Dataphin では、オープンソースの Flink リアルタイムコンピューティングエンジンのリアルタイムインスタンスのランタイムメトリックを分析できます。 この分析には、リアルタイムインスタンス情報の更新などの操作が含まれ、障害、バックプレッシャー状態、シンク出力、およびチェックポイントの失敗に関するデータが表示されます。
権限の説明
プロジェクトのランタイム分析を表示するには、プロジェクトスペースの権限が必要です。
Apache Flink ダッシュボードへのアクセスには、ユーザー名とパスワードが必要です。 ダッシュボードは、スーパー管理者、システム管理者タスク所有者プロジェクト運用管理のオーナー、、および を含むユーザーロールのプロンプト情報を提供します。
ランタイム分析エントリ
Dataphin ホームページの上部メニューバーで [開発] をクリックして、デフォルトでデータ開発ページに移動します。
[ランタイム分析] を表示するには、次の手順に従います。
[運用とメンテナンス] -> [プロジェクト](開発-本番モードでは環境の選択が必要です)-> [リアルタイムインスタンス] ->
 アイコンをクリックします。
アイコンをクリックします。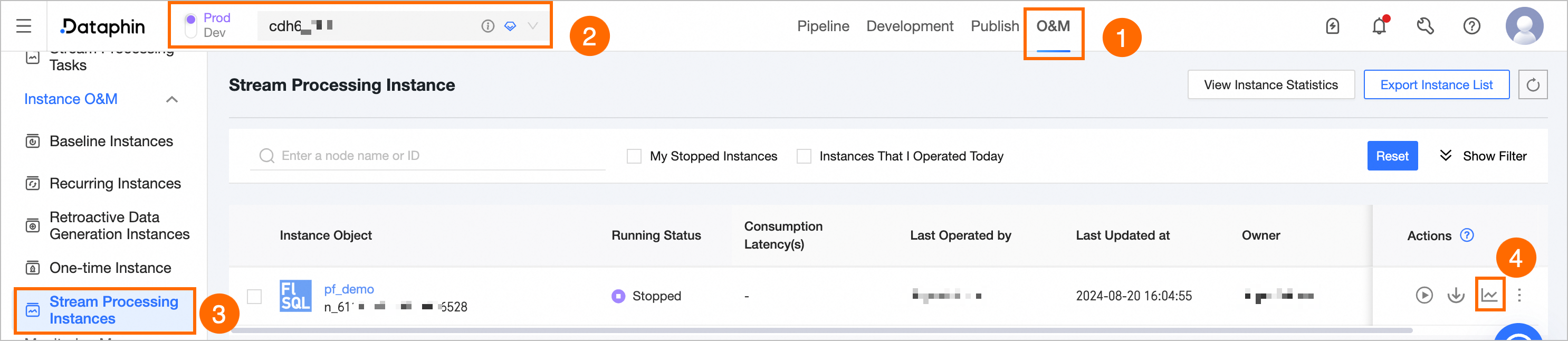
ランタイム分析の表示
ランタイム分析ページには、以下に示すように、さまざまなメトリックの実行ステータスが表示されます。
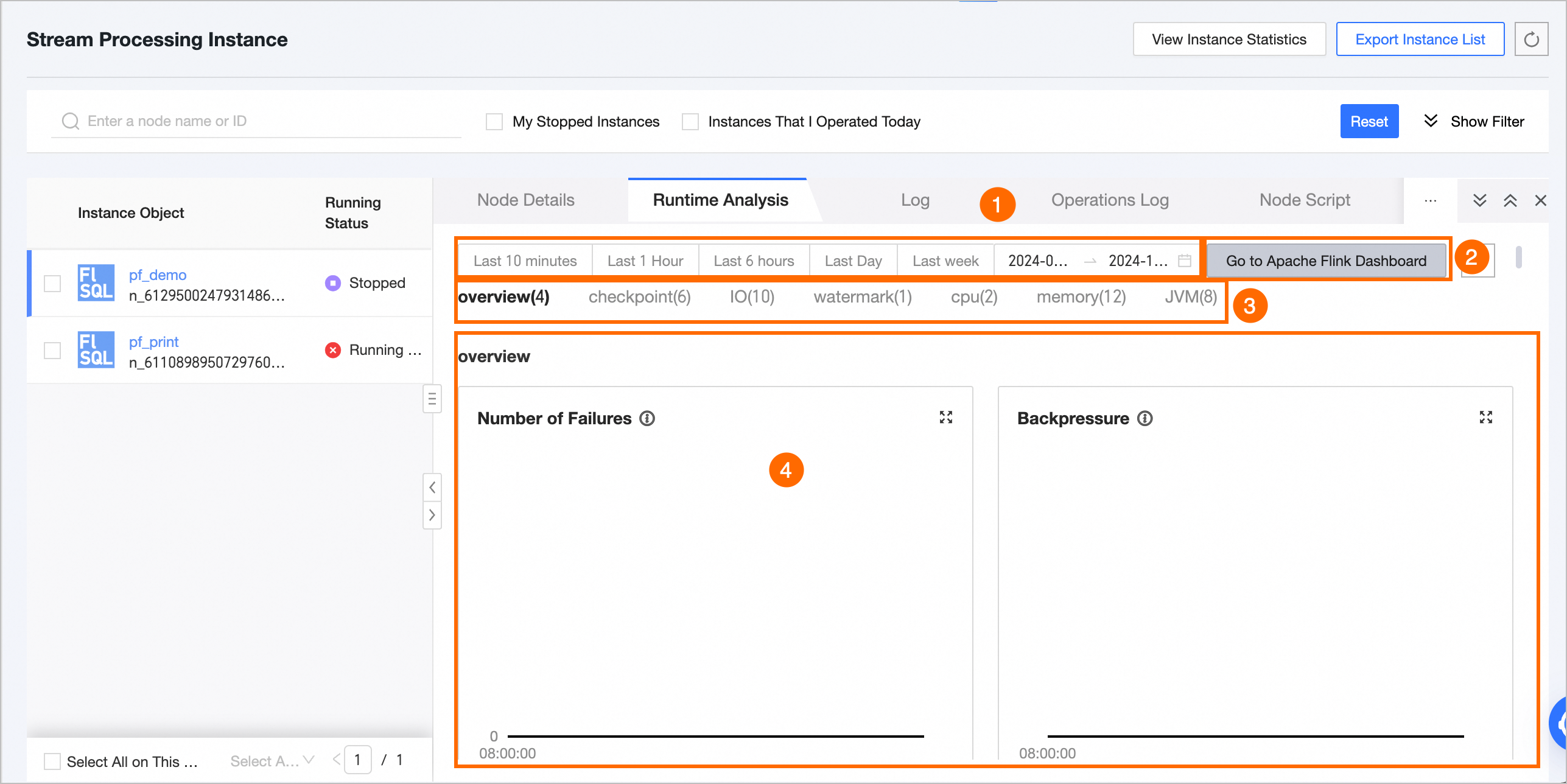
機能 | 説明 |
[① 時間範囲の選択] |
|
[② Apache Flink ダッシュボードに移動] および [更新] |
|
③ リアルタイム監視メトリック | Flink SQL または Flink Datastream タスクの場合、概要、チェックポイント、IO、ウォーターマーク、CPU、メモリ、JVM などのメトリックを表示できます。 各メトリックの詳細な説明については、「リアルタイム監視メトリックの説明」をご参照ください。 |
④ メトリックデータ統計 | 選択した期間内の各メトリックのデータステータスを表示します。 |
メトリック統計の説明
選択した時間間隔が 6 時間以下の場合、1 分ごとに収集されたすべてのデータポイントを表示できます。
6 時間を超えて 24 時間までの時間間隔の場合、データポイントは時間から 5 分ごとに収集され、各ポイントは前の 5 分間のカウントを表します。
24 時間を超える時間間隔の場合、データポイントは時間から 10 分ごとに収集され、各ポイントは前の 10 分間のカウントを表します。
リアルタイム監視メトリックの説明
概要
監視メトリック | 説明 | 単位 |
[失敗回数] | 指定された期間内に発生したタスクの失敗回数。 | 回 |
[バックプレッシャー状態] | 現在の期間中にタスクがバックプレッシャーを発生させているかどうかを示します。これは、ダウンストリームタスクが処理できるよりも速い速度でデータを生成する場合に発生します。 | ブール値 |
[各シンクのデータ出力] | 各シンクのスループット。1 秒あたりのトランザクション数 (TPS) で測定されます。 | TPS |
[チェックポイントの失敗回数] | 現在の期間内にタスクのチェックポイントが失敗した回数。 | 回 |
チェックポイント
監視メトリック | サブタイプ | 説明 | 単位 |
チェックポイントの総数 (チェックポイント数) | チェックポイントの総数 (チェックポイントの総数) | 指定された期間のタスクチェックポイントの総数をカウントします。 | カウント |
