DataAnalysis の SQL クエリ機能では、複数のデータソース(MaxCompute、Hologres、EMR など)に対して SQL ステートメントを記述・実行でき、DataWorks コンソールを離れることなく結果をエクスポートまたは可視化できます。
DataWorks では、最新の機能と向上した操作性を提供するため、DataAnalysis の新バージョンをご利用いただくことを推奨します。
サポート対象のデータソース
SQL クエリは、以下のデータソースをサポートしています:MaxCompute、Hologres、EMR、CDH、StarRocks、ClickHouse、SelectDB、Doris、AnalyticDB for MySQL 3.0、AnalyticDB for PostgreSQL、Tablestore、MySQL、PostgreSQL、Oracle、SQL Server。
利用可能なデータソースは、ワークスペースに追加済みのものに限られます。
前提条件
開始する前に、以下の条件を満たしていることを確認してください。
クエリ対象のデータソースを含む DataWorks ワークスペースへのアクセス権限があること。管理者に連絡し、Data Analyst、Model Designer、Developer、O&M、Workspace Administrator、または Project Owner のロールでワークスペースメンバーとして追加してもらう必要があります。
その ワークスペース 内の データソース の権限(下記のデータソース の権限を参照)
データソースの権限
データソースの範囲
アクセス権限を持つワークスペースからのみデータをクエリできます。
ID アクセスモード
DataAnalysis では、データソースへのアクセスに以下の 2 種類の ID モードをサポートしています。
| アクセス ID モード | 説明 | サポート対象のデータソース | アクセスの取得方法 |
|---|---|---|---|
| 実行者 ID | 現在 DataWorks にログイン中の Alibaba Cloud アカウント。 | MaxCompute および Hologres | 「MaxCompute プロジェクト管理者」または「Hologres インスタンス管理者」に、メンバーのアクセス権限を付与するよう依頼してください。 |
| データソースのデフォルトアクセス ID | データソース作成時に設定されたアクセス ID。 | すべてのデータソース | Workspace Administrator 権限を持つユーザーに依頼し、現在の Alibaba Cloud アカウントへのアクセス権限付与を実施してもらいます。 |
MaxCompute プロジェクトで IP ホワイトリストによるアクセス制御が有効になっている場合、DataAnalysis のホワイトリストを MaxCompute プロジェクトの IP ホワイトリストに追加してください。
SQL クエリの起動
DataWorks データ分析にログインし、対象のリージョンに切り替えて、[データ分析に入る] をクリックします。
ナビゲーションバーに 新規 DataAnalysis へ移動 と表示されている場合、現在はレガシ版 DataAnalysis ページにアクセスしています。
ナビゲーションバーに レガシ版 DataAnalysis に戻る と表示されている場合、クリックしてレガシ版ページに戻ります。(非推奨)
ステップ 1:フォルダの追加
クエリ対象のデータソースおよびテーブルを整理するためにフォルダを追加します。フォルダを追加すると、そのフォルダ内のテーブルを閲覧したり、テーブルスキーマを確認したり、フォルダツリーから直接 SQL ステートメントを生成したりできます。
