ローカルファイル入力コンポーネントを使用すると、ローカルのテキスト、Excel(xls、xlsx)、および CSV ファイルを Dataphin にアップロードし、他のデータソースとのデータ同期を容易にすることができます。このトピックでは、ローカルファイル入力コンポーネントの構成プロセスについて概要を説明します。
制限事項
ローカルファイル入力コンポーネントは、ワンタイムタスクに対してのみ構成可能です。
手順
Dataphin ホームページで、トップメニューバーに移動し、[開発] > [data Integration] を選択します。
統合ページのトップメニューバーで、[プロジェクト] を選択します(開発 - 本番モードでは環境を選択する必要があります)。
左側のナビゲーションウィンドウで、[バッチパイプライン] をシングルクリックします。次に、[バッチパイプライン] リストで、目的の [オフラインパイプライン] をシングルクリックして、構成ページにアクセスします。
右上隅にある [コンポーネントライブラリ] をクリックして、[コンポーネントライブラリ] パネルを開きます。
[コンポーネントライブラリ] パネルの左側のナビゲーションウィンドウで、[入力] を選択します。右側のリストで [ローカルファイル] コンポーネントを見つけて、キャンバスにドラッグします。
コンポーネントカードの
 アイコンをクリックして、[ローカルファイル入力構成] ダイアログボックスを開きます。
アイコンをクリックして、[ローカルファイル入力構成] ダイアログボックスを開きます。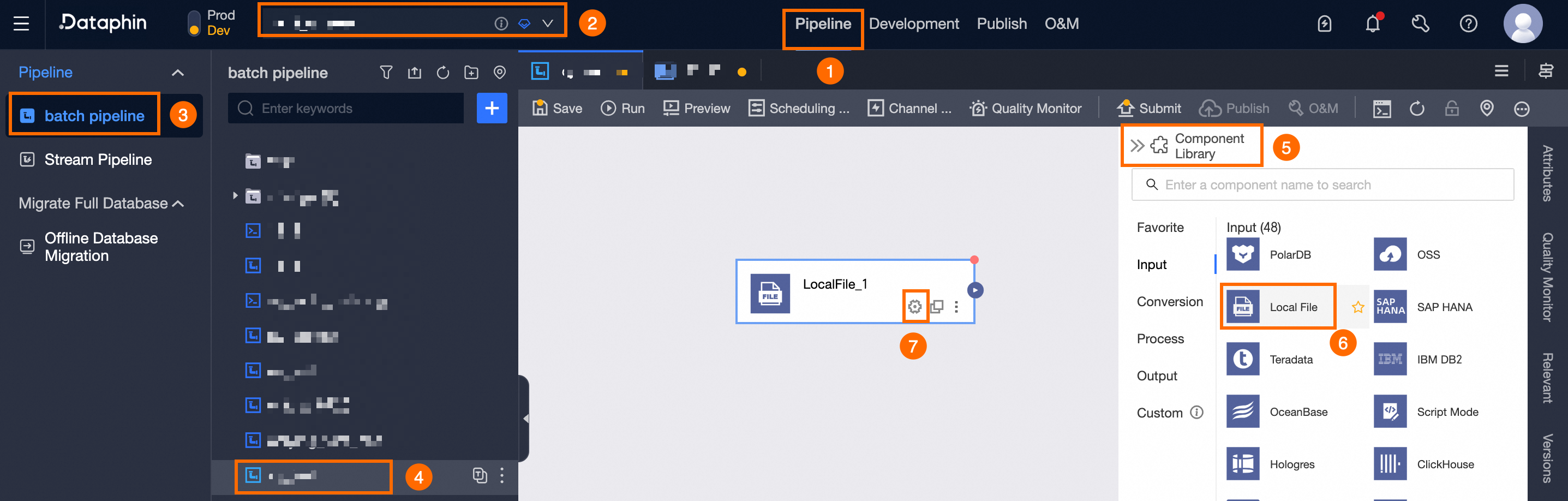
[ローカルテキスト入力構成] ダイアログボックスでは、csv、text、xls、xlsx などのファイルタイプを選択できます。次の構成手順に従います。
テキストファイルタイプ
パラメータ
説明
ステップ名
ローカルファイル入力コンポーネントのステップ名は Dataphin によって自動生成されますが、ビジネスシナリオに合わせて変更できます。命名規則は次のとおりです。
漢字、英大文字と英小文字、アンダースコア(_)、および数字のみを含める必要があります。
長さは 64 文字以下にする必要があります。
ファイルタイプ
テキストファイルタイプを選択します。
ファイルパス
[ファイルを選択] をクリックするか、オブジェクトファイルをファイルパス領域にドラッグします。
説明.txt 形式のファイルのみがサポートされており、ファイルサイズは 500 MB を超えてはなりません。
最初の行のコンテンツタイプ
最初の行のコンテンツタイプとして、[データコンテンツ] または [列名] を選択します。
最初の行のコンテンツ開始行
最初の行のコンテンツタイプが [列名] の場合、データコンテンツの開始行は 2 以上である必要があります。
最初の行のコンテンツタイプが [データコンテンツ] の場合、データコンテンツの開始行は 1 以上である必要があります。
行区切り文字、列区切り文字(オプション)
行区切り文字:ファイル内の行を区切る区切り文字。指定しない場合、デフォルトは
\nです。他の文字の場合は、入力して [解析] をクリックします。列区切り文字:ファイル内の列を区切る区切り文字。指定しない場合、デフォルトはカンマ(,)です。
ファイルエンコーディング
ファイルのエンコード方法を選択します。システムは、[UTF-8] エンコーディングと [GBK] エンコーディングをサポートしています。
詳細構成
読み取り制御の構成項目を入力します。サンプルコードは次のとおりです。
{ "textReaderConfig":{ "caseSensitive":true, "useTextQualifier":false, "textQualifier":"\"", "trimWhitespace":false } }出力フィールドの作成
出力フィールドが表示され、構成できます。
フィールドの一括追加。
[一括追加] をクリックします。
JSON 形式で一括構成を入力します。例:
[{ "index": 0, "name": "cf1a", "type": "String" }, { "index": 1, "name": "cf1b", "type": "String" }]説明ここで、`index` は列番号、`name` はフィールド名、`type` はフィールドタイプを指します。たとえば、
