複雑なデータ開発シナリオに対応するため、Dataphin のインテリジェント R&D バージョンでは、ユーザー定義の Java UDF 関数の作成がサポートされています。このチュートリアルでは、組み込みの Java 関数(toLowerCase)を例として使用して、Dataphin を使用して Java UDF 関数をカスタマイズする方法を示します。
前提条件
JAR ファイルをダウンロードします。
背景情報
このチュートリアルでは、ダウンロードした JAR ファイルを使用して、大文字を小文字に変換する Java UDF 関数をカスタマイズする方法を説明します。追加の Java UDF コードを開発して機能を拡張することもできます。詳細については、「IntelliJ IDEA を使用して Java UDF を開発する」をご参照ください。
このチュートリアルで使用される JAR ファイルのコードは次のとおりです。
package org.alidata.odps.udf.examples;
import com.aliyun.odps.udf.UDF;
public final class javaudf extends UDF {
public String evaluate(String s) {
if (s == null) {
return null;
}
return s.toLowerCase();
}
}説明:
JAR ファイルのパスは
org.alidata.odps.udf.examplesです。クラスファイル名は
javaudfです。
手順 1: JAR ファイルをアップロードする
Dataphin コンソールにログインします。
Dataphin コンソールで、ワークスペースリージョンを選択し、[dataphin に入る >>] をクリックします。
[リソース管理] ページに移動します。
Dataphin ホームページで、[開発] をクリックします。