失敗したチェックポイントの数 (失敗したチェックポイントの数) | 現在の期間中に失敗したタスクチェックポイントの数を示します。 | カウント | |
完了したチェックポイントの数 (完了したチェックポイントの数) | 現在の期間内に完了したタスクチェックポイントの数を集計します。 | カウント | |
進行中のチェックポイントの数 (進行中のチェックポイント数) | 現在進行中のタスクチェックポイントの数を反映します。 | カウント | |
最新のチェックポイントの期間 (lastCheckpointDuration) | 最後のチェックポイントの期間 (最終チェックポイント期間) | 最新のタスクチェックポイントの完了にかかった時間を測定します。 チェックポイントの期間が長すぎる場合やタイムアウトが発生する場合は、状態サイズが大きい、一時的なネットワークの問題、バリアのずれ、データのバックプレッシャーなどの要因が考えられます。 | ミリ秒 (ms) |
最後のチェックポイントのサイズ (最終チェックポイントサイズ) | 最後のチェックポイントのサイズ (最終チェックポイントサイズ) | 最後にアップロードされたチェックポイントのサイズ。ボトルネック時のパフォーマンス問題の分析に役立ちます。 | バイト (Byte) |
IO
監視メトリック | 意味 | 監視メトリック | 説明 | 単位 |
入力レート: 1 秒あたりに受信した合計バイト数。 (1 秒あたりのバイト数 (numBytesIn)) | アップストリームのフローレートに関する洞察を提供し、ジョブトラフィックのパフォーマンス分析に役立ちます。 | 1 秒あたりのローカル読み込みバイト数 (1 秒あたりのローカルのバイト数) | ローカルで 1 秒あたりに読み取られるバイト数を測定します。 | バイト |
1 秒あたりのリモート バイト読み取り数 (リモートでのバイト数/秒) | リモートで 1 秒あたりに読み取られるバイト数を測定します。 | バイト | ||
ローカルネットワーク バッファー 読み取り速度 (バイト/秒) (1 秒あたりのローカルの numBuffersIn) | ローカルネットワークバッファーから 1 秒あたりに読み取られるバイト数を測定します。 | バイト | ||
ネットワーク バッファーから 1 秒あたりに読み取られるリモート バイト数 (1 秒あたりのリモートでの numBuffersIn) | リモートネットワークバッファーから 1 秒あたりに読み取られるバイト数を測定します。 | バイト | ||
出力レート: 1 秒あたりに送信された合計バイト数。 (1 秒あたりの出力バイト数) | アップストリームスループットの出力状態に関する洞察を提供し、ジョブトラフィックのパフォーマンス分析に役立ちます。 | 1 秒あたりの出力バイト数 (1 秒あたりの送信バイト数) | 1 秒あたりに送信されるバイト数を測定します。 | バイト |
1 秒あたりのネットワーク バッファー バイト出力 (1 秒あたりの numBuffersOut) | ネットワークバッファーから 1 秒あたりに送信されるバイト数を測定します。 | バイト | ||
サブタスク I/O: 1 秒あたりに処理された合計レコード数。 (タスク numRecords I/O/秒) | ジョブの潜在的な I/O ボトルネックを特定し、その重大度を評価できます。 | 1 秒あたりに受信したレコード数 (1 秒あたりの numRecordsIn) | 1 秒あたりに受信したレコード数を測定します。 | カウント |
