このガイドでは、コードの再利用、データセットのマウント、パラメーター管理などのエンジニアリングプラクティスを通じて開発効率を向上させる方法や、MaxCompute Spark、EMR Serverless Spark、AnalyticDB for Spark などのコンピュートエンジンへの接続に関するベストプラクティスおよびデバッグ手法について説明します。
まず、「基本的なノートブック開発」をお読みになることを推奨します。
開発環境と本番環境
DataWorks Notebook はスケジュール可能な開発・分析ツールです。これは、以下の 2 種類の実行環境で動作することを意味します。
開発環境:DataStudio のノートブックノード編集ページでセルを実行すると、コードが個人用開発環境インスタンス内で直接実行されます。この環境は、コードロジックの迅速な検証およびデバッグに使用します。
本番環境:ノートブックノードをコミットして公開すると、定期的なスケジューリング、データバックフィル、またはその他の類似アクションによって実行がトリガーされます。コードは分離された一時的なタスクインスタンスで実行されます。この環境は、安定かつ信頼性の高い本番運用に使用します。
これらの 2 つの環境間には機能面で大きな違いがあるため、効率的な開発を行うにはその違いを理解することが重要です。
クイックリファレンス:開発環境と本番環境の比較
機能 | 開発環境 (セルの実行) | 本番環境 (スケジュール実行) |
プロジェクトリソースの参照 ( |
| 自動的に有効になります。 |
データセットの読み書き (OSS/NAS) | 個人用開発環境でデータセットをマウントします。 | スケジューリング構成でデータセットをマウントします。 |
ワークスペースパラメーターの参照 ( | サポートされています。テキスト置換はコード実行前に自動的に行われます。 | サポートされています。テキスト置換はタスク実行前に自動的に行われます。 |
Spark セッション管理 | デフォルトでは、Spark セッションは非アクティブ状態が 2 時間続くと自動的に解放されます。 | 各タスクインスタンスごとに短期間のセッションが作成され、タスク終了時に破棄されます。 |
本番環境でのコードおよびデータの再利用
プロジェクトリソース (.py ファイル) の参照
コードをよりモジュール化し、再利用性および保守性を高めるために、共通の関数やクラスを独立した .py ファイルにまとめます。その後、##@resource_reference{"custom_name.py"} 構文を使用して、これらのファイルを MaxCompute リソースとして参照できます。
Python リソースの作成と公開
DataWorks DataStudio の左側ナビゲーションウィンドウで、
 をクリックし、Resource Management に移動します。
をクリックし、Resource Management に移動します。Resource Management のディレクトリツリーで、対象ディレクトリを右クリックするか、右上隅の + をクリックします。New Resource > [MaxCompute Python] を選択し、ファイル名を
my_utils.pyとします。Document Content セクションで、Online Editing をクリックし、ユーティリティ関数のコードをコードエディタに貼り付け、Save をクリックします。
# my_utils.py def greet(name): return f"Hello, {name} from resource file!"ツールバーで Save をクリックし、次に Publish をクリックしてリソースを公開します。これにより、リソースが開発環境および本番環境の両方のタスクで利用可能になります。
ノートブックでのリソース参照
ノートブックの Python セルの先頭行で、公開済みのリソースを参照するために
##@resource_reference構文を使用します。##@resource_reference{"my_utils.py"} # リソースが my_folder/my_utils.py のようなサブディレクトリにある場合でも、 # ディレクトリパスを含めずにファイル名のみで参照します:##@resource_reference{"my_utils.py"} from my_utils import greet message = greet('DataWorks') print(message)開発環境でのデバッグ
Python セルを実行します。出力結果は次のとおりです。
Hello, DataWorks from resource file!重要開発環境でのデバッグ中に、システムは
##@resource_reference宣言を検出し、Resource Management から対応するファイルを個人ディレクトリ内のworkspace/_dataworks/resource_referencesパスに自動的にダウンロードし、コードからアクセスできるようにします。ModuleNotFoundErrorが発生した場合は、エディタツールバーの 再起動 ボタンをクリックしてリソースを再読み込みし、再度試してください。本番環境への公開と検証
