジベースが配置されている VPC に NAT Gateway を設定して、アウトバウンドのインターネットアクセスを許可します。
インターネット NAT ゲートウェイの作成:NAT Gateway – インターネット NAT ゲートウェイの購入ページに移動します。作成中に、DTS RAGFlow ナレッジベースと同じ VPC と vSwitch を選択してください。
SNAT エントリの設定:[インターネット NAT ゲートウェイ] ページに移動します。対象ゲートウェイの [操作] 列で、[SNAT の設定] をクリックし、[SNAT エントリの作成] をクリックします。パラメーターを次のように設定します:
SNAT エントリの粒度: VPC。
[EIP の選択]:ドロップダウンリストからパブリックネットワークアクセスを提供する EIP を選択します。
ステップ 3:ドキュメントのアップロードと知識グラフの構築
新しく作成したナレッジベースで、[データセット] に移動し、[ファイルの追加] をクリックしてローカルファイルをアップロードします。
アップロードが完了すると、RAGFlow は自動的に解析、チャンク化、埋め込み、その他の処理ステップを実行します。GraphRAG が有効になっているため、システムは知識抽出も実行し、結果のエンティティとエッジを設定済みの AnalyticDB for PostgreSQL インスタンスに書き込み、知識グラフの構築が完了します。
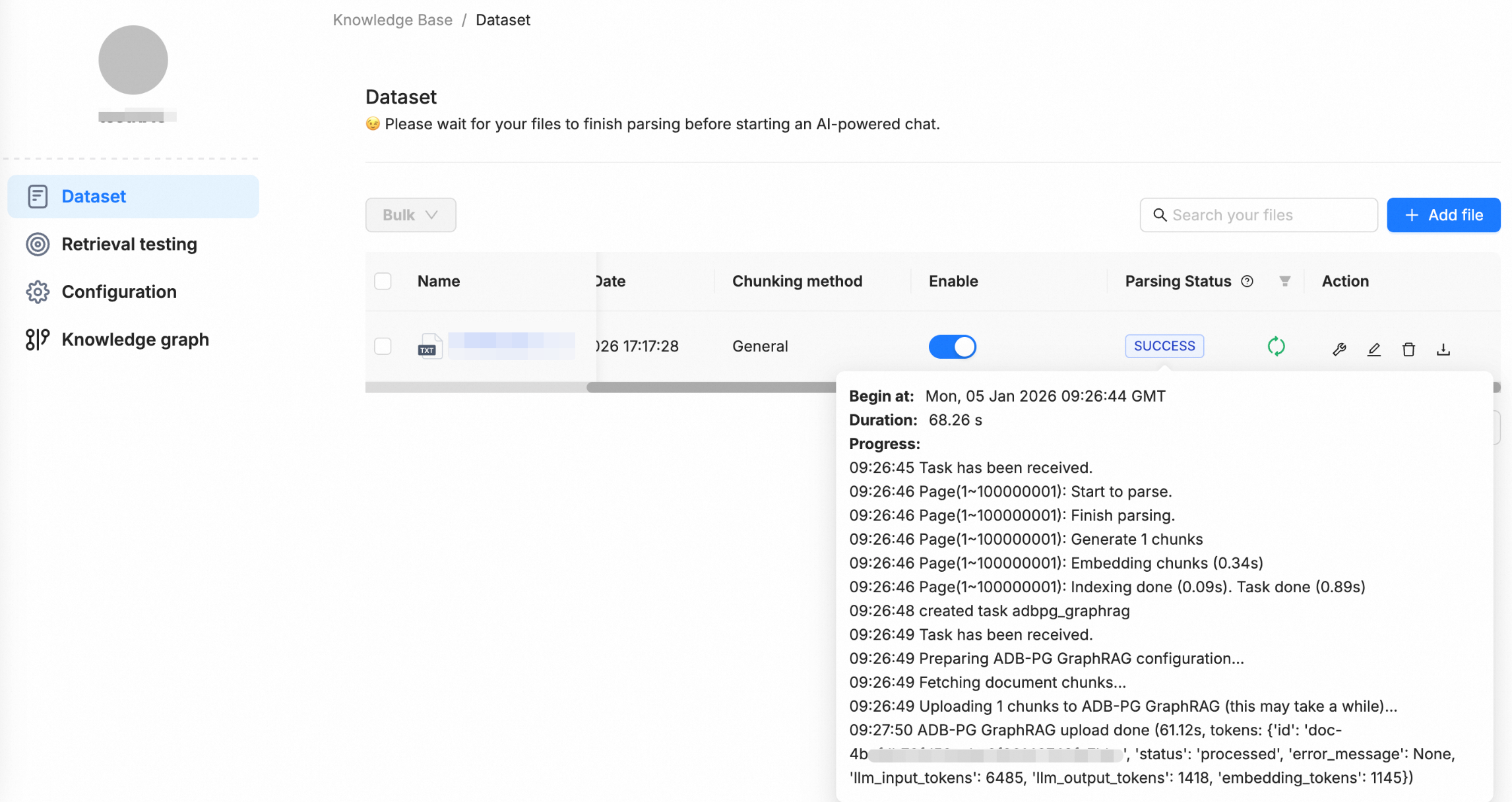
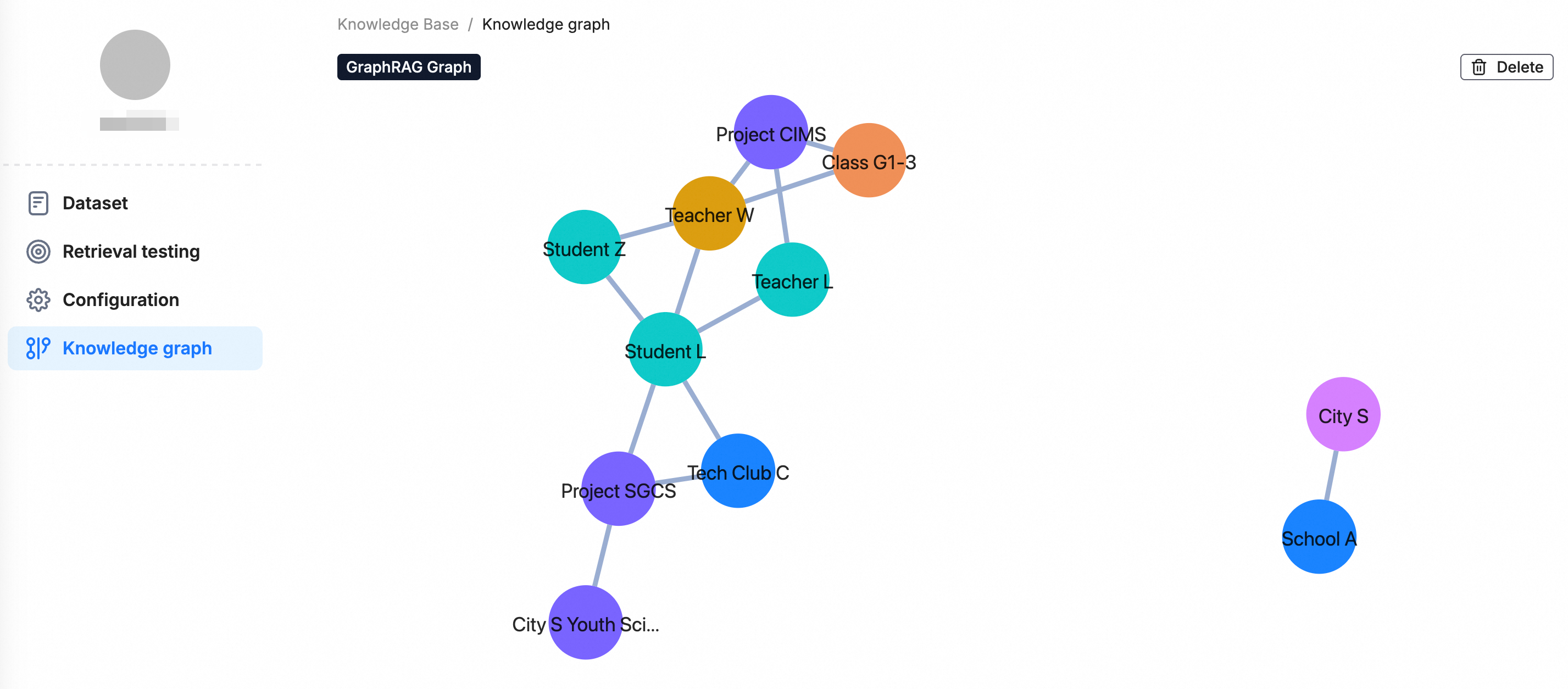
処理が完了すると、左側のナビゲーションウィンドウに [知識グラフ] コンポーネントが表示され、抽出されたエンティティと関係を視覚的に参照および検証できます。
ステップ 4:検索テスト
比較テストを実行して、さまざまなクエリタイプに対する GraphRAG の有効性を検証します。
ナレッジベースの [検索テスト] ページに移動します。
シナリオ 1:単純なクエリ
「RAG とは何か?」のような事実に基づいた単純なクエリの場合、システムは主にベクター検索に依存して、GraphRAG が有効であるかどうかに関係なく、最も関連性の高いテキストチャンクを返します。
シナリオ 2:複雑なクエリ
「RAG と GraphRAG の長所と短所を比較せよ」のように、エンティティ間の関係の理解を必要とする複雑なクエリの場合は、[Use GraphRAG] を選択します。
