Amazon RDS for SQL Server 出力コンポーネントは、Amazon RDS for SQL Server データソースにデータを書き込みます。他のデータソースから Amazon RDS for SQL Server データソースにデータを同期する場合、ソースデータソース情報を構成した後、Amazon RDS for SQL Server 出力コンポーネントのターゲットデータソースを構成する必要があります。このトピックでは、Amazon RDS for SQL Server 出力コンポーネントを構成する方法について説明します。
前提条件
Amazon RDS for SQL Server データソースが作成されていること。詳細については、「Amazon RDS for SQL Server データソースを作成する」をご参照ください。
Amazon RDS for SQL Server 出力コンポーネントのプロパティを構成するために使用するアカウントは、データソースに対するライトスルー権限を持っている必要があります。権限がない場合は、データソース権限をリクエストする必要があります。詳細については、「データソース権限のリクエスト、更新、および返却」をご参照ください。
手順
Dataphin ホームページで、上部ナビゲーションバーの [開発] > [Data Integration] をクリックします。
統合ページの上部ナビゲーションバーで、プロジェクトを選択します(開発 - 本番モードでは、環境を選択する必要があります)。
左側のナビゲーションウィンドウで、[バッチパイプライン] をクリックします。[バッチパイプライン] リストで、開発するオフラインパイプラインをクリックして、構成ページを開きます。
ページの右上隅にある [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側のナビゲーションウィンドウで、[出力] を選択します。右側の出力コンポーネントリストで、[Amazon RDS For SQL Server] コンポーネントを見つけて、キャンバスにドラッグします。
ターゲットの入力、変換、またはフローコンポーネントの
 アイコンをクリックしてドラッグし、現在の Amazon RDS for SQL Server 出力コンポーネントに接続します。
アイコンをクリックしてドラッグし、現在の Amazon RDS for SQL Server 出力コンポーネントに接続します。Amazon RDS for SQL Server 出力コンポーネントカードの
 アイコンをクリックして、[Amazon RDS For SQL Server 出力構成] ダイアログボックスを開きます。
アイコンをクリックして、[Amazon RDS For SQL Server 出力構成] ダイアログボックスを開きます。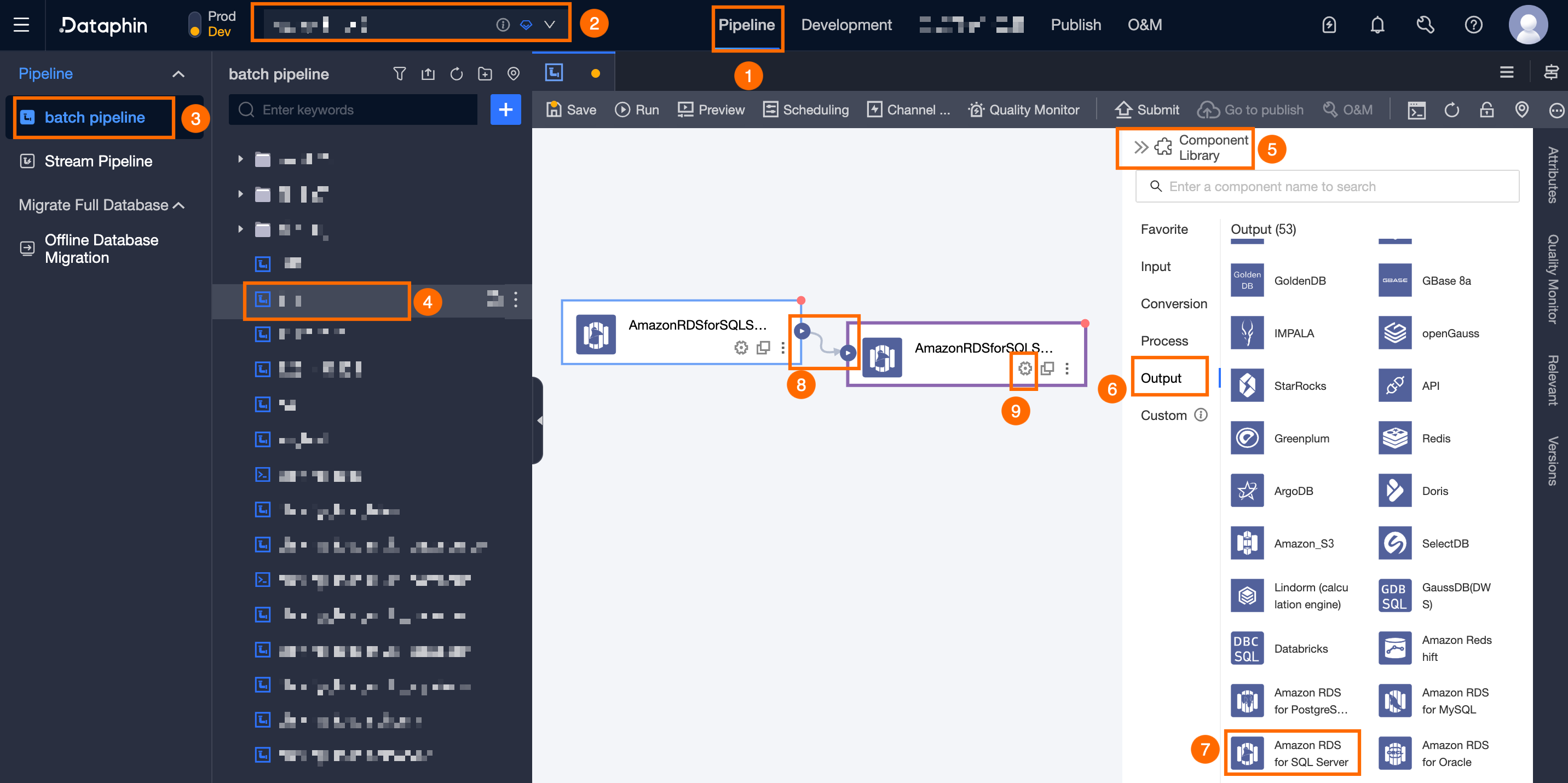
[Amazon RDS For SQL Server 出力構成] ダイアログボックスで、パラメーターを構成します。
パラメーター
説明
基本設定
ステップ名
Amazon RDS for SQL Server 出力コンポーネントの名前。Dataphin は自動的にステップ名を生成しますが、ビジネスシナリオに基づいて変更できます。名前は次の要件を満たしている必要があります。
中国語、英字、アンダースコア (_)、数字のみ使用できます。
最大 64 文字まで使用できます。
データソース
データソースのドロップダウンリストには、ライトスルー権限を持つデータソースと持たないデータソースを含め、すべての Amazon RDS for SQL Server データソースが表示されます。
 アイコンをクリックして、現在のデータソース名をコピーします。
アイコンをクリックして、現在のデータソース名をコピーします。ライトスルー権限のないデータソースの場合、データソースの横にある [リクエスト] をクリックして、ライトスルー権限をリクエストできます。詳細については、「データソース権限のリクエスト、更新、および返却」をご参照ください。