[データ開発] ページで、[データ処理] をクリックします。
左側のナビゲーションウィンドウで、
 [リソース管理] アイコンをクリックします。
[リソース管理] アイコンをクリックします。
[リソース管理] ページで、[リソース管理]
 アイコンをクリックします。
アイコンをクリックします。[新規リソース] ダイアログボックスで、必須パラメーターを入力します。
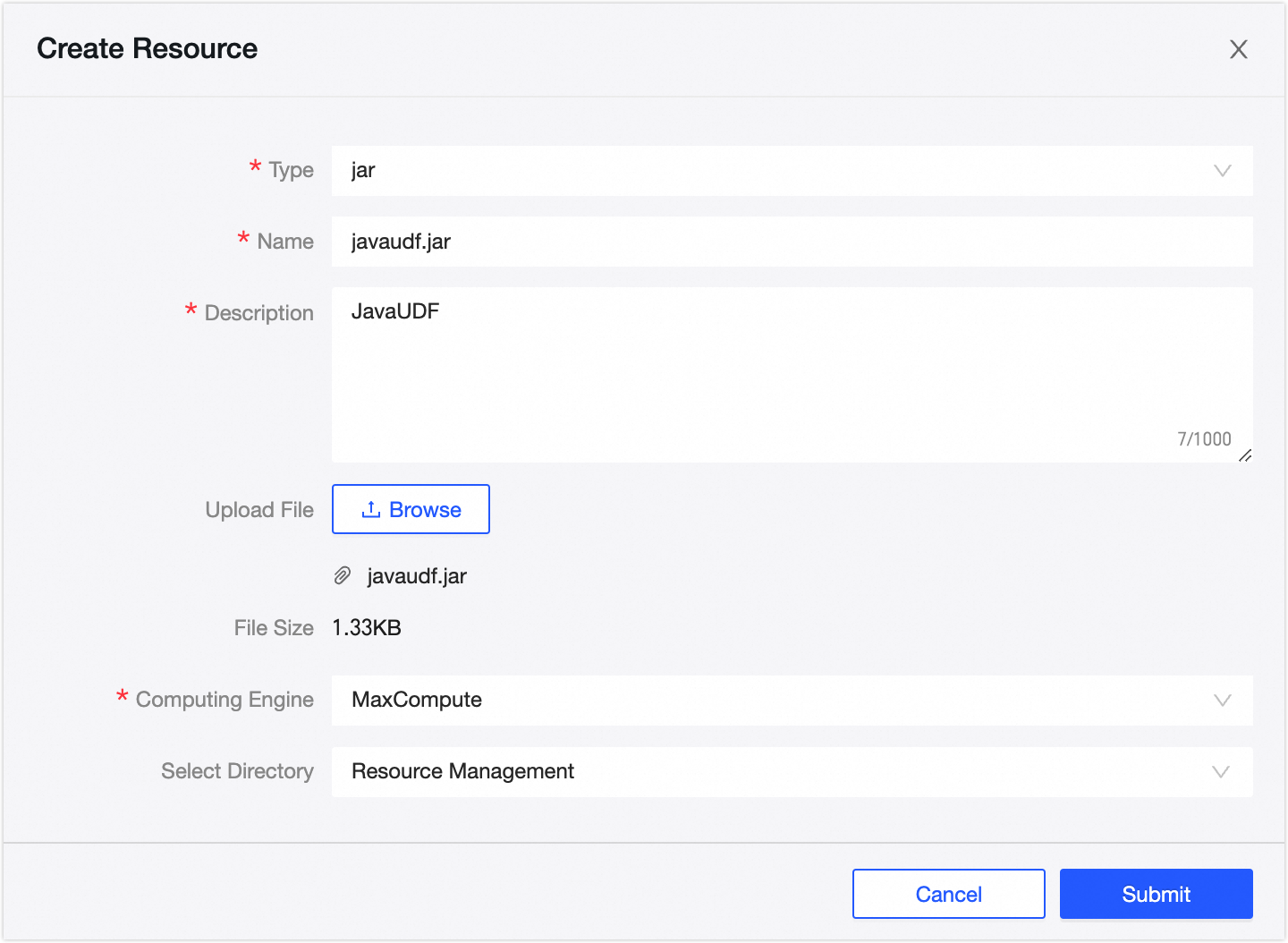
パラメーター
説明
種類
[jar] を選択します。
名前
アップロードするファイル名が、
javaudf.jarなどのファイルの種類で終わっていることを確認します。説明
リソースの説明を入力します。
ファイルをアップロード
アップロードするローカルの JAR ファイル(例:
javaudf.jar)を選択します。コンピューティングの種類
[maxcompute] を選択します。
ディレクトリを選択
JAR ファイルを保存するディレクトリを選択します。デフォルトは [リソース管理] です。デフォルト設定を保持します。
[送信] をクリックして、リソースのアップロードを完了します。
[送信の備考] ダイアログボックスで、必要なコメントを入力します。
[確認して送信] をクリックします。
オプション: 必要に応じて、リソースを本番環境に公開します。
開発 - 本番モードの場合は、リソースを本番環境に公開します。詳細については、「リリース タスクの管理」をご参照ください。
基本モードでは、正常に送信されたリソースは自動的に本番環境に入ります。
手順 2: MAXC 関数を作成する
[データ処理] タブで、左側のナビゲーションウィンドウの
 [関数管理] アイコンをクリックします。
[関数管理] アイコンをクリックします。[関数管理]
アイコンをシングルクリックし、[MAXC 関数] を選択します。[新しい関数] ダイアログボックスで、パラメーターを入力します。