Save および Publish をクリックしてノートブックノードを公開した後、Operation and Maintenance Center > Auto Triggered Task に移動し、[テスト] をクリックしてタスクを実行します。タスクが成功すると、ログに
Hello, DataWorks from resource file!が出力されます。重要There is no file with id ...エラーが発生した場合は、Python リソースが本番環境に公開されていることを確認してください。
詳細については、「MaxCompute リソースと関数」をご参照ください。
データセットの読み書き (OSS/NAS)
ノートブックタスクの実行中、OSS または NAS に格納された大規模ファイルを簡単に読み書きできます。
開発環境でのデバッグ
データセットのマウント:個人用開発環境の詳細ページで、ストレージ設定 > データセット に移動して構成します。
コードでのデータセットへのアクセス:データセットは個人用開発環境内の特定のマウントパスにマウントされます。コード内でこのパスを直接読み書きできます。
# データセットが /mnt/data/dataset パスにマウントされていると仮定します。 import pandas as pd # マウントパスを直接使用します。 file_path = '/mnt/data/dataset/testfile.csv' df = pd.read_csv(file_path) # PyODPS を使用して MaxCompute にデータを書き込みます。 o = %odps o.write_table('mc_test_table', df, overwrite=True) print(f"MaxCompute テーブル mc_test_table にデータを正常に書き込みました。")
本番環境へのデプロイメント
データセットのマウント:ノートブックノード編集ページで、右側ナビゲーションウィンドウの Scheduling Settings > Scheduling Policy に移動し、同じデータセットを追加します。
コードでのデータセットへのアクセス:ノードをコミットして公開すると、データセットが本番環境にマウントされます。コード内で同じマウントパスを使用してアクセスします。
# データセットが /mnt/data/dataset パスにマウントされていると仮定します。 import pandas as pd # マウントパスを直接使用します。 file_path = '/mnt/data/dataset/testfile.csv' df = pd.read_csv(file_path) # PyODPS を使用して MaxCompute にデータを書き込みます。 o = %odps o.write_table('mc_test_table', df, overwrite=True) print(f"MaxCompute テーブル mc_test_table にデータを正常に書き込みました。")
詳細については、「個人用開発環境でのデータセットの使用」をご参照ください。
ワークスペースパラメーターの使用
この機能は、DataWorks Professional Edition 以上でのみ利用可能です。
DataWorks では、既存のスケジューリングパラメーターを拡張するワークスペースパラメーターを提供しています。これらのパラメーターにより、タスクおよびノード間でグローバル設定を再利用し、環境を隔離できます。SQL セルまたは Python セルで、${workspace.param} 形式を使用してワークスペースパラメーターを参照できます。ここで、param はワークスペースパラメーターの名前です。
1. ワークスペースパラメーターの作成:開始前に、DataWorks で Operation and Maintenance Center > Scheduling Settings > Workspace Parameters に移動して、必要なパラメーターを作成します。
2. ワークスペースパラメーターの参照:
SQL セルでワークスペースパラメーターを参照します。
SELECT '${workspace.param}';セルを実行すると、ワークスペースパラメーターの解決済み値が出力されます。
Python セルでワークスペースパラメーターを参照します。
print('${workspace.param}')セルを実行すると、ワークスペースパラメーターの解決済み値が出力されます。
詳細については、「ワークスペースパラメーターの使用」をご参照ください。
マジックコマンドによるコンピュートエンジンとの連携
マジックコマンドは、% または %% をプレフィックスとする特殊コマンドであり、Python セルと各種コンピュートリソースとの連携を簡素化します。
MaxCompute への接続
MaxCompute コンピュートリソースに接続する前に、MaxCompute コンピュートリソースをバインドしていることを確認してください。
%odps:PyODPS エントリオブジェクトの取得このコマンドは、現在の MaxCompute プロジェクトにバインドされた認証済みの PyODPS オブジェクトを返します。AccessKey をコード内にハードコードしないため、MaxCompute との連携にはこの方法を推奨します。