"name":"user_id","type":"String"は、user_id という名前のフィールドを String タイプとして導入することを意味します。TEXT 形式で一括構成を入力します。例:
0,cf1a,String 1,cf1b,String行区切り文字は各フィールドの情報を区切り、デフォルトは改行(\n)です。改行(\n)、セミコロン(;)、およびピリオド(.)をサポートしています。
列区切り文字はフィールド名とフィールドタイプを区切り、デフォルトはカンマ(,)です。
[確認] をクリックして構成を保存します。
出力フィールドの作成。
[出力フィールドの作成] をシングルクリックし、ページのプロンプトに従って [ソース序数]、[列] を入力し、[タイプ] を選択します。テキストファイルタイプのソース序数は、フィールドが配置されている列の数値序数(0 から始まる)で入力する必要があります。
出力フィールドの管理。
追加したフィールドに対して次の操作を実行できます。
[列] アイコン
 をクリックアンドドラッグして、フィールドの順序を変更します。
をクリックアンドドラッグして、フィールドの順序を変更します。[操作] 列の
 アイコンをクリックして、既存のフィールドを変更します。
アイコンをクリックして、既存のフィールドを変更します。[操作] 列の
 アイコンをシングルクリックして、選択したフィールドを削除します。
アイコンをシングルクリックして、選択したフィールドを削除します。
CSV ファイルタイプ
パラメータ
説明
ステップ名
ローカルファイル入力ステップの名前を入力します。Dataphin はデフォルトのステップ名を生成しますが、ビジネスシナリオに合わせてカスタマイズできます。次の命名規則に従ってください。
漢字、英大文字と英小文字、アンダースコア(_)、および数字のみを含めます。
名前は最大 64 文字までに制限します。
ファイルタイプ
CSV ファイルタイプを選択します。
ファイルパス
ファイルを選択するには、[ファイルを選択] をシングルクリックするか、オブジェクトファイルを指定されたファイルパス領域にドラッグします。
説明csv ファイルタイプのみがサポートされており、最大ファイルサイズは 500 MB です。
文字区切り文字
ファイルの列区切り文字を指定します。空白のままにすると、デフォルトはカンマ(,)です。
ファイルエンコーディング
ファイルのエンコーディングを選択します。サポートされているエンコーディングには、[UTF-8] と [GBK] が含まれます。
最初の行のコンテンツタイプ
最初の行に [データコンテンツ] または [列名] が含まれているかどうかを選択します。
データコンテンツ開始行
最初の行に [列名] が選択されている場合、データコンテンツは 2 行目以上から開始する必要があります。
最初の行に [データコンテンツ] が選択されている場合、データコンテンツは 1 行目以上から開始する必要があります。
出力フィールドの作成
出力フィールドがここに表示されます。
フィールドの一括追加
[一括追加] をシングルクリックします。
JSON 形式で一括構成を入力します。例:
[{ "index": 0, "name": "cf1a", "type": "String" }, { "index": 1, "name": "cf1b", "type": "String" }]説明ここで、`index` は列番号、`name` はフィールド名、`type` はフィールドデータ型を指定します。たとえば、
"name":"user_id","type":"String"は、String データ型の user_id という名前のフィールドを追加します。TEXT 形式で一括構成を入力します。例:
0,cf1a,String 1,cf1b,String行区切り文字は各フィールドの情報を区切り、デフォルトは改行(\n)です。サポートされている区切り文字には、改行(\n)、セミコロン(;)、およびピリオド(.)が含まれます。
列区切り文字はフィールド名とフィールドタイプを区切り、デフォルトはカンマ(,)です。
[確認] をシングルクリックします。
出力フィールドの作成。
出力フィールドを作成するには、[出力フィールドの作成] をシングルクリックし、[ソース序数] と [列] を入力し、プロンプトに従って [タイプ] を選択します。CSV ファイルタイプの場合、ソース序数は 0 から始まる列の数値序数に対応している必要があります。
