ユーザーが E-MapReduce (EMR) クラスター内の特定の機密データをクエリする権限を持っているが、ユーザーに完全な機密データを表示させたくない場合は、EMR の動的データマスキング機能を有効にして、クエリ結果の機密データを動的にマスキングできます。このトピックでは、EMR の動的データマスキング機能を有効にする方法を説明し、参考としてこの機能の使用例を示します。
制限
EMR クラスターは、Data Security Guard の機密データ識別機能とデータマスキング機能のみをサポートします。
機密データ識別機能とデータマスキング機能は、特定の種類の EMR クラスターとテーブルでのみサポートされています。詳細については、「Data governance」トピックの「Data Map でプレビューできる Hive テーブルのタイプ」セクションをご参照ください。
Data Security Guard 側のメタデータは 1 日の遅延で更新されます。EMR データをマスキングしたい場合、マスキングしたい EMR データは 1 日前に作成されている必要があります。
スケジューリング用の専用リソースグループのみがサポートされています。詳細については、「スケジューリング用の専用リソースグループの課金」をご参照ください。
準備
前提条件
デフォルトでは、Data Security Guard は Alibaba Cloud アカウントにマッピングされた EMR クラスターアカウントを使用してデータをサンプリングします。EMR クラスターで Lightweight Directory Access Protocol (LDAP) または Kerberos 認証が有効になっており、Ranger または DLF-Auth を使用してテーブルの権限を管理している場合は、Alibaba Cloud アカウントと EMR クラスターアカウント間のマッピングを構成する必要があります。マッピングされた EMR クラスターアカウントが、EMR クラスター内のテーブルにアクセスするために必要な権限を持っていることを確認する必要があります。詳細については、「DataStudio (旧バージョン): EMR 計算資源を関連付ける」をご参照ください。
データの準備
EMR テーブルの作成
DataStudio ページに移動します。
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発へ] をクリックします。
Data Studio ページの DATASTUDIO ペインで、作成アイコンをクリックし、 を選択します。
ノードコードを修正し、
onefall_test_dsgテーブルを作成します。CREATE TABLE IF NOT EXISTS onefall_test_dsg ( username STRING ,gender STRING ,phone STRING ,email STRING ,card_no STRING ,address STRING ,zip_code STRING ) ROW FORMAT DELIMITED FIELDS TERMINATED BY',' ;onefall_test_dsgテーブルにテストデータをインポートします。テストデータファイル data.csv をダウンロードします。
テストデータをインポートします。
data.csv ファイルを EMR クラスターのノードにアップロードし、次の SQL 文を実行してテストデータをロードします:
LOAD DATA LOCAL INPATH '/…/data.csv' OVERWRITE INTO TABLE onefall_test_dsg;data.csv ファイルを Object Storage Service (OSS) バケットにアップロードし、次の SQL 文を実行してテストデータをロードします:
LOAD DATA INPATH 'oss://bucket-name.Endpoint/…/data.csv' OVERWRITE INTO TABLE onefall_test_dsg ;
Data Security Guard 側のメタデータの更新