検索結果には、関連するテキストチャンクと構造化された関係サブグラフの両方が含まれます。このサブグラフは、クエリに関与するコアエンティティとその関係を明確にリストした Markdown テーブルとして表示され、LLM に構造化されたコンテキストを提供して、より論理的で洞察に満ちた回答を生成させます。
返されるサブグラフは次のフォーマットを使用します:
---- Entities ---- ,Entity,Description 0,entity1,description1 1,entity2,description2 ---- Relations ---- ,From Entity,To Entity,Description 0,source_entity1,target_entity1,description1 1,source_entity2,target_entity2,description2例:
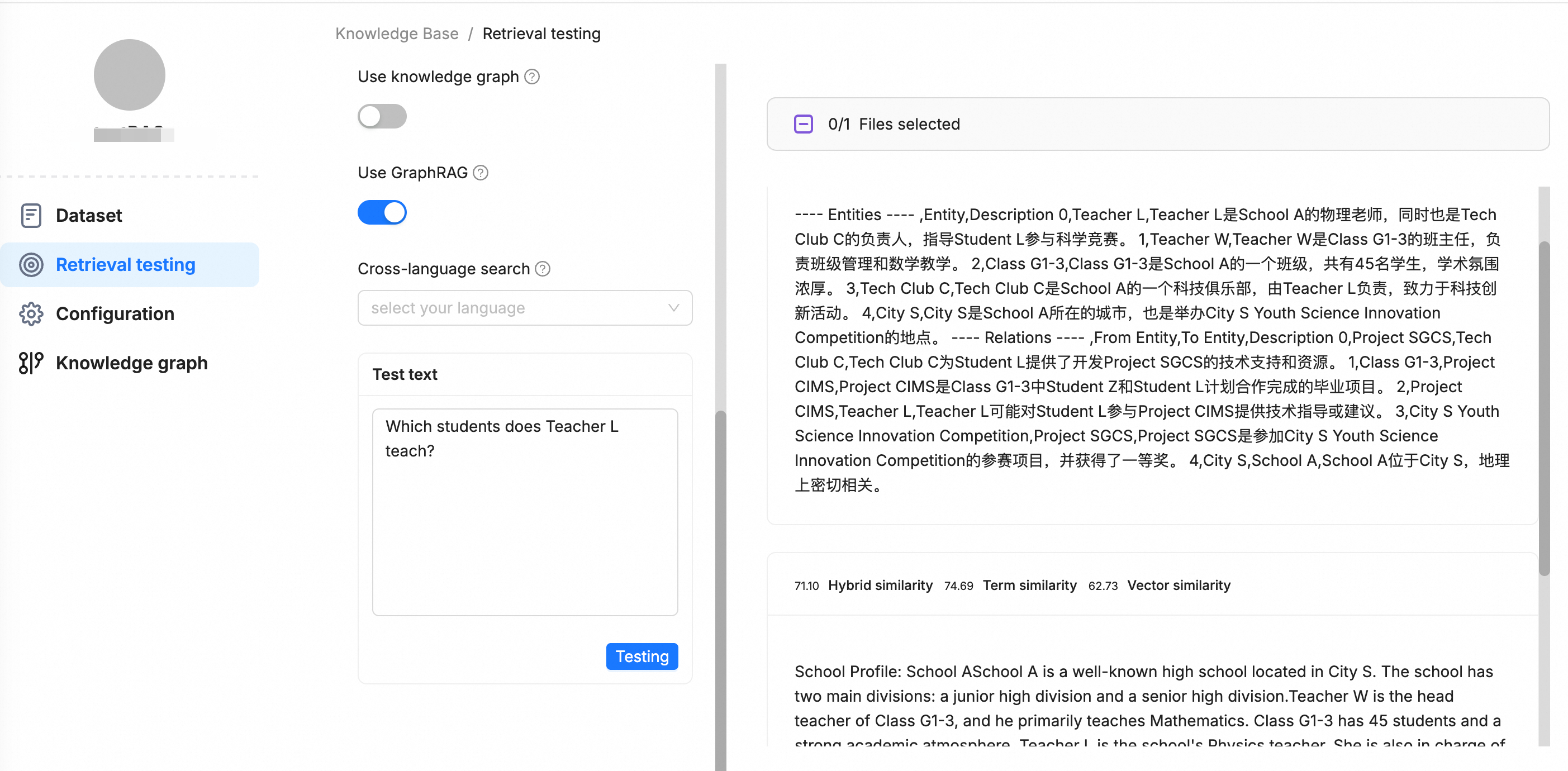
[Use GraphRAG] を選択しない場合、検索結果にはテキストチャンクのみが含まれます。構造化された関係データがないと、LLM は正確な回答を提供できない場合があります。