出力フィールドの管理。
追加したフィールドに対して次の操作を実行できます。
フィールドの位置を並べ替えるには、[列] アイコン
をシングルクリックしてドラッグします。既存のフィールドを編集するには、[操作] 列の
アイコンをクリックします。既存のフィールドを削除するには、[操作] 列の
アイコンをシングルクリックします。
XLS または XLSX ファイルタイプ
パラメータ
説明
ステップ名
ローカルファイル入力プロセスにおけるステップの名前。Dataphin は自動的にステップ名を生成しますが、ビジネスシナリオに合わせて変更できます。命名規則は次のとおりです。
漢字、英大文字と英小文字、アンダースコア(_)、および数字を含めることができます。
長さは 64 文字を超えることはできません。
ファイルタイプ
xls または xlsx ファイルタイプを選択します。
ファイルパス
[ファイルを選択] をクリックするか、オブジェクトファイルを指定されたファイルパス領域にドラッグします。
説明xls ファイルタイプの場合、.xls 形式のみがサポートされています。xlsx の場合、.xlsx 形式のみがサポートされています。最大ファイルサイズは 500 MB です。
システム解析は最大 50 MB のファイルをサポートします。ファイルサイズが 50 MB を超える場合、出力フィールドの自動解析は使用できません。出力フィールドを手動で作成してください。
シート選択
名前またはインデックスでシートを選択します。
[名前別]:読み取るシート名を指定します。
[インデックス別]:読み取るシートインデックスを指定します(0 から開始)。
最初の行のコンテンツタイプ
最初の行のデータコンテンツまたは列名を選択します。
データコンテンツ開始行
最初の行が列名の場合、データコンテンツは 2 行目以上から開始する必要があります。データコンテンツの場合、1 行目以上から開始する必要があります。
データコンテンツ終了行
データコンテンツの終了行は、開始行以上である必要があります。指定しない場合、システムはデフォルトでデータを含む最後の行まで読み取ります。
シート名のエクスポート
必要に応じて、ソースシートの名前をエクスポートします。選択すると、[出力フィールド] に [ソースシート] フィールドが含まれ、コンテンツは
{ファイル名}-{シート名}の形式になります。ファイルエンコーディング
ファイルのエンコーディングを選択します。システムは、[UTF-8] エンコーディング方法と [GBK] エンコーディング方法をサポートしています。
出力フィールド
出力されるフィールドを確認します。
フィールドの一括追加。
[一括追加] をクリックします。
JSON 形式で一括構成を入力します。例:
[{ "index": 0, "name": "cf1a", "type": "String" }, { "index": 1, "name": "cf1b", "type": "String" }]説明ここで、`index` は列番号、`name` はフィールド名、`type` はフィールドタイプを指します。たとえば、
"name":"user_id","type":"String"は、user_id という名前のフィールドを String タイプとして導入することを意味します。TEXT 形式で一括構成を入力します。例:
0,cf1a,String 1,cf1b,String行区切り文字を使用して各フィールドの情報を区切ります。デフォルトは改行(\n)です。改行(\n)、セミコロン(;)、およびピリオド(.)をサポートしています。
列区切り文字を使用してフィールド名とフィールドタイプを区切ります。デフォルトはカンマ(,)です。
[確認] をクリックします。
出力フィールドの作成。
[出力フィールドの作成] をクリックし、プロンプトに従って [ソース序数]、[列] を入力し、[タイプ] を選択します。
出力フィールドの管理。
追加したフィールドに対して次の操作を実行します。
[列] アイコン
をクリックアンドドラッグして、フィールドを並べ替えます。既存のフィールドを編集するには、
[操作] 列の アイコンをシングルクリックします。既存のフィールドを削除するには、[操作] 列の
アイコンをシングルクリックします。
[ローカルテキスト] 入力コンポーネントの構成を完了するには、[確認] をクリックします。