Data Transmission Service (DTS) でデータ同期またはデータ移行タスクを作成する際に、ターゲットテーブルに追加の列を加え、値を割り当てることができます。データがターゲットテーブルに書き込まれた後、これらの追加列の値でフィルター処理できます。これにより、メタデータ管理、並べ替え、重複排除などの操作を実行できます。これは、ターゲットに転送されたデータをより適切に管理および処理するのに役立ちます。
注意事項
以下のシナリオでは、データ同期インスタンスまたはデータ移行インスタンスに追加列を追加できます:
ターゲットデータベースの データベースタイプ は DataHub、Lindorm、Kafka、または ClickHouse です。
ソースデータベースのデータベースタイプは DB2 for LUW または DB2 for iSeries (AS/400) で、ターゲットデータベースのデータベースタイプは MySQL または PolarDB for MySQL です。
ソースデータベースのデータベースタイプが MySQL、MariaDB、または PolarDB for MySQL であり、ターゲットデータベースのデータベースタイプが MySQL、MariaDB、または PolarDB for MySQL です。
ソースデータベースのデータベースタイプが MySQL で、ターゲットデータベースのデータベースタイプが Tair/Redis、AnalyticDB for PostgreSQL、または AnalyticDB for MySQL 3.0 です。
ソースデータベースの データベースタイプ は PolarDB for PostgreSQL で、ターゲットデータベースの データベースタイプ は AnalyticDB for PostgreSQL です。
ソースデータベースのデータベースタイプは SQL Server で、ターゲットデータベースのデータベースタイプは MySQL です。
同期インスタンスでは、同期タイプ を スキーマ同期 に設定します。移行インスタンスでは、移行タイプ を スキーマ移行 に設定します。
データ同期タスクの追加列のルールを変更する前に、追加列の名前がターゲットテーブルの既存の列と競合しないか評価してください。
同期タスクのソースデータベースが MongoDB の場合、ターゲットデータベースのコレクションに _id または _value という名前のフィールドを含めることはできません。そうしないと、同期は失敗します。
選択中のオブジェクト セクションでデータベースを右クリックすると、DTS は、対応するターゲットデータベース内のすべてのテーブルに、設定された追加列を追加します。
操作手順
このセクションでは、DTS データ同期インスタンスを例に、追加列を追加する方法について説明します。
データ同期タスクページに移動します。
Data Management (DMS) コンソールにログインします。
上部のナビゲーションバーで、[データ + AI] をクリックします。
左側のナビゲーションウィンドウで、 を選択します。
説明操作は DMS コンソールのモードとレイアウトによって異なる場合があります。詳細については、「シンプルモードコンソール」および「DMS コンソールのレイアウトとスタイルをカスタマイズする」をご参照ください。
また、新しい DTS コンソールのデータ同期タスクページに移動することもできます。
タスクの作成 をクリックし、ソースデータベースとターゲットデータベースを構成します。
説明オブジェクトを再選択 をクリックして、実行中 の同期インスタンスに列を追加します。
プロンプトに従って オブジェクト設定 ステップに進み、構成を完了します。
このステップで追加列を追加できます。
同期タイプ を スキーマ同期 に設定します。
ソースオブジェクト セクションで、同期するデータベースまたはテーブルを選択し、
 をクリックして 選択中のオブジェクト ボックスに移動します。
をクリックして 選択中のオブジェクト ボックスに移動します。選択中のオブジェクト セクションで、同期するデータベースまたはテーブルを右クリックします。
ダイアログボックスの追加の列セクションで、列の追加ボタンをクリックします。
追加列の列名、タイプ、および値の割り当てを入力します。
説明値の割り当て では、テキストボックスの右側にある
 アイコンをクリックして、追加列の値の式をカスタマイズできます。 詳細については、「割り当ての設定」をご参照ください。
アイコンをクリックして、追加列の値の式をカスタマイズできます。 詳細については、「割り当ての設定」をご参照ください。OK をクリックします。
プロンプトに従って、残りのデータ同期タスク構成を完了します。
説明同期タスクに抽出・変換・書き出し (ETL) 機能が構成されている場合、同期されるデータはまず追加列のルールによって処理されて値が生成されます。次に、ETL スクリプトが適用されて最終的な値が計算され、それがターゲットデータベースに同期されます。
割り当て構成
追加列の値は、定数、変数、演算子、および式関数で構成されます。
構文は、ETL のデータ処理 DSL (ドメイン固有言語) と互換性があります。
式では、列名は単一引用符 (') ではなく、バッククォート (`) で囲みます。
定数
型
例
int
123
float
123.4
string
"hello1_world"
boolean
true または false
datetime
DATETIME('2021-01-01 10:10:01')
変数
変数
説明
データの型
値の例
__TB__
データベース内のテーブルの名前。