Data Security Guard 側のメタデータは 1 日の遅延で更新されます。onefall_test_dsg テーブルを作成して公開した後、データマスキング操作を実行する前に翌日まで待つ必要があります。
データマスキングの構成
ステップ 1: 機密データ識別ルールの作成
DataWorks は、機密データ識別ルールを使用して EMR テーブル内の機密フィールドを識別します。データマスキングルールを構成する前に、機密データ識別ルールを構成する必要があります。詳細については、「機密データ識別ルールを構成して機密データ識別タスクを実行する」をご参照ください。
[データ識別ルール] タブに移動
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、[セキュリティセンターへ] をクリックします。
左側のナビゲーションウィンドウで、 をクリックして [データセキュリティガード] ページに移動します。
説明Alibaba Cloud アカウントに必要な権限が付与されている場合、直接データセキュリティガードページにアクセスできます。
Alibaba Cloud アカウントに必要な権限が付与されていない場合、データセキュリティガードの権限付与ページにリダイレクトされます。Alibaba Cloud アカウントに必要な権限が付与された後にのみ、データセキュリティガードの機能を使用できます。
左側のナビゲーションウィンドウで、 を選択します。[データ識別ルール] タブが表示されます。
機密データ識別ルールの構成
この例では、データ準備セクションで作成された onefall_test_dsg テーブルの gender、phone、および email フィールドを識別するための機密データ識別ルールが作成されます。
作成したい機密フィールドタイプのデータカテゴリを指定します。
[データ識別ルール] タブの左側にある [BuildInClassificationTemplate] セクションで、作成された機密フィールドタイプが属するデータカテゴリを選択します。詳細については、「機密データ識別ルールを構成して機密データ識別タスクを実行する」をご参照ください。
機密フィールドタイプを作成し、このタイプの機密データ識別ルールを構成します。
タブの右上隅にある [機密フィールドタイプ] をクリックします。機密データ識別ルールを構成できるパネルが表示されます。詳細については、「機密データ識別ルールを構成して機密データ識別タスクを実行する」をご参照ください。
説明ユーザーが機密フィールドタイプを理解しやすくするために、
gender、phone、およびemailのonefall_test_dsgテーブルのフィールド名を機密フィールドタイプとして使用できます。[機密データ識別ルール] を構成した後、右上隅の [一括公開] をクリックし、作成した機密データ識別ルールを選択して一度に公開します。

ステップ 2: データマスキング管理の構成
DataWorks では、データマスキングルールを構成して EMR テーブル内の機密フィールドをマスキングできます。詳細については、「データマスキングルールの作成」をご参照ください。
[データマスキング管理] ページに移動
[DataWorks コンソール] にログインし、[データセキュリティガード] ページに移動します。詳細については、「概要」をご参照ください。
[今すぐ試す] をクリックします。データセキュリティガードの [ホームページ] が表示されます。
左側のナビゲーションウィンドウで、 を選択します。[データマスキング管理] ページで、シナリオを作成し、そのシナリオでデータマスキングルールを構成できます。
データマスキングシナリオの作成
DataWorks は、[データ開発 / データマップ表示の非識別化]、[データ分析と表示の非識別化]、[MaxCompute エンジンのレイヤーマスキング]、[Hologres レイヤーマスキング] などの動的データマスキングシナリオを提供します。DataWorks は、[データ統合の静的非識別化] のシナリオも提供します。前述のデータマスキングシナリオはレベル 1 のデータマスキングシナリオであり、固定されており、作成、変更、または削除はできません。レベル 1 のデータマスキングシナリオに基づいて、レベル 2 のデータマスキングシナリオを構成できます。詳細については、「データマスキングシナリオの作成」をご参照ください。