マジックコマンドを使用して MaxCompute 接続を作成します。
%odpsを入力します。右下隅に MaxCompute コンピュートリソースセレクターが表示され、自動的にコンピュートリソースが選択されます。右下隅の MaxCompute プロジェクト名をクリックしてプロジェクトを切り替えられます。o=%odps取得した MaxCompute コンピュートリソースを使用して、PyODPS スクリプトを実行します。
たとえば、現在のプロジェクト内のすべてのテーブルを取得するには、次のとおりです。
with o.execute_sql('show tables').open_reader() as reader: print(reader.raw)
%maxframe:MaxFrame 接続の確立このコマンドは MaxFrame セッションを作成し、MaxCompute 向けの分散型 pandas ライクなデータ処理機能を提供します。
# MaxCompute MaxFrame セッションへの接続とアクセス mf_session = %maxframe df = mf_session.read_odps_table('your_mc_table') print(df.head()) # 開発およびデバッグ後は、手動でセッションを破棄してリソースを解放します mf_session.destroy()
Spark コンピュートリソースへの接続
DataWorks Notebook は複数の Spark エンジンへの接続をサポートしています。これらのエンジンは、接続方法、実行コンテキスト、リソース管理の点で異なります。
単一のノートブックノードでは、マジックコマンドを使用して一度に 1 種類のコンピュートリソースにのみ接続できます。
エンジンの比較
機能 | MaxCompute Spark | EMR Serverless Spark | AnalyticDB for Spark |
コマンド |
|
|
|
説明 コマンド実行後、ノートブックカーネル全体の実行コンテキストがリモート PySpark 環境に切り替わります。その後、以降のセルに直接 PySpark コードを記述できます。 | |||
前提条件 | MaxCompute コンピュートリソースをバインドします。 | EMR コンピュートリソースをバインドし、Livy Gateway を作成します。 | ADB Spark コンピュートリソースをバインドします。 |
開発モード | Livy セッションを自動的に作成または再利用します。 | 既存の Livy Gateway に接続し、セッションを作成します。 | Spark Connect Server を自動的に作成または再利用します。 |
本番モード | Livy モード:Livy サービス経由で Spark ジョブを送信します。 | spark-submit バッチモード:純粋なバッチ処理。セッション状態は保持されません。 | Spark Connect Server モード:Spark 接続サービス経由で連携します。 |
リソース解放 | タスクインスタンス終了後に、システムが自動的にセッションを解放します。 | タスクインスタンス終了後に、システムが自動的にリソースをクリーンアップします。 | タスクインスタンス終了後に、システムが自動的にリソースを解放します。 |
ユースケース | MaxCompute エコシステムと密接に統合された汎用バッチ処理および ETL タスク。 | Hudi や Iceberg などのオープンソースビッグデータエコシステムとの連携を必要とする柔軟な構成が求められる複雑な分析タスク。 | AnalyticDB for MySQL の C-Store テーブルに対する高性能インタラクティブクエリおよび分析。 |
MaxCompute Spark
MaxCompute コンピュートリソースに接続する前に、MaxCompute コンピュートリソースをバインドしていることを確認してください。
Livy を介して MaxCompute プロジェクトに組み込まれた Spark エンジンに接続します。
接続の確立:Python セルで次のコマンドを実行します。システムが自動的に Spark セッションを作成または再利用します。
# Spark セッションの作成 %maxcompute_sparkPySpark コードの実行:接続確立後、新しい Python セルで
%%sparkセルマジックを使用して PySpark コードを実行します。# MaxCompute Spark を使用する場合、Python セルは %%spark で始まる必要があります。 %%spark df = spark.sql("SELECT * FROM your_mc_table LIMIT 10") df.show()接続の手動解放:デバッグ完了後は、手動でセッションを停止または削除できます。本番環境で実行する場合、システムが現在のタスクインスタンスの Livy セッションを自動的に停止および削除するため、手動操作は不要です。