string
table
__DB__
データベースの名前。
string
mydb
__OPERATION__
操作のタイプ。
string
__OP_INSERT__,__OP_UPDATE__,__OP_DELETE__
__COMMIT_TIMESTAMP__
トランザクションがコミットされた時刻。
datetime
'2021-01-01 10:10:01'
`column`
データレコードの列の値。
string
`id`, `name`
__SCN__
システム変更番号 (SCN)。データベース内のトランザクションコミットのバージョンと時刻を記録し、一意です。
string
22509****
__ROW_ID__
説明MySQL は __ROW_ID__ をサポートしていません。
データレコードのアドレス ID。データを特定し、一意です。
string
AAAgWHAAKAAJgX****
式関数
数値演算
関数
構文
有効値
戻り値
例
加算 (+)
op_sum(value1, value2)
value1+value2
value1:整数または浮動小数点数
value2:整数または浮動小数点数
両方のパラメーターが整数の場合は整数が返されます。それ以外の場合は、浮動小数点数が返されます。
op_sum(`col1`, 1.0)
`col1`+1.0
減算 (-)
op_sub(value1, value2)
value1-value2
value1:整数または浮動小数点数
value2:整数または浮動小数点数
両方のパラメーターが整数の場合は整数が返されます。それ以外の場合は、浮動小数点数が返されます。
op_sub(`col1`, 1.0)
`col1`-1.0
乗算 (*)
op_mul(value1, value2)
value1*value2
value1:整数または浮動小数点数
value2:整数または浮動小数点数
両方のパラメーターが整数の場合は整数が返されます。それ以外の場合は、浮動小数点数が返されます。
op_mul(`col1`, 1.0)
`col1`*1.0
除算 (/)
op_div_true(value1, value2)
value1/value2
value1:整数または浮動小数点数
value2:整数または浮動小数点数
両方のパラメーターが整数の場合は整数が返されます。それ以外の場合は、浮動小数点数が返されます。
op_div_true(`col1`, 2.0)。col1=15 の場合、7.5 が返されます。
`col1`/1.0
剰余演算
op_mod(value1, value2)
value1:整数または浮動小数点数
value2:整数または浮動小数点数
両方のパラメーターが整数の場合は整数が返されます。それ以外の場合は、浮動小数点数が返されます。
op_mod(`col1`, 10)。col1=23 の場合、3 が返されます。
論理演算
機能
構文
値の範囲
戻り値
例
等しい
op_eq(value1, value2)
value1:整数、浮動小数点数、または文字列
value2:整数、浮動小数点数、または文字列
ブール値:true または false
op_eq(`col1`, 23)
より大きい
op_gt(value1, value2)
value1:整数、浮動小数点数、または文字列
value2:整数、浮動小数点数、または文字列
ブール値:true または false
op_gt(`col1`, 1.0)
より小さい
op_lt(value1, value2)
value1:整数、浮動小数点数、または文字列
value2:整数、浮動小数点数、または文字列
ブール値:true または false
op_lt(`col1`, 1.0)
以上
op_ge(value1, value2)
value1:整数、浮動小数点数、または文字列
value2:整数、浮動小数点数、または文字列
ブール値:true または false
op_ge(`col1`, 1.0)
以下
op_le(value1, value2)
value1:整数、浮動小数点数、または文字列
value2:整数、浮動小数点数、または文字列
ブール値:true または false
op_le(`col1`, 1.0)
AND 演算
op_and(value1, value2)
value1:ブール値
value2:ブール値
ブール値:true または false
op_and(`is_male`, `is_student`)
OR 演算
op_or(value1, value2)
value1:ブール値
value2:ブール値
ブール値:true または false
op_or(`is_male`, `is_student`)
IN 演算
op_in(value, json_array)
value:任意の型
json_array:JSON 形式の文字列
ブール値:true または false
op_in(`id`,json_array('["0","1","2","3","4","5","6","7","8"]'))
Is null
op_is_null(value)
value:任意の型
ブール値:true または false
op_is_null(`name`)
Is not null
op_is_not_null(value)
value:任意の型
ブール値:true または false
op_is_not_null(`name`)
文字列関数
機能
構文
有効値
戻り値
例
文字列の連結
op_add(str_1,str_2,...,str_n)
str_1:文字列
str_2:文字列
...
