DataWorks のデータ分析機能は、データ分析と共有のためのツールです。さまざまなデータソースに接続し、SQL クエリを実行し、スプレッドシートを使用して日常的なデータ抽出と分析を管理できます。このトピックでは、MaxCompute エンジンと SQL クエリを使用してパブリックデータセットを分析する方法を説明し、データ分析の基本機能を紹介します。
機能
DataWorks は、さまざまなビジネスシナリオ向けの公開データセットを提供します。 このトピックでは、Alibaba e-commerce データセット(commerce_ali_e_commerce テーブル)を使用して、データ分析機能の使用を開始する方法を説明します。
-
Alibaba eコマースデータセット:さまざまな期間における Taobao の注文詳細の統計情報が含まれています。
-
この表には、約 100 万人のユーザーを対象に
November 25, 2017からDecember 3, 2017までの期間に行われた、クリック、購入、カート追加、お気に入り登録などのランダムなアクションが記録されています。 -
ユーザー数:
987,994。製品数:4,162,024。総アクション数:100,150,807。
-
-
データ分析機能の詳細については、「データ分析」をご参照ください。
-
パブリックデータセットは、次のリージョンで利用できます:中国 (上海)、中国 (北京)、中国 (深圳)、中国 (杭州)、中国 (成都)、中国 (張家口)、中国 (ウランチャブ)。
権限
-
データ分析に必要な権限が必要です。権限の完全なリストについては、「データ分析のプリセットロールの権限」をご参照ください。
-
ユーザーにロールを付与する方法については、「ワークスペースメンバーの追加とロールおよび権限の管理」をご参照ください。
前提条件
MaxCompute データソースが設定済みである必要があります。詳細については、「MaxComputeコンピューティングリソースのバインド」をご参照ください。
SQL クエリへのアクセス
DataWorks コンソールにログインします。 左側のナビゲーションウィンドウで、 を選択します。 表示されるページで、ドロップダウンリストから目的のワークスペースを選択し、[SQLクエリに移動] をクリックします。
ステップ1:データのクエリ
この例では、さまざまな期間の Taobao の注文詳細を含む Alibaba e コマースデータセット (commerce_ali_e_commerce) を使用します。SQL Query 機能を使用してデータセットのクエリと並べ替えを行い、その結果を分析して共有します。
-
SQL Query に移動します。
次のいずれかの方法でアクセスできます。
-
Temporary Fileを作成します。
左側のペインで、My Files の横にある
 アイコンをクリックし、Create File を選択して、プロンプトに従って SQL クエリファイルを作成します。SQL クエリファイルを作成するその他の方法については、「SQL クエリ (旧)」をご参照ください。説明
アイコンをクリックし、Create File を選択して、プロンプトに従って SQL クエリファイルを作成します。SQL クエリファイルを作成するその他の方法については、「SQL クエリ (旧)」をご参照ください。説明-
このトピックでは、DataWorks が提供する公開データセットを使用します。 初めて SQL Query にアクセスすると、Welcome Page ページが表示されます。 このページで Go to DataAnalysis > [MaxCompute] をクリックすると、Alibaba eコマースデータセット (
commerce_ali_e_commerce) のクエリを生成できます。 -
さらに多くの公開データセットを検索するには、に移動し、Public Data ディレクトリを検索します。
-
-
クエリの Data Source を選択します。
一時ファイルのエディターで、右上隅の
 アイコンをクリックします。クエリのワークスペース、エンジン、データソースを選択します。この例では、先ほど設定した MaxCompute データソースを選択します。
アイコンをクリックします。クエリのワークスペース、エンジン、データソースを選択します。この例では、先ほど設定した MaxCompute データソースを選択します。 -
コードを編集して実行します。
コードエディタで、次のコードを編集して実行します。