Amazon RDS for SQL Server データソースがない場合は、[データソースの作成] をクリックして作成します。詳細については、「Amazon RDS for SQL Server データソースを作成する」をご参照ください。
スキーマ(オプション)
スキーマを跨いでテーブルを選択できます。テーブルが配置されているスキーマを選択します。スキーマを指定しない場合、データソースで構成されているスキーマがデフォルトで使用されます。
テーブル
出力データのターゲットテーブルを選択します。キーワードを入力してテーブルを検索するか、正確なテーブル名を入力して [完全一致] をクリックします。テーブルを選択すると、システムは自動的にテーブルステータスをチェックします。
 アイコンをクリックして、選択したテーブルの名前をコピーします。
アイコンをクリックして、選択したテーブルの名前をコピーします。ロードポリシー
ターゲットテーブルにデータを書き込むための戦略を選択します。ロードポリシーには以下が含まれます。
データの追加(insert Into): プライマリキー/制約の競合が発生した場合、ダーティデータエラーが報告されます。
プライマリキーの競合時に更新(merge Into): プライマリキー/制約の競合が発生した場合、マップされたフィールドのデータが既存のレコードで更新されます。
同期書き込み
プライマリキー更新構文はアトミック操作ではありません。書き込むデータに重複するプライマリキーがある場合は、同期書き込みを有効にする必要があります。そうでない場合は、並列書き込みが使用されます。同期書き込みのパフォーマンスは並列書き込みよりも低くなります。
説明このオプションは、ロードポリシーがプライマリキーの競合時に更新に設定されている場合にのみ構成できます。
バッチ書き込みサイズ(オプション)
一度に書き込むデータのサイズ。[バッチ書き込みレコード] も設定できます。いずれかの制限に達すると、システムはデータを書き込みます。デフォルト値は 32M です。
バッチ書き込みレコード(オプション)
デフォルト値は 2048 レコードです。データが同期および書き込みされるとき、バッチ書き込み戦略が使用されます。パラメーターには、[バッチ書き込みレコード] と [バッチ書き込みサイズ] が含まれます。
累積データがいずれかの制限(バッチ書き込みサイズまたはバッチ書き込みレコード)に達すると、システムはデータのバッチが一杯になったと見なし、このバッチデータをすぐに宛先に一度に書き込みます。
バッチ書き込みサイズを 32MB に設定することをお勧めします。バッチ書き込みレコード制限については、バッチ書き込みの利点を最大限に活用するために、1 レコードの実際のサイズに基づいて調整できます。たとえば、1 レコードのサイズが約 1KB の場合、バッチ書き込みサイズを 16MB に設定し、バッチ書き込みレコードを 16MB を 1 レコードサイズ 1KB で割った結果よりも大きい値(つまり、16384 レコードより大きい値)、たとえば 20000 レコード に設定できます。この構成では、システムはバッチ書き込みサイズに基づいてバッチ書き込みをトリガーします。累積データが 16MB に達すると、書き込み操作が実行されます。
プリステートメント(オプション)
データインポートの前にデータベースで実行される SQL スクリプト。
たとえば、継続的なサービスの可用性を確保するために、現在のステップでデータを書き込む前に、まずターゲットテーブル Target_A を作成し、次に Target_A にデータを書き込みます。現在のステップがデータの書き込みを完了した後、継続的にサービスを提供しているテーブル Service_B の名前を Temp_C に変更し、次にテーブル Target_A の名前を Service_B に変更し、最後に Temp_C を削除します。
ポストステートメント(オプション)
データインポート後にデータベースで実行される SQL スクリプト。