str_n:文字列
連結された文字列
op_add(`col`,'hangzhou','dts')
文字列のフォーマットと連結
str_format(format, value1, value2, value3, ...)
format:中括弧 ({}) をプレースホルダーとして使用する文字列。例:"part1: {}, part2: {}"。
value1:任意
value2:任意
フォーマットされた文字列
str_format("part1: {}, part2: {}", `col1`, `col2`)。col1="ab" かつ col2="12" の場合、"part1: ab, part2: 12" が返されます。
文字列の置換
str_replace(original, oldStr, newStr, count)
original:元の文字列
oldStr:置換される文字列
newStr:置換後の文字列
count:置換の最大回数を指定する整数。このパラメーターを -1 に設定すると、すべての一致が置換されます。
置換後の文字列
str_replace(`name`, "a", 'b', 1)。name="aba" の場合、"bba" が返されます。str_replace(`name`, "a", 'b', -1)。name="aba" の場合、"bbb" が返されます。
すべての文字列型フィールド (varchar、text、char など) の値を置換する
tail_replace_string_field(search, replace, all)
search:置換される文字列
replace:置換後の文字列
all:すべての一致する文字列を置換するかどうかを指定します。このパラメーターは true のみをサポートします。
説明すべての一致する文字列を置換する必要がない場合は、
str_replace関数を使用してください。
置換後の文字列
tail_replace_string_field('\u000f','',true)。すべての文字列型フィールドの値で "\u000f" をスペースに置換します。
文字列の先頭と末尾から特定の文字を削除する
str_strip(string_val, charSet)
string_val:元の文字列
char_set:削除する文字のコレクション
先頭と末尾から文字が削除された後の文字列
str_strip(`name`, 'ab')。name=axbzb の場合、xbz が返されます。
文字列を小文字に変換する