1 秒あたりに送信されるレコード数 (1 秒あたりの numRecordsOut) | 1 秒あたりに送信されたレコード数を測定します。 | カウント | ||
サブタスク I/O: 処理された合計レコード数。 (タスク numRecords 入出力) | ジョブの潜在的な I/O ボトルネックを特定できます。 | 受信レコードの総数 (numRecordsIn) | 受信したレコードの総数を測定します。 | カウント |
送信されたレコードの合計数 (レコード数) | 送信されたレコードの総数を測定します。 | カウント |
ウォーターマーク
監視メトリック | 説明 | 単位 |
タスクごとの最終ウォーターマーク タイムスタンプ (タスク入力ウォーターマーク) | 各タスクが最後のウォーターマークを受信した時刻を示し、タスクマネージャー (TM) によるデータ受信の遅延を反映します。 | ミリ秒 (ms) |
CPU
監視メトリック | 説明 | 単位 |
単一 JM の CPU 使用率 (JM CPU負荷) | 単一の JobManager (JM) の CPU 負荷を測定します。 値が常に 100% を超えている場合は、CPU 負荷が高く、システムの遅延や応答時間の遅延などのパフォーマンスの問題が発生する可能性があります。 | カウント |
単一 TM の CPU 使用率 (TM CPU負荷) | Flink 内の単一の TaskManager (TM) による CPU タイムスライスの使用率を示します。 100% の値は 1 つのコアが完全に使用されていることを示し、400% は 4 つのコアが完全に使用されていることを示します。 常に 100% を超える値は、CPU 負荷が高いことを示します。 逆に、CPU 使用率が低く、負荷が高い場合は、読み取り/書き込み操作が多すぎて、割り込み不可能なスリープ状態が多くなっていることが原因である可能性があります。 | カウント |
メモリ
監視メトリック | サブタイプ | 説明 | 単位 |
JM ヒープメモリ (JM ヒープメモリ) | JM ヒープメモリ使用量 (JM ヒープメモリ使用量) | JobManager によって現在使用されているヒープメモリの量。 | バイト |
JM ヒープメモリコミット済み (JM ヒープメモリコミット済み) | JVM によって JobManager で使用可能であることが保証されているヒープメモリの量。 | バイト | |
JM ヒープメモリ最大値 (JM ヒープメモリ最大値) | JobManager で使用できるヒープメモリの最大量。 | バイト | |
JM 非ヒープメモリ (JM 非ヒープメモリ) | JM 非ヒープメモリ使用量 (JM 非ヒープメモリ使用量) | JobManager によって現在使用されている非ヒープメモリの量。 | バイト |
JM 非ヒープメモリコミット済み (JM 非ヒープメモリコミット済み) | JVM によって JobManager で使用可能であることが保証されている非ヒープメモリの量。 | バイト | |
JM 非ヒープメモリ最大値 (JM 非ヒープメモリ最大値) | JobManager で使用できる非ヒープメモリの最大量。 | バイト | |
TM ヒープメモリ (TM ヒープメモリ) | TM ヒープメモリ使用量 (TM ヒープメモリ使用量) | TaskManager によって現在使用されているヒープメモリの量。 | バイト |
TM ヒープメモリコミット済み (TM ヒープメモリコミット済み) | JVM によって TaskManager で使用可能であることが保証されているヒープメモリの量。 | バイト | |