SQL 分析ページで、フォルダ一覧上部の検索ボックス右側にある
 アイコンをクリックします。
アイコンをクリックします。追加するデータセットの種類を選択します。
データセットの種類 説明 Data Map - メタデータ Data Map で収集されたテーブルメタデータです。各データソースまたは計算リソースが 1 つのデータセットになります。 Data Map - データアルバム データアルバムは、テーマごとにテーブルをグループ化したものです。各データアルバムが 1 つのデータセットになります。 マイお気に入り Data Map で「お気に入り」に登録したテーブルです。 マイ MaxCompute テーブル 現在ログイン中のアカウントが所有するすべての MaxCompute テーブルです。 パブリックテーブル パブリックデータセット(MaxCompute が提供)で、テストデータの生成に役立ちます。
最大 12 個のデータセットを追加できます。不要になったデータセットは削除して、上限を超えないようにしてください。
ステップ 2:SQL クエリの作成
データカタログに基づくクエリ
左側のフォルダツリーで、「マイ MaxCompute テーブル」などの追加済みデータセットを開きます。
分析対象のテーブルを右クリックし、SQL ステートメントの生成 を選択します。推奨される SQL ステートメントを含む一時ファイルが生成されます。
必要に応じて SQL ステートメントを編集し、保存 をクリックして マイファイル に保存します。
データソースに基づくクエリ
左側のフォルダツリーで マイファイル の上にマウスを置き、ファイル作成用の
 アイコンをクリックします。
アイコンをクリックします。新規ファイルに SQL ステートメントを記述し、マイファイル に保存します。
DataWorks では、アカウントに権限のある MaxCompute テーブル名について、入力中に自動補完が有効になります。
共有 SQL ファイルに基づくクエリ
左側のフォルダツリーで、他のユーザーのファイル をクリックして、他のユーザーが共有した SQL ファイルを閲覧します。ファイルを開いた後、詳細パネルで SQL のコピー をクリックします。
パブリックデータセットに基づくクエリ
パブリックデータセットを追加した後、そのデータセットをクリックします。詳細パネルの上部バーからエンジンを選択し、SQL ステートメントの生成 をクリックします。パブリックデータセットはテスト目的専用です。
ステップ 3:クエリエンジンの構成とクエリの実行
SQL エディターの右上隅にある
 アイコンをクリックし、クエリエンジンを構成します。
アイコンをクリックし、クエリエンジンを構成します。構成項目 説明 ワークスペース 実行エンジンが配置されているワークスペースです。ワークスペースへのアクセス権限があることを確認してください。ない場合は、ワークスペース管理者に連絡し、ワークスペースメンバーとして追加してもらいます。 データソースの種類 実行エンジンの種類です。SQL ステートメント内でプロジェクトが指定されていない場合、エンジンは構成済みのデータソースをデフォルトで使用します。 データソース名 実行エンジンの名前です。 アクセス ID モード 実行者 ID(MaxCompute および Hologres のみ対応。メンバーシップおよび SELECT 権限が必要)または データソースのデフォルトアクセス ID(すべてのデータソースに対応。構成済み ID と異なるアカウントを使用する場合は、アカウントへのアクセス権限付与が必要)のいずれかを選択します。 すべて実行 をクリックして全文を実行するか、一部を選択して 選択部分を実行 をクリックします。