str_lower(value)
value:文字列の列または文字列定数
小文字の文字列
str_lower(`str_col`)
文字列を大文字に変換する
str_upper(value)
value:文字列の列または文字列定数
大文字の文字列
str_upper(`str_col`)
文字列を数値に変換する
cast_string_to_long(value)
value:文字列
整数
cast_string_to_long(`col`)
数値を文字列に変換する
cast_long_to_string(value)
value:整数
文字列
cast_long_to_string(`col`)
部分文字列の出現回数を数える
str_count(str,pattern)
str:文字列の列または文字列定数
pattern:見つける部分文字列
部分文字列の出現回数
str_count(`str_col`, 'abc')。str_col="zabcyabcz" の場合、2 が返されます。
部分文字列を見つける
str_find(str, pattern)
str:文字列の列または文字列定数
pattern:見つける部分文字列
部分文字列の最初の一致の位置。一致が見つからない場合、`-1` が返されます。
str_find(`str_col`, 'abc')。`str_col="xabcy"` の場合、`1` が返されます。
文字列が文字のみで構成されているか確認する
str_isalpha(str)
str:文字列の列または文字列定数
true または false
str_isalpha(`str_col`)
文字列が数字のみで構成されているか確認する
str_isdigit(str)
str:文字列の列または文字列定数
true または false
str_isdigit(`str_col`)
正規表現のマッチング
regex_match(str,regex)
str:文字列の列または文字列定数
regex:正規表現の文字列の列または文字列定数
true または false
regex_match(__TB__,'user_\\d+')
文字列の一部を指定された文字でマスクする。これは、電話番号の最後の 4 桁をアスタリスクに置き換えるなど、データマスキングに使用できます。
str_mask(str, start, end, maskStr)
str:文字列の列または文字列定数
start:マスクの開始位置を指定する整数。最小値は 0 です。