# Spark セッションおよび Livy のクリーンアップ %maxcompute_spark stop # Spark セッションのクリーンアップ、Livy の停止、および Livy の削除 %maxcompute_spark delete
EMR Serverless Spark
コンピュートリソースへの接続を確立する前に、ワークスペースにEMR Serverless Spark コンピュートリソースをバインドし、Livy Gateway を作成してください。
事前に作成された Livy Gateway に接続して、EMR Serverless Spark と連携します。
接続の確立:コマンド実行前に、セルの右下隅で EMR コンピュートリソースおよび Livy Gateway を選択します。
# 基本的な接続 %emr_serverless_spark # または、接続時にカスタム Spark パラメーターを渡します。カスタム Spark パラメーターを渡す際は、 # パーセント記号を 2 つ (%%) 使用する必要があります。 %%emr_serverless_spark { "spark_conf": { "spark.emr.serverless.environmentId": "<EMR Serverless Spark 実行環境 ID>", "spark.emr.serverless.network.service.name": "<EMR Serverless Spark ネットワーク接続 ID>", "spark.driver.cores": "1", "spark.driver.memory": "8g", "spark.executor.cores": "1", "spark.executor.memory": "2g", "spark.driver.maxResultSize": "32g" } }説明カスタムパラメーターとグローバル構成の関係
デフォルト動作:ここで定義されたカスタムパラメーターは、現在の接続 (セッション) のみに適用され、一時的です。カスタムパラメーターを指定しない場合、システムは 管理センター で構成されたグローバルパラメーターを使用します。
推奨される使用方法:複数のタスクまたは複数のユーザー間で再利用が必要な構成については、管理センター > Serverless Spark > SPARK パラメーター でグローバルに構成し、一貫性を確保して管理を簡素化してください。
優先順位ルール:カスタムパラメーターとグローバル構成の両方に同じパラメーターが設定されている場合、どちらの設定が有効になるかは、管理センター の [グローバル構成優先度] オプションに依存します。
選択済み:グローバル構成がこのセッションのカスタムパラメーターを上書きします。
未選択:このセッションのカスタムパラメーターがグローバル構成を上書きします。
(オプション) 再接続:管理者が誤って Livy Gateway ページからトークンを削除した場合、このコマンドを使用してトークンを再作成します。
# 現在の個人用開発環境の Livy トークンを再接続およびリフレッシュします。 %emr_serverless_spark refresh_tokenPySpark または SQL コードの実行:接続確立後、カーネルが切り替わります。Python セルに直接 PySpark コードを記述するか、EMR Spark SQL セルに SQL を記述できます。
EMR Spark SQL セルによる SQL コードの送信および実行
%emr_serverless_sparkで接続を確立した後、EMR Spark SQL セルに直接 SQL ステートメントを記述できます。セル内でコンピュートリソースを選択する必要はありません。EMR Spark SQL セルは
%emr_serverless_spark接続を再利用して、ジョブを対象のコンピュートリソースに送信し、実行します。
Python セルによる PySpark コードの送信および実行
%emr_serverless_sparkで接続を確立した後、新しい Python セルで PySpark コードを送信および実行できます。セルに%%sparkプレフィックスを追加する必要はありません。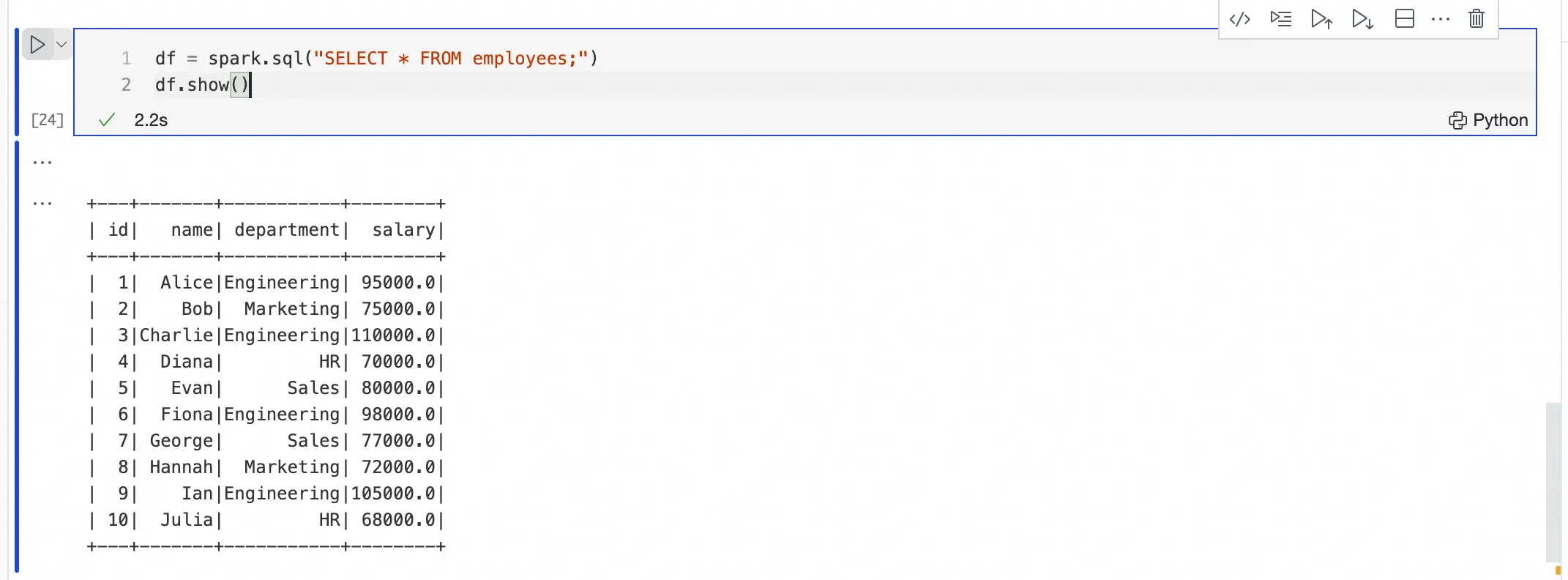
接続の手動解放
重要複数のユーザーが Livy Gateway を共有している場合、
stopまたはdeleteコマンドは、そのゲートウェイを使用中のすべてのユーザーに影響します。これらのコマンドは慎重に使用してください。# Spark セッションおよび Livy のクリーンアップ %emr_serverless_spark stop # Spark セッションのクリーンアップ、Livy の停止、および Livy の削除 %emr_serverless_spark delete
AnalyticDB for Spark
コンピュートリソースへの接続を確立する前に、ワークスペースにAnalyticDB for Spark コンピュートリソースをバインドしてください。
Spark Connect Server を作成して、AnalyticDB for Spark エンジンに接続します。
