本トピックでは、Data Transmission Service (DTS) を使用して RAGFlow ナレッジベースを作成し、使用する方法について説明します。
適用範囲
ベクターデータベースを作成済みであること:
サポートされるベクターデータベース
適用範囲
AnalyticDB for PostgreSQL インスタンス
PolarSearch クラスター
PolarSearch 機能が有効になっている PolarDB for MySQL クラスター。
Lindorm インスタンス
エンジンタイプにはSearch Engineとベクトルエンジンを含める必要があります。
PolarDB for PostgreSQL クラスター
PGVector (ベクトル検索) プラグインがインストールされていること。
ベクターデータベースと同じリージョンに OSS バケットを作成済みであること。 [ストレージクラス] は [標準] である必要があります。 [ストレージ冗長性] は [ゾーン冗長ストレージ (推奨)] に設定することを推奨します。
リージョン:この機能は、中国 (杭州)、中国 (上海)、中国 (北京)、中国 (深セン)、中国 (香港)、シンガポール、インドネシア (ジャカルタ) でのみ利用可能です。
注意事項
RAGFlow ナレッジベースのパブリックエンドポイントは、一度有効にすると無効にできません。
RAGFlow アカウントは、対応する RAGFlow ナレッジベースでのみ有効です。
課金
詳細については、「AI データ準備の課金方法」をご参照ください。
操作手順
RAGFlow ナレッジベースの作成
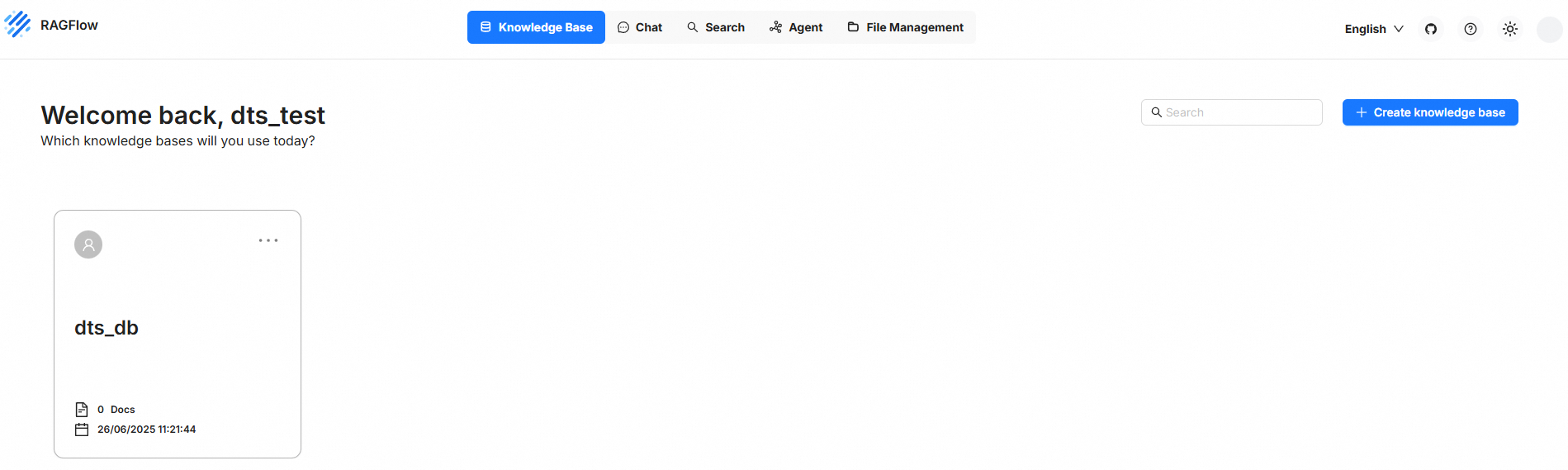
ターゲットリージョンの RAGFlow ナレッジベースリストページに移動します。
DTS コンソールにログインします。
左側のナビゲーションウィンドウで、データの準備 をクリックします。
ページの左上隅で、データ準備インスタンスが存在するリージョンを選択します。
[RAGFlow Knowledge Base] タブをクリックします。
[ナレッジベースの作成] をクリックして、タスク設定ページに移動します。
RAGFlow ナレッジベースを設定します。
[デプロイメント範囲] セクションで、RAGFlow ナレッジベースの [インスタンス名] を入力します。
[ネットワークとゾーン] セクションで、RAGFlow ナレッジベースの [VPC]、[ゾーンと vSwitch]、および [セカンダリゾーンと vSwitch] を選択します。
[RAGFlow ナレッジベース設定] セクションで、[ナレッジベースサービス数] を入力します。
説明この例では、[設定プラン] は [デフォルト] のままにします。
[ベクターデータベース設定] セクションで、ベクターデータベースを設定します。
説明[既存インスタンスからインポート] を選択した場合、インスタンス内の既存の [データベース]、[データベーススキーマ]、および [データベースアカウント] の名前を入力する必要があります。
エンジン:ADB PostgreSQL