この例では、[データ開発 / データマップ表示の非識別化] と [データ分析と表示の非識別化] のデータマスキングシナリオが使用されます。
レベル 1 のデータマスキングシナリオ [データ開発 / データマップ表示の非識別化] に基づいて構成されたレベル 2 のデータマスキングシナリオの名前:
development demonstrationレベル 1 のデータマスキングシナリオ [データ分析と表示の非識別化] に基づいて構成されたレベル 2 のデータマスキングシナリオの名前:
SQL analysis
データマスキングルールの作成
データマスキングシナリオを作成した後、右上隅の [マスキングルール] をクリックしてデータマスキングルールを作成できます。gender、phone、および email の機密フィールドタイプに対してデータマスキングルールを作成する手順を繰り返します。詳細については、「データマスキングルールの作成」をご参照ください。
データマスキングシナリオを選択します。
[データマスキング管理] ページの [マスキングシーン] セクションで、 の下にある [デフォルトシーン] をクリックし、ページの右上隅にある [+ マスキングルール] をクリックします。
データマスキングルールを作成します。
[データマスキングルールの作成] ダイアログボックスで、[機密フィールドタイプ]、[データマスキングルール名]、[データマスキングシナリオ]、[マスキングモード] などのパラメーターを構成します。詳細については、「データマスキングルールの作成」トピックの「データマスキングルールを構成するためのエントリ」セクションをご参照ください。
次の表に、作成された各機密フィールドタイプのデータマスキングルールの構成を示します。
パラメーター
説明
gender
email
phone
機密フィールドタイプ
gender
email
phone
データマスキングルール名
gender
email
phone
データマスキングシナリオ
development demonstrationとSQL analysisdevelopment demonstrationとSQL analysisdevelopment demonstrationとSQL analysisマスキングモード
置換する文字
置換位置
すべての文字を置換
置換位置
ランダムな値で置換
HASH
データウォーターマーキング
オフ
暗号化アルゴリズム
MDS
ソルト値
5
マスキングアウト
墨消しモード
説明他のメソッドを使用してデータをマスキングすることもできます。この例では、[置換する文字]、[HASH]、および [マスキングアウト] が使用されます。詳細については、「データマスキングルールの作成」トピックの「データマスキングメソッドの構成」セクションをご参照ください。
ステップ 3: 機密データ識別の有効化
本番環境の Data Security Guard が毎日 EMR メタデータを取得した後、Data Security Guard は DataWorks API 操作を呼び出してテーブルのサンプルデータを取得し、機密データ識別ルールに基づいて機密フィールドを識別します。この例では、機密データ識別ルールを手動で有効にして機密フィールドを識別できます。
左側のナビゲーションウィンドウで、 を選択します。[機密データ識別] ページが表示されます。
[機密データ識別] ページの左上隅にある [タスクの実行] をクリックします。[機密データ識別タスクの有効化] パネルで、パラメーターを構成します。
[タスクタイプ]: [手動タスク] に設定します。
[識別に使うアカウント]: 現在のアカウントは、データのサンプリングとスキャンに使用されます。サンプリングできるデータの範囲は、アカウントの権限によって異なります。この例では、[Alibaba Cloud アカウント] が選択されています。