MaxCompute SQL の場合、実行前に推定コストが表示されます。ツールバーの その他 > コスト推定 から、いつでもコスト推定を確認できます。
実行後、クエリ結果ページで 実行ログ、実行結果、および対応する SQL を確認します。
結果パネルの右上隅にあるボタンで、並列表示と上下表示のレイアウトを切り替えられます。
ステップ 4:クエリ結果の可視化
クエリ結果の左側ツールバーでチャートボタンをクリックすると、結果から自動的に可視化が生成されます。
チャート上部の Copilot ボタンをクリックして、DataWorks Copilot Ask 機能をお試しください。
ステップ 5:エクスポートと共有
クエリ結果をローカルファイル、OSS、MaxCompute テーブル、ワークブック、または DingTalk Sheet にエクスポートできます。
大規模なデータセットをデータソース間で移動する場合は、より信頼性の高いデータ移行のために、Data Integration 内の オフライン同期タスク を使用してください。
ローカルファイル
CSV、TXT、XLS 形式でダウンロードできます。
MaxCompute から大量のデータをダウンロードする場合、SQL 実行モードを [実行して一時テーブルを生成] に変更します。[SQLクエリ]メニューの左下の隅にあるアイコンをクリックします。
| 項目 | 説明 |
|---|---|
| ダウンロード制限 | サポートされているのは MaxCompute および EMR エンジンのみです。詳細については、「ダウンロード可能なデータ行数」をご参照ください。MaxCompute プロジェクトでデータ保護メカニズムが有効になっている場合、ダウンロードは失敗します。「クエリ結果やダウンロードオプションが制限されるのはなぜですか。 |
| ダウンロード範囲 | テーブルに表示されるデータのみ は、現在表示中のページ(最大 10,000 件)のみをダウンロードします。すべてのデータ は、ダウンロード制限内での全クエリ結果をエクスポートします。 |
| ダウンロード方法 | 承認なしでダウンロード(デフォルト、リクエスト不要)。承認後にダウンロード は、Fraud Detection ルール の設定およびダウンロードリクエストの提出が必要であり、DataWorks Enterprise Edition のみで利用可能です。 |
Object Storage Service (OSS)
CSV、テキスト、ORC、Parquet 形式で Object Storage Service (OSS) バケットに結果をエクスポートできます。大規模なデータのアーカイブや、他のクラウドサービスとの統合に適しています。
初回使用時は、DataWorks が OSS リソースにアクセスできるよう権限付与を行ってください: ファイルパス のドロップダウンから ワンクリック権限付与 リンクをクリックし、RAM 認可を完了するための指示に従ってください。
| 構成項目 | 説明 |
|---|---|
| ファイルパス | フォルダアイコンをクリックして、出力ファイルの OSS バケットおよびフォルダを選択します。 |
| ファイル名 | システムにより自動生成されます。必要に応じて編集できます。 |
| テキスト形式 | エクスポート形式:csv、text、orc、または parquet。 |
| 区切り文字 | 列区切り文字。デフォルト:カンマ (,)。 |
| エンコーディング形式 | ファイルエンコーディング:UTF-8 または GBK。 |
| CU | エクスポートタスクに使用するコンピューティングユニット (CU)。デフォルト:1 CU。 |
