このトピックでは、API 操作を呼び出すことによってデータを更新する方法について説明します。
1. テーブルの作成
テーブルを作成し、Object Storage Service (OSS)、MaxCompute、または Data Lake Formation (DLF) データソースの完全データをテーブルにインポートできます。
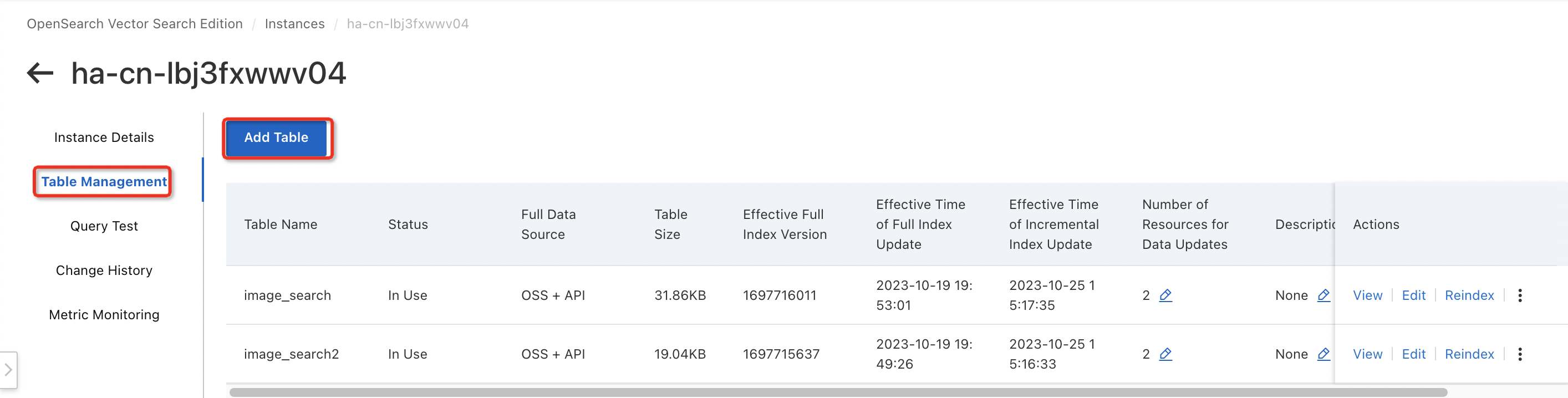
テーブルの作成方法の詳細については、以下のトピックをご参照ください。
テーブルが構成された後、テーブルのステータスが「使用中」になるまで待ちます。その後、API 操作を呼び出すことによって、テーブル内のデータを更新できます。

2. パブリックアクセスホワイトリストの構成
OpenSearch Vector Search Edition インスタンスが配置されている VPC から、同じ vSwitch を使用してインスタンスにアクセスする場合は、この手順をスキップします。
オンプレミス環境またはインターネットから OpenSearch Vector Search Edition インスタンスにアクセスする方法の詳細については、「パブリックアクセスホワイトリストを構成する」をご参照ください。
3. テーブルへのデータのプッシュ
次のサンプルコードは、SDK for Python を使用してテーブルにデータをプッシュする方法の例を示しています。
依存関係の追加:
pip install alibabacloud-ha3engine-vectorデータプッシュのデモコード:
# -*- coding: utf-8 -*-
from alibabacloud_ha3engine_vector import models, client
from Tea.exceptions import TeaException, RetryError
Config = models.Config(
endpoint="<API endpoint>", # // API エンドポイント。API エンドポイントは、インスタンスの詳細ページの API エンドポイントセクションで確認できます。 http:// プレフィックスを削除する必要があります。
instance_id="<Instance ID>", # // インスタンス ID。インスタンス ID は、インスタンスの詳細ページの左上隅で確認できます。例: ha-cn-i7*****605。
protocol="http",
access_user_name="<Username>", # // ユーザー名。ユーザー名は、インスタンスの詳細ページの API エンドポイントセクションで確認できます。
access_pass_word="<Password>" # // パスワード。パスワードは、インスタンスの詳細ページの API エンドポイントセクションで確認できます。
)
# エンジンクライアントを初期化します。
ha3EngineClient = client.Client(Config)
def push():
# ドキュメントのプッシュ先となるテーブルの名前。形式: <インスタンス ID>_<テーブル名>。
tableName = "<instance_id>_<table_name>";
try:
