代入ノードは、上流ノードのクエリ結果または他の出力を下流ノードに渡します。代入ノードは、MaxCompute SQL、Python 2、およびシェルのスクリプトをサポートします。最後のクエリまたは出力結果を、ノードの出力パラメーター (outputs) に自動的に割り当てます。下流ノードは、このパラメーターを参照することで代入ノードの出力を取得できます。
前提条件
-
バージョン要件:この機能は、DataWorks Standard Edition 以降でのみ利用可能です。
-
権限:お使いの RAM アカウントが対象のワークスペースに追加され、開発またはワークスペース管理者のロールが割り当てられている必要があります。詳細については、「ワークスペースへのメンバー追加」をご参照ください。
主要概念:パラメーターの受け渡しと参照
代入ノードの中核機能は、上流ノードから下流ノードへデータを転送するパラメーターの受け渡しです。
-
上流の代入ノード:データを生成します。最後の出力またはクエリ結果を、システムが生成した
outputsという名前の出力パラメーターに自動的に割り当てます。 -
下流のビジネスノード:データを受信して使用します。ノードに入力パラメーター (例:
param) を設定し、その値を上流ノードのoutputsパラメーターを参照するように設定できます。これにより、コードでデータが利用できるようになります。
パラメーターの形式
次の表に、渡されるパラメーターの形式を示します。
|
言語 |
値 |
形式 |
|
MaxCompute SQL |
最後の |
ノードは、出力を2次元配列として下流ノードに渡します。 |
|
Python 2 |
最後の |
DataWorks は、出力文字列をカンマ ( 例えば、代入ノードからの出力の最終行が 重要
出力にカンマが含まれる場合は、エスケープする必要があります。例えば、出力が |
|
シェル |
最後の |
操作手順
以下の例では、代入ノードの結果をシェルノードに渡す方法を説明します。なお、下流ノードとして任意のノードタイプを使用できます。
-
上流の代入ノードの設定
対象のワークフローで、代入ノードを作成して編集します。必要に応じて MaxCompute SQL、Python 2、またはシェルを選択し、下流ノードに渡したい結果を生成するコードを記述します。
print '10,20,30,40' -
下流のシェルノードの設定
シェルノードを作成し、ノードの設定で上流の結果を参照します:
-
右側の Scheduling Settings パネルで、Node Context Parameters タブをクリックします。
-
Input Parameters セクションで、Add parameters をクリックします。
-
表示されるダイアログボックスで、値を先ほど作成した代入ノードの
outputsパラメーターに設定します。現在のノードの入力パラメーターに任意の[Parameter Name] (例:param) を指定します。説明パラメーターを設定すると、下流ノードと上流の代入ノードの間に依存関係が自動的に作成されます。
-
パラメーターを設定した後、下流のシェルノードのコードで
${param}という形式を使用して、上流ノードから渡された値を参照できます。
-
-
実行と検証
-
ワークフローキャンバスに戻ります。ツールバーで [デプロイ] をクリックし、[完全デプロイ] を選択します。
-
に移動し、対象のワークフローで、スモークテストを実行します。
-
テストインスタンスで、最終結果が期待どおりであることを確認します。
-
OpenAPI を使用した代入ノードの作成
コンソールを使用するだけでなく、DataWorks OpenAPI の CreateNode API を呼び出すことでも代入ノードを作成できます。API でノードを作成する際は、FlowSpec の Spec パラメーターにノード情報を設定する必要があります。
リソースグループをバインドする場合は、FlowSpec 内の runtimeResource.resourceGroup フィールドにリソースグループの識別子を指定します。以下にコード例を示します。
{
"version": "1.1.0",
"kind": "Node",
"spec": {
"nodes": [
{
"recurrence": "Normal",
"script": {
"runtime": {
"command": "CONTROLLER_ASSIGNMENT"
},
"content": "print '10,20,30'"
},
"runtimeResource": {
"resourceGroup": "S_res_group_XXX_XXXX"
},
"name": "assignment_node_demo"