end:マスクの終了位置を指定する整数。最大値は文字列の長さから 1 を引いたものです。
maskStr:長さ 1 の文字列。例:'#'。
開始位置から終了位置までの部分の後の文字列がマスクされます
str_mask(`phone`, 7, 10, '#')
指定された文字列の後の部分文字列を取得する
substring_after(str, cond)
str:元の文字列
cond:文字列
文字列
説明戻り値には文字列 cond は含まれません。
substring_after(`col`, 'abc')
指定された文字列の前の部分文字列を取得する
substring_before(str, cond)
str:元の文字列
cond:文字列
文字列
説明戻り値には文字列 cond は含まれません。
substring_before(`col`, 'efg')
2 つの指定された文字列の間の部分文字列を取得する
substring_between(str, cond1, cond2)
str:元の文字列
cond1:文字列
cond2:文字列
文字列
説明戻り値には文字列 cond1 と cond2 は含まれません。
substring_between(`col`, 'abc','efg')
値が文字列であるか確認する
is_string_value(value)
value:文字列または列名
ブール値:true または false
is_string_value(`col1`)
文字列型フィールドの内容を、末尾から逆方向に置換する。
tail_replace_string_field(search, replace, all)
search:置換される文字列
replace:置換後の文字列
all:すべての出現を置換するかどうかを指定します。値は true または false です。
置換後の文字列
すべての文字列型フィールドの値で "\u000f" をスペースに置換します。
tail_replace_string_field('\u000f','',true)
MongoDB のフィールドの値を取得する
bson_value("field1","field2","field3",...)
field1:レベル 1 フィールドの名前。
field2:レベル 2 フィールドの名前。
ドキュメント内の対応するフィールドの値
e_set(`user_id`, bson_value("id"))
e_set(`user_name`, bson_value("person","name"))
条件式
機能