[コンテンツ識別]: [コンテンツ認識] または [メタデータ認識] に設定します。この例では、[コンテンツ認識] が選択されています。
[サンプリング数量]: ビジネス要件に基づいて値を指定できます。デフォルト値の 100 を使用することをお勧めします。
[スキャン範囲]: [完全] または [部分データ] に設定します。パラメーターを [部分データ] に設定した場合、ワークスペースとデータベースを指定してスキャンする必要があるデータの範囲を決定する必要があります。
この例では、
onefall_test_dsgテーブルが使用されます。
スキャン範囲を選択した後、パネルの右下隅にある [実行] をクリックして、機密データ識別タスクを有効にします。
説明[機密データ識別] ページの [タスク実行記録] タブで、機密データ識別タスクの実行詳細を表示できます。
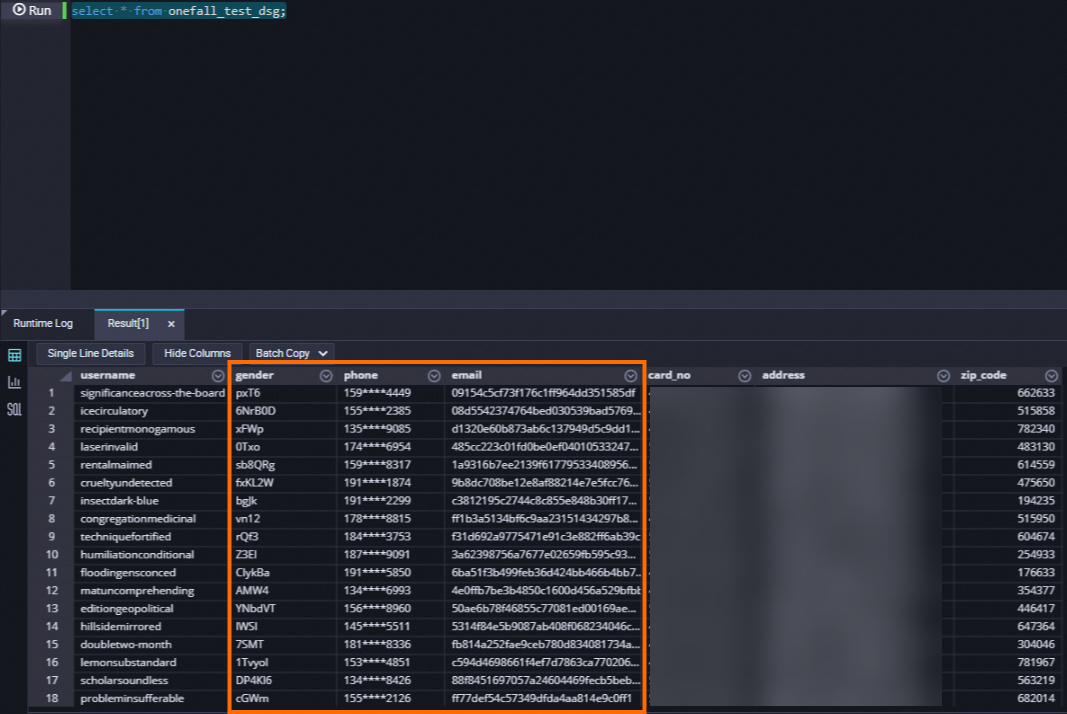
SQL 文の実行結果の表示
EMR テーブルのデータマスキング結果のプレビュー
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、[データマップへ] をクリックします。
DataMap ページの左側のナビゲーションウィンドウで
 アイコンをクリックします。表示されたページで、上部のナビゲーションバーのドロップダウンリストをクリックし、E-MapReduce を選択します。次に、検索ボックスに
アイコンをクリックします。表示されたページで、上部のナビゲーションバーのドロップダウンリストをクリックし、E-MapReduce を選択します。次に、検索ボックスに onefall_test_dsgと入力します。onefall_test_dsg テーブルの名前をクリックしてテーブルの詳細ページに移動します。次に、[データプレビュー] タブをクリックしてテーブルデータをプレビューします。
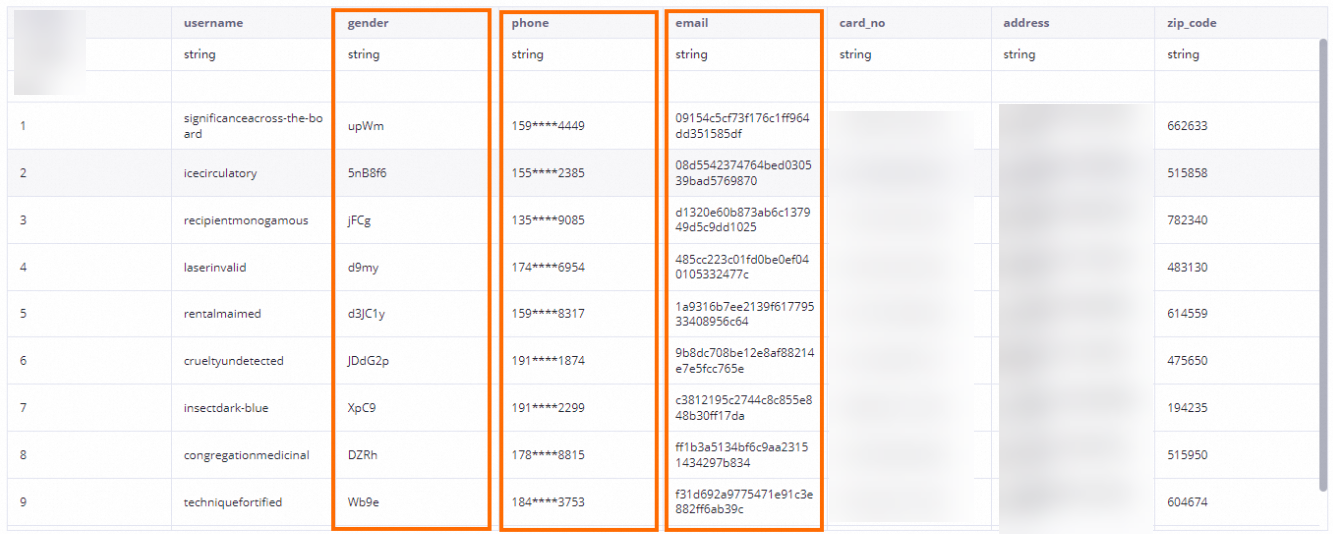
[データプレビュー] タブでは、テーブル内のフィールドは、構成された機密データ識別ルールとデータマスキングルールに基づいてマスキングされます。
Data Studio ページでのデータマスキング結果の表示
Data Studio ページでデータマスキング結果を表示できるかどうかは、Data Studio の [セキュリティ設定など] タブの [データセキュリティ] セクションにある [ページクエリ結果のデータをマスク] パラメーターの構成によって制御されます。次の手順を実行してパラメーターを構成できます:
DataStudio ページに移動します。
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発へ] をクリックします。
Data Studio ページの左側のナビゲーションウィンドウで、
 アイコンをクリックします。[設定] ページが表示されます。
アイコンをクリックします。[設定] ページが表示されます。[設定] ページで、[セキュリティ設定など] をクリックします。[データセキュリティ] セクションで [ページクエリ結果のデータをマスク] をオンにします。
クエリされたデータのマスキング効果のテスト
DataStudio ページに移動します。
DataWorks コンソールにログインします。上部のナビゲーションバーで、目的のリージョンを選択します。左側のナビゲーションウィンドウで、 を選択します。表示されたページで、ドロップダウンリストから目的のワークスペースを選択し、[データ開発へ] をクリックします。
左側のナビゲーションウィンドウで、
 アイコンをクリックします。[アドホッククエリ] ペインで、ポインターを
アイコンをクリックします。[アドホッククエリ] ペインで、ポインターを  アイコンの上に移動し、 を選択してアドホッククエリノードを作成します。
アイコンの上に移動し、 を選択してアドホッククエリノードを作成します。ノードで
onefall_test_dsgテーブルをクエリし、Data Studio ページでテーブルのマスキング効果を表示します。SELECT * FROM onefall_test_dsg;