}
]
}
}独自のコードを使用して API を呼び出す場合は、Alibaba Cloud の公式 SDK と同じ方法でパラメーターが渡されるようにしてください。そうでない場合、パラメーターが正しく渡されたとしても、リソースグループのバインドが有効にならない可能性があります。
制限事項
-
受け渡しレベル:代入ノードは、直接の下流ノードにのみパラメーターを渡すことができ、複数のレベルをまたいで渡すことはできません。
-
サイズ制限:値の最大サイズは 2 MB です。代入ステートメントの出力がこの制限を超えると、代入ノードは失敗します。
-
構文の制約:
-
代入ノードのコードではコメントはサポートされていません。コメントを含めると、予期せぬ結果を招く可能性があります。
-
MaxCompute SQL モードでは WITH 句はサポートされていません。
-
言語別の例
出力 (outputs) のデータ形式と、下流ノードがそれを参照する方法は、代入ノードの言語によって若干異なります。以下の例では、下流ノードとしてシェルノードを使用して、その違いを説明します。
例 1:MaxCompute SQL クエリ結果の受け渡し
SQL クエリの結果は、2次元配列として下流ノードに渡されます。
-
上流ノード (代入ノード - SQL) の設定
以下の SQL コードが 2 行 2 列を返すものとします:
SELECT 'beijing', '1001' UNION ALL SELECT 'hangzhou', '1002'; -
下流ノード (シェルノード) の設定と出力
シェルノードで、上流の SQL ノードの
outputsを参照するregionという名前の入力パラメーターを追加します。データを読み込むために次のコードを記述します:
echo "Full result set: ${region}" echo "First row: ${region[0]}" echo "Second field of the first row: ${region[0][1]}"DataWorks はパラメーターを直接解析し、静的な置換を実行します。実行時の出力は以下のようになります:
Full result set: beijing,1001 hangzhou,1002 First row: beijing,1001 Second field of the first row: 1001
例 2:Python 2 の出力結果の受け渡し
Python 2 の print ステートメントの出力は、カンマ (,) で分割され、1次元配列として下流ノードに渡されます。
-
上流ノード (代入ノード - Python 2) の設定
Python 2 のコードは次のとおりです:
print 'Electronics, Clothing, Books'; -
下流ノード (シェルノード) の設定と出力
シェルノードで、上流の代入ノードの
outputsを参照するtypesという名前の入力パラメーターを追加します。データを読み込むために次のコードを記述します:
# 1次元配列全体を出力 echo "Full result set: ${types}" # インデックスで配列から要素を出力 echo "Second element: ${types[1]}"DataWorks はパラメーターを直接解析し、静的な置換を実行します。実行時の出力は次のようになります:
Full result set: Electronics, Clothing, Books Second element: Clothing
シェルノードの処理ロジックは Python 2 ノードと同様のため、ここでは説明を省略します。
ユースケース:パーティション化されたデータのバッチ処理
この例では、代入ノードと For-Each ノードを使用して、複数のビジネスラインからのユーザー行動データをバッチ処理する方法を説明します。これにより、単一のロジックで複数のビジネスラインのデータ処理を自動化できます。

背景情報
ある大手インターネット企業でデータエンジニアとして、E コマース (ecom)、金融 (finance)、物流 (logistics) という 3 つの中核ビジネスラインのデータ処理を担当しているとします。将来的には、さらに多くのビジネスラインが追加される可能性があります。これらのビジネスラインのユーザー行動ログに対して、毎日同じ集約ロジックを実行し、各ユーザーの PV (ページビュー) を計算し、その結果を共通の集計テーブルに保存する必要があります。
-
上流のソーステーブル (DWD レイヤー):
-
dwd_user_behavior_ecom_d:E コマースユーザー行動テーブル。 -
dwd_user_behavior_finance_d:金融ユーザー行動テーブル。 -