構文
値の範囲
戻り値
例
C 言語の三項演算子 (
? :) に似ています。条件に基づいて値を返します。(cond ? val_1 : val_2)
cond:ブール値のフィールドまたは式
val_1:戻り値 1
val_2:戻り値 2
説明val_1 と val_2 は同じ型でなければなりません。
cond が true の場合、val_1 が返されます。それ以外の場合は、val_2 が返されます。
(id>1000? 1 : 0)
時間関数
機能
構文
値の範囲
戻り値
例
現在のシステム時刻
dt_now()
なし
DATETIME、秒単位の精度
dts_now()
dt_now_millis()
なし
DATETIME、ミリ秒単位の精度
dt_now_millis()
UTC タイムスタンプ (秒) を DATETIME に変換する
dt_fromtimestamp(value,[timezone])
value:整数
timezone:タイムゾーン。これはオプションのパラメーターです。
DATETIME、秒単位の精度
dt_fromtimestamp(1626837629)
dt_fromtimestamp(1626837629,'GMT+08')
UTC タイムスタンプ (ミリ秒) を DATETIME に変換する
dt_fromtimestamp_millis(value,[timezone])
value:整数
timezone:タイムゾーン。これはオプションのパラメーターです。
DATETIME、ミリ秒単位の精度
dt_fromtimestamp_millis(1626837629123);
dt_fromtimestamp_millis(1626837629123,'GMT+08')
DATETIME を UTC タイムスタンプ (秒) に変換する
dt_parsetimestamp(value,[timezone])
value:DATETIME
timezone:タイムゾーン。これはオプションのパラメーターです。
整数
dt_parsetimestamp(`datetime_col`)
dt_parsetimestamp(`datetime_col`,'GMT+08')
DATETIME を UTC タイムスタンプ (ミリ秒) に変換する
dt_parsetimestamp_millis(value,[timezone])
value:DATETIME
timezone:タイムゾーン。これはオプションのパラメーターです。
整数