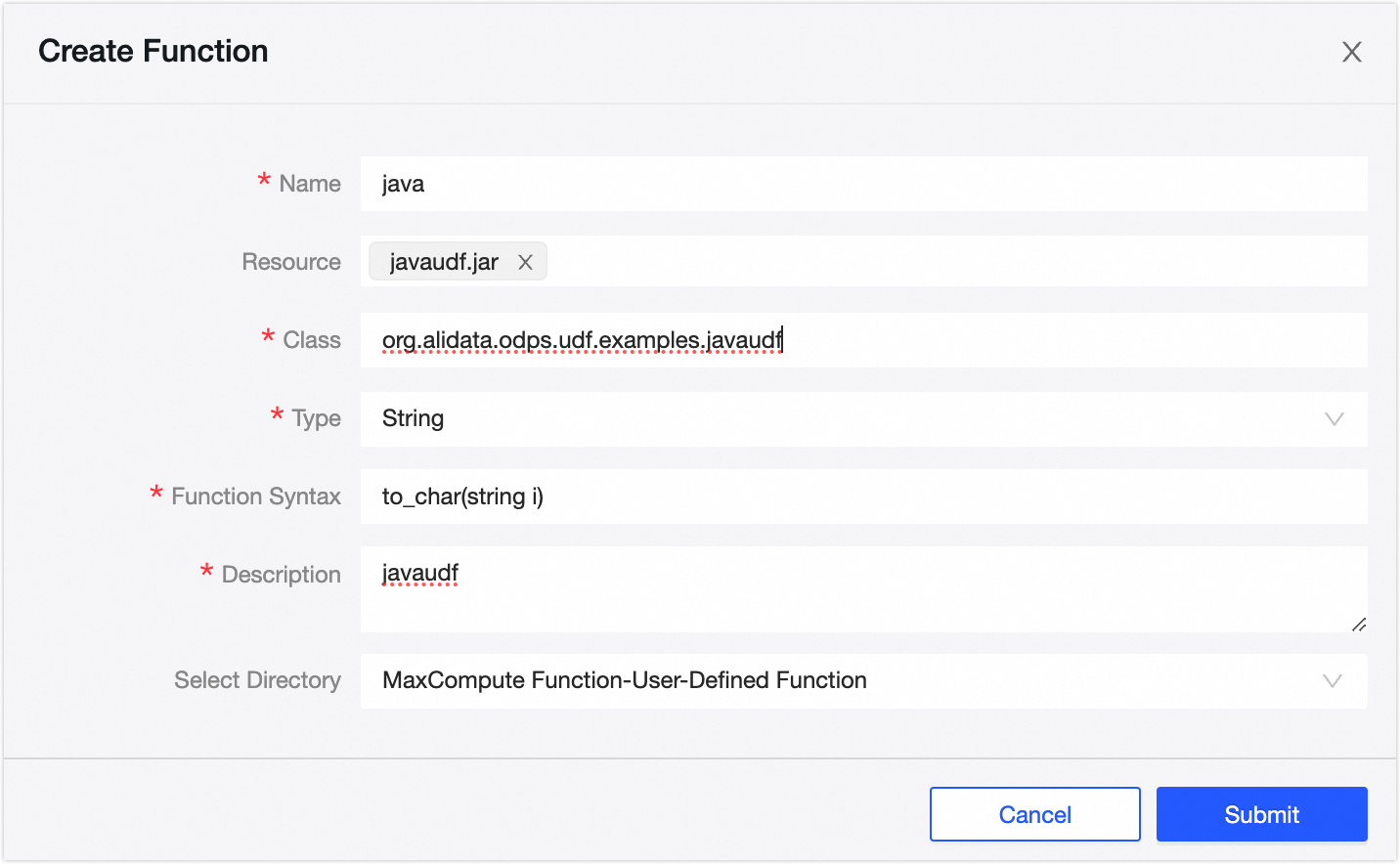
パラメーター
説明
名前
関数名を指定します(例:
Java)。リソースを選択
以前にアップロードしたリソース
javaudf.jarを選択します。クラス名
JAR ファイルのパス.クラスファイル名という形式で完全修飾クラス名を入力します(例:
org.alidata.odps.udf.examples.javaudf)。種類
関数の種類を選択します。文字列処理関数には [文字列] を選択します。
コマンド形式
関数を呼び出すための構文を定義します。文字列への変換には、
to_char(string i)の形式を使用します。使用方法のドキュメント
関数の使用方法の説明を入力します(例: 小文字に変換するための
javaudf)。ディレクトリを選択
関数のデフォルトディレクトリである [MAXC 関数 - ユーザー定義関数] を保持します。
[送信] をクリックして、関数の作成を完了します。
[送信の備考] ダイアログボックスで、関連するコメントを入力します。
[確認して送信] をクリックして、送信プロセスを完了します。
オプション: 必要に応じて、関数を本番環境に公開します。
開発 - 本番モードの場合は、関数を本番環境に公開する必要があります。ガイダンスについては、「リリース タスクの管理」をご参照ください。
基本モードでは、正常に送信された関数は本番環境で自動的に使用可能になります。
手順 3: 新しい SQL タスクを作成する
[データ処理] タブで、左側のナビゲーションウィンドウの
 [スクリプト タスク] アイコンをクリックします。
[スクリプト タスク] アイコンをクリックします。[スクリプト タスク] ページで、
アイコンをクリックし、[MAX_COMPUTE_SQL] オプションを選択します。[新しいファイル] ダイアログボックスで、必要なパラメーターを入力します。