フィールドマッピング
入力フィールド
上流コンポーネントの出力に基づいて入力フィールドを表示します。
出力フィールド
出力フィールドを表示します。次の操作を実行できます。
フィールド管理:[フィールド管理] をクリックして、出力フィールドを選択します。

 アイコンをクリックして、[選択済みの入力フィールド] を [選択されていない入力フィールド] に移動します。
アイコンをクリックして、[選択済みの入力フィールド] を [選択されていない入力フィールド] に移動します。 アイコンをクリックして、[選択されていない入力フィールド] を [選択済みの入力フィールド] に移動します。
アイコンをクリックして、[選択されていない入力フィールド] を [選択済みの入力フィールド] に移動します。
一括追加:[一括追加] をクリックして、JSON、TEXT、または DDL 形式で構成します。
JSON 形式での一括構成。例:
// 例: [{"name":"id","type":"String"}, {"name":"aaasa","type":"String"}, {"name":"creator","type":"String"}, {"name":"modifier","type":"String"}, {"name":"creator_nickname","type":"String"}, {"name":"modifier_nickname","type":"String"}, {"name":"create_time","type":"Date"}, {"name":"modify_time","type":"Date"}, {"name":"qbi_system_upload_id","type":"Long"}]説明name はインポートされたフィールドの名前を示し、type はインポート後のフィールドタイプを示します。たとえば、
"name":"user_id","type":"String"は、user_id という名前のフィールドをインポートし、そのタイプを String に設定することを意味します。TEXT 形式での一括構成。例:
// 例: id,String aaasa,String creator,String modifier,String creator_nickname,String modifier_nickname,String create_time,Date modify_time,Date qbi_system_upload_id,Long行区切り文字は、各フィールドの情報を区切るために使用されます。デフォルトは改行(\n)です。サポートされている区切り文字には、改行(\n)、セミコロン(;)、ピリオド(.)が含まれます。
列区切り文字は、フィールド名とフィールドタイプを区切るために使用されます。デフォルトはカンマ(,)です。
DDL 形式での一括構成。例:
CREATE TABLE tablename ( id INT PRIMARY KEY, name VARCHAR(50), age INT );
新しい出力フィールドを作成する:[+ 出力フィールドの作成] をクリックし、プロンプトに従って [列] に入力し、[タイプ] を選択します。現在の行の構成が完了したら、
 アイコンをクリックして保存します。
アイコンをクリックして保存します。
クイックマッピング
上流の入力とターゲットテーブルのフィールドに基づいて、フィールドマッピングを手動で選択できます。[クイックマッピング] には、[同じ行のマッピング] と [同じ名前のマッピング] が含まれます。
同じ名前のマッピング:同じ名前のフィールドをマッピングします。
同じ行のマッピング:ソーステーブルとターゲットテーブルのフィールド名が異なるが、対応する行のデータをマッピングする必要がある場合、同じ行のフィールドをマッピングします。
[OK] をクリックして、[Amazon RDS For SQL Server] 出力コンポーネントのプロパティ構成を完了します。