# ドキュメントを追加します。
# ドキュメントが既に存在する場合、指定されたドキュメントが追加される前に既存のドキュメントが削除されます。
# =====================================================
# ドキュメントの内容を更新します。
add2DocumentFields = {
"id": 1, # プライマリキーフィールドの ID。値は INT 型です。
"cate_id": "123", # この単一値フィールドの値は STRING 型です。
"vector": "a\x1Db\x1Dc\x1Dd" # この複数値フィールドの値は STRING 型です。
}
# ドキュメントの内容を add2Document 構造に追加します。
add2Document = {
"fields": add2DocumentFields,
"cmd": "add" # add コマンドは、ドキュメントが追加されることを示します。
}
optionsHeaders = {}
# ドキュメントデータをプッシュするために使用される外部構造でドキュメント操作を指定するために追加された構造。この構造には、1 つ以上のドキュメント操作を指定できます。
documentArrayList = []
documentArrayList.append(add2Document)
pushDocumentsRequest = models.PushDocumentsRequest(optionsHeaders, documentArrayList)
# データがプッシュされるドキュメントのプライマリキーフィールド。
pkField = "id"
# リクエストにデフォルトのランタイムパラメータを使用します。
response = ha3EngineClient.push_documents(tableName, pkField, pushDocumentsRequest)
print(response.body)
print(response.body)
except TeaException as e:
print(f"send request with TeaException : {e}")
except RetryError as e:
print(f"send request with Connection Exception : {e}")
if __name__ == "__main__":
push()注:
SDK for Python を使用する場合は、endpoint パラメータを指定するときに http:// プレフィックスを削除する必要があります。
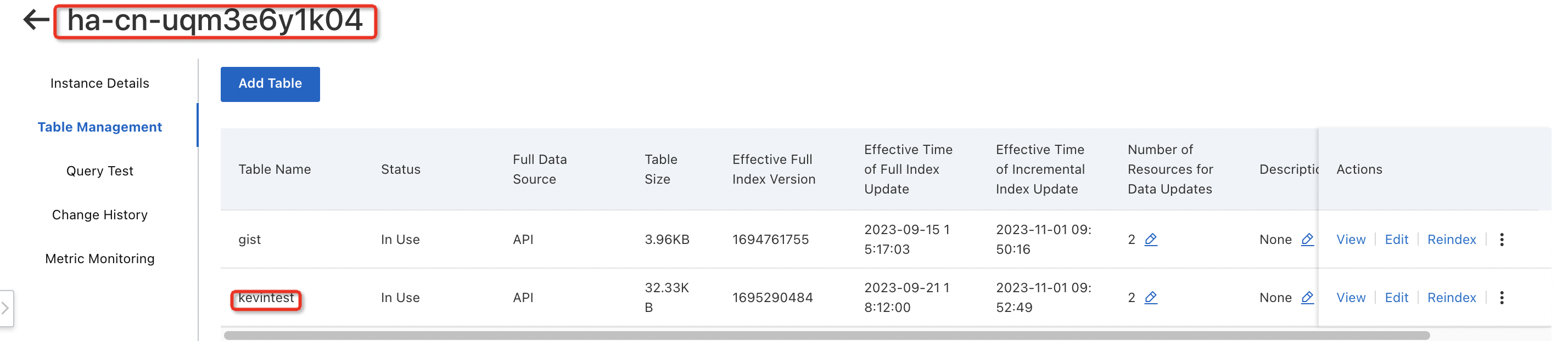
dataSourceName パラメータの値は、インスタンス ID_テーブル名という形式にする必要があります。この例では、値は ha-cn-uqm3e6y1k04_kevintest です。
応答で {"status": "OK", "code": 200} が返された場合、リクエストは成功です。
4. データの検証
プライマリキーまたはベクターを使用して、クエリテストでデータを検証します。
クエリ構文の詳細については、「プライマリキーベースのクエリ」および「ベクターベースのクエリ」をご参照ください。
SDK リファレンス
他のプログラミング言語の SDK の詳細については、「データのクエリ」をご参照ください。