接続の確立:ネットワーク接続を確保するには、接続パラメーターで vSwitch ID およびセキュリティグループ ID を正しく構成する必要があります。コマンド実行前に、セルの右下隅で ADB Spark コンピュートリソース を選択します。
# ネットワーク接続を確立するには、vSwitch ID およびセキュリティグループ ID を構成する必要があります。 %adb_spark add \ --spark-conf spark.adb.version=3.5 \ --spark-conf spark.adb.eni.enabled=true \ --spark-conf spark.adb.eni.vswitchId=<ADB の vSwitch ID> \ --spark-conf spark.adb.eni.securityGroupId=<個人用開発環境のセキュリティグループ ID>PySpark コードの実行:接続確立後、新しい Python セルで PySpark コードを実行します。
# C-Store テーブルでのみ操作を実行できます。 df = spark.sql("SELECT * FROM my_adb_cstore_table LIMIT 10") df.show()注記:AnalyticDB for Spark エンジンは、現在
'storagePolicy'='COLD'属性を持つ C-Store テーブルのみを処理できます。接続の手動解放:開発環境でのデバッグ完了後は、リソースを節約するために接続セッションを手動でクリーンアップします。本番環境で実行する場合、システムが自動的にリソースをクリーンアップします。
%adb_spark cleanup
Lindorm Ray への接続
Lindorm コンピュートエンジンの RAY リソースグループは分散コンピューティングサービスを提供し、エンドツーエンドの AI ワークロードをサポートします。マジックコマンドを使用して、ノートブックから Lindorm Ray リソースにシームレスに接続し、インタラクティブな開発およびデバッグを行い、その後ノートブックをスケジュールされた本番タスクとして公開できます。
接続の確立:Python セルで
%lindorm_rayコマンドを実行します。セルの右下隅にコンピュートリソースセレクターが表示されます。Lindorm コンピュートリソースおよび作成済みの RAY リソースグループ を選択します。# 指定された Lindorm Ray リソースグループに接続します。 %lindorm_ray重要Lindorm Ray コンピュートリソースに接続した後、同じノートブックで SQL セルを実行できなくなります。Lindorm Ray エンジンは Python および Ray コードのみを排他的に実行します。
同じコードセルを複数回実行すると、システムが自動的に前の Ray ジョブを終了し、新しいジョブを開始します。これにより、リソースの無駄遣いやタスクの競合を防げます。
Ray コードの実行:接続確立後、新しい Python セルに直接 Ray コードを記述および実行できます。ログはリアルタイムでセルの出力エリアにストリーミングされ、インタラクティブなデバッグが容易になります。
次の例では、Ray クラスター上で実行され、ログおよび最終結果をセルの出力エリアに返すシンプルなリモートタスク (
@ray.remoteデコレーターを使用) を定義します。import ray import time @ray.remote def hello_world(): print("Hello from Lindorm Ray!") time.sleep(5) return "Task finished." # リモートタスクの送信 result_ref = hello_world.remote() print(ray.get(result_ref))(オプション) カスタム起動パラメーターの指定:Ray 環境にサードパーティ製 Python パッケージをインストールしたり、ローカルのコードファイルをアップロードしたりするなど、追加の構成を指定する必要がある場合は、
%%lindorm_rayコマンドを使用して接続を確立します。例 1:依存関係のインストール
pipパラメーターを使用して、Ray 環境内にjiebaパッケージをインストールします。%%lindorm_ray { "runtime_env": { "pip": ["jieba"] } }環境の準備が完了したら、後続の Ray ジョブでパッケージをインポートおよび使用できます。次の例は、リモート関数内で
jiebaを呼び出して中国語の形態素解析を実行する方法を示しています。import ray @ray.remote def do_work(x): import jieba return "/".join(jieba.cut(x)) print(ray.get(do_work.remote("Welcome to the DataWorks+LindormRay solution")))例 2:DataWorks リソースのアップロードおよび使用