TM ヒープメモリ最大値 (TM ヒープメモリ最大値) | TM ヒープメモリの最大値 | バイト | |
TM 非ヒープメモリ (TM 非ヒープメモリ) | TM 非ヒープメモリ使用量 (TM 非ヒープメモリ使用量) | TaskManager によって現在使用されている非ヒープメモリの量。 | バイト |
TM 非ヒープメモリコミット済み (TM 非ヒープメモリコミット済み) | JVM によって TaskManager で使用可能であることが保証されている非ヒープメモリの量。 | バイト | |
TM 非ヒープメモリ最大値 (TM 非ヒープメモリ最大値) | TaskManager で使用できる非ヒープメモリの最大量。 | バイト |
JVM
監視メトリック | 説明 | 単位 |
JM アクティブ スレッド (JM スレッド) | JobManager (JM) 内のアクティブスレッドの数。 JM スレッドが多すぎると、大量のメモリが消費され、ジョブの安定性が損なわれる可能性があります。 | カウント |
TM アクティブ スレッド (TM スレッド) | TaskManager (TM) 内のアクティブスレッドの数。TM ごとに集計され、複数の TM が別々の行に表示されます。 | カウント |
JM Young世代ガベージコレクタランタイム (JM GC 時間) | JobManager (JM) 内の若い世代のガベージコレクターのランタイム。 ガベージコレクション時間が長すぎると、メモリ使用量が過剰になり、ジョブのパフォーマンスに影響を与える可能性があります。 このメトリックは、ジョブレベルの問題の診断に役立ちます。 | ミリ秒 (ms) |
TM Young世代ガベージコレクタランタイム (TM GC 時間) | TaskManager (TM) 内の若い世代のガベージコレクターのランタイム。 ガベージコレクション時間が長すぎると、メモリ使用量が過剰になり、ジョブのパフォーマンスに影響を与える可能性があります。 このメトリックは、ジョブレベルの問題の診断に役立ちます。 | ミリ秒 (ms) |
JM Young世代ガベージコレクタ数 (JM GC回数) | JobManager (JM) 内の若い世代のガベージコレクションのカウント。 ガベージコレクションイベントの数が多いと、大量のメモリが消費され、ジョブのパフォーマンスに影響を与える可能性があります。 このメトリックは、ジョブレベルの問題の診断に役立ちます。 | カウント |
TM Young世代ガベージコレクタ数 (TM GC 回数) | TaskManager (TM) 内の若い世代のガベージコレクションのカウント。 ガベージコレクションイベントの数が多すぎると、大量のメモリが消費され、ジョブのパフォーマンスに影響を与える可能性があります。 このメトリックは、タスクレベルの問題の診断に役立ちます。 | カウント |
JVM 起動以降に TM によってロードされたクラスの合計数 (TM クラスローダー) | Java 仮想マシン (JVM) の起動以降に TaskManager (TM) によってロードされたクラスの総数。 ロードまたはアンロードされるクラスの数が多いと、大量のメモリが消費され、ジョブのパフォーマンスに影響を与える可能性があります。 | カウント |
JVM 起動以降に JM によってロードされたクラスの合計数 (JM クラスローダー) | Java 仮想マシン (JVM) の起動以降に JobManager (JM) によってロードされたクラスの総数。 ロードまたはアンロードされるクラスの数が多いと、大量のメモリが消費され、ジョブのパフォーマンスに影響を与える可能性があります。 | カウント |