[エンジン] を [ADB PostgreSQL] に設定します。 次に、[データベース] で、ターゲットの AnalyticDB for PostgreSQL インスタンスを選択します。 データを受信するインスタンスの [データベース名]、[データベーススキーマ名]、[データベースアカウント]、および [パスワード] を入力します。
エンジン:PolarSearch
[エンジン] を [PolarSearch] に設定します。 次に、[データベース] で、PolarSearch 機能が有効になっている PolarDB for MySQL クラスターを選択します。 データを受信するクラスターの [データベースアカウント] と [パスワード] を入力します。
エンジン:PolarDB PostgreSQL
[エンジン] を [PolarDB PostgreSQL] に設定します。 次に、[データベース] で、ターゲットの PolarDB for PostgreSQL クラスターを選択します。 データを受信するインスタンスの [データベース名]、[データベーススキーマ名]、[データベースアカウント]、および [パスワード] を入力します。
エンジン:Lindorm
[エンジン] を Lindorm に設定します。 次に、[データベース] で、ターゲットの Lindorm インスタンスを選択します。 データを受信するインスタンスの [データベースアカウント] と [パスワード] を入力します。
[OSS 設定] セクションで、データを受信するバケットを選択し、データを保存するパスを入力します。
設定が完了したら、ページの右側にある [今すぐ購入] をクリックします。
RAGFlow ナレッジベースリストページに戻り、ナレッジベースが正常に実行されるのを待ちます。 [実行ステータス] が [実行中] になるはずです。
説明右上隅の
 アイコンをクリックしてタスクリストをリフレッシュし、RAGFlow ナレッジベースの最新ステータスを表示できます。
アイコンをクリックしてタスクリストをリフレッシュし、RAGFlow ナレッジベースの最新ステータスを表示できます。
IP ホワイトリストの設定
ターゲットの RAGFlow ナレッジベースの 操作 列で、[ホワイトリストの設定] をクリックします。
[ホワイトリストの設定] パネルで、RAGFlow へのアクセス方法に基づいて IP アドレスをホワイトリストに追加します。
アクセス方法
シナリオ例
追加する IP ホワイトリスト
説明
内部ネットワーク
クライアントと RAGFlow ナレッジベースが同じ VPC 内にある。
クライアントのプライベート IP アドレスまたは CIDR ブロック。
複数の IP アドレスまたは CIDR ブロックはカンマ (,) で区切ります。
クライアントのパブリック IP アドレスを照会するには、
curl ipinfo.io/ip(推奨) またはcurl ifconfig.meコマンドを実行します。
パブリックネットワーク
クライアントがローカルサーバー上にある。
クライアントのパブリック IP アドレスまたは CIDR ブロック。
[設定] をクリックします。
RAGFlow へのログイン
ターゲットの RAGFlow ナレッジベースの 操作 列で、[管理] をクリックします。