working_dirパラメーターは、DataWorks Resource Management から Ray クラスターにリソースをアップロードし、タスク内でインポートおよび呼び出せるようにするために使用します。重要working_dirを使用してリソースをアップロードする場合、ファイルは開発環境から直接 Ray クラスターにアップロードされ、100 MB のサイズ制限が適用されます。リソースパッケージが大きすぎると、アップロードが失敗したり、Ray ノードが不安定になったりする可能性があります。
# DataStudio Resource Management にアップロードされたリソースを参照し、そのパスを宣言します。 %%lindorm_ray { "runtime_env": { "working_dir": "/mnt/workspace/_dataworks/resource_references" } }DataStudio の Resource Management に ray_resource.py ファイルをアップロードしたと仮定します。次のセルを記述および実行すると、システムが後続のコード内の
##@resource_reference宣言を自動的に解析し、対応するリソースを/mnt/workspace/_dataworks/resource_referencesパスにダウンロードします。重要開発環境では、##@resource_reference を含むセルを実行した後、上記の
%%lindorm_rayセルを再度実行して、working_dir 内のダウンロード済みリソースを Ray クラスターにアップロードする必要があります。本番環境では、再度実行する必要はありません。import ray ##@resource_reference{"ray_resource.py"} @ray.remote def do_work(x): print('Ray says:', x) from ray_resource import fun fun() return x worker = do_work.remote("Welcome to the DataWorks+LindormRay solution") print(ray.get(worker))
本番スケジューリングおよび運用:開発およびデバッグ完了後、ノートブックノードをコミットおよび公開できます。その後、DAG 内の Lindorm Ray ノードとして定期的にスケジュールされます。
パラメーター化:コードでは、
${bizdate}などの標準的な DataWorks スケジューリングパラメーターを使用できます。ログの表示:本番環境では、過剰なログがパフォーマンスに影響を与えないようにするため、システムはデフォルトで最初の 1 MB のログのみを読み込みます。ログが切り捨てられた場合、完全なタスkログを表示するためのリンクが Lindorm コンソールに含まれます。
リソース解放:スケジュールされた本番タスク終了後、Lindorm Ray タスクは終了状態になり、リソースを占有しなくなります。インタラクティブな開発中は、カーネルを再起動するかノートブックを閉じることで Lindorm Ray タスクを終了できます。
付録:マジックコマンド クイックリファレンス
マジックコマンド | 説明 | コンピュートエンジン |
| PyODPS エントリオブジェクトの取得 | MaxCompute |
| MaxFrame 接続の確立 | |
| Spark セッションの作成 | MaxCompute Spark |
| Spark セッションのクリーンアップおよび Livy の停止 | |
| Spark セッションのクリーンアップ後、Livy を停止および削除 | |
| Python セル内で、確立済みの Spark コンピュートリソースに接続 | |
| Spark セッションの作成 | EMR Serverless Spark |
| Livy Gateway の詳細情報の表示 | |
| Spark セッションのクリーンアップおよび Livy の停止 | |
| Spark セッションのクリーンアップ後、Livy を停止および削除 | |
| 個人用開発環境の Livy トークンのリフレッシュ | |
| 再利用可能な ADB Spark セッションの作成および接続 | AnalyticDB for Spark |
| Spark セッション情報の表示 | |
| 現在の Spark 接続セッションの停止およびクリーンアップ | |
| Lindorm Ray 接続の確立 | Lindorm Ray |
| Lindorm Ray 接続の確立およびカスタムランタイム環境の構成 (依存関係のインストールやコードのアップロードなど) |
よくある質問
Q:ワークスペースリソースを参照する際に、
ModuleNotFoundErrorまたはThere is no file with id ...エラーが発生するのはなぜですか?A:次の手順でトラブルシューティングを行ってください。
[データ開発] > [Resource Management] に移動し、MaxCompute Python リソースが保存されていることを確認します。本番環境でこのエラーが発生した場合は、リソースが本番環境に公開されていることを検証してください。
ノートブックエディタのツールバーで 再起動 をクリックしてリソースを再読み込みします。
Q:ワークスペースリソースを更新した後も、古いリソースが参照され続けるのはなぜですか?