dwd_user_behavior_logistics_d:物流ユーザー行動テーブル。 -
dwd_user_behavior_${biz_line}_d:他の潜在的なビジネスラインのユーザー行動テーブル。 -
これらのテーブルは同じ構造を持ち、日 (
dt) でパーティション分割されています。
-
-
下流のターゲットテーブル (DWS レイヤー):
-
dws_user_summary_d:ユーザーサマリーテーブル。 -
このテーブルは、すべてのビジネスラインからの集約結果を保存するために、ビジネスライン (
biz_line) と日 (dt) でパーティション分割されています。
-
ビジネスラインごとに個別のタスクを作成すると、メンテナンスが煩雑になり、エラーが発生しやすくなります。For-Each ノードを使用すると、1つの処理ロジックを維持するだけで、システムがすべてのビジネスラインを自動的に反復処理して計算を完了するため、メンテナンスが簡素化されます。
データ準備
まず、サンプルテーブルを作成し、テストデータを挿入します。この例では、業務日として 20251010 を使用します。
-
ワークスペースに MaxCompute コンピュートエンジンをバインドします。
-
Data Studio に移動し、MaxCompute SQL ノードを作成します。
-
ソーステーブル (DWD レイヤー) を作成します:以下のコードを MaxCompute SQL ノードに追加し、選択して実行します。
-- E コマースユーザー行動テーブル CREATE TABLE IF NOT EXISTS dwd_user_behavior_ecom_d ( user_id STRING COMMENT 'ユーザー ID', action_type STRING COMMENT 'アクションタイプ', event_time BIGINT COMMENT 'イベントの UNIX タイムスタンプ (ミリ秒)' ) COMMENT 'E コマースユーザー行動詳細ログテーブル' PARTITIONED BY (dt STRING COMMENT '日付パーティション、形式 yyyymmdd'); INSERT OVERWRITE TABLE dwd_user_behavior_ecom_d PARTITION (dt='20251010') VALUES ('user001', 'click', 1760004060000), -- 2025-10-10 10:01:00.000 ('user002', 'browse', 1760004150000), -- 2025-10-10 10:02:30.000 ('user001', 'add_to_cart', 1760004300000); -- 2025-10-10 10:05:00.000 -- E コマースユーザー行動テーブルが作成されたことを確認します。 SELECT * FROM dwd_user_behavior_ecom_d where dt='20251010'; -- 金融ユーザー行動テーブル CREATE TABLE IF NOT EXISTS dwd_user_behavior_finance_d ( user_id STRING COMMENT 'ユーザー ID', action_type STRING COMMENT 'アクションタイプ', event_time BIGINT COMMENT 'イベントの UNIX タイムスタンプ (ミリ秒)' ) COMMENT '金融ユーザー行動詳細ログテーブル' PARTITIONED BY (dt STRING COMMENT '日付パーティション、形式 yyyymmdd'); INSERT OVERWRITE TABLE dwd_user_behavior_finance_d PARTITION (dt='20251010') VALUES ('user003', 'open_app', 1760020200000), -- 2025-10-10 14:30:00.000 ('user003', 'transfer', 1760020215000), -- 2025-10-10 14:30:15.000 ('user003', 'check_balance', 1760020245000), -- 2025-10-10 14:30:45.000 ('user004', 'open_app', 1760020300000); -- 2025-10-10 14:31:40.000 -- 金融ユーザー行動テーブルが作成されたことを確認します。 