説明また、操作 列の [ナレッジベースにログイン] をクリックし、内部ネットワークまたはパブリックネットワーク経由でのログインを選択することもできます。
[エンドポイント] セクションで、[パブリックエンドポイントでログイン] または [内部エンドポイントでログイン] をクリックします。
説明パブリックネットワーク経由で RAGFlow ナレッジベースにアクセスするには、インスタンスのパブリックエンドポイントを有効化する必要があります。
ログインページで、メールアドレスとパスワードを入力し、[ログイン] をクリックします。
RAGFlow ページで、ナレッジベースの管理などの操作を実行します。
説明これらの操作の詳細については、RAGFlow の公式ドキュメントをご参照ください。
(オプション) ネットワーク設定
デフォルトでは、RAGFlow は外部ネットワークにアクセスできません。RAGFlow でモデルプロバイダーを追加するには、RAGFlow が使用するベクターデータベースの VPC に NAT Gateway を設定する必要があります。これにより、RAGFlow が外部モデルにアクセスできるようになります。
プライベートネットワーク経由での接続 (Alibaba Cloud Model Studio)
プライベートネットワーク経由で Alibaba Cloud Model Studio プラットフォームにアクセスすると、データ転送のセキュリティと効率が向上します。PrivateLink を使用して、VPC と Alibaba Cloud Model Studio の間にネットワーク接続を確立できます。詳細については、「プライベートネットワーク経由で Alibaba Cloud Model Studio のモデルまたはアプリケーション API にアクセスする」をご参照ください。
パブリックネットワーク経由での接続
RAGFlow が使用するベクターデータベースの VPC に NAT Gateway を設定して、外部モデルへのアクセスを許可します。NAT Gateway の詳細については、「パブリック NAT Gateway」をご参照ください。
付録
パブリックエンドポイントの有効化
ターゲットの RAGFlow ナレッジベースの 操作 列で、[管理] をクリックします。
[エンドポイント] セクションで、[パブリックエンドポイントの有効化] をクリックします。
ポップアップ [パブリックエンドポイントの有効化] ダイアログボックスで、[OK] をクリックします。
パブリックエンドポイントが有効になるまでお待ちください。[実行ステータス] は、[基本情報] セクションで [実行中] になっている必要があります。
RAGFlow アカウントの登録
ターゲットの RAGFlow ナレッジベースのRAGFlow ログインページに移動します。
RAGFlow ログインページで、[登録] をクリックします。
メールアドレス、名前、パスワードを入力します。
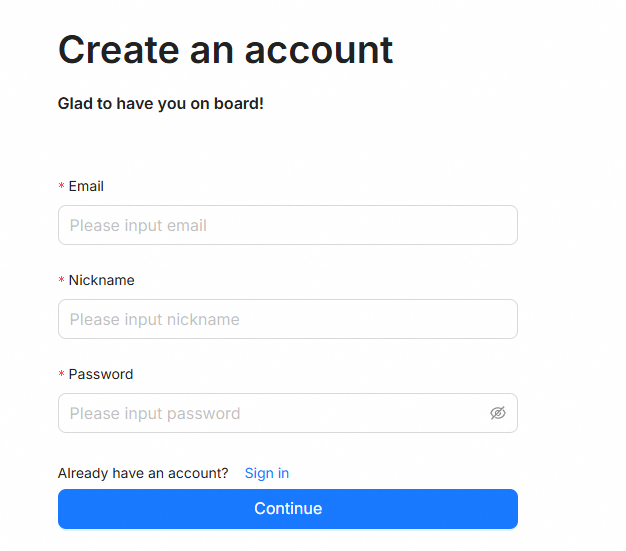
[続行] をクリックします。
ページの上部にアカウントが登録されたことを示す
 メッセージが表示されます。
メッセージが表示されます。