A:変更済みのリソースを再公開する際は、Data Studio 設定で
Dataworks › Notebook › Resource Reference: Download Strategyを autoOverwrite に設定し、ノートブックツールバーで [カーネルの再起動] をクリックしてください。Q:開発環境でデータセットを参照すると
FileNotFoundErrorエラーが発生するのはなぜですか?A:データセットが現在選択中の個人用開発環境にマウントされていることを確認してください。
Q:開発環境ではデータセットの参照が成功するのに、本番環境で
Execute mount dataset exception! Please check your dataset configエラーが発生するのはなぜですか?A:Scheduling Settings にデータセットがマウントされており、OSS データセットに対して必要な権限が付与されていることを確認してください。
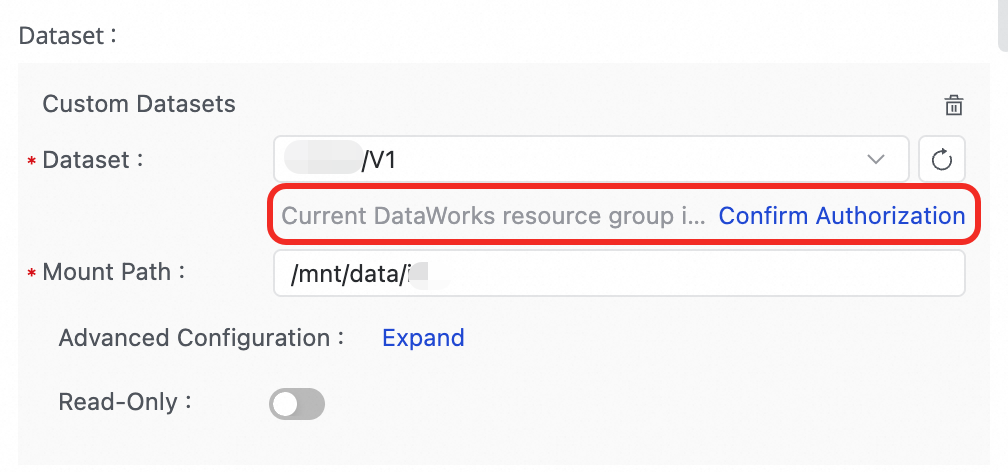
Q:個人用開発環境のバージョンを確認するにはどうすればよいですか?
A:個人用開発環境で
Cmd+Shift+Pを押してABOUTと入力すると、現在のバージョンを確認できます。バージョン 0.5.69 以降へのアップグレードが必要な場合、アップグレードプロンプトが表示されます。[ワンクリックアップグレード] をクリックしてインスタンスを更新してください。Q:Spark エンジンへの接続が失敗するのはなぜですか?
A:次の手順に従ってください。
一般的な確認事項:ワークスペース詳細ページのコンピュートリソース一覧で、対象のコンピュートリソース (MaxCompute、EMR、または ADB) がワークスペースに正しくバインドされており、アカウントに必要な権限があることを確認します。
EMR Serverless Spark:Livy Gateway が存在し、正常であることを確認します。
AnalyticDB for Spark:ネットワークの問題に注目します。
vswitchIdおよびsecurityGroupIdが正しく構成され、個人用開発環境と ADB Spark インスタンス間のネットワーク接続が確保されていることを確認します。セキュリティグループルールで、必要なポートへのトラフィックが許可されていることを検証します。