dt_parsetimestamp_millis(`datetime_col`)
dt_parsetimestamp_millis(`datetime_col`,'GMT+08')
DATETIME を文字列に変換する
dt_str(value, format)
value:DATETIME
format:yyyy-MM-dd HH:mm:ss 形式の文字列
文字列
dt_str(`col1`, 'yyyy-MM-dd HH:mm:ss')
文字列を DATETIME に変換する
dt_strptime(value,format)
value:文字列
format:yyyy-MM-dd HH:mm:ss 形式の文字列
DATETIME
dt_strptime('2021-07-21 03:20:29', 'yyyy-MM-dd hh:mm:ss')
年、月、日、時、分、または秒から値を加算または減算して時刻を変更する
dt_add(value, [years=intVal],
[months=intVal],
[days=intVal],
[hours=intVal],
[minutes=intVal]
)
value:DATETIME
intVal:整数
説明マイナス記号 (-) は減算を示します。
DATETIME
dt_add(datetime_col,years=-1)
dt_add(datetime_col,years=1,months=1)
よくある質問
シナリオの説明
MySQL から Redis にデータを同期または移行する場合、DTS はデフォルトでデータ行全体をマップする 3 つの キャッシュデータマッピングモード を提供します。特定の列のみを抽出し、キーと値のペアを作成するには、カスタム構成を使用する必要があります。
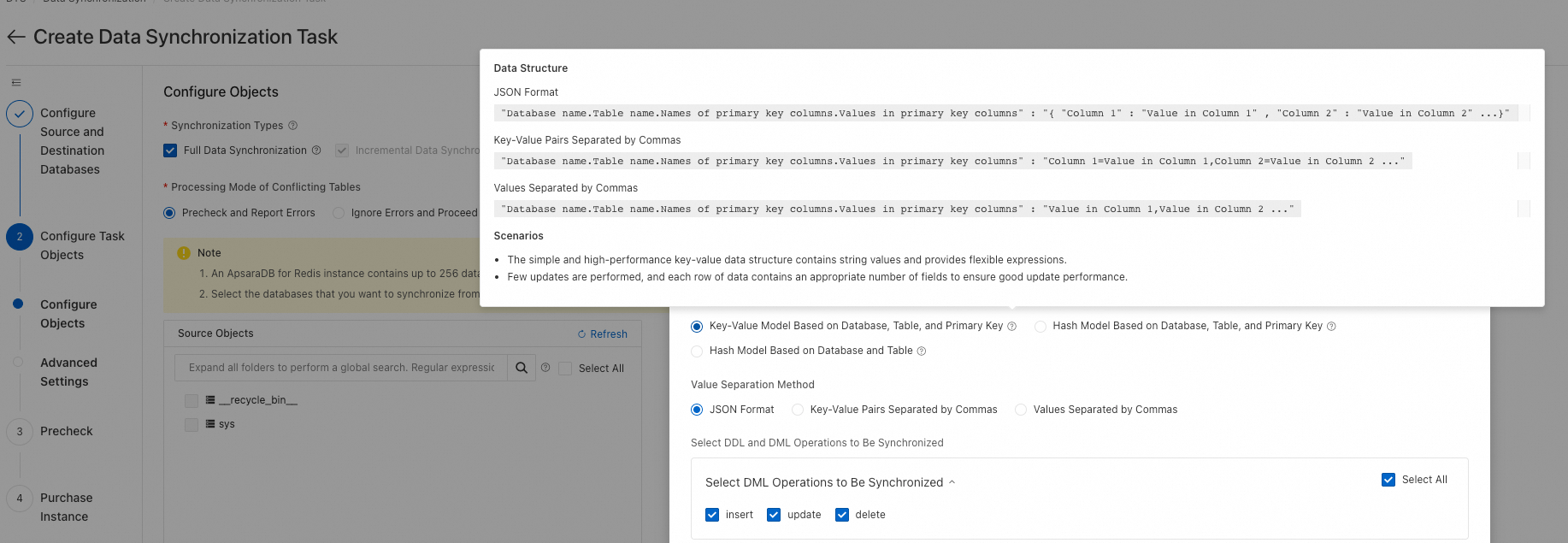
構成方法
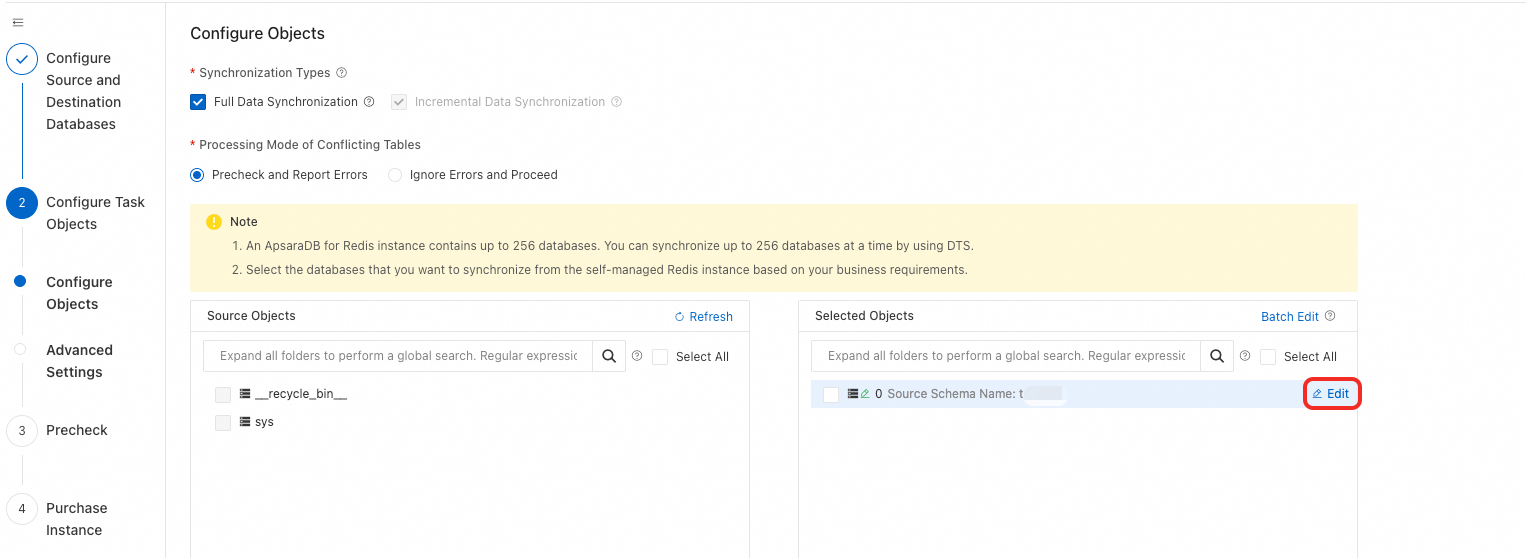
オブジェクトを構成する際、同期または移行するデータベースとテーブルを右側のペインに移動し、ターゲット Redis DB の編集ボタンをクリックします。
次の列を追加します:
__DTS_TP_TO_REDIS_KEY__および__DTS_TP_TO_REDIS_VALUE__。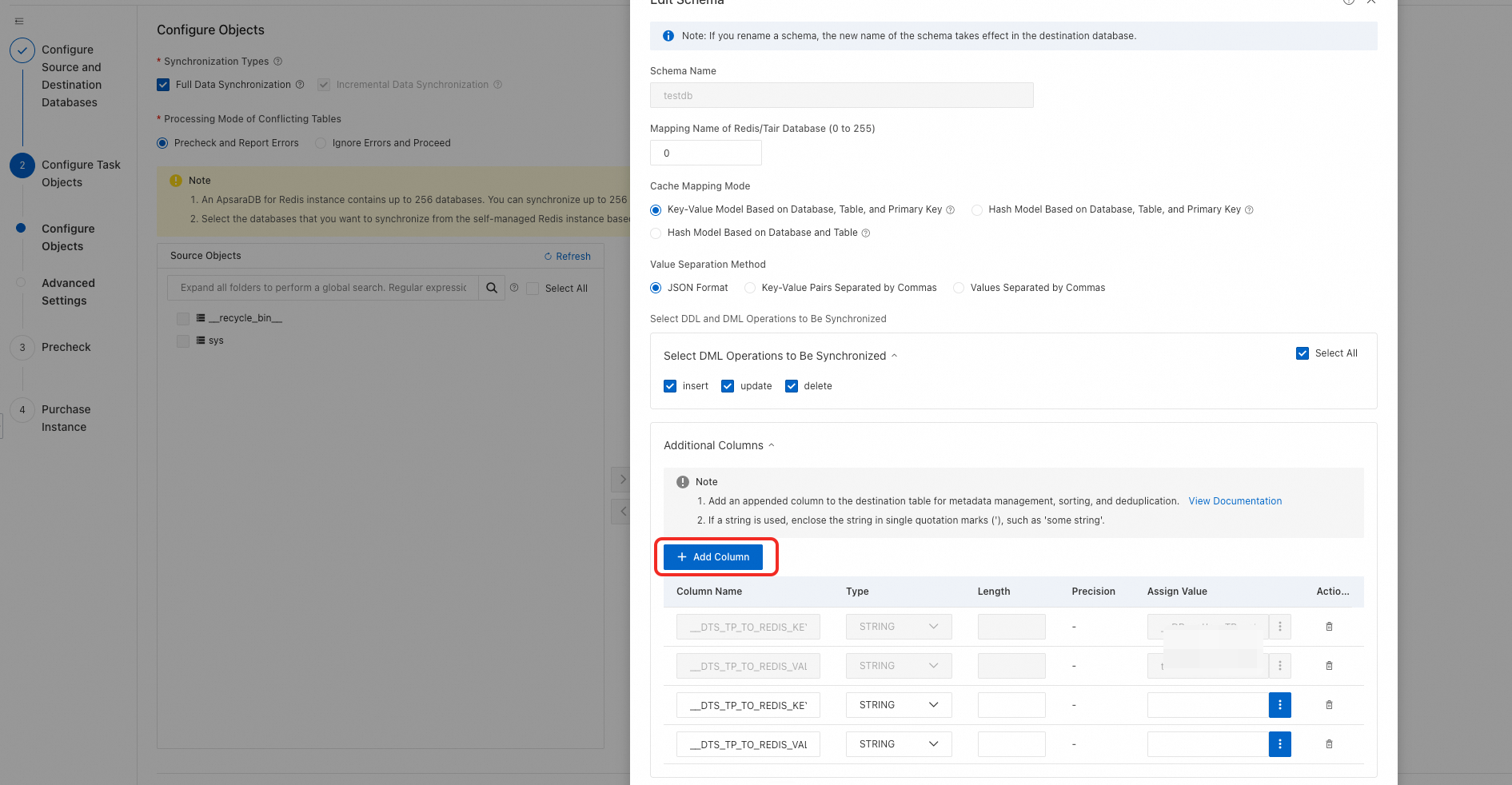
DSL 構文に基づいて値の割り当てをカスタマイズします。たとえば、MySQL の