SELECT * FROM dwd_user_behavior_finance_d where dt='20251010'; -- 物流ユーザー行動テーブル CREATE TABLE IF NOT EXISTS dwd_user_behavior_logistics_d ( user_id STRING COMMENT 'ユーザー ID', action_type STRING COMMENT 'アクションタイプ', event_time BIGINT COMMENT 'イベントの UNIX タイムスタンプ (ミリ秒)' ) COMMENT '物流ユーザー行動詳細ログテーブル' PARTITIONED BY (dt STRING COMMENT '日付パーティション、形式 yyyymmdd'); INSERT OVERWRITE TABLE dwd_user_behavior_logistics_d PARTITION (dt='20251010') VALUES ('user001', 'check_status', 1760032800000), -- 2025-10-10 18:00:00.000 ('user005', 'schedule_pickup', 1760032920000); -- 2025-10-10 18:02:00.000 -- 物流ユーザー行動テーブルが作成されたことを確認します。 SELECT * FROM dwd_user_behavior_logistics_d where dt='20251010'; -
ターゲットテーブル (DWS レイヤー) を作成します:以下のコードを MaxCompute SQL ノードに追加し、選択して実行します。
CREATE TABLE IF NOT EXISTS dws_user_summary_d ( user_id STRING COMMENT 'ユーザー ID', pv BIGINT COMMENT 'PV' ) COMMENT 'ユーザー日次 PV サマリーテーブル' PARTITIONED BY ( dt STRING COMMENT '日付パーティション、形式 yyyymmdd', biz_line STRING COMMENT 'ビジネスラインパーティション (ecom、finance、logistics など)' );重要ワークスペースが Standard Edition の場合、このノードを本番環境にデプロイし、データバックフィルを実行する必要があります。
ワークフローの実装
-
ワークフローを作成します。右側の [スケジューリングパラメーター] パネルで、スケジューリングパラメーター bizdate を前日に設定します:
$[yyyymmdd-1]。 -
ワークフローで、get_biz_list という名前の代入ノードを作成し、MaxCompute SQL 言語を使用して以下のコードを記述します。このノードは、処理対象のビジネスラインのリストを出力します:
-- 処理対象のすべてのビジネスラインを出力 SELECT 'ecom' AS biz_line UNION ALL SELECT 'finance' AS biz_line UNION ALL SELECT 'logistics' AS biz_line; -
For-Each ノードの設定
-
ワークフローキャンバスに戻り、get_biz_list 代入ノードの下流に For-Each ノードを作成します。
-
For-Each ノードの設定ページに移動します。右側のスケジューリング設定パネルの で、loopDataArray パラメーターを get_biz_list ノードの outputs にバインドします。
-
For-Each ノードのループ本体で、[内部ノードの作成] をクリックして MaxCompute SQL ノードを作成し、ループ本体の処理ロジックを記述します。
説明-
このスクリプトは For-Each ノードによって駆動され、ビジネスラインごとに 1 回実行されます。
-
実行時、組み込み変数
${dag.foreach.current}は、'ecom'、'finance'、'logistics' といった現在のビジネスライン名に動的に置換されます。
SET odps.sql.allow.dynamic.partition=true; INSERT OVERWRITE TABLE dws_user_summary_d PARTITION (dt='${bizdate}', biz_line) SELECT user_id, COUNT(*) AS pv, '${dag.foreach.current}' AS biz_line FROM dwd_user_behavior_${dag.foreach.current}_d WHERE dt = '${bizdate}' GROUP BY user_id; -
-
-
検証ノードの追加