このクエリは、パブリックデータセットを使用して、期間別に Taobao の注文をカウントし、ソートします。
SET odps.namespace.schema = true ; SELECT CASE WHEN CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) >= 0 AND CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) <= 3 THEN '00:00-03:00' WHEN CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) >= 4 AND CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) <= 7 THEN '04:00-07:00' WHEN CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) >= 8 AND CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) <= 11 THEN '08:00-11:00' WHEN CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) >= 12 AND CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) <= 15 THEN '12:00-15:00' WHEN CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) >= 16 AND CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) <= 19 THEN '16:00-19:00' WHEN CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) >= 20 AND CAST(SUBSTR(behavior_time, 12, 2) AS BIGINT) <= 23 THEN '20:00-23:00' END AS order_time ,COUNT(*) AS order_count FROM bigdata_public_dataset.commerce.commerce_ali_e_commerce GROUP BY order_time ORDER BY COUNT(*) DESC LIMIT 100 ; -
クエリ結果を表示します。
 アイコンをクリックして、SQL コードを実行します。
アイコンをクリックして、SQL コードを実行します。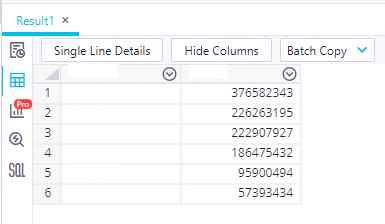
ステップ2:データの分析
ステップ1 のクエリ結果ページで、左側にある ![]() アイコンをクリックし、次に編集アイコン
アイコンをクリックし、次に編集アイコン ![]() をクリックすると、グラフ編集ページが開きます。ビジネス要件に基づいて、グラフの情報を編集できます。
をクリックすると、グラフ編集ページが開きます。ビジネス要件に基づいて、グラフの情報を編集できます。
ステップ3:データの共有
SQL クエリの結果をスプレッドシートにエクスポートし、他のユーザーとオンラインで共同作業することで、結果を共有できます。
-
クエリ結果をエクスポートします。
ステップ 1 では、クエリ結果ページで右側の
 アイコンをクリックし、ドロップダウンメニューから Workbook and share を選択します。
アイコンをクリックし、ドロップダウンメニューから Workbook and share を選択します。 -
Spreadsheet ページに移動します。
Spreadsheet ページでは、クエリ結果を同期できます。スプレッドシートの操作の詳細については、「スプレッドシート」をご参照ください。
-
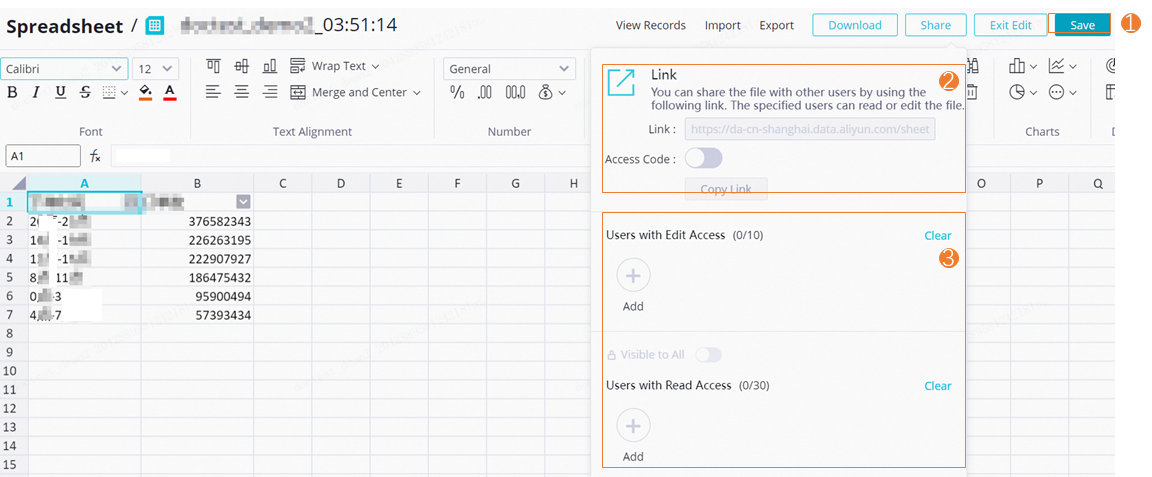
クエリ結果を共有します。
ページの右上隅で、Share をクリックします。受信者は、URL またはアクセスコードを使用してスプレッドシートにアクセスできます。受信者には編集権限または閲覧のみの権限を付与できます。
次のステップ
-
SQL クエリの詳細については、「SQL クエリ (旧)」をご参照ください。
-
スプレッドシートの操作の詳細については、「スプレッドシート」をご参照ください。