| リソースグループ | エクスポートタスクに使用するサーバーレスリソースグループです。空欄の場合は、DataAnalysis > システム管理 で構成済みのデータ統合リソースグループが使用されます。 |
OK をクリックしてエクスポートを開始します。タスクページで進行状況、実行ログ、および構成を確認できます。タスクが成功した後、OSS コンソールからエクスポートされたファイルをダウンロードできます。
MaxCompute テーブル
結果を MaxCompute テーブルに直接保存できます(ローカルダウンロードや再アップロードは不要)。必要に応じてテーブルのライフサイクルを設定できます。
このオプションは、MaxCompute エンジンをクエリ対象とする場合にのみ表示されます。
ワークブック
結果をワークブックに保存して、さらに データ分析 を行ったり、最新の分析結果を他者と共有 したりできます。
DingTalk Sheet
結果を DingTalk Sheet にエクスポートします。
その他の操作
SQL ファイルのバージョン管理
SQL ファイル編集ページの上部ツールバーで、その他 > バージョン をクリックすると、自動保存されたバージョンと手動保存されたバージョンを比較し、保存したいバージョンを選択できます。
コードの検索
フォルダツリーの上部で ![]() アイコンをクリックし、キーワードを入力して SQL ファイル全体を検索できます。DataWorks Standard Edition 以降で利用可能です。
アイコンをクリックし、キーワードを入力して SQL ファイル全体を検索できます。DataWorks Standard Edition 以降で利用可能です。
実行履歴の表示
フォルダツリーの上部で ![]() アイコンをクリックすると、過去の SQL クエリ実行記録を表示できます。
アイコンをクリックすると、過去の SQL クエリ実行記録を表示できます。
よくある質問
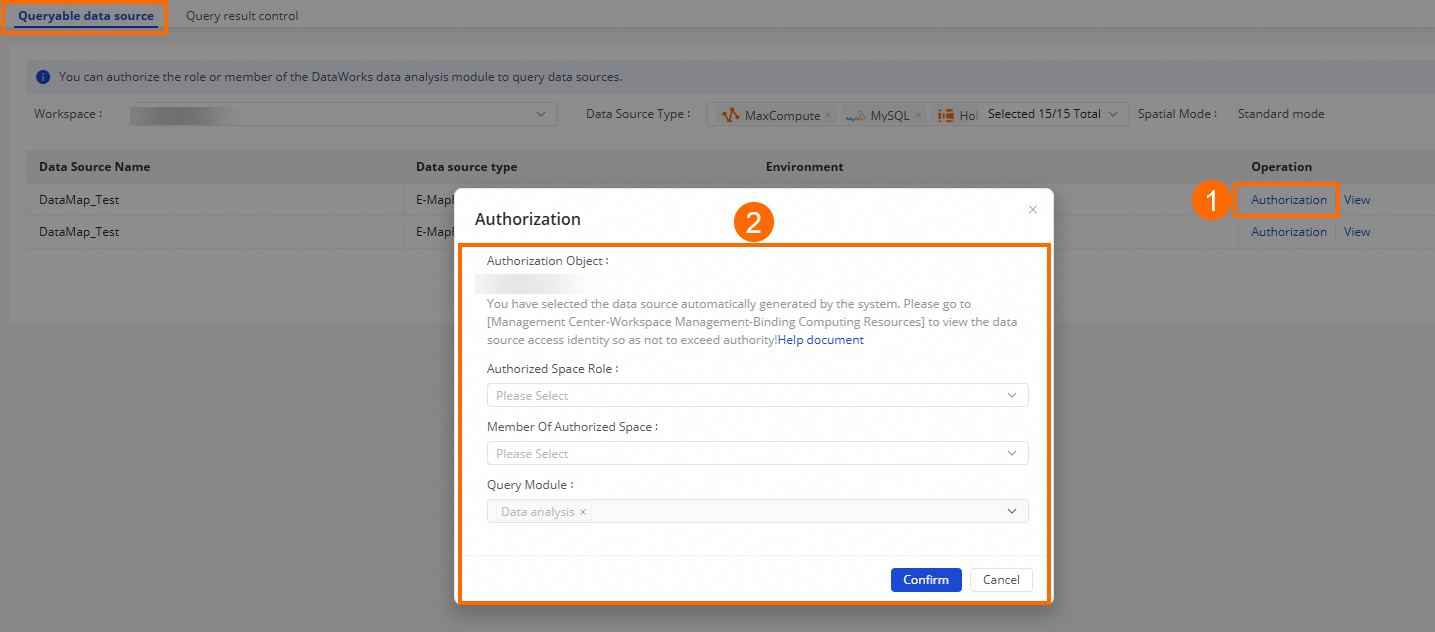
データソースのデフォルトアクセス ID に権限を付与するにはどうすればよいですか?
DataWorks コンソール にログインします。上部ナビゲーションバーで対象リージョンを選択し、左側ナビゲーションウィンドウから データガバナンス > セキュリティセンター を選択し、セキュリティセンターへ移動 をクリックします。
左側ナビゲーションウィンドウで セキュリティポリシー > データクエリおよび分析制御 をクリックします。
対象ワークスペースに切り替え、該当データソースを見つけ、権限付与 をクリックしてアクセス権限を付与します。
「このノードは専用リソースグループでのみ実行可能です」というエラーで SQL クエリが失敗するのはなぜですか?
DataAnalysis > その他 > システム管理 に移動し、エンジンの スケジュールリソースグループ および データ統合リソースグループ を構成します。
クエリ結果やダウンロードオプションが制限されるのはなぜですか?
デフォルトでは結果の一部のみが表示されることがあります。制限を調整するには、以下の手順を実行します。
DataWorks コンソール にログインします。上部ナビゲーションバーで対象リージョンを選択し、左側ナビゲーションウィンドウから データガバナンス > セキュリティセンター を選択し、セキュリティセンターへ移動 をクリックします。
左側ナビゲーションウィンドウで セキュリティポリシー > データクエリおよび分析制御 をクリックします。
クエリ結果制御 タブで、単一表示レコードの最大値、単一コピー・レコードの最大値、単一ダウンロード・レコードの最大値、および ダウンロードの許可 を調整します。

詳細については、「データクエリおよび分析制御」をご参照ください。