パラメーター
説明
名前
コンピューティング タスクの名前を入力します(例:
javaudf)。スケジュールタイプ
タスクのスケジュールタイプを選択します(例: [定期タスクノード])。
説明
タスクの簡単な説明を入力します。
ディレクトリを選択
システムのデフォルトは [スクリプト タスク] ディレクトリです。
[確認] をクリックして続行します。
手順 4: Java UDF 関数を使用する
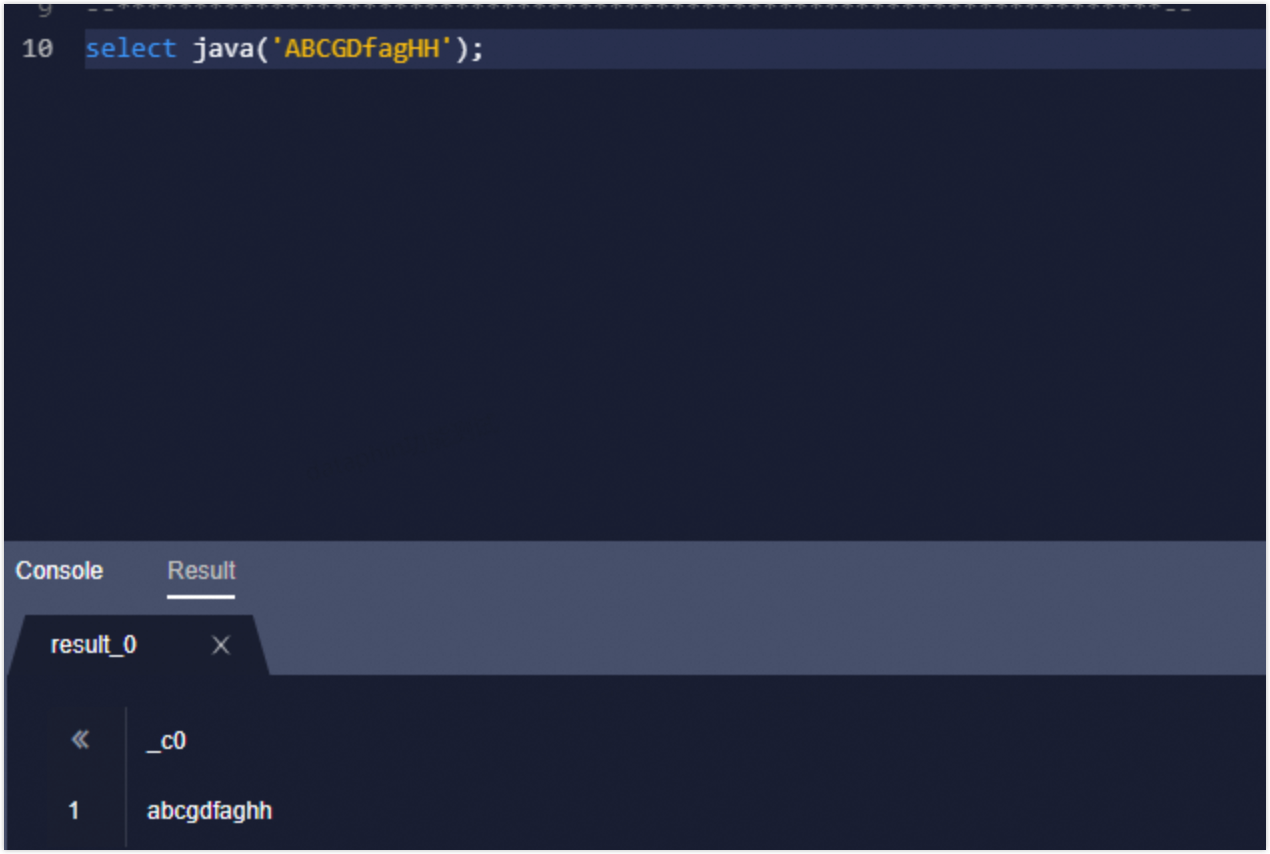
SQL タスクコードエディタで、コードを記述します(例:
SELECT java('ABCGDfagHH');)。ページの右上にある [実行] をクリックしてコードを実行し、結果を表示します。
オプション: スケジュールとメンテナンス
SQL タスクの実行を自動化するには、タスクのスケジューリングパラメーターを設定し、定期的なスケジューリングのために本番環境に公開します。
コードエディタで、[設定のスキャン] をクリックしてスケジューリングパラメーターを設定します。詳細については、「論理テーブルのスケジューリングプロパティを設定する」をご参照ください。
SQL タスクを次のように保存、送信、および公開します。
 アイコンをクリックしてコードを保存します。
アイコンをクリックしてコードを保存します。 アイコンをクリックしてコードを送信してレビューします。
アイコンをクリックしてコードを送信してレビューします。[送信の備考] ダイアログボックスで、必要なコメントを入力します。
[確認して送信] をクリックして送信を完了します。
オプション: 必要に応じて、SQL タスクを本番環境に公開します。
開発 - 本番モードの場合は、SQL タスクを本番環境に公開します。ガイダンスについては、「リリース タスクの管理」をご参照ください。
基本モードでは、正常に送信された SQL タスクは本番環境で自動的に使用可能になります。