ワークフローに戻ります。For-Each ノードの [下流ノードの作成] をクリックして MaxCompute SQL ノードを作成し、以下のコードを追加します。
SELECT * FROM dws_user_summary_d WHERE dt='20251010' ORDER BY biz_line, user_id;
デプロイと結果
ワークフローを本番環境にデプロイします。 に移動し、ターゲットのワークフローを見つけて、業務日を '20251010' に設定してスモークテストを実行します。
実行が完了したら、テストインスタンスで実行ログを表示します。最終ノードは以下の出力を生成します:
|
user_id |
pv |
dt |
biz_line |
|
user001 |
2 |
20251010 |
ecom |
|
user002 |
1 |
20251010 |
ecom |
|
user003 |
3 |
20251010 |
finance |
|
user004 |
1 |
20251010 |
finance |
|
user001 |
1 |
20251010 |
logistics |
|
user005 |
1 |
20251010 |
logistics |
メリット
-
高いスケーラビリティ:新しいビジネスラインを追加するには、代入ノードに SQL を 1 行追加するだけで済みます。処理ロジックの変更は不要です。
-
容易なメンテナンス:すべてのビジネスラインが同じ処理ロジックを共有します。1 か所の変更がすべてに反映されます。
よくある質問
-
Q:MaxCompute SQL を使用すると "find no select sql in sql assignment!" というエラーが表示されるのはなぜですか。
A:このエラーは、MaxCompute SQL スクリプトに
SELECTステートメントがないために発生します。SELECTステートメントを追加することで問題を解決できます。WITH 句はサポートされておらず、使用した場合も同様にこのエラーが発生しますのでご注意ください。 -
Q:シェルまたは Python を使用すると "OutPut Result is null, cannot handle!" というエラーが表示されるのはなぜですか。
A:このエラーは、スクリプトが出力を生成しなかったことを示します。コードに、Python の場合は
print、シェルの場合はechoなどの出力ステートメントが含まれていることを確認してください。 -
Q:シェルまたは Python でカンマを含む出力要素をどのように処理しますか。
A:カンマ (
,) を\,に置き換えてエスケープする必要があります。以下に Python のコード例を示します。categories = ["Electronics", "Clothing, Shoes & Accessories"] # 各要素のカンマをエスケープします。 # ',' を '\,' に置き換えます。 escaped_categories = [cat.replace(",", "\,") for cat in categories] # エスケープされた要素をカンマで結合します。 output_string = ",".join(escaped_categories) print output_string # 下流ノードに渡される最終的な文字列は次のとおりです: # Electronics,Clothing\, Shoes & Accessories -
Q:下流ノードは、複数の上流の代入ノードから結果を受け取ることができますか。
A:はい。異なるノードからの結果を、異なるパラメーターに割り当てることができます。
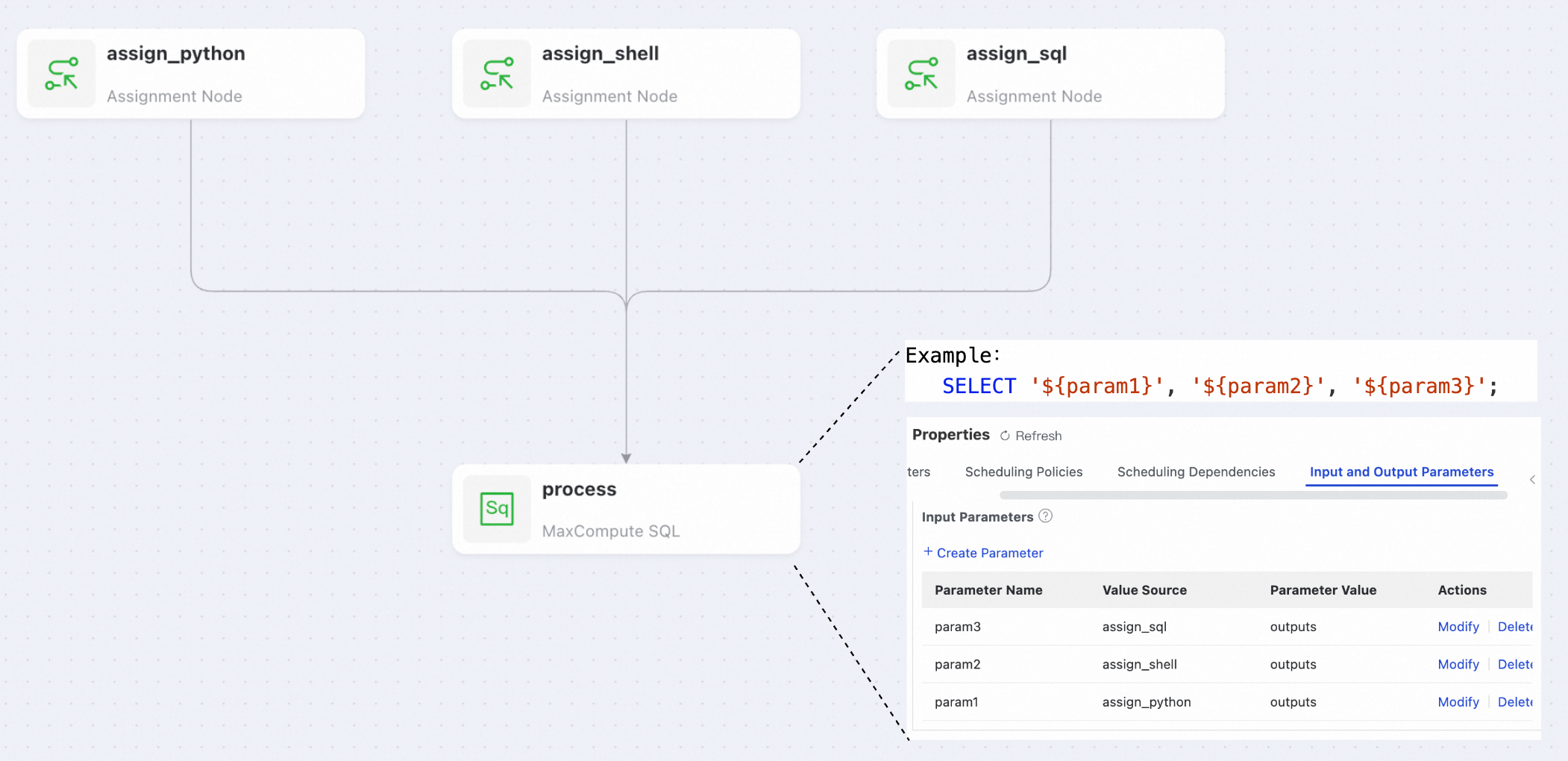
-
Q:代入ノードは他の言語タイプをサポートしていますか。
A:現在、代入ノードは MaxCompute SQL、Python 2、シェルのみをサポートしています。ただし、EMR Hive、Hologres SQL、EMR Spark SQL、AnalyticDB for PostgreSQL、ClickHouse SQL、MySQL など、他の一部のノードタイプには、同様の結果を実現する組み込みのパラメーターの割り当て機能があります。
[出力パラメーター] セクションで、[代入パラメーターの追加] をクリックします。
関連トピック
-
下流ノードで結果をループ処理する必要がある場合は、「For-Each ノード」と「Do-While ノード」をご参照ください。
-
ワークフロー内の複数のレベルをまたいでパラメーターを渡すには、「パラメーターノード」をご参照ください。
-
パラメーターの受け渡しの設定に関する詳細については、「ノードコンテキストパラメーター」をご参照ください。