aesテーブルを考えます:CREATE TABLE `aes` ( `id` BIGINT(20) UNSIGNED NOT NULL AUTO_INCREMENT COMMENT '自動インクリメントプライマリキー', `login_time` INT(10) NOT NULL DEFAULT '0' COMMENT 'ログイン識別子時間', `pay_time` INT(10) NOT NULL DEFAULT '0' COMMENT '支払い識別子時間', `gid` INT(10) NOT NULL DEFAULT '0' COMMENT 'ゲーム ID', `cid` INT(10) NOT NULL DEFAULT '0' COMMENT 'チャネル ID', `gcp_code` VARCHAR(40) NOT NULL DEFAULT '' COMMENT 'チャネルパッケージ番号。空の値は gid の新しいエントリを示します。', `uname` VARCHAR(120) CHARACTER SET utf8 COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT 'アカウント', PRIMARY KEY (`id`), UNIQUE KEY `idx_uq` (`gid`, `gcp_code`, `uname`), KEY `idx_uname` (`uname`) )ENGINE=InnoDB AUTO_INCREMENT=48022 DEFAULT CHARSET=utf8 COMMENT='ゲームアカウントアクティベーション時間情報テーブル';ビジネスシナリオ:
キーは
stat_create_day:{gcp_code}:{uname}です。このキーはaesテーブルの 2 つのフィールド、gcp_codeとunameを使用します。値は
{login_time}です。この値はdatetime形式に変換する必要がある 1 つのフィールドを使用します。
値の割り当ての参照:
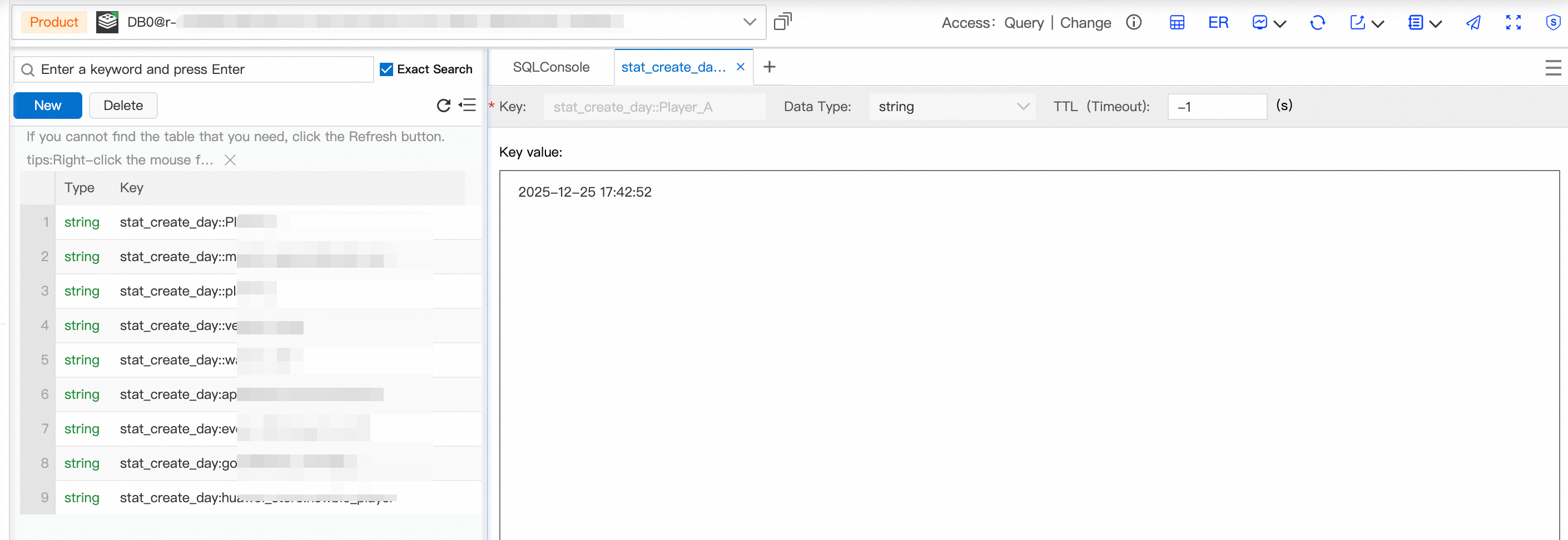
__DTS_TP_TO_REDIS_KEY__の値:'stat_create_day'+':'+`gcp_code`+':'+`uname`__DTS_TP_TO_REDIS_VALUE__の値:dt_fromtimestamp(cast_string_to_long(`login_time`))
データが Redis に同期または移行された後、キーと値